
 起点课堂会员权益
起点课堂会员权益没人敢先停:AI 囚徒困境如何困住大模型、巨头和普通人
五一快到了,先祝大家节日快乐。也真心希望,这几天我们可以好好休息一下。
对我们这些打工人来说,真正奢侈的可能已经不是假期,而是确定感。我们休息的这几天,模型不会停,公司不会停,行业不会停。老板还在算成本,投资人还在看效率,竞争对手还在用 AI 压缩人力。
假期只是暂停了你的工作,没有暂停这场竞赛。

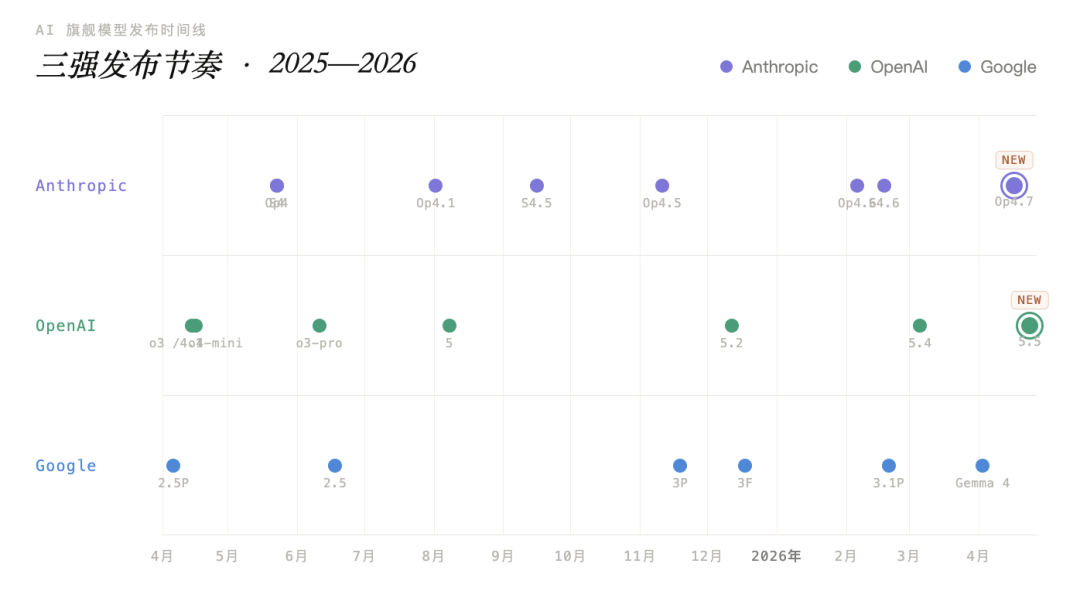
在过去的4月下半旬,三个顶级模型接连发布。4月16日,Claude Opus 4.7上线。7天后,GPT-5.5发布。过了24小时,DeepSeek V4横空出世。
reddit上有个帖子,标题是:”gpt-5.5 dropped today and the ai race just got genuinely unhinged”。
“unhinged,失控了”。这场AI军备竞赛早就不只是几家 AI 实验室之间的较量,更像是一场没有退出机制的囚徒困境。每一个玩家都知道继续跑下去代价巨大,但没有人敢停下来。并且这种恐惧,正在沿着产业链向下渗透:从AI实验室,到硬件,到大厂,到中小公司,最后落到每一个还凭着某种专业技谋生的普通人。

一、囚徒困境:没人敢先停
发布就是开火:AI 公司不再只是更新产品,而是在制造压力
先说一组数据:OpenAI在过去8个月内,发布了5个主要模型。GPT-5.1、GPT-5.2,到 GPT-5.3-Codex、GPT-5.4,再到 GPT-5.5。每一次发布都伴随着全网评测、媒体刷屏、用户重新选边站队。
这个节奏,在2022年是不可想象的。那时候,一个大模型发布,市场能消化半年。GPT-4发布后,所有人花了几个月时间摸清它的能力边界,构建产品、探索用例。那段时间里,”理解这个模型”本身就是有价值的工作。
现在三大实验室的旗舰模型更新周期,已经压缩到”每几周”一次。2025 年,一个模型上线后,至少还能独占几周的讨论窗口。但到了 2026 年第二季度,这个窗口被压缩了:几个模型几乎前后脚发布,刚上线就会被放在同一张表里横向比较。
每家公司都在做理性选择,整个行业却一起失控
囚徒困境的核心是:明明合作对大家都好,但因为谁也不能保证对方会合作,所以每个人都会先选择保护自己,最后一起走向更差的结果。
AI的军备竞赛就是这个结构;假设Anthropic、OpenAI、Google三家同时停下来,不发布新模型,专注降本和商业化;理论上烧钱压力大幅降低,整个行业节奏会健康很多。研发团队能充分打磨当前代的产品,客户能稳定地使用建设工作流,生态能真正成熟。
但实际是只要有一家先慢下来,问题就来了。它可能只是想压缩成本,把产品做稳,把商业化跑通。但在今天的 AI 牌桌上,市场未必会这么解读。媒体会问它是不是技术动能不足,投资人会担心估值故事失速,客户会重新评估降低风险,人才也会开始观察谁更像下一代入口。

Meta 不是例外,而是这场竞赛最清楚的样本
Meta的旗舰模型原定2026年3月发布,但因为内测表现落后于御三家现役模型,被推迟到5月甚至更晚。更关键的是,Meta内部还讨论过,是否临时授权使用Google Gemini,来撑住Instagram、WhatsApp、Facebook里的AI功能。
一家公司一年计划投入1150亿到1350亿美元做AI基础设施,却仍然可能需要借竞争对手的模型过渡。足够体现:AI军备竞赛已经卷到什么程度。
这就是囚徒困境最残酷的地方:加大投入不一定保证领先,但减少投入必然落后。
二、窗口缩短:领先时间越来越短
没有全能模型,只有短暂领先的单项能力
4月下旬,当三家顶级实验室的旗舰模型同时摆在台面上。
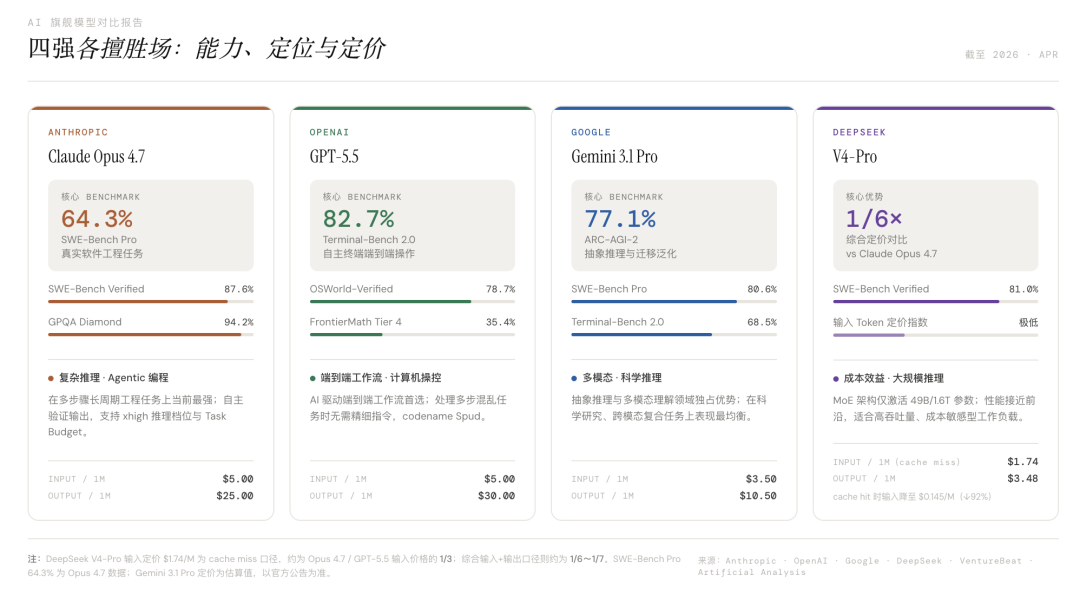
现在的模型竞争,已经很难用“谁第一”来概括:Claude 更像工程师,强在代码和复杂编程;GPT-5.5 更像执行者,强在自主操作和端到端工作流;Gemini 更像研究员,强在多模态、科学推理和抽象问题;DeepSeek 则把成本的桌子给掀翻了。
所谓领先,正在变成一件分任务、分场景、分成本结构的事。AI赛道没有冠军,只有不同战场上的局部优势。
今天的领先,很快就会变成明天的标配
更要命的是,即使在某个维度短暂领先,这个窗口也越来越短。
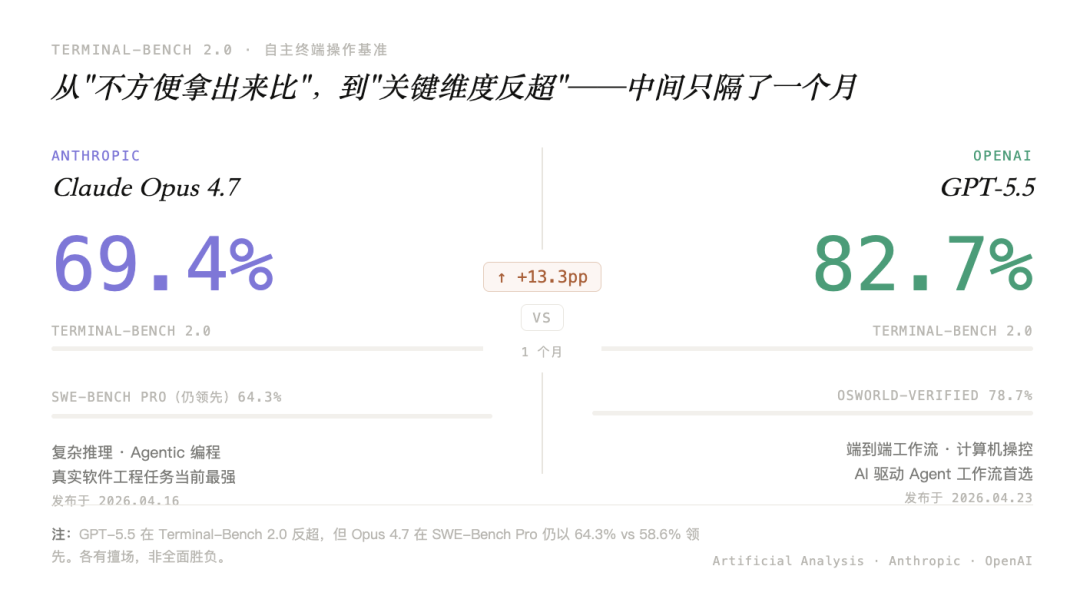
SemiAnalysis 的分析师说了一个细节:OpenAI 在 GPT-5.4 发布时,几乎没有放出和 Anthropic 的正面对比数据。他们判断:一旦摆出来,GPT-5.4 很可能会被 Opus 4.6 打得很难看。
GPT-5.5 发布后,在 Terminal-Bench 2.0 这个自主终端任务 benchmark 上,GPT-5.5 拿到 82.7%,反超 Opus 4.7 的 69.4%。从“不方便拿出来比”,到“在关键维度反超”,中间只隔了一个月。
这才是这场 AI 竞赛最可怕的地方。它正在破坏一个过去很常见的判断:技术领先,可以慢慢转化成商业护城河。
今年HumanX会后流传最广的一句话,几乎概括了整个行业的情绪:去年,OpenAI是公认的赢家。今年,Anthropic被认为领先一大截。明年?没有人敢下注。
Meta 还没追上这一轮,下一轮已经开跑
Avocado 延期还有一个细节:Meta 内部已经在推进下一代模型,代号 Watermelon。也就是说,这一代模型还没发布,下一代已经上路了。
这已经不是正常的产品迭代,而是追赶压力倒逼出的研发结构。过去的节奏是:发布一代,收集反馈,稳定运行,再启动下一代。现在变成了:当前代还没发,下一代已经在跑;下一代还没发,下下代已经立项。研发流水线从串行变成了并行。
代价也很清楚:每一代留给打磨的时间越来越少,bug 和体验问题来不及修,用户看到的是功能不断增加,但稳定性不断被透支。

三、卖铲子的人,也有自己的焦虑
英伟达的悖论:越是受益,越要防守
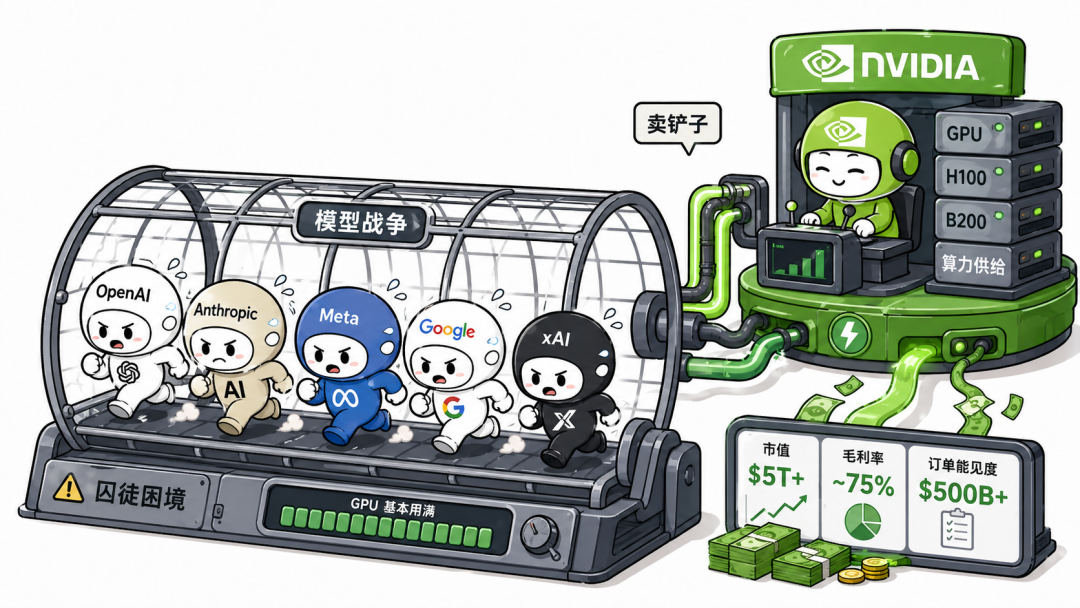
如果说 AI 军备竞赛有一个确定的受益者,很多人第一反应会是英伟达。
它确实是受益者:英伟达市值已经突破5 万亿美元,毛利率维持在75% 左右,2025—2026 年 AI 芯片订单能见度被市场解读为超过5000 亿美元。这已经不像一家普通科技公司,更像是垄断了军备供应链的军火商。
黄仁勋说:不要押注谁会赢,而是让所有可能赢的人都离不开你。OpenAI、Anthropic、Meta、Google、xAI,都需要更多 GPU、更大集群、更高算力。只要模型战争继续,英伟达就继续卖铲子;只要实验室继续烧钱,英伟达就继续收钱。
所以表面上,英伟达是这场 AI 军备竞赛的最大受益者。更准确地说,它是这场竞赛的底层供给方。它没有被困在囚徒困境里,它在维持那个让所有人都继续奔跑的囚笼。
从“唯一选择”到“重要选择”,护城河正在变窄
黄仁勋真正警惕的,不是GPU卖不出去,而是“必须用Nvidia”这件事开始松动。主要是这三个方向。
第一是软件层。DeepSeek V4开始适配华为昇腾等非Nvidia硬件,说明前沿模型不再天然绑定CUDA生态。CUDA仍然强,但它第一次被更系统地放到“可替代”的讨论里。
第二是客户层。Anthropic已经不是单押Nvidia:一边拿AWS Trainium容量,一边签Google和Broadcom的TPU合作。OpenAI也在推进与Broadcom的定制芯片合作。最大的几个AI买家,正在主动把算力来源拆成多条线。
第三是市场层。Broadcom 2025财年AI收入达到200亿美元,同比增长65%。它吃到的,正是大客户寻找“非Nvidia方案”的需求。

所以,Nvidia现在的投资动作,不能只看成财务投资。投Anthropic,是把下一代模型公司继续绑在Nvidia生态里;投Synopsys,是向芯片设计工具链更深处延伸;继续争取中国市场,是在政策夹缝里保住规模。
四、开源模型正在拆闭源模型的地基
价格锚点下移,闭源模型必须证明价值
DeepSeek V4的发布,给整个行业的价格给掀翻了;VentureBeat算过一笔账:一个用GPT-5.5大约要花35美元的任务,用DeepSeek V4只要5.22美元。虽然它在SWE-Bench Pro上还有差距,55.4%低于Opus 4.7的64.3%。
对大量生产场景来说,问题从来不是“我要不要最强模型”,而是“这个模型够不够用,以及能不能高频调用”。
V4-Flash更进一步,cache hit输入价格低到每百万token 0.028美元。对于长期挂在代码库、知识库、业务系统里的agent来说,这个价格意味着一件事:AI不再只是被偶尔调用的高级能力,而开始接近一种可以常驻运行的基础设施。
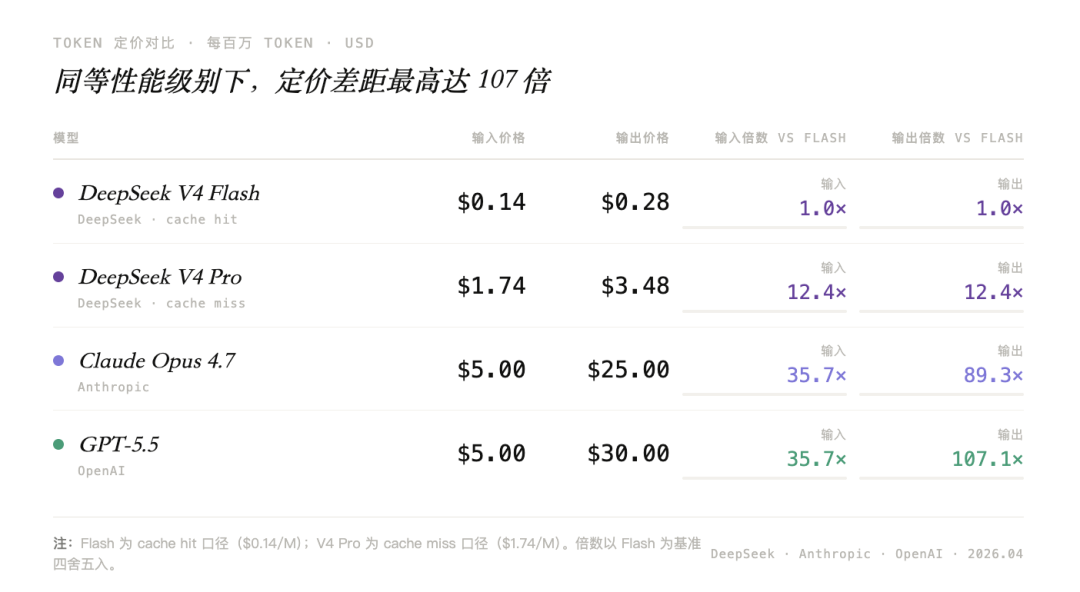
开源能压价,但未必能赚钱
这里有一个更现实的问题:开源 AI 还没跑通清晰的商业模式。Meta 的 AI价值,更多藏在广告、用户时长和生态粘性里,很难像 Anthropic、OpenAI 那样,单独拆出一条明确的收入曲线。
企业市场也没有真正倒向开源。Menlo Ventures 2025 年调研显示,开源 LLM 在企业生产环境中的占比只有11%,低于上一年的19%。真到生产环境,企业更看重支持、合规、稳定性和责任归属。
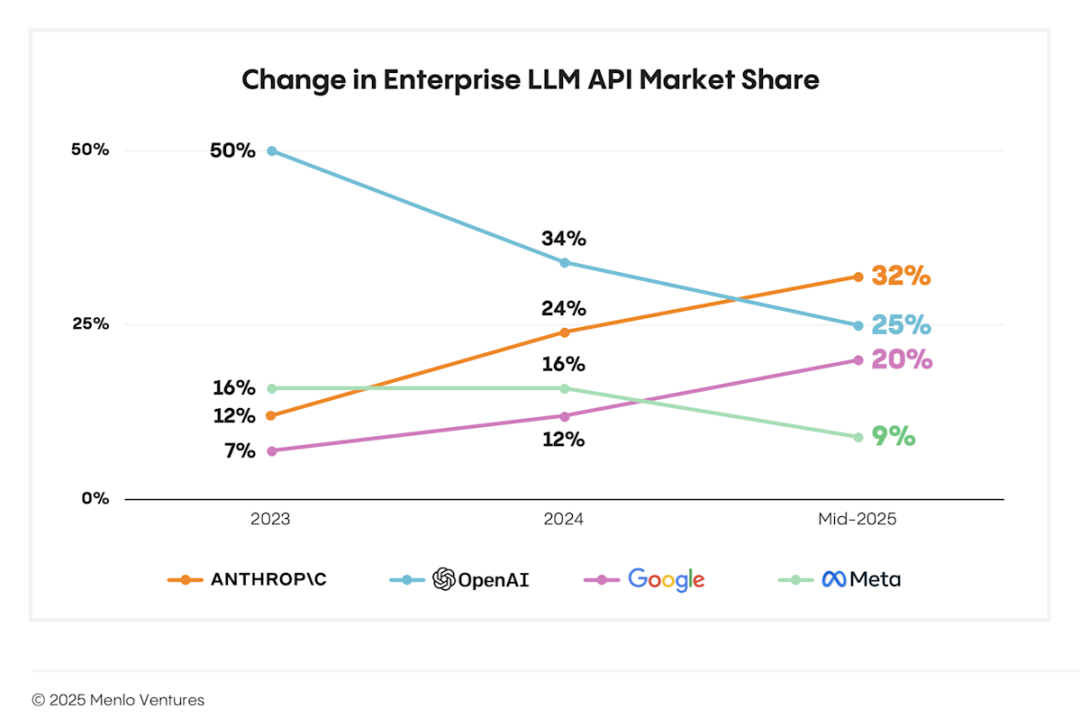
开源的威胁不在赚钱,而在压低闭源定价权:开源模型本身未必已经跑通商业模式,但只要能力足够接近,就会削弱闭源模型的高溢价空间。
闭源必须从模型领先,转向产品和生态锁定:如果开源追赶窗口缩短到 6 到 12 个月,闭源就不能只靠能力领先收费,而要把能力沉淀成稳定产品、企业服务和更难替换的生态。
五、恐惧沿着产业链一路下沉
竞赛的压力不会只停留在AI实验室和芯片公司。它会沿着产业链向下传导。传导路径有三个层级,每一层的恐惧结构都不一样。
大厂争入口:谁掌握用户起点,谁就掌握下一代分发
对大厂来说,真正的恐惧不是模型不够强,而是AI 入口被别人拿走。
Google 靠 Search,Microsoft 靠 Office 和 Azure,Apple 靠 iPhone,Meta 靠 Instagram、WhatsApp 和 Facebook。这些入口,是用户每天打开数字世界的起点,也是广告、订阅和数据的根基。

AI 正在改变这个起点,用户直接问 ChatGPT,Google Search 的流量会被分走;开发者用 Claude Code,GitHub Copilot 的黏性会被削弱;企业直接找 Anthropic 采购,微软 Azure 的中间位置也会变尴尬。
大厂最怕的,是用户打开手机后的第一个动作,不再是搜索、社交、办公软件,而是某个 AI 原生应用;入口一旦被绕过,广告、订阅、数据和生态都会松动。
中小公司被夹击:能力被集成,场景被收编
中小公司面对的是另一种恐惧:你的核心竞争力,可能正在被模型厂商原生集成。
过去很多 AI SaaS 的机会,是把 GPT、Claude 包进一个具体场景里,比如写报告、审合同、做数据分析、查代码。
但现在模型厂商自己也在补这些能力。研究报告、表格处理、代码审查、浏览器操作,这些原本可以撑起一个垂直产品的功能,正在被大模型原生集成。
“AI 套壳”的窗口期正在变短,这个模式能成立,是因为模型过去不够懂场景,所以创业公司还能靠体验优化和场景适配赚钱。但随着模型能力扩展,只做一层包装的产品会越来越危险。模型一升级,原本的卖点就可能变成基础能力。
真正的出路在行业纵深,中小公司不能只卖“AI 能力”。能留下来的,是行业数据、复杂流程、客户关系、交付经验,以及别人复制起来不划算的场景深度。
普通人被挤压:入门岗位变少,成长路径变窄
个体焦虑:入门岗位正在变少
AI 对就业的影响,最先体现在新人身上。过去,软件开发、客服、分析、法务、产品助理这类岗位,会把大量基础工作交给新人:整理资料、写初稿、做报表、查问题、跑流程。
现在,这些工作越来越多被 AI 接走了。企业还在招人,但更愿意招能够直接驾驭 AI 的成熟员工。新人进入行业的台阶,正在变高。
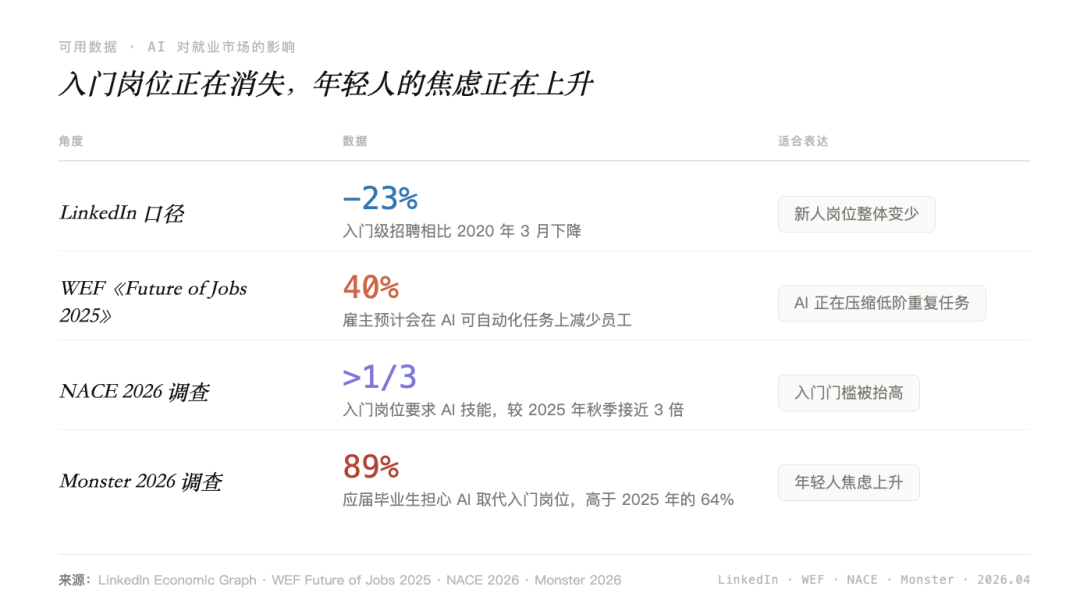
更深的焦虑:积累可能随时贬值
Fortune 把这种焦虑叫作FOBO:Fear of Becoming Obsolete,也就是害怕自己变得过时。这个词说的是一种很现实的感受:我今天学的东西,还能值多久?
你刚学会一个工具,下一个模型可能已经原生支持了。你刚掌握一个工作流,新的 Agent 可能已经自动完成了。你刚建立起某项技能,下一次产品更新可能就把它变成默认功能。
于是很多人会卡在一种状态里:不学会掉队,学了又不知道能用多久。
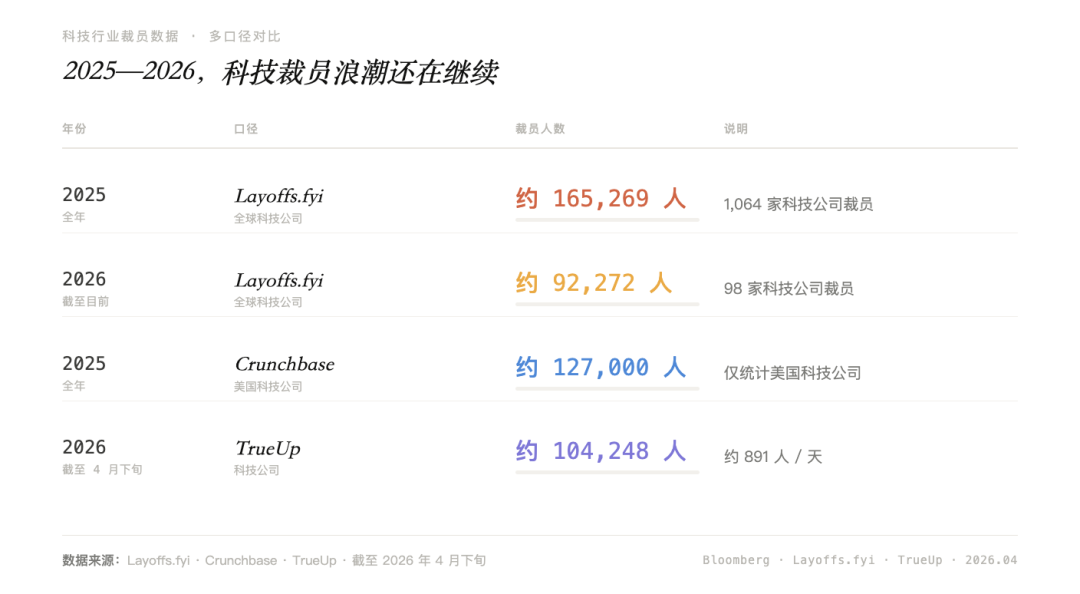
结构性问题:人才培养通道正在变窄
初级岗位不只是公司的执行层,也是人才训练场。法务新人靠看合同,慢慢学会判断风险。产品新人靠写需求、参加评审,慢慢理解用户和业务。财务新人靠做报表,慢慢看懂数字背后的经营逻辑。
这些基础工作看起来琐碎,却是高级判断力的来源。如果 AI 接走大量初级任务,企业短期效率会提高,但年轻人也会失去从基础工作里积累经验的机会。
今天没有新人可培养,十年后哪里来的高级人才?这才是 AI 对就业最深的影响:它在加速传统人才培养路径的塌陷。
六、当所有人都在跑,真正重要的是找到自己的位置
这场竞赛短期内停不下来。每个参与者都看到了问题,但在没有外部约束的情况下,谁都不敢先慢下来。AI 竞赛最难解的地方就在这里:单个玩家看得见风险,却没有能力单方面改变游戏规则。
全球范围内已经有 AI 监管讨论,但共识还没有真正形成。即便框架出现,落地也需要时间。在那之前,这场竞赛大概率还会继续加速。
有一件事值得想清楚:速度决定短期位置,深度决定长期价值。大厂赌的是分发入口和用户习惯;中小公司要守住的,是具体场景里的行业纵深;个人真正能沉淀的,是判断力、品味,以及人与人之间的信任。
竞赛不会停下来,我们不一定要赢下这场竞赛。真正要做的,是找到那个跑步机替代不了的位置。
本文由 @AI进化论 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


