
 起点课堂会员权益
起点课堂会员权益RAG技术如何重塑下一代互联网产品?从“闭卷”到“开卷”的产品思维升级
AI产品的‘幻觉问题’、‘知识陈旧’和‘数据孤岛’正在成为用户信任崩塌的致命伤。RAG技术的崛起不仅是一场技术革命,更是一次产品思维的范式转移——从‘闭卷考试’到‘开卷考试’,让AI真正成为业务场景中的‘专属专家’。本文将深度剖析三大RAG形态的进化路径,并提供可落地的四步实践框架。

一、困境与觉醒——互联网产品的“AI困境”正在呼唤变革
最近跟朋友聊天,发现大家都在吐槽一件事,就是现在的很多AI产品,用起来总感觉有点“傻”
就拿我前几天遇到的事来说吧,我想在一个电商平台上查个退货政策,就去问那个智能客服,结果它给我一个三年前的链接,点进去早就失效了,你说气不气,最后还是得老老实实去找人工客服排队,体验瞬间降到冰点
这种事儿绝对不是个例,我相信你肯定也遇到过,比如你在一个内容社区,想让AI帮你总结一下某个热点事件,结果它给你编得有鼻子有眼,里面一半都是假信息,还得你自己再去一个个核实,这哪是提效工具,简直是“增负”工具
作为一名AI产品经理,我每天都在跟这些问题打交道,我们把这些问题归结为几个典型的“AI困境”,这些困境就像几座大山,压得我们这些想做点创新的人喘不过气来
一个就是“幻觉”问题,大模型有时候太能“编”了,你问它一个东西,它不知道,但它不会说不知道,它会一本正经地胡说八道,给你创造一些事实,这在娱乐场景下可能无伤大雅,但在严肃的知识问答或者金融、医疗领域,这就是致命的缺陷,会直接摧毁用户对产品的信任
另一个是“知识陈旧”,这也好理解,大模型的训练数据总有个截止日期,就像我遇到的那个客服机器人,它的知识库可能还停留在几年前,互联网世界瞬息万变,一个产品的价格、一个活动的规则,可能上周刚改过,模型不知道,给出的就是错误信息,这直接影响了产品的可用性
还有一个更深层次的问题,我称之为“数据孤岛”,每个公司内部都有海量的私有数据,比如产品手册、技术文档、销售话术、客户案例,这些数据是公司最宝贵的知识财富,但它们都散落在各个系统里,形成了一个个孤岛,原生的大模型根本接触不到这些信息,它就像一个博学的通才,却对你公司的具体业务一无所知,这让它在解决企业内部的实际问题时,显得力不从心
这些困境叠加在一起,导致很多AI产品陷入了一个尴尬的境地,看起来很智能,一用就露馅,用户的新鲜感一过,留存率就直线下滑,我们这些做产品的人,投入了大量的资源和精力,最后却做出来一个“人工智障”,这种挫败感,真的很难受
我们越来越清楚地意识到,单纯依赖一个原生大模型,想让它解决所有问题,这条路可能走不通了,这就像你让一个没上过大学的人去考研,他基础再好,也答不出那些专业课的题目,我们需要一种新的方式,一种能让模型“学得更快、答得更准”的方式,变革的呼声越来越高,而RAG,可能就是那个我们一直在等的答案
二、本质解构——RAG不是功能,而是一场产品哲学的“开卷革命”
很多人第一次听到RAG,检索增强生成,第一反应就是“哦,这不就是搜索加上一个AI总结嘛”,技术上好像是这么回事,但如果你仅仅把它看作一个技术组合,那格局就小了
在我看来,RAG的出现,带来的是一场产品思维的根本性变革,是从“闭卷考试”到“开卷考试”的哲学升级
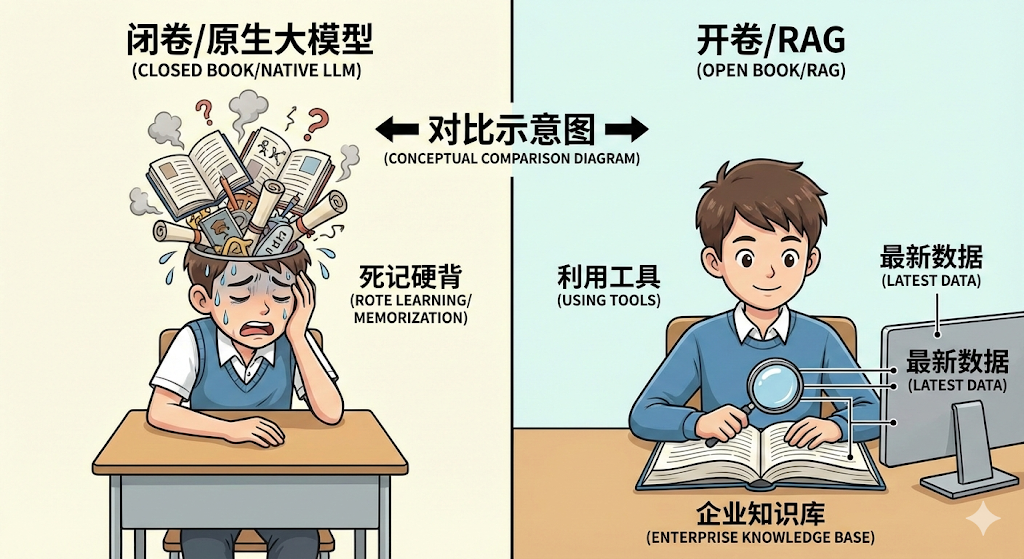
“闭卷”思维 VS “开卷”思维
想想我们以前做AI产品的思路是什么,我们希望模型无所不知,像一个超级大脑,把全世界的知识都记在脑子里,我们通过不断地投喂数据、做微调,试图让模型“背下”所有的知识点,这就是典型的“闭卷思维”,模型在回答问题时,完全依赖自己记忆里的东西
这种思维的弊端,就是我们第一章里说的那些,记忆会出错,会产生幻觉,记忆会过时,无法更新,而且你不可能把公司内部那些私有的、实时变化的数据全都让它背下来,成本太高,效率太低
RAG带来了什么呢,它带来的是“开卷思维”,我们不再强求模型记住所有东西,而是给了它一本书,一个专属的、最新的知识库,并且教会了它如何“查书”,当用户提问时,模型不再是凭空回忆,而是先去知识库里找到最相关的几页,把这些内容作为参考,再组织语言回答用户,这就是开卷考试
你看,这个转变是根本性的,我们对模型的定位变了,它不再是一个需要背下所有东西的“考生”,而是一个懂得如何利用工具、查找资料、并基于资料进行回答的“研究员”,这大大降低了对模型本身记忆力的要求,转而强调它“查找和理解”的能力
RAG的产品化定义
基于这种“开卷思维”,我们可以给RAG一个全新的产品化定义,它不再是一个冷冰冰的技术术语,而是一个产品的“专属、实时、可追溯的知识中枢”
“专属”意味着这个知识库是为你这个产品或企业量身定制的,里面装的是你的产品说明、你的业务流程、你的客户数据,而不是互联网上那些大而全的通用知识,这让AI的回答真正和你自己的业务挂钩
“实时”意味着这个知识库是可以随时更新的,今天下午产品价格变了,你马上就可以更新知识库里的文档,下一秒,AI就能给出最新的价格,这就解决了知识陈旧的问题
“可追溯”这个点特别重要,因为RAG的回答是基于知识库里的原文生成的,我们可以把这些原文链接附在答案后面,用户如果对答案有疑问,可以自己点进去看原文,这就给了用户一个核查的途径,大大提升了答案的可信度,也解决了幻觉问题,因为一切都有据可查
核心价值四支柱
这个“知识中枢”的定位,给产品带来了四个看得见摸得着的核心价值,我称之为“价值四支柱”
准确性,这是最直接的价值,因为答案来源于经过审核的、最新的私有知识库,而不是模型自己的“想象”,回答的准确率自然就上去了,对于客服、金融、法律这类对准确性要求极高的场景,这是刚需
实时性,刚才也提到了,知识库的动态更新能力,让产品能够跟上业务的变化,一个新功能上线了,一篇新的市场分析报告出炉了,都可以立刻成为AI知识体系的一部分,这让AI产品真正具备了生命力
安全性,这也是很多企业非常关心的一点,用原生大模型,你总担心自己的私有数据被拿去训练了,造成数据泄露,而RAG模式下,私有数据存储在自己的知识库里,模型只是在查询时临时调用,数据本身不离开你的控制范围,这就解决了数据安全和隐私的顾虑
可解释性,或者叫可追溯性,当AI给出一个答案时,它能告诉你“我是根据这几份文档得出的结论”,这就让AI的决策过程不再是一个黑盒子,用户可以理解AI为什么这么说,这对于建立用户信任至关重要,尤其是在一些需要合规审计的场景,这种可追溯性是必不可少的
所以你看,RAG真的不只是一个功能,它是一种全新的产品构建理念,它把AI从一个“什么都懂一点,但什么都不精”的通才,变成了一个“在你这个领域,拿着最新参考书的专家”,这种转变,正在为下一代互联网产品的形态打开全新的想象空间

三、形态进化——三大RAG形态如何对应不同的互联网产品赛道
理解了RAG的“开卷”哲学之后,我们就要聊点更实际的了,作为产品经理,我们怎么把这个理念落地到具体的产品上呢,RAG也不是铁板一块,它在实践中已经演化出了几种不同的形态,来适应不同的业务需求,我把它总结为三种主流形态,就像给你一张“选型地图”,你可以看看自己的产品更适合哪条路
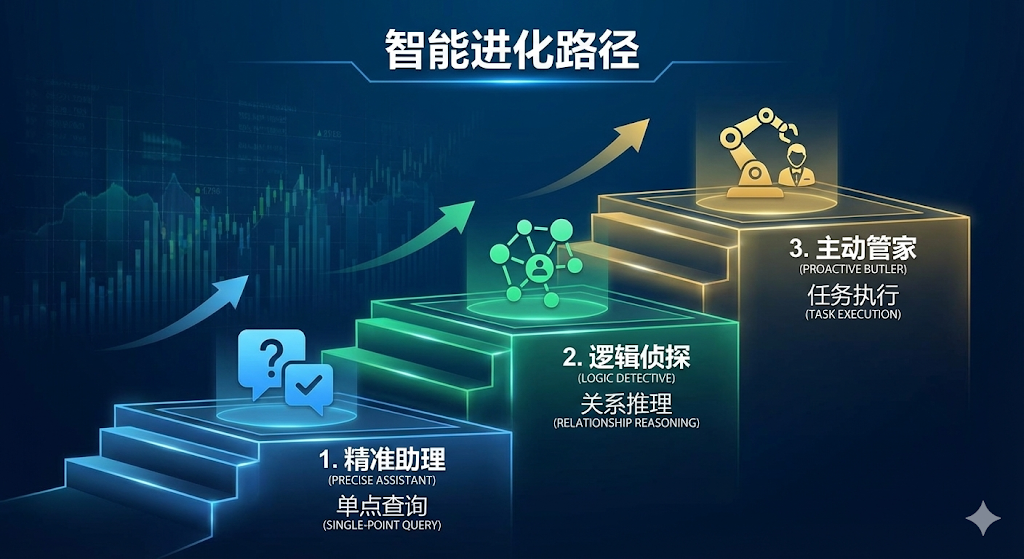
传统RAG “精准助理”
这是最常见,也是最基础的RAG形态,我叫它“精准助理”,它的核心逻辑很简单,就是“被动检索+精准回答”,用户问一个问题,系统去知识库里找到最匹配的文本片段,然后让大模型基于这些片段生成一个通顺的答案
这种形态最适合什么样的场景呢,就是那些有大量结构化或半结构化文档,并且用户问题相对聚焦的领域,比如电商平台的客服系统,几百页的售后政策、退换货流程,普通用户根本没耐心看,有了传统RAG,用户只需要用大白话问“我这个东西不想要了怎么退”,系统就能自动定位到相关条款,并给出清晰的步骤
还有在线教育的答疑机器人,把所有的教材、课件、习题解析都放进知识库,学生遇到问题随时问,AI就能像个助教一样,给出基于教材的准确解答,甚至还能引用原文页码
企业内部的SOP问答也是个典型,一个大公司可能有成千上万条操作规范,新员工入职培训头都大了,用传统RAG做一个内部问答机器人,新员工遇到任何流程问题,直接问就行,AI会把标准操作步骤告诉你,大大降低了培训成本和出错率
“精准助理”的价值在于,它把那些厚重的、沉睡的文档给“激活”了,变成了一个可以即时互动、即问即答的智能体验,它的关键是知识库的质量和检索的精度
Graph RAG “逻辑侦探”
如果说传统RAG解决的是“点”的问题,那Graph RAG解决的就是“线”和“面”的问题,我喜欢叫它“逻辑侦探”,它的核心是“理解关系+深度推理”
光靠文本检索有时候是不够的,因为很多知识的价值隐藏在实体之间的关系里,比如“A公司是B公司的供应商,B公司又是C项目的承包商”,当C项目出了问题,可能需要追溯到A公司的某个批次的产品,这种跨越多层关系的推理,传统RAG就很难做到
Graph RAG是怎么做的呢,它在构建知识库的时候,不只是简单地把文本存起来,而是会先通过技术手段,把文本里的实体(比如公司、人、产品、事件)和它们之间的关系(比如拥有、投资、属于)提取出来,构建成一张巨大的“知识图谱”,就像一张复杂的人际关系网
当用户提出一个复杂问题时,系统不只是在文本里搜索,更是在这张图谱上进行游走和推理,寻找答案路径,这就让AI具备了逻辑分析能力
这种形态特别适合复杂的B端分析场景,比如一个大型工厂的设备故障根因分析,知识图谱可以关联设备信息、维修记录、传感器数据、操作员日志,当一个故障发生时,AI可以像个侦探一样,在图谱上寻找所有可能的关联因素,最终定位到最可能的原因
金融风控也是一个绝佳的场景,通过构建企业和个人之间的投资、担保、交易关系图谱,Graph RAG可以发现隐藏的关联交易、欺诈团伙,这种能力是传统风控模型很难具备的
对了,还有社交网络的内容理解,通过分析用户、话题、帖子之间的关系,可以更好地进行内容分发和社群发现,理解一个梗的前因后果,或者一个热点事件的传播路径
“逻辑侦探”的强大之处在于,它让AI从一个“文员”升级成了一个“分析师”,能够处理跨文档、跨数据的复杂逻辑问题,它的核心是知识图谱的构建质量和图查询推理算法的效率
Agentic RAG “主动管家”
这是目前最前沿,也是最令人兴奋的形态,我称之为“主动管家”,它的核心是“任务拆解+自主执行”,它彻底颠覆了“一问一答”的模式
“主动管家”面对的不是一个简单的问题,而是一个复杂的目标,比如用户说,“帮我规划一个下周末去海边城市的两天一夜旅行,预算一千块以内,要包括往返交通和住宿”,你看,这不是一个能直接在知识库里找到答案的问题
Agentic RAG会怎么做呢,它会像一个真正的管家一样,把这个大任务拆解成一系列小步骤,查询知识库获取旅行攻略和城市信息,调用外部工具比如机票查询API、酒店预订API,获取实时数据,根据预算进行筛选和组合,甚至在发现某个方案不可行时,会主动调整策略,比如建议用户更换目的地或者调整出行时间,最后,它会把一个完整的、可执行的旅行方案呈现给用户
这种形态赋予了产品“主动性”,它不只是被动地回答,而是能够主动地规划、调用工具、执行任务,并从执行结果的反馈中学习和调整
除了个性化旅游规划,智能投顾助手也是一个很好的例子,用户设定一个理财目标和风险偏好,AI Agent可以主动分析市场行情,调用交易API,构建和调整投资组合,并定期生成报告
还有自动化营销活动策划,运营人员只需要提出活动目标,比如“提升新用户注册量百分之二十”,AI Agent就可以自动策划活动方案、生成宣传文案和图片、配置活动页面、甚至对接广告投放渠道
“主动管家”的出现,标志着AI产品从“问答”到“解决复杂任务”的跃迁,它让AI真正成为了一个能干活的“数字员工”,它的核心在于任务拆解的逻辑能力、工具(API)的丰富程度以及从反馈中学习的闭环机制
这三种形态,从“精准助理”到“逻辑侦探”再到“主动管家”,代表了RAG技术在产品化道路上的进化路径,它们不是互相替代的关系,而是适用于不同深度和复杂度的业务场景,作为产品经理,看清这张地图,才能为自己的产品找到最合适的智能化升级路径
四、落地蓝图——从洞察到上线:RAG产品的四步实践框架
好了,聊完了理念和形态,最关键的问题来了,我们团队到底该怎么动手做呢,毕竟想法再好,落不了地也是白搭,根据我踩过的一些坑和总结的经验,我梳理了一个从零到一引入RAG的四步实践框架,希望能给你一些参考,让你少走点弯路
第一步 精准诊断业务痛点(你的产品真的需要RAG吗)
这是最重要的一步,也是最容易被忽略的一步,很多团队看到新技术就兴奋,一头扎进去,最后发现做的东西根本没人用,所以在动手之前,一定要先问问自己,你的产品,你的用户,真的需要RAG吗
我给你一个简单的自查清单,你可以对照着看看
你的用户是不是经常问一些重复性的、有固定答案的问题,比如客服场景,如果百分之八十的工单都是关于那几个常见问题的,那RAG的价值就很大
你的产品是不是依赖大量、动态变化的知识,比如金融资讯、电商商品信息、法律法规,如果知识更新不及时会造成严重后果,那RAG的实时性就是救命稻草
用户在使用你的产品时,是不是需要强有力的证据来支撑决策,比如在B端软件里,AI给出的一个分析结论,用户需要知道这个结论是基于哪些数据得出的,RAG的可追溯性就能建立信任
你公司内部是不是有大量的知识文档沉睡在各个角落,无法被有效利用,导致员工重复造轮子,效率低下,那用RAG构建一个内部知识库,价值就非常明显
如果以上问题你的答案大部分都是“是”,那恭喜你,引入RAG大概率是个正确的方向,如果不是,那你可能需要再思考一下,别为了用AI而用AI
第二步 定义成功与约束(明确目标与边界)
确定要做之后,千万别急着写代码,第二步是坐下来,和你的团队一起,把目标和边界想清楚,你要明确,这个RAG产品做出来,要达成一个什么样的效果才算成功
这个成功指标一定要是可量化的,不能是“提升用户体验”这种虚无缥缈的话,可以是“将客服工单的平均响应时间从5分钟降低到30秒”,可以是“将用户自助解决问题的比例提升百分之三十”,也可以是“新员工入职后,关于流程问题的提问次数减少百分之五十”,把这些指标定下来,就是你未来衡量项目成败的尺子
同时,也要识别出你的约束条件,做产品不是天马行空,总要考虑现实,你的技术团队对RAG的技术栈熟悉吗,需要学习成本吗,你的数据从哪里来,质量怎么样,需要花多少人力去清洗和标注,你的预算有多少,能支持多大规模的计算资源和模型调用,把这些约束条件列出来,能帮你在一开始就设定一个合理的预期,避免项目进行到一半才发现资源不够
第三步 小范围试点与快速验证(用最小MVP跑通闭环)
目标和约束都清楚了,现在可以动手了,但我的建议是,不要一上来就想搞个大而全的系统,那样周期太长,风险太高,正确的做法是,选择一个独立的、高价值的细分场景,做一个最小可行产品(MVP),快速跑通一个完整的闭环
比如,你想做一个全功能的电商客服机器人,那你的MVP可以只聚焦在“售后政策问答”这一个点上,这个场景用户痛点明确,知识范围也相对封闭,就是那几份售后政策文档,实现起来相对简单
你的目标就是用最快的速度,把这个小功能上线,让一小部分真实用户用起来,然后密切关注你之前定下的那些指标,比如答案的准确率、用户的满意度、对人工客服的求助率有没有下降,收集用户的反馈,看看他们觉得哪里好,哪里不好
这个阶段的核心就是“快”,快速迭代,快速验证,可能你第一个版本的表现很糟糕,没关系,根据反馈马上调整,是检索没做好,还是模型生成能力不行,或者是知识库文档本身就有问题,定位问题,解决问题,再上线,再验证,通过这样几轮小步快跑,你就能用最小的成本,验证RAG在你的业务场景里到底行不行,以及怎么做才能行
第四步 规模化扩展与持续优化(从功能到平台)
当你的MVP在试点场景被证明是成功的,数据和口碑都很好,那就可以进入第四步,考虑规模化扩展了
扩展可以有两个方向,一个是横向扩展,把你在“售后政策问答”上验证成功的经验,复制到其他客服场景,比如“物流查询”、“活动咨询”等等,逐步覆盖所有客服领域,另一个是纵向扩展,思考如何把这个RAG能力平台化,抽象成一个通用的知识问答服务,不仅能支持客服,还能支持公司的销售、法务、人事等其他部门
在规模化的同时,一个更重要的事情是建立一个持续优化的机制,RAG产品不是做完上线就结束了,它是一个需要持续运营和喂养的东西,你需要建立一个反馈闭环,比如在每个答案后面加一个“赞”或“踩”的按钮,对于用户“踩”的答案,要有人工去分析原因,并去优化知识库或者模型,你还需要有一个机制,让业务部门可以方便地更新和维护知识库,保证知识的实时性
从一个单点功能,到一个产品矩阵,再到一个能力平台,这是一个漫长的过程,但只要你遵循这四步走的框架,先诊断,再定义,后试点,终扩展,就能走得更稳,更远

五、前瞻与挑战——下一代互联网产品的“RAG+”想象
聊到这里,我们对RAG的现在和落地已经有了比较清晰的认识,但作为产品人,我们的眼光总要看得更远一些,RAG的终点在哪里,它还会和什么东西结合,催生出怎样我们现在还无法想象的新物种,这才是最让人兴奋的地方
未来趋势
我个人非常看好一个趋势,就是RAG与微调(Fine-tuning)的深度结合,现在我们谈RAG,好像和微调是两条路,一个“开卷”,一个“闭卷”,但未来,最强的模型一定是既会“开卷”又会“闭卷”的学霸
这是什么意思呢,我们可以通过微调,让模型深度学习一个行业的“行话”、思维模式和沟通风格,比如让它学习海量的医疗文献和病历,让它具备一个医生的“语感”和逻辑,这是内化到模型里的“行业逻辑”,是它的“内功”
而RAG,则为这个有“内功”的模型,提供实时的、具体的“外部知识”,比如最新的药品信息、临床指南,当一个问题进来,模型既能用专业的口吻和逻辑去分析,又能引用最新的证据来回答,这就完美结合了微调的“深度”和RAG的“广度”与“时效性”
基于这种“RAG+”的思路,我们可以畅想一些全新的产品形态,比如“个人数字孪生知识库”,想象一下,一个AI,把你读过的所有文章、写过的所有文档、所有的聊天记录、邮件都作为它的知识库,它比你自己还了解你的知识体系和思考习惯,当你需要写一份报告或者做一个决策时,它能立刻为你提供最相关的背景资料和你自己曾经的思考,这会成为我们每个人的“第二大脑”
再比如“实时协作的AI白板”,在一个团队进行头脑风暴的会议上,大家在白板上随意涂写想法,AI在后台实时理解讨论的内容,并主动从公司的知识库、项目文档、甚至是互联网上,把相关的数据、案例、图表推送到白板上,为讨论提供事实依据和灵感火花,这会让协作的效率和深度发生质变
直面挑战
当然,未来是光明的,但通往未来的路总是充满挑战,RAG产品化也不是一帆风顺的,有几个核心的难题,是我们现在就必须正视和思考的
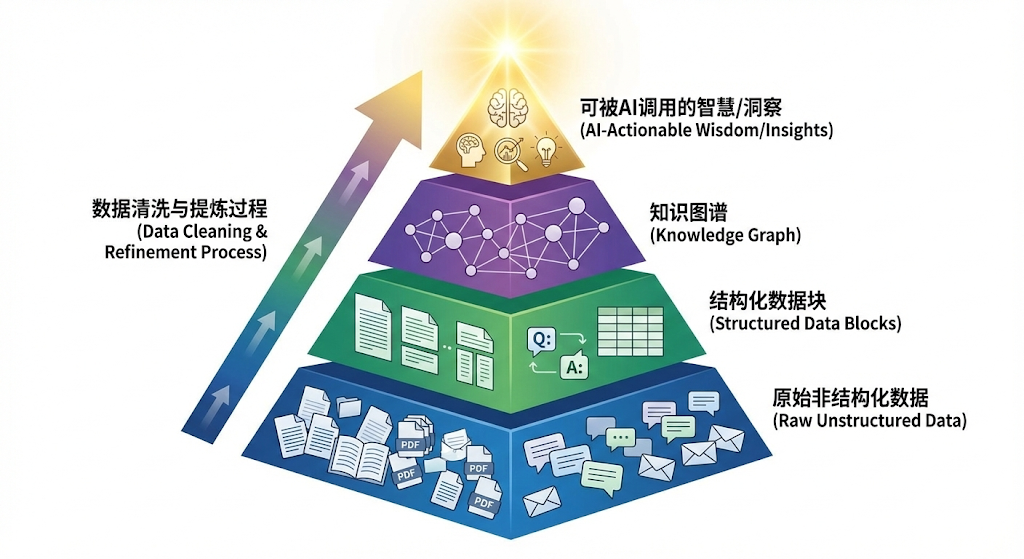
最大的挑战,我认为是“知识库建设”,RAG的效果,上限就是由你知识库的质量决定的,垃圾进,垃圾出,如何构建和维护一个高质量、低噪声、结构化的知识库,是一个巨大的工程,这需要我们思考如何设计一个“知识资产金字塔”,从底层的原始文档,到中间层的结构化数据,再到顶层的知识图谱,如何自动化地完成这个构建过程,如何激励业务专家参与到知识的贡献和审核中来,这都是非常棘手的问题
另一个是“评估难题”,怎么量化一个RAG产品体验的好坏,这比评估传统软件要复杂得多,答案的准确率只是一个维度,我们还要考虑它的相关性、完整性、时效性、语言的流畅度,甚至答案的“同理心”,目前业界还没有一个统一的、公认的评估框架,很多时候我们还是依赖人工抽检,这既不高效也不客观,建立一套科学、自动化的评估体系,是RAG产品走向成熟的关键一步
对了,还有“工程复杂度”,一个完整的RAG系统,涉及文档加载、切分、向量化、存储、检索、模型生成等多个环节,每个环节都有很多技术选型,如何把这些组件稳定、高效、低成本地组合在一起,本身就是一个复杂的系统工程,尤其是在规模化之后,系统的稳定性和成本控制会成为巨大的挑战
给从业者的建议
面对这些趋势和挑战,我想对同行的朋友们说,RAG带来的不仅仅是技术架构的升级,它对我们产品经理的能力模型提出了新的要求
我们不能再只盯着界面和流程了,我们需要向下,去理解数据,去思考知识,我们需要具备“数据架构师”和“知识工程师”的思维,你要去思考你产品的核心知识是什么,它们以什么形式存在,如何把它们变成AI可以理解和利用的资产,你要去设计知识的流转、更新和反馈机制
这场从“闭卷”到“开卷”的变革才刚刚开始,它会像移动互联网一样,深刻地重塑每一个互联网产品的形态和价值,我的建议是,不要再观望了,现在就开始,从你自己的产品出发,去思考它的“知识战略”是什么,哪怕只是做一个小小的MVP,去感受这个过程,去积累你的经验,因为在不远的将来,一个产品的竞争力,很大程度上将取决于它驾驭自身知识的能力
本文由 @云端写信 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


