
 起点课堂会员权益
起点课堂会员权益聊聊“上下文工程(Context Engineering)”
当AI应用在面对复杂任务时频频出错,问题可能远不止是提示词的问题。上下文工程正成为AI时代的关键范式转移,它将AI从概率性工具转变为确定性系统组件。本文深度解析RAG、工具调用和提示词链三大核心技术,并提供构建可靠AI系统的四步实践框架,带你从‘手工作坊’迈向‘工业级AI架构’。
作为一名 AI 开发者或产品经理,你是否也曾陷入这样的困境:尽管花费数小时精心雕琢提示词(Prompt),你的 AI 应用或 Agent 在面对稍微复杂的任务时,依然会给出离谱的错误答案、凭空捏造事实(产生幻觉),或是干脆答非所问。
每当这时,我们的第一反应通常是:“肯定是我的提示词没写好!”
但这往往只是表面现象。尤其在今天,我们正从简单的聊天机器人迈向能够自主执行复杂任务的 AI Agent,这种思维的局限性正变得前所未有的致命。问题的根源,早已不是一个简单的指令,而是一个系统性的架构缺陷。
这正是上下文工程(Context Engineering)变得至关重要的原因。
它不仅仅是一项新技术,更是 AI 时代软件架构的一次根本性范式转移,旨在将 AI 从一个概率性的新奇玩意,转变为企业系统中一个确定性、可依赖的核心组件。
特斯拉前 AI 总监 Andrej Karpathy 一针见血地指出:
在每一个工业级的大语言模型应用中,上下文工程都是一门精巧的艺术与科学,其核心在于为模型的下一步(推理),用恰到好处的信息填满上下文窗口。
他的观点揭示了一个行业内正在发生的深刻转变:我们的思维必须从“提示词工程”升级到“上下文工程”。这不仅仅是术语的替换,更是从业余 AI Demo 迈向专业级 AI 应用的分水岭。
那么,到底什么是上下文工程?它与我们熟知的提示词工程有何本质区别?更重要的是,我们该如何利用它来构建那些真正智能、可靠,能解决实际问题的 AI 系统?
从“手工作坊”到“流水线”:上下文工程 vs. 提示词工程
要理解上下文工程的巨大价值,我们首先得搞清楚它和提示词工程的根本区别。如果你还在为调整一两个词而纠结,那你可能还在用“手工作坊”的模式做事;而真正的专业玩家,已经在思考如何搭建一条自动化的“信息流水线”了。
让我们用一个生动的比喻来区分这两者:
- 提示词工程 (Prompt Engineering):好比一位手工艺人。他会为某一个特定的任务,全神贯注地雕琢一个完美的指令。他的核心工作是手动、迭代地优化文本,目标是让 AI 在这一次的对话里,给出一个高质量的回答。这是一种战术层面的技巧,追求单点任务的极致效果。
- 上下文工程 (Context Engineering):则更像一位工业设计师。他不会只盯着一个零件,而是围绕 AI 模型这个“发动机”,设计一整套自动化的信息供给系统。他的核心工作是构建一个能够自动检索、组织并提供相关信息的系统或装配线,目标是让 AI 能够持续、可靠地完成各种复杂任务。这是一种战略层面的架构思维,追求系统的稳定与可扩展。
为了更清晰地对比,我们可以看看下面这张表:
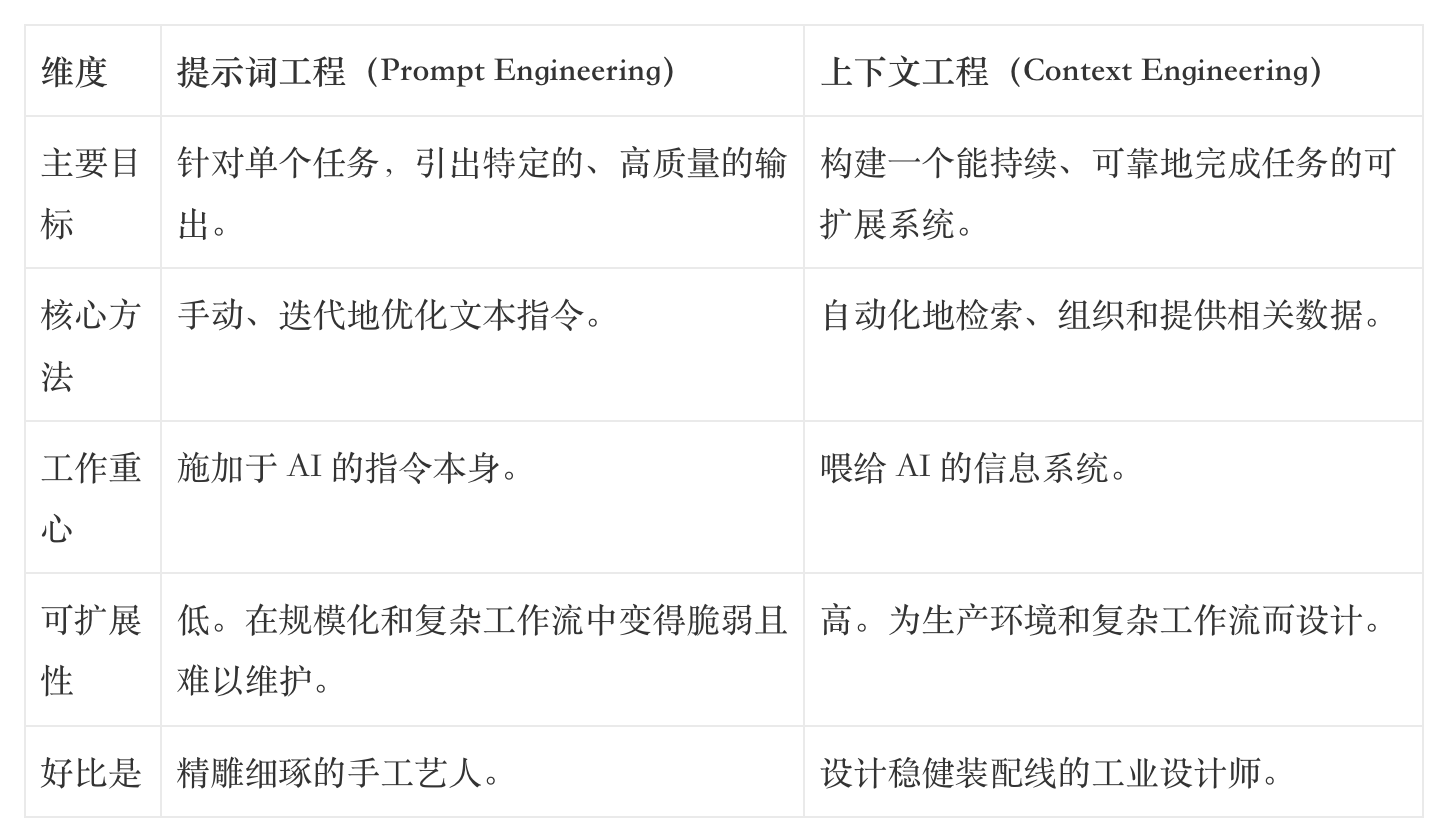
这并非一个学术上的区分,而是对未来成功的预测。那些固守于“手工艺”式提示词工程的团队,将不可避免地撞上脆弱性和不可扩展性的高墙。
未来属于那些像系统架构师一样思考的人,而不仅仅是“文字的魔术师”。
总而言之,提示词工程是上下文工程的一个子集。上下文工程决定了 AI 的“视野”里应该看到哪些信息(比如最新的公司政策、用户的历史订单),而提示词工程则是在这个视野范围内,如何更好地提出问题。
这种系统性的思维强调一种“杠杆效应”的层级:正如 YC Root Access 所揭示的,
一行糟糕的研究,可能导致上千行无用的代码。
在系统层面优化信息供给(即上下文工程),远比在执行层面反复修改指令(即提示词工程)的杠杆效应要大得多。
现在我们知道了它们是什么,接下来看看具体该怎么做。
上下文工程的“三板斧”:核心技术与思维方式
上下文工程不是一个空洞的理论,它是由一系列具体、强大的技术组成的实践方法论。掌握了它们,你就拥有了将一个通用 AI 模型,打造成特定领域专家的能力。下面我们来聊聊最核心的“三板斧”。
技术一:检索增强生成(RAG)
给 AI 一本可以随时查阅的“开卷考试书”。
大语言模型最大的局限之一,就是它的知识是“静态”的——它只知道训练截止日期前的事情,对于公司的最新政策、私有数据或实时信息一无所知。RAG(Retrieval-Augmented Generation)就是为了解决这个问题而生的。
你可以把 RAG 想象成是给了 AI 一本可以随时查阅的参考书,让它从“闭卷考试”变成了“开卷考试”。当 AI 接到一个问题时,它不会直接凭记忆回答,而是会先去你指定的知识库(比如公司的内部文档、产品数据库、最新的支持工单)中,检索出最相关的信息片段,然后基于这些新鲜、准确的“参考资料”来生成答案。
举个例子,一个客服机器人如果只靠模型的固有知识,可能会给出一个过时的退货政策。这不仅会惹恼客户,更会带来商业风险。但如果它使用了 RAG 技术,就能在回答前先查询最新的政策文档,从而确保提供给客户的信息 100% 准确,这直接保护了品牌信誉并降低了潜在的法律责任。
技术二:工具使用与函数调用 (Tool Use / Function Calling)
让 AI 从“动嘴”进化到“动手”。
如果说 RAG 给了 AI 一双能看懂私有知识的眼睛,那么工具使用(Tool Use)则给了它一双能与外部世界交互的“手”。这项技术允许 AI 调用预定义的函数或外部 API,从而执行具体的操作,而不仅仅是生成文本。
这彻底改变了 AI 的角色,让它从一个只会聊天的“对话者”,转变为能够深度参与工作流的“行动者”。
- 安排会议:AI 可以调用日历 API,查询空闲时间并自动创建会议。
- 更新客户记录:AI 可以调用 CRM 系统的 API,将通话记录自动同步到 Salesforce 中。
- 查询实时库存:电商机器人可以调用库存 API,实时查询某件商品的存货情况。
通过赋予 AI“动手”的能力,我们把它从一个简单的文本生成器,升级为了一个能处理复杂业务流程的自动化助手。
技术三:提示词链 (Prompt Chaining)
把复杂的大任务拆解成“流水线作业”。
当你试图用一个超级复杂的 Prompt 让 AI 一次性完成一个宏大任务(比如“写一份完整的市场分析报告”)时,结果往往是泛泛而谈、缺乏深度,甚至错误百出。因为这对 AI 来说,一步到位的“认知负荷”太高了。
提示词链(Prompt Chaining)的思想很简单:把一个大任务,拆解成一系列相互关联、循序渐进的小步骤,就像工厂的流水线一样。每一步的输出,都成为下一步的输入。
以上述的市场分析报告为例,我们可以设计一个三步提示词链:
- Prompt 1: “识别出针对远程工作者的生产力应用领域,排名前三的竞品是什么?”
- Prompt 2: “基于上一步识别出的竞品列表,分析并列出每个竞品的主要优缺点。”
- Prompt 3: “根据前两步的竞品分析,撰写一段 200 字的摘要,总结我们新应用的一个关键市场机会。”
通过这种方式,我们确保了每一步的输出质量都可控,AI 的思考过程也变得更加结构化,最终报告的可靠性和深度自然也就大大提升了。
这些技术的战略价值
这些技术不仅仅是酷炫的工具,它们能直接为业务创造可衡量的价值。将这些技术与商业利益对应起来,你会看得更清楚:

这三种技术——RAG、工具使用和提示词链——是我们上下文工程语法中强大的“动词”。下一节将提供一套“句法”,教你如何将它们组织成一个连贯的句子:一个可重复的、四步走的工作流。
从理论到实践:构建上下文工程系统的四步法
拥有强大的技术就像手里握着一把好锤子,但如果没有清晰的蓝图,你还是造不出一栋坚固的房子。构建一个可靠的 AI 系统也是如此,你需要一个结构化的方法论,而不是随心所欲地敲敲打打。这就像搭建复杂的乐高模型需要图纸一样。
下面是一个简单实用的四步法,可以帮助你系统地构建上下文工程。
第一步:定义一个明确的目标 (Define a Specific Goal)
在写下任何代码或 Prompt 之前,最重要的一步是清晰地定义你要解决的问题和成功的标准。一个模糊的目标,比如“提升客服水平”,是无法执行的。目标必须具体、可衡量。
- 模糊目标:“我想做一个 AI 来改善客户支持。”
- 明确目标:“我要构建一个 AI 助手,它能通过引用内部知识库,准确回答关于退货政策的问题,目标是将人工客服处理此类问题的响应时间减少 30%。”
一个明确的目标不仅指明了方向,还定义了需要用到的上下文资产(内部知识库)和衡量成功的具体指标(响应时间减少 30%)。
第二步:盘点你的上下文资产 (Inventory Your Context Assets)
目标明确后,就像厨师在做菜前准备好所有食材(mise en place)一样,你需要盘点 AI 完成任务所需的所有信息,我们称之为“上下文资产”。
这些资产通常可以分为三类:
- 知识 (Knowledge):静态的、可供查阅的信息。例如,官方的退货政策 PDF 文档、产品手册、FAQ 页面等。
- 数据 (Data):与特定用户或情境相关的动态信息。例如,某个客户的订单历史记录、过去的聊天记录等。
- 工具 (Tools):AI 需要执行的外部操作。例如,一个可以查询订单状态的 API 接口、一个可以创建支持工单的函数等。
把这些资产整理出来,你就为 AI 构建了一个可靠的信息库,让它基于事实回答,而不是凭空捏造。
第三步:设计交互流程 (Design the Interaction Flow)
现在,你需要为 AI 的决策过程画出“故事板”或“流程图”。在这一步,你需要决定在何时、以何种方式调用你在第二步中盘点的资产,并选择最合适的上下文工程技术。
这就是你决定部署哪项“三板斧”的地方。AI 需要外部知识吗?使用 RAG。它需要采取行动吗?使用工具使用。任务对于一步完成来说太复杂了吗?用提示词链来分解它。
让我们继续以客服机器人为例,它的交互流程可能如下:
- 用户提出关于退货的问题(例如:“我想退货该怎么做?”)。
- 系统启动 RAG 流程,在“退货政策文档”这个知识资产中检索最相关的段落。
- AI 根据检索到的内容,生成一个精准的回答。
- 如果用户追问:“我的那个订单能退吗?”,系统会识别出需要数据资产和工具。
- AI 调用“查询订单状态”的 API 工具,传入用户的订单号,获取订单详情。
- AI 结合订单详情和退货政策,给出最终的个性化答复。
这个流程清晰地定义了每一步如何管理和运用上下文,将一个被动的聊天机器人,变成了一个主动解决问题的专家。
第四步:迭代测试与优化 (Test and Refine Iteratively)
记住,你的第一个版本绝对不会是完美的。最后一步是一个持续的循环:在真实场景中测试你的系统,收集失败案例和用户反馈,然后回头去优化你的目标、资产和流程。
AI 系统不是一蹴而就的,它需要像任何优秀的软件产品一样,通过不断的迭代来打磨和完善。
要实现上面这些流程,自然少不了一些趁手的兵器。幸运的是,AI 社区已经为我们准备好了丰富的工具箱。
工欲善其事必先利其器:热门工具与框架一览
从零开始搭建一整套上下文工程系统无疑是复杂的。好消息是,开源社区已经涌现出许多优秀的工具和框架,它们就像预制好的“乐高积木”,可以帮助我们更轻松、更高效地构建强大的 AI 应用。以下是一些主流的选择:
这些框架是构建复杂 LLM 应用的中枢神经系统,负责“编排”模型、数据和工具之间的协作。
- LangChain: 一个功能极其丰富的框架,提供了连接 LLM、向量数据库、API 等各种组件的标准化接口,是目前最流行的选择之一。
- Haystack: 另一个强大的开源框架,专注于帮助开发者构建生产就绪的 LLM 和 RAG 应用,尤其擅长处理复杂的搜索和问答任务。
这些库专注于优化 RAG 流程的各个环节,让“开卷考试”变得更高效。
- LlamaIndex: 专注于数据的“连接”层,擅长将各种来源的数据(PDF, API, 数据库)轻松接入 LLM 应用。
- FlashRAG: 一个为 RAG 研究和实验设计的 Python 工具包,它提供了数十个预处理好的基准 RAG 数据集,这对于需要进行可复现研究和性能比较的开发者来说至关重要。
- RAGFlow: 一个强调“深度文档理解”的开源 RAG 引擎,它能够处理多种格式的文档,如 PDF 文件甚至图像,使其非常适合用于复杂的混合媒体知识库。
它们是实现 RAG 背后“语义检索”的核心基础设施,负责存储文本的向量表示并进行高效的相似性搜索。
- Chroma, Pinecone, Weaviate: 这些都是目前主流的向量数据库,为 RAG 系统提供了强大的检索引擎。
模型上下文协议 (Model Context Protocol, MCP): 这是一个由 Anthropic 发起,并被 OpenAI、Google 等行业巨头采纳的开放标准。你可以把它想象成 AI 与外部工具、数据交互的“USB-C 接口”。它作为一个通用的客户端-服务器协议,定义了一套统一的规范来标准化 AI Agent 与工具的交互方式,从而解决了“N×M 集成问题”,极大地简化了工具集成和系统间的互操作性。
选择合适的工具组合,可以让你的开发工作事半功倍。理解了这些,我们再来看看,在构建更高级的 AI Agent 时,如何运用这些上下文思维。
决胜 AI Agent:构建时的上下文思维模式
当我们开始构建真正能自主完成任务的 AI Agent 时,“上下文”的重要性被提升到了前所未有的高度。
根据我的经验,绝大多数 Agent 的失败,并非逻辑上的失败,而是我称之为“上下文失败”(context failures)——即我们为其提供的信息环境的崩溃。
Agent 中的上下文管理挑战
与简单的问答机器人不同,Agent 需要处理长时任务,这意味着它会不断与工具交互、接收反馈、记录中间步骤。这个过程会导致上下文窗口迅速膨胀,并带来一系列严峻的挑战,这些是导致“上下文失败”的直接症状:
- 成本飙升:token 数量越多,API 调用成本越高。
- 性能下降:上下文窗口过长,模型性能会退化,出现所谓的“上下文中毒”(错误信息污染后续推理)、“分心”(被不相关信息干扰)或“混淆”(无法分清不同信息来源)。
这些症状的根源在于无管理的上下文增长。因此,被动地让上下文野蛮生长,是构建可靠 Agent 的大忌。我们需要主动、有策略地管理它。
先进的上下文管理策略
“有意压缩” (Intentional Compaction)
这一策略的核心理念,是主动管理上下文,而不是被动填满它,其灵感源于 YC 的 Root Access 系列中展示的一个强大工作流。与其等到上下文窗口快满了再想办法,不如在每一步都刻意保持其“苗条”。一个行之有效的策略是,始终将上下文的利用率保持在较低水平(例如 40%以下)。当一个阶段性任务完成后,不要把所有对话历史和工具输出都塞给下一个 Agent,而是生成一个简洁的“进展文件”或摘要,只包含关键信息,然后用这个摘要来启动下一个任务。
上下文隔离 (Context Isolation)
当一个 Agent 需要调用不同工具或处理不同子任务时,一个常见的错误是把所有信息都混在一个大的上下文中。更好的做法是为不同的任务或工具创建独立的上下文环境,就像使用沙箱或独立的状态对象一样。比如,一个负责“搜索文件”的子 Agent,它的上下文里只需要包含搜索指令和结果,而不需要知道主 Agent 的完整计划,这样可以有效避免信息交叉污染。
更高级的开发工作流:“研究-计划-执行” (Research-Plan-Implement)
同样借鉴自 YC Root Access 的实践,这个高级工作流将 Agent 的开发过程系统化为三个阶段,其核心就是围绕上下文的管理:
- 研究 (Research): 在动手写代码或执行任务前,先让一个 AI(或人)充分理解系统和问题。它需要搞清楚所有相关文件、数据流和依赖关系。这个阶段的产出是一份清晰的研究报告。
- 计划 (Plan): 基于研究阶段的洞察,制定一个详细的、分步骤的执行计划。这个计划应该明确要修改哪些文件、调用哪些工具、以及每一步的预期结果。
- 执行 (Implement): 在人和 AI 都对计划达成共识后,再让 AI Agent 去执行。由于上下文(研究报告和计划)已经极度清晰,执行阶段的出错率会大大降低。
这个工作流背后有一个深刻的洞察:“一行糟糕的研究,可能导致上千行无用的代码。” 在计划阶段花时间审查上下文,远比在代码写完后去调试要高效得多。
构建 AI Agent 的思维转变
最终,构建一个强大的 AI Agent,需要我们完成一个根本性的思维转变:
从问“我该写什么样的 Prompt?” 转变为问“我的 Agent 需要什么样的上下文才能成功?”
这包括三个核心问题:
- 它需要知道什么?(知识,通过 RAG 提供)
- 它需要能做什么?(工具,通过函数调用赋予)
- 它需要记得什么?(记忆,通过有效的上下文管理和压缩策略实现)
理解了这一转变,我们就能更好地把握 AI 系统设计的未来。
结语:超越提示词,拥抱系统化 AI 的未来
回顾全文,我们不难发现一个清晰的脉络:构建强大、可靠的 AI 应用,其关键已经不再是战术性地“调教”某一个提示词,而是战略性地架构一整个上下文系统。这正是从“提示词工程”到“上下文工程”的范式转移,是 AI 时代软件架构的核心演进。
从 RAG、工具使用到提示词链,再到为 Agent 设计的“研究-计划-执行”工作流,所有这些技术和方法论都指向同一个未来——我们必须像设计一个“语义操作系统”一样,去系统地设计 AI 的信息环境。在这个系统中,AI 不再是被动响应指令的工具,而是能够主动管理知识、记忆和行为的认知核心。
随着 AI Agent 变得越来越复杂,能够自主完成多步骤的宏大任务,上下文工程将不再是少数专家的“屠龙之技”,而会成为下一代 AI 构建者的核心必备技能。它不再是锦上添花,而是决定 AI 应用成败的基石。
所以,别再只盯着那个小小的提示词输入框了。抬起头,开始在你的下一个项目中实践上下文工程的思维,去构建真正智能、可靠且能创造巨大价值的 AI 应用吧。掌握它,你将定义 AI 的未来。
作者:爱撸猫的产品仔;公众号:爱撸猫的产品仔
本文由 @爱撸猫的产品仔 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自作者提供
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


