
 起点课堂会员权益
起点课堂会员权益做完一个AI产品,我重新理解了PRD这件事
AI翻译将「临床3期」误翻成「临床2期」的惊险案例,揭示了AI产品设计的根本挑战——如何在不确定性中构建可靠系统。文章从医药行业的致命错误出发,深度剖析7条AI产品PRD撰写心法,包括流动文档管理、显式技术权衡、内置错误闭环等颠覆性思路,为应对AI的「一本正经胡说八道」提供了可落地的解决方案框架。

有一天我在做翻译核对。原文写的是Phase III clinical trial,AI 给我翻成了「临床 2 期」。
我看到的瞬间。。。冒冷汗。
懂点医药的朋友应该知道这事儿有多严重。临床 2 期是小范围疗效验证,几十到几百人;3 期是大规模确证试验,上千人,是产品上市前的最后一关。监管文件里 2 和 3 弄混,是要出大事的。
而且这玩意,扫一眼就过去了。2 和 3 就一个字之差。

幸好我们做了双模型审核,幸好我们加了[需确认]标注,这个错误在质检环节被拦了下来。
但问题来了。
如果 AI 就是会犯这种错而我们还在用它,这个产品到底要怎么设计才能不出大事?
更进一步,一份AI产品的PRD要写成什么样,才能容纳「AI会犯错」这种根本现实?
这个问题不是医药特有的。
ChatGPT 会一本正经胡说八道,Cursor 会写出能跑但有 bug 的代码,Midjourney 会画出六根手指的人手,Perplexity 的引用偶尔指向不存在的链接。
每个AI产品都在面对同一件事——模型是不确定的。
而所有传统软件 PRD 的写法,底层假设都是「程序是确定的」。
这两件事一对上,就出问题了。
简单交代下背景。我做了一个AI 翻译 Agent,迭代到 V3,用户修改率从 35% 一路压到了 12%,Bad Case 池累计 47 条。
今天想聊的不是这个产品本身,是我做这个产品的过程里,硬磨出来的一份 PRD。
坦率的讲,我以前没怎么写过 PRD。模板是大语言模型给我整的,框架是网上扒了一堆「优秀 PRD 范例」拼起来的。
但写到一半我就发现,按那些范例的写法做 AI 产品根本不够用。功能列表、用户故事、流程图,写得再齐再完整,也回答不了「AI 会犯错怎么办」这种问题。
我后来一边做产品一边改 PRD,磨出来7 条心得。每一条都对应着一个我从「传统 PRD 那套」往「AI 产品 PRD」转弯的瞬间。
可能有些想法还不成熟,但已经毫无保留地掏给你了。能用上一两条,这篇就没白写。
1. 传统 PRD 写完就归档,AI 产品 PRD 是流动的
传统软件 PRD 的标准生命周期你应该熟,定义需求、开发、测试、上线、归档。归档之后这份文档基本就死了。
AI 产品的 PRD 不能这么搞。
我那份 PRD 的 Prompt 章节有一个完整的 Changelog,从 v1.0 到 v3.0,每个版本改了什么、为什么改、改完什么效果,全部留痕。某个版本是因为踩了一个编号错译的坑,加了数字校验规则。某个版本是用户反馈翻译不够「专业」,把角色描述细化了。某个版本是用户修改率到 22% 还降不下去,干脆加了独立的审核 Prompt。
为啥要这么写?
因为 AI 产品的所有东西都是流动的。
模型在变——DeepSeek 每月都有更新,Claude 几个月一个大版本,今天调好的 Prompt 明天换模型就可能失效。数据在变——知识库每周加新内容。用户认知也在变——他们用得越久对你产品的预期越高。
如果你的 PRD 只是产品上线前那一瞬间的快照,三个月后就是废纸。
我之前以为PRD是写给开发看的,后来发现,最受益于这份PRD的人是几个月后的我自己。AI产品迭代快,你三个月前为啥做这个决策,三个月后自己都可能忘。一份持续更新的PRD,是你给未来的自己留的护栏。
可执行的动作就一句:把PRD当成日记。每次改Prompt、每次切模型、每次发现Bad Case,都在PRD里同步留痕。
学习成本是,你得克服「PRD写完就交差」的心理惯性。说真的一开始我也烦,但坚持了一个月之后,再回看v1.0那个版本,跟看一个陌生人写的东西一样——那时候我就不烦了。
2. 传统 PRD 写「我要做什么」,AI 产品 PRD 写「我为什么不做另外那几个」
这一条我觉得是最反直觉的。
大部分人写 PRD,主体就是一份功能清单。F-01 做啥、F-02 做啥、F-03 做啥。开发看了知道做啥,老板看了知道你交付啥,齐活。
但AI产品PRD里最值钱的章节不是功能清单,是「显式权衡」。
把你评估过的所有方案、为什么不选另外几个、什么条件触发你换方案,全部写出来。
我那份 PRD 里花了一整章做这个事。光是术语注入这一个小决策,就有 RAG vs Prompt 注入两个方案。技术上 RAG 肯定更「高级」,但我那时候术语库才 100 多条,做 RAG 得搭向量库、做 Embedding,每次调用还多一次成本。Prompt 注入虽然 low,但在 100 条规模下完全够用。所以选了 Prompt 注入,并且写明:等术语库到 500+ 条时再切 RAG。
这事儿适用于所有 AI 产品。
你做对话 Agent,要不要上 Function Calling?要不要做记忆?记忆用向量库还是结构化数据库?你做 AI 写作工具,要不要做多模型路由?长文用 Claude 短文用 GPT 还是反过来?你做代码助手,要不要做 RAG 索引整个代码库?
每个决策都不止一种方案,每种方案都各有优劣,而且最优解会随着规模、成本、模型能力的变化而变。
这事儿在传统软件里没那么严重——传统软件的方案空间是收敛的,你做个 CRUD 网页技术栈翻不出花来。但 AI 产品的方案空间是发散的,今天最优明天可能就不是了,所以必须把当时的判断逻辑写下来。
为啥?因为 AI 圈每隔一段时间就会有人冒出来问,「你为什么不用 RAG?」「你为什么不微调?」「你为什么不上 Agent 框架?」如果你写 PRD 的时候没把权衡记下来,每次有人问你都得重新论证一遍,自己都开始怀疑自己。
可执行的动作是,每一个技术决策旁边都写一段「我评估过哪些方案,每个方案的优劣,我为什么选这个,什么条件触发我换」。哪怕只有三行字。
学习成本是,很多人懒得写,觉得是浪费时间。但相信我——三个月后你会忘,半年后你会感谢自己。
3. 传统 PRD 可以不为 bug 留位置,AI 产品 PRD 必须内置错误管理机制
回到开头那个临床 2 期 3 期的故事。
那个错误是我自己发现的。我作为产品的 owner,同时也是高频使用者。那天扫到「Phase III」被翻成「临床 2 期」,整个人愣住了。
冒冷汗那种愣住。
这种事不只在医药里。
ChatGPT 会编造不存在的论文引用。Cursor 会生成看似正确但有越界访问 bug 的代码。Midjourney 会画出六根手指的人手。
每个 AI 产品都会犯错——区别只在错误的代价大小。
传统软件出 bug 是异常事件,是要修复的目标。所以传统 PRD 里没有「bug 管理」这章节,bug 管理是开发上线后的事。
AI产品出错是常态,是必然事件。这就要求你在PRD里就明确「错误如何被捕获、归因、修复,并且不再发生」。
这就是为什么AI产品PRD必须有Bad Case池这一章。
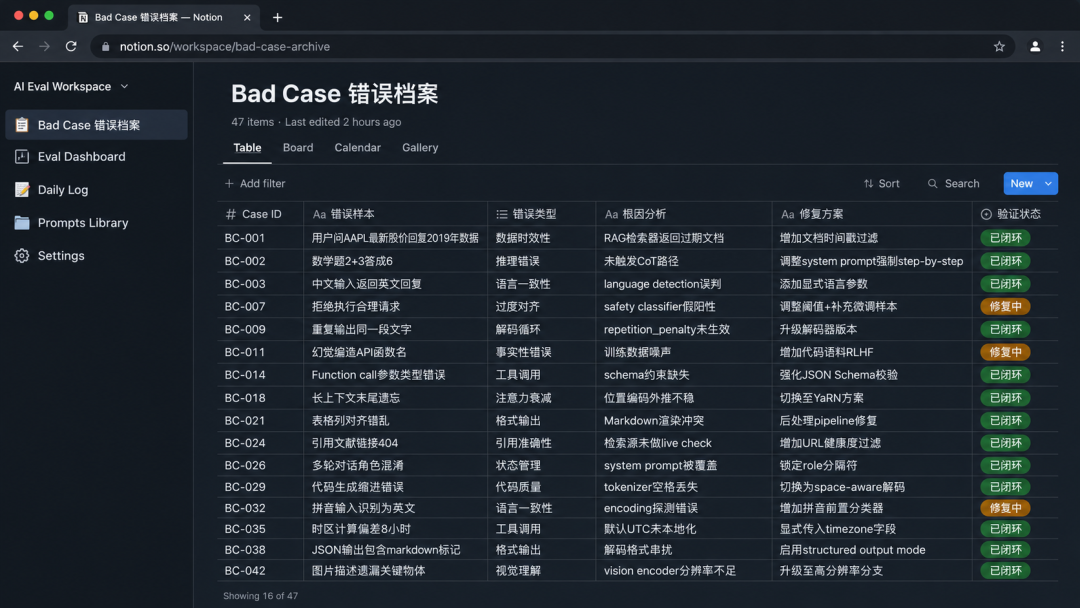
简单说一下我怎么做的。每条 Bad Case 有几个字段:错误样本、错误类型、根因分析(归到 Prompt 哪一层)、修复方案、验证结果(用 5+ 条历史 case 回归测试)、关联 Case、状态。
关键是5步闭环:归档、归因、修复、验证、沉淀。
到现在累计 47 条,闭环修复 43 条,闭环率 91.5%。
这套机制不只适用于翻译。你做对话 Agent,幻觉就是 Bad Case。你做代码助手,生成的 bug 代码就是 Bad Case。你做 AI 画图,画错的手指、画错的字就是 Bad Case。
所有 AI 产品的护城河都在「错误如何归因、修复、不再发生」这件事上。
功能能抄,模型能换,但你积累了几百条 Bad Case 的归因记录和闭环修复经验——是抄不走的。
可执行的动作是,从Day 1就建Bad Case池。哪怕只有一条。模板可以先粗糙,但「归因+修复+验证」这个闭环必须从一开始就跑起来。
学习成本得说一下。最大的成本不是工程上的,是身份上的。我那47条Bad Case里差不多一半是我自己用产品时发现的——因为我同时是owner和用户。很多AI PM做产品自己从来不当用户,这事儿在AI产品上是大忌——AI产品最反直觉的东西,往往要你高频用了才能感受到。
但这只是错误归因这一层。AI 产品上还有更隐蔽的一层。
4. 传统 PRD 里「用户需求」是显性的,AI 产品 PRD 里要捕捉用户的隐性心理负担
这一条我觉得是最颠覆的。
V1 上线的时候,我以为用户的核心诉求很简单——翻译要准。
所以 V1.5 我把术语库做了,把 Prompt 也做了 4 层结构,结果用户修改率从 35% 降到了 22%。
降了,但远远不够。
我那时候特别纳闷。是模型不够好吗?要不要换模型?还是 Prompt 还有漏洞?我研究了好几天,没头绪。
直到有一天,我自己作为产品高频用户,用这玩意翻完一份文档之后,注意到一个动作。
我做的第一件事不是看哪里不准,是从头到尾通读一遍。
为啥?因为我不知道哪里可能不准。
这个动作非常烦人——等于把翻译节省下来的时间又花在了通读上。我就在那一瞬间反应过来——
用户用 AI 翻译,最大的心理负担不是「翻译不准」,是「我不知道哪里可能翻得不准」。
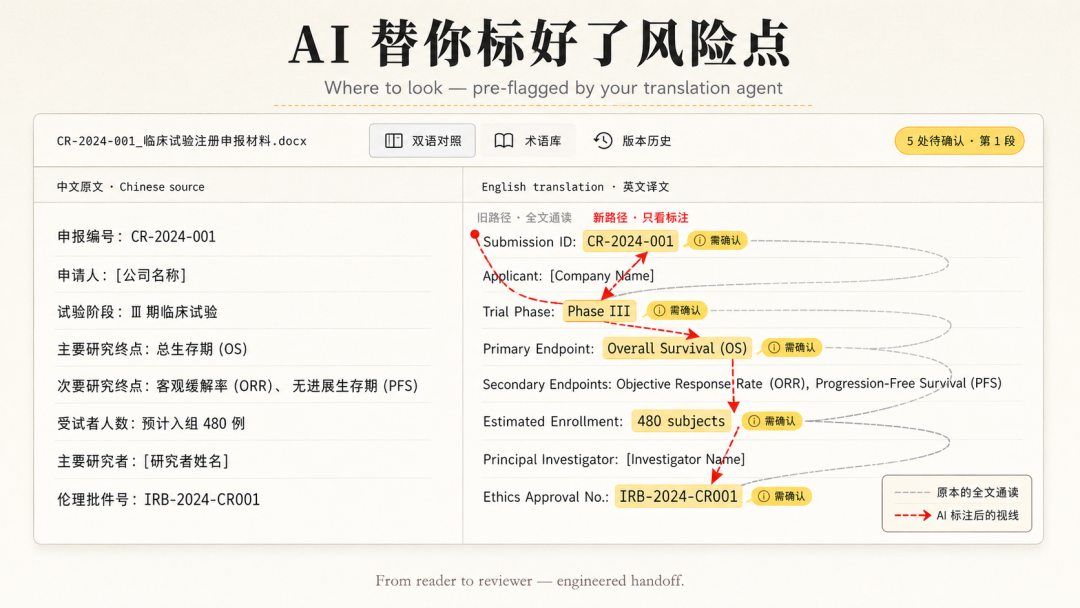
所以 V2 我加了 [需确认] 自动标注。模型对自己不确定的字段(专业术语、数字、编号),自动标黄。
用户看到的是什么?是 AI 替他标注了风险点。他不用全文通读,只需要重点看这些被标注的地方。
修改率从 22% 降到了 12%。
但更重要的是用户行为变了。他们开始信任这个工具了。
后来公司一个同事用了一段时间,跑过来跟我说,能不能加一个自动检测输入语言的功能?因为他每次涉及两种语言以上的翻译,还要去手动改翻译方向,挺烦。
我那一刻就反应过来一件事——当用户开始给你提体验优化的需求时,他已经信任你了。如果他还在质疑翻译准不准,他根本不会跟你聊体验问题。
这个洞察其实在所有 AI 产品上都成立。
- Perplexity 为啥要在每段回答后面挂引用来源?不只是为了「准」,是为了让用户「知道哪句是从哪来的」,可以自己判断可信度。
- Cursor 为啥要做 diff 预览?不是为了「写得更准」,是为了让用户在 AI 改代码之前能看清楚 AI 到底要改啥。
- ChatGPT 为啥越来越爱说「我不太确定,但你可以参考…」?不是模型变弱了,是产品在主动标注不确定性。
所有这些设计的底层是同一件事——
AI 产品的核心不是「做到 100% 准确」(你做不到),是「诚实地暴露不确定性」。
用户不需要AI完美,用户需要AI诚实。把不确定的地方告诉我,剩下的我自己能处理。
但这种隐性需求,传统 PRD 里的「用户故事」根本写不出来。「作为用户我希望 XXX,从而能 XXX」这种格式,捕捉得到「我要更准的翻译」,但捕捉不到「我要知道哪里可能不准」。
可执行的动作是,在你的产品里,永远给用户一个「模型对自己的输出有多确定」的信号。可以是[需确认]标注,可以是置信度分数,可以是不同颜色高亮,可以是引用来源。形式不重要——说到底就是诚实。
学习成本是,你得放下「我做的产品要看起来无所不能」的虚荣心。这个虚荣心很多人都有,包括早期的我。承认产品有不确定性,不是示弱——是给用户提供了真正可用的协作框架。
明白了用户要什么之后,下一个问题是——你的产品到底服务谁、解决什么、要为什么错买单?
5. 传统 PRD 里评测是开发后的事,AI 产品 PRD 里评测权重是产品定义的核心
传统软件的评测是什么?测试用例、回归测试、性能测试。一般是 QA 开发后做的,PRD 里最多写一句「需要通过 XX 测试」。
AI产品的评测完全不一样。评测体系本身就是产品定义的一部分——权重怎么分,决定了你的产品到底服务谁、解决什么问题。
我那份 PRD 的评测体系是 4 维评分:准确性 40%、安全性 30%、专业度 20%、有用性 10%。
这权重不是拍脑袋来的,是按「错误代价的不可逆程度」反推的。在我的场景里安全性出错几乎没法回头,所以是高权重,而且我设了一条「0分一票否决」的红线。
但你做电商、做办公、做创意工具,权重就完全不同。
- 电商场景:「相关性」可能比「准确性」更值钱。淘宝搜「连衣裙」给你推100%准确但全是黑色——你会用吗?相关性+多样性>单纯准确性。
- 办公场景:「效率」是核心,「准确性」是底线。GitHub Copilot给你补全90%正确但慢得要死的代码,不如给你补全80%正确但快如闪电——所以Copilot的核心指标是接受率,不是绝对准确率。
- 创意工具:「多样性」和「惊喜感」可能比「准确性」更重要。Midjourney给你画一个跟描述完全一致但平庸的画,不如给你画一个偏离描述但让你眼前一亮的——这就是Midjourney设计四宫格选择的逻辑。
- 代码助手:「可运行」比「优雅」重要,「不删用户代码」比「写得好」更重要。Cursor的Apply按钮要求diff预览,是因为「让用户失控」是最大的错误。
所以不同 AI 产品的评测体系权重应该完全不一样。但思考的框架是一样的——
按「这个维度如果出错,代价多严重多不可逆」来反推。
这个思考方式不仅适用于评测,也适用于产品所有的资源分配。哪个维度错了你最害怕?那它就是你最该投入资源的地方。
可执行的动作很具体——在你的PRD里,专门有一节写几维评分的权重,每个维度的判定标准,以及哪个维度是0分一票否决。
如果你的 PRD 里这一节没有,那大概率你做产品的时候——是凭感觉在分配资源。
6. 传统 PRD 追求自动化,AI 产品 PRD 要主动设计「人在哪里介入」
这一条跟现在很多 AI 产品的「全自动」叙事是反的。
传统软件PRD的目标是什么?能不需要人介入就不需要人介入。表单自动校验、订单自动处理、数据自动同步。人介入越少越好——因为程序是确定的。
AI产品反过来——人在哪里介入是产品的核心设计。
我那份PRD里有个章节叫Human in the Loop设计,原则就一句话:模型不应该「替代人」,应该「辅助人+标注不确定性+留出审核空间」。
L1 是输出标注——[需确认] 自动标注。 L2 是修改追踪——自动记录用户改了哪些地方,反过来驱动迭代。 L3 是主动反馈——一键报错按钮,用户主动提交 Bad Case 入池。
这三层的核心,是在产品的不同环节,留出人介入的接口。
所有靠谱的 AI 产品都在做这件事。
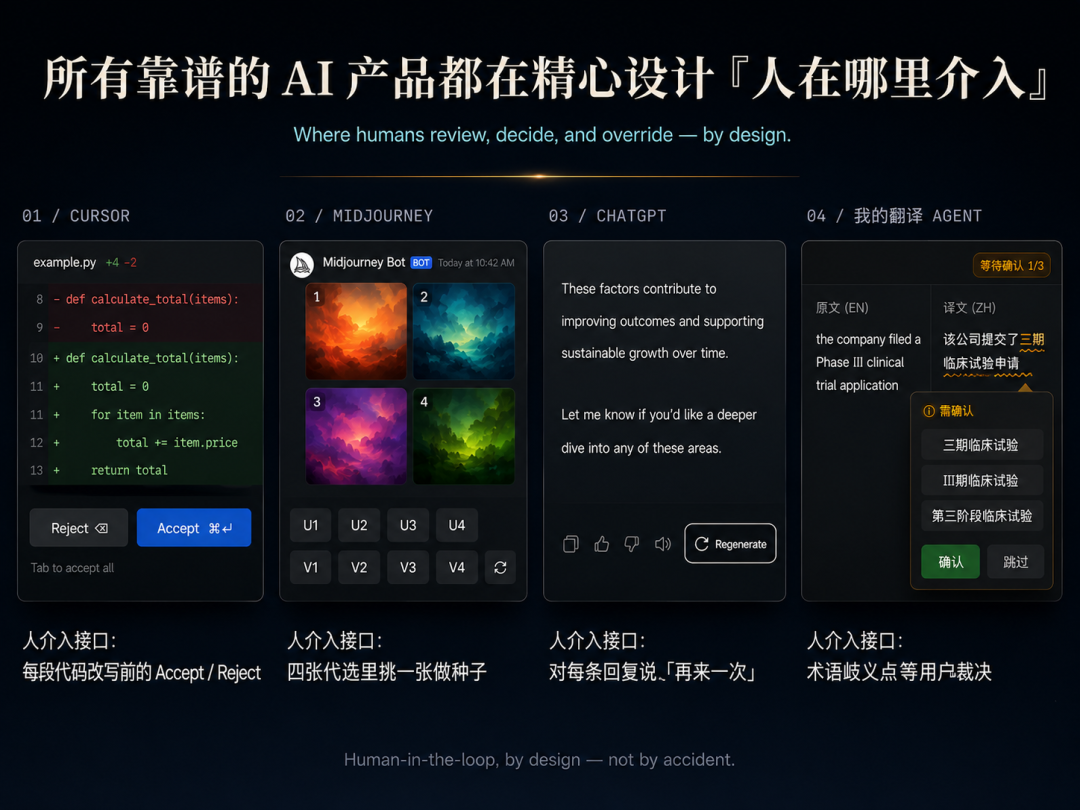
Cursor 的 Accept / Reject 按钮、Copilot 的 Tab 接受、Midjourney 的四宫格选择、ChatGPT 的 Regenerate——都不是「全自动」,都是精心设计的「人在哪介入」。
为啥要这么设计?
因为 AI 在专业场景下永远不可能 100% 可信。你试图做全自动,结果就是用户得花时间通读全部输出来核对,效率反而比不用 AI 还低。
但你设计了HITL,把不确定的地方明确暴露出来,用户的工作就变成了「review 5%标注的地方」而不是「核对100%的内容」——这才是协作。
我能理解为什么很多人做 AI 产品第一念头都是「能不能做到全自动?」——因为「全自动」听起来牛逼,能讲故事,能融钱。但说真的——
在大多数垂直专业场景下,全自动是个伪命题。它不仅做不到,还会让用户失去对产品的信任。
回到主线。我建议每一份AI产品的PRD里,都专门有一节叫「人在哪里介入」,把人和AI的边界画清楚。什么是人做的、什么是AI做的、什么是AI做但人review的——全部画在一张图上。
学习成本是,你得放下「让AI做尽可能多」的执念,承认在某些场景下,留出人的位置才是产品力。
7. 这份 PRD 本身,就是「AI 辅助 + 人的判断」的协作产物
最后这一条偏元,但我觉得很重要。
前面说了,我之前没怎么接触过 PRD。这份 12 章节的 PRD,模板是大语言模型给我整理的,框架是网上扒的,部分章节的初稿 AI 帮我打了。
但这份PRD里最有价值的部分,AI给不了。
「用户要的不是更准,是知道哪里可能不准」这个判断,是我作为高频用户用产品时蹲守出来的。「评测权重按错误代价反推」这个原则,是我做了几次错误归因之后总结出来的。「Bad Case 池才是护城河」这个洞察,是我冒着冷汗看到「临床 2 期」三个字时悟到的。
这些,AI 都给不了。
更微妙的是——做AI产品PRD这件事本身,就是AI产品PM日常工作的一面镜子。你怎么和AI协作写PRD,决定了你的产品里怎么设计AI和用户的协作。如果你写PRD的时候就让AI替你做所有判断,那你做出来的产品大概率也是想让AI替用户做所有判断——最后两边都翻车。
可执行的动作是,用AI整理框架、找参考、扩写细节,但所有「为什么这么决定」「为什么用户是这样反应的」的判断段落——必须你自己写。
聊到这里,差不多就是我想分享的全部了。
但我还想聊一个更大的事。
整理这7条心得的时候,我突然意识到——传统软件的PRD和AI软件的PRD,底层假设是完全不一样的。
传统软件 PRD 的底层假设是「程序是确定的」。你写 if A then B,输入 A 必然输出 B。所以 PRD 只需要写清楚「我要做什么」。
AI软件PRD的底层假设是「模型是不确定的」。同一个输入,今天可能输出X,明天可能输出Y。
这个差异,决定了 AI 产品 PRD 里的所有东西:
为什么 PRD 要持续更新?因为模型在变。 为什么要写显式权衡?因为方案的不确定性更高。 为什么要有 Bad Case 池?因为错误是必然的。 为什么用户要的是知道哪里可能不准?因为不确定性必须被暴露。 为什么评测权重要按错误代价反推?因为不同的不确定性代价不同。 为什么要 HITL?因为不确定性需要人做最后兜底。
7 条心得,说到底是同一件事的 7 个切片——
如何在不确定性里做产品。
这是 AI 产品 PM 和传统 PM 真正的鸿沟。
回到那个临床 2 期翻成 3 期的瞬间。那是让我惊醒的一次错误,也是那一次,让我从此对 AI 产品的 PRD 有了完全不一样的理解。
它不是给开发看的功能清单。
PRD 就是 PM 的成长史。
最后说几句。
这套方法论我也还在摸索。可能再过半年,回头看这 7 条,我自己就要推翻其中一两条。但我把它先掏出来,是希望屏幕前的你,如果也在做 AI 产品,能从这里得到一些起点。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
本文由 @CyberHuck 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









这么好的文章,需要留言称赞一下!
感谢大佬 互相学习