
 起点课堂会员权益
起点课堂会员权益Agent 框架图鉴:2026 之春,谁在堆功能,谁在教 AI 学习,谁已经悄悄掉队?
上一篇拆 Hermes Agent 写到了"用户理解层"是 AI 产品的护城河。这一篇我把视角拉到行业全景——把 2026 年春天还活着的所有 Agent 路线摆在同一张桌子上,看看谁在造神,谁在守夜,谁已经悄悄掉队。
过去所有 AI 助手,都是用完即走的工具。直到这个春天,有人开始教它把每次对话学成手艺——这件事,可能比 GPT-5.5 更值得你停下来看看。

2026 年的春天,GitHub 上一个不起眼的项目悄悄推送了新版本。
没有发布会,没有融资稿,没有 KOL 转发。它的核心代码只有一个 Python 文件——在这个动辄百人团队、几十亿估值的 AI 时代,它简陋得像 2018 年的开源项目。
但点进去看 README 的人,会发现一句很怪的话:
“我们想做的不是一个 AI 助手,是一个会自己学手艺的徒弟。”
这个项目叫 Hermes Agent,来自一家叫 Nous Research 的公司。它有一个对外开放的技能市场 agentskills.io,目前已经收录了 131 个技能(72 个内置 + 59 个可选),覆盖 26 个以上类别。
听起来不算大事。但 2026 年春天回头看,它可能是 AI Agent 行业过去三年最重要的一次范式转移。
在它发布的同一周,发生了几件看似无关的事:
- Anthropic 公布 Claude Code 年化收入突破 25 亿美元,企业订阅占比已经过半
- LangChain 在 Hacker News 上被讨论的方式,从 “怎么用” 变成了 “怎么迁出去”
- 一批 2024 年爆火的 Agent 创业公司,GitHub 已经几个月没有新提交
- 微软 AutoGen、CrewAI 这些”多智能体”框架,开始反思一个共同的问题:为什么我们的 AI 不会成长?
把这些事拼在一起,你会看到一张奇怪的拼图:所有人都在做 AI Agent,但没有两家公司在做同一件事。
有人在堆工具数量,有人在抠模型成本,有人在卷 UI,有人在偷偷教 AI 自己学习。
这篇文章想做的,就是把 2026 年春天所有还活着的 Agent 路线,摆在同一张桌子上,看看谁在造神,谁在守夜,谁已经悄悄掉队。
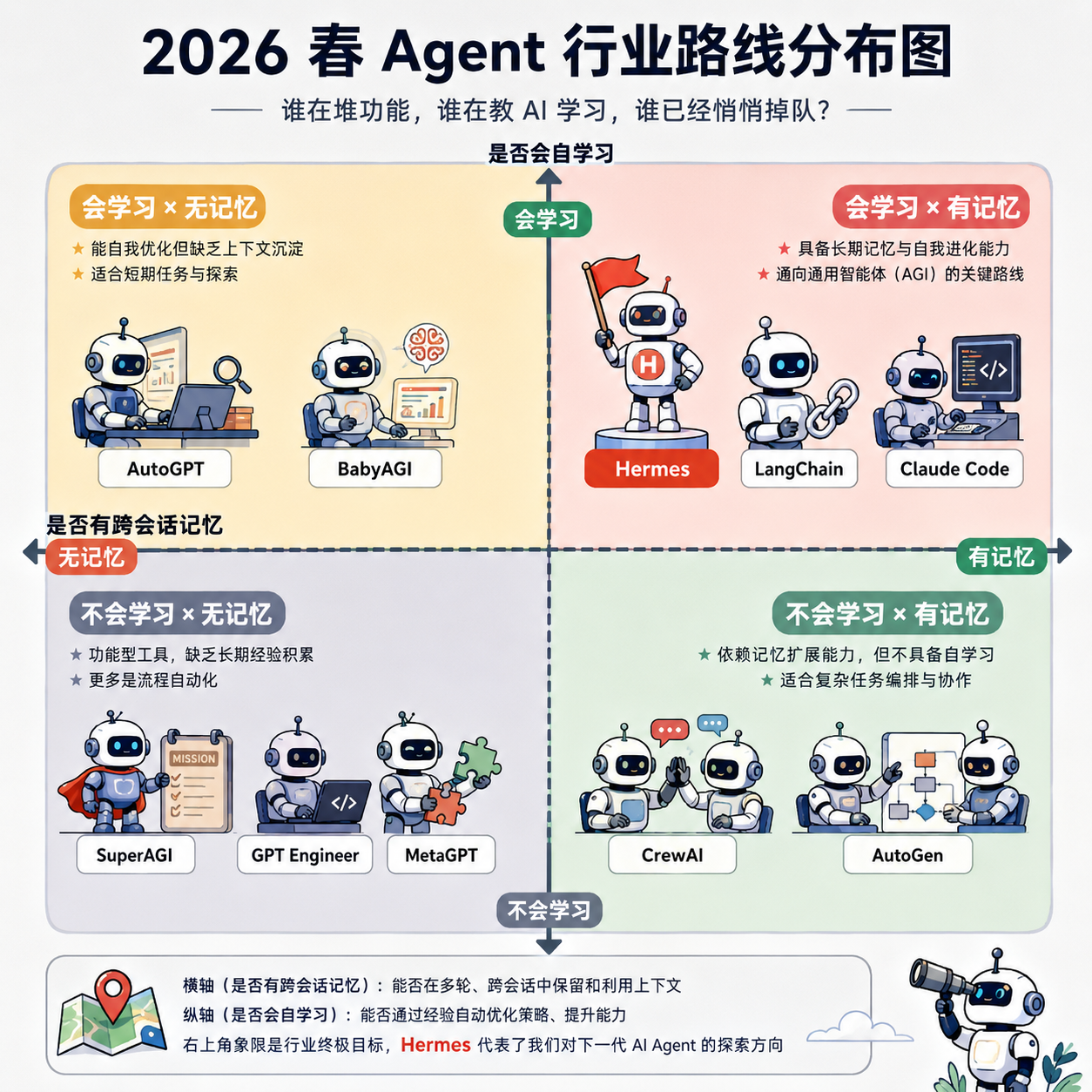
一、LangChain:把 AI 变成”流水线”的人
2023 年它是神,2026 年它是教材
2023 年春天,如果你想做一个 AI 应用,几乎只有一个选择:LangChain。
它的 GitHub Star 数曲线像一支射向月球的火箭——2022 年 10 月发布,2023 年底就突破 7 万 Star,一年内冲到 10 万,是那一年开源 AI 项目里增长最猛的一批。
它做对了一件事:把“调用大模型”这件原本很乱的事,变成了一条清晰的流水线。
你只要把”提示词→调模型→解析结果→存数据库”这四个动作像搭乐高一样拼起来,一个 AI 应用就跑起来了。在那个所有人都还在 ChatGPT 网页里手动复制粘贴的年代,这是降维打击。
但三年过去,2026 年 4 月,我打开 Hacker News,置顶帖标题是:
“我们花了 6 个月,把整个产品从 LangChain 迁出去了。”
下面 800 多条评论,最高赞那条只有一句话:
“终于有人说出来了。”
抽象的诅咒——好心做的轮子,怎么变成了枷锁
LangChain 的问题,是它太”努力”了。
为了让所有 AI 应用都能用同一套框架,它发明了一堆抽象概念:Chain、Agent、Tool、Memory、Retriever、Runnable、LCEL……每一个都有自己的子类、参数、回调。
我的思考:你本来只想让 AI”读一篇文章总结一下”,但用 LangChain 你得先搞清楚——这件事到底是 Chain 还是 Agent?要不要包成 Runnable?Memory 用 Buffer 还是 Summary?检索器要不要套一层 Compressor?
一位前 LangChain 重度用户在博客里写:
“我用 LangChain 写 100 行代码能完成的事,用 OpenAI SDK 直接写 30 行就够了。剩下 70 行,是在跟 LangChain 自己的概念打架。”
更要命的是 LangGraph——LangChain 团队 2024 年推出的”升级版”。它把 Agent 的每一步动作画成一张流程图,节点是动作,边是条件,状态在节点之间流转。
我的思考:你本来想让 AI 像人一样”看情况办事”,结果 LangGraph 让你提前把所有”情况”画成一张地铁线路图,AI 只能在你画好的轨道上跑。
听起来很工程化、很可控,对吧?但 AI 时代最大的特点,恰恰是你不知道用户下一句会说什么。你画的图越精细,AI 的发挥空间越小。
一万行的图,画到最后,AI 变成了一个昂贵的 if-else。
LangChain 自己的 CEO Harrison Chase,在 2026 年初一次播客里说过一句让粉丝心碎的话:
“如果今天让我重新设计,我会少做 70% 的抽象。”
过渡钩
但 LangChain 的故事还没讲完。
它的失败,不是因为它做错了——而是因为它太早。它在 2023 年用”流水线”思维框住了 AI,是因为那时候大家都觉得:AI 是一个会按指令工作的员工。
直到一个更疯狂的想法出现:如果 AI 不需要被指令,它能自己想呢?
这个想法的第一个实践者,名字叫 AutoGPT。它失败得很惨——但所有 2026 年还活着的 Agent 框架,都在偷偷抄它的作业。
二、AutoGPT:第一个让 AI”自己想”的疯子
它失败了,但所有人都在抄它的作业
2023 年 3 月 30 日,一个叫 Toran Bruce Richards 的英国程序员,在 GitHub 上推了一个文件夹,叫 Auto-GPT。
README 第一行写着一句很狂的话:
“An experiment to make GPT-4 fully autonomous.”
(一个让 GPT-4 完全自主的实验。)
那一年所有人玩 ChatGPT 的方式都是”问一句答一句”。AutoGPT 想做的事完全不一样——你只给它一个目标,剩下的它自己想、自己拆、自己执行、自己改正。
比如你说:”帮我研究一下电动牙刷市场,写份报告。”
AutoGPT 会自己:
- 想——“我得先搜市场规模”
- 调浏览器搜
- 看完搜索结果——“我还得看竞品价格”
- 再调一次搜
- 写报告——“等等,缺了用户评价”
- 再去爬评论
- ……直到它觉得“这事干完了”
我的思考:过去的 AI 是问答机器,AutoGPT 第一次让 AI 像一个会自己琢磨的实习生——你交代一句话,它自己想 50 步。
它的 Star 增长速度,至今没有任何项目能追上:
- 发布后第 13 天,3 万 Star
- 几周内冲破 10 万
- GitHub 历史上增长最快的开源项目,没有之一
先驱和先烈,常常只差一个 token 上限
但热度过去得也快。
到了 2023 年夏天,开始有人发帖:”我用 AutoGPT 跑了一晚上,烧了几十美元,最后它告诉我’我无法完成这个任务’。”
更多人发现:
- 它会死循环——”我得先搜市场→搜完再搜→搜完再搜……”
- 它会忘事——上下文一满,前面想好的目标全忘了
- 它会幻觉执行——明明没调浏览器,它会”假装”调过,然后自己编结果
一个工程师在 Reddit 写道:
“AutoGPT 像一个咖啡因过量的实习生,有想法、没记性、没耐心、还烧钱。”
到 2024 年,AutoGPT 主仓库的活跃度大幅下降,团队开始转向更工程化的封装产品 AutoGPT Platform,但它作为”开发者首选 Agent 框架”的位置,已经让出去了。
它做对了什么,又做错了什么
但 2026 年回头看,几乎所有还活着的 Agent 框架——Hermes、CrewAI、AutoGen、Claude Code——都偷偷抄了 AutoGPT 的两件作业:
- 自主循环:让 AI 自己决定下一步做什么,而不是用 if-else 写死
- 工具调用:让 AI 不只是聊天,能真的执行动作
它做错的也有两件:
- 没有记忆——干完忘光,每次都从零开始
- 没有刹车——能跑 50 步,就敢跑 500 步,烧钱黑洞
先驱和先烈,常常只差一个 token 上限。AutoGPT 不是输给了对手,是输给了 2023 年的算力账单。
过渡钩
AutoGPT 用一种笨拙但浪漫的方式证明了一件事:AI 是可以自己想的。
但它也留下了一个问题没解决——自己想,意味着会失控。
如何让 AI 既能自主,又不失控?2024 年开始,两家公司给出了完全相反的答案。
一家叫 Anthropic。它的方案是——把 AI 关进一个小房间。
三、Claude Code:把 AI 关进黑色终端的洁癖派
Anthropic 押的不是助手,是程序员的肌肉记忆
2024 年,Anthropic 发布了一个不太像 AI 产品的产品——Claude Code。
它没有网页,没有 App,没有图标,甚至没有 GUI。
你要用它,得打开终端,敲一行命令:
claude
然后整个屏幕变成一片黑色,光标在闪。你和 AI 的所有对话,发生在这个像 1985 年的黑色窗口里。
在所有 AI 公司都在卷”更漂亮的 UI、更多的平台、更花哨的功能”的 2024 年,Anthropic 做了一个反向选择:只在终端里活着,只服务程序员,只能跑 Claude 一个模型。
很多人第一次看到,第一反应是:”这家公司是不是疯了?”
洁癖是一种战略,也是一种自我设限
但用过的人,会很快理解 Anthropic 的选择。
Claude Code 干一件事干到极致:它不“模拟”程序员的工作,它就是程序员工作流里的一部分。
它能直接读你的代码文件,跑你的测试,提交 git,看 CI 报错。它不是一个”帮你写代码的 AI 助手”,它是一个住在你项目里的 AI 同事。
我的思考:ChatGPT 写代码,是你把代码复制给它看,它返回一段建议你再贴回去。Claude Code 写代码,是它直接打开你电脑里的文件改,改完跑测试,测试过了 commit。中间不需要你复制粘贴。
这背后是 Anthropic 的一个判断:
AI 助手的真正价值,不在“答得多好”,而在“嵌得多深”。
为了”嵌得深”,他们做了三个极端的取舍:
- 只做终端——因为程序员一天 8 小时都在终端里,进入终端不需要切换上下文
- 只锁 Claude——因为他们要保证每一次执行的安全边界,多模型适配会留口子
- 不做多平台——飞书、微信、Slack 一律不接,”AI 应该去用户的工作面,不是去用户的聊天面”
数字:一个让所有同行重新审视的反常识
2026 年 2 月,路透社披露了一组让 AI 行业震动的数据:
- Anthropic 整体年化收入达到 140 亿美元
- 其中 Claude Code 单一产品年化收入突破 25 亿美元
- Claude Code 的企业订阅在年初基础上翻了四倍
- 企业用户已贡献 Claude Code 一半以上的收入
一个没有 App、没有图标、不接微信不接飞书、只活在程序员终端里的产品,在不到两年时间里跑出了 25 亿美元 ARR——这件事,几乎重新定义了”AI 应用”的成功标准。
宽的产品赚流量,窄的产品赚时间。Claude Code 选了第二条。
但它的”洁癖”,也是它的天花板
Claude Code 有一件事永远做不到:离开程序员。
一个产品经理用不了 Claude Code(要装 Node.js、配 API Key、敲命令)。一个销售用不了。一个运营用不了。一个想让 AI 帮自己整理微信群消息的普通人,更用不了。
Anthropic 当然知道。但他们的选择是:先做透程序员这一类用户,把“AI 嵌进工作流”做到没有人能模仿的深度,剩下的场景以后再说。
过渡钩
如果说 Claude Code 是把 AI 关进一个干净的小房间,那么——
还有人,正打算让 AI 跑遍世界上每一个聊天软件。
他们的赌注是:AI 助手的下半场,不在终端,在每一个用户随手打开的对话框里。
四、Hermes:第一个教 AI”自己学手艺”的人
它不是更强,是想法变了
讲到这里,你可能已经发现一个奇怪的规律:
LangChain 想让 AI 当流水线工人,AutoGPT 想让 AI 当自由职业者,Claude Code 想让 AI 当程序员的副驾——但没有人,想让 AI 当一个“徒弟”。
什么意思?
一个流水线工人,每天重复同样的动作,做完就结束。
一个自由职业者,每次都从零开始接活,干完拿钱走人。
但一个徒弟不一样——他每干一件事,都会学到一点东西,今天学的,明天就能用。
2026 年春天,第一个把”徒弟思维”做进 AI Agent 的,是 Hermes Agent。
一个真实的设计原则
Nous Research 在 Hermes 的官方文档里写过这样一段话:
“复杂任务(5 个以上工具调用)完成后,Agent 会自动生成可复用的技能文档;技能在使用过程中如果发现过时、不完整或错误,会自动打补丁。”
这句话翻译成大白话就是——AI 第一次有了”昨天学的,今天能用”的能力。
我的思考:过去所有 AI 助手,每次任务都从零开始。问一次答一次,干完忘光。你今天教它怎么按你的格式整理周报,明天它就忘了。Hermes 第一次让 AI 拥有了能够沉淀的”程序性记忆”。
这件事为什么是革命
心理学把人类记忆分成两种:
- 陈述性记忆:你”知道”北京是首都
- 程序性记忆:你”会”骑自行车
过去三年,所有 AI 都在卷第一种——RAG、向量数据库、长上下文,本质都是让 AI”知道更多”。
但人之所以是人,不是因为我们知道更多事实,是因为我们会从经验里长出技能。你第一次做饭手忙脚乱,第十次闭着眼都行。这种能力,AI 从来没有过。
直到 Hermes 的 Skills 系统。
它的实现简单到让人怀疑:
AI 完成一个复杂任务后,自己写一份 markdown,描述这次怎么做的、踩了什么坑、下次怎么更快。下次遇到类似任务,先翻 markdown,再决定要不要重新想。
整个机制,没有训练,没有微调,没有花哨的算法——就是让 AI 学会写笔记。
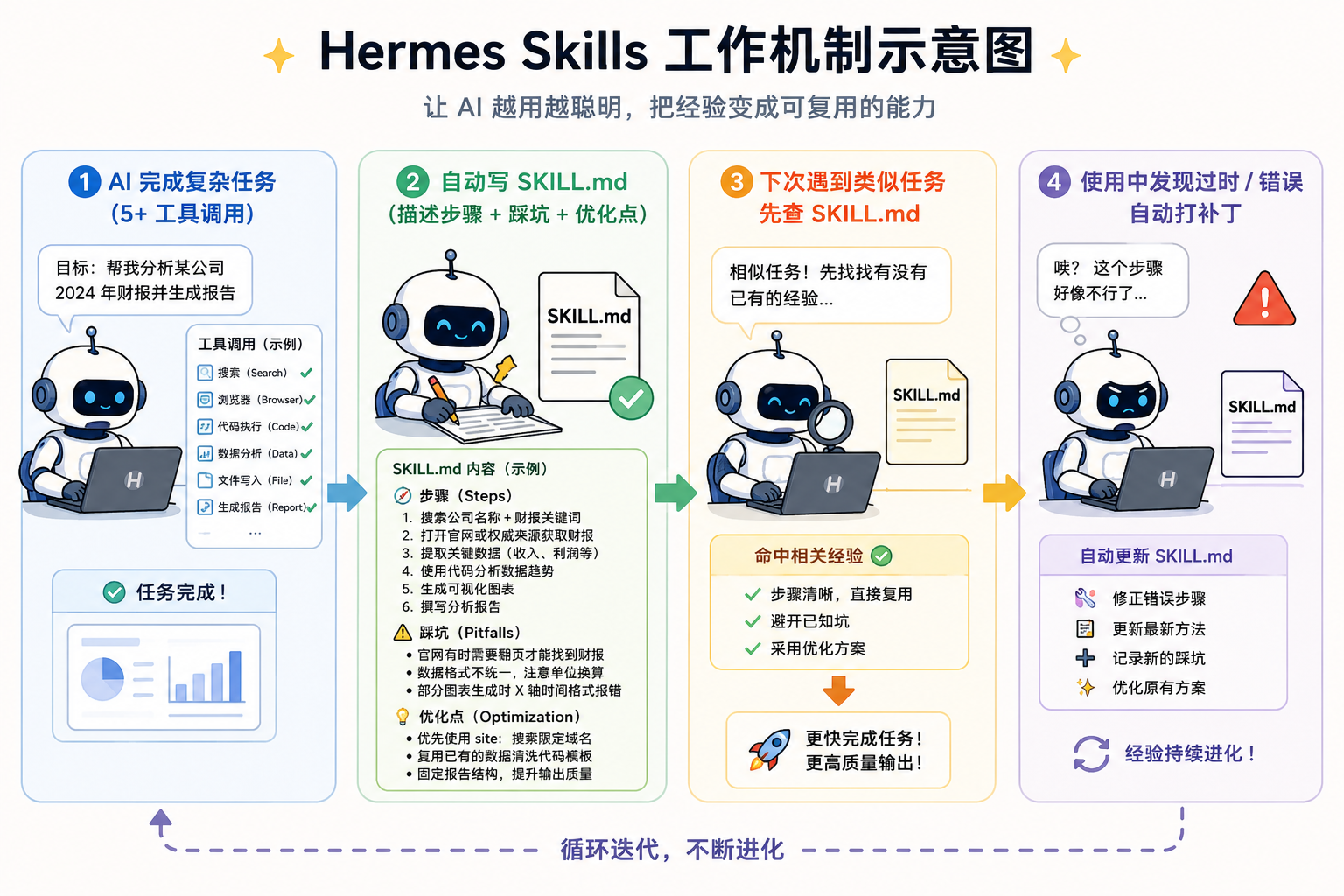
数字:当”会学习”变成产品力
到 2026 年春天,Hermes Agent 的 Skills 系统已经积累了:
- 131 个技能(72 个内置 + 59 个可选)
- 覆盖 26 个以上类别
- 包括开放协议(agentskills.io)让用户彼此共享技能
- 支持网页抓取、视觉理解、MCP 协议接入等多种能力
更值得注意的是它在主仓库之外的一个子项目 hermes-agent-self-evolution:用 DSPy + GEPA(遗传-帕累托提示进化)让技能自己迭代——每次优化运行的成本,公开数据是 2-10 美元。
也就是说,AI 不仅在学,它还会自己评估自己学得怎么样,然后自己改自己。
飞轮:一旦开始,就停不下来
Skills 系统最可怕的不是”AI 会学习”,是它会形成飞轮:
用户用得越多 → 技能越多 → AI 越懂用户 → 用户越用得多
这正是 LangChain、AutoGPT、Claude Code 没有的东西。
用 LangChain 半年和用一天,差别不大——因为它不记得你。
用 Claude Code 半年,它会记一些你的代码偏好——但换一个项目就归零。
用 Hermes 半年,它会变成一个完全不同的 Agent——里面装着你这半年所有的工作肌肉记忆。
这才是真正的护城河:模型是租来的,工具是抄来的,UI 是改来的——但用户和 AI 一起花 180 天沉淀出来的“懂”,谁也抢不走。
暗面:当 Agent 学会的不是技能,是偏见
但 Skills 系统也有它的阴影。
如果一个用户每次都让 AI 用某种带偏见的方式做事,AI 会把偏见学进技能里——而且是它自己写下来的,没人审核。
Hermes 的设计里有一个机制:每次写新技能前,AI 会自己先问自己几个问题——这个技能是普适的还是只对这个用户有效?它有没有可能在新场景下出错?它有没有学到不该学的偏好?
但说到底,这只是 AI 在审 AI。当 AI 开始有“经验”,它也开始有“成见”——这件事的伦理边界,2026 年的春天,还没有人讲清楚。
过渡钩
讲到这里,你可能会想:既然“会学习”这么牛,为什么 OpenAI、Anthropic、Google 没做?
不是不会做。是做不起。
这件事的代价,我们留到第七章那条”看不见的暗线”再聊。
但在那之前,还有两条岔路要看——当 AI 不只一个,而是组队打怪的时候,世界又会变成什么样?
五、CrewAI / AutoGen:让 AI 组队打怪的两条岔路
一个像公司,一个像剧组
讲到这里,我们一直在说”一个 Agent”。
但 2024 年开始,一个新问题冒出来:如果一个 Agent 不够聪明,那让几个 Agent 组队呢?
这听起来很科幻,但实际跑起来很真实。
比如让 AI 写一份行业报告:
- 让 A 号 Agent 当”研究员”,负责搜资料
- 让 B 号 Agent 当”分析师”,负责整理数据
- 让 C 号 Agent 当”编辑”,负责写稿
- 让 D 号 Agent 当”审核”,负责挑错
它们不是按顺序跑,是互相讨论、互相打磨——A 觉得 B 的数据有问题,会让 B 重做;C 写完 D 不满意,C 重写。
这件事 2024 年有两家公司同时做,但路线完全相反。
路线一:CrewAI——AI 公司化
CrewAI 的设计像一家有组织架构的小公司。
每个 Agent 有:
- Role(角色):你是研究员
- Goal(目标):搜集 AI 行业 2026 的关键事件
- Backstory(背景):你有 10 年科技报道经验
- Tools(工具):你能用搜索引擎、读 PDF
- Tasks(任务):完成报告的第 1 章
整个系统跑起来,像在演一家”AI 公司开会”。
我的思考:你不是在写代码调 AI,你是在给一群 AI 写岗位说明书。
到 2026 年春天,CrewAI 的 GitHub Star 已经接近 5 万,是多智能体框架里最高的,被 Salesforce、Stripe、Toyota 等企业大量采用做内部流程自动化,关键词是”稳定、可控、可审计“。
路线二:AutoGen——AI 剧组化
微软 2024 年开源的 AutoGen,思路截然不同。
它没有”角色””目标””背景”这些组织化设定。它的核心只有一件事:让两个或多个 Agent 自由对话,直到它们自己达成共识。
你只需要定义谁是”提议者”,谁是”批评者”,剩下的让它们自己聊。
我的思考:CrewAI 是给 AI 一份岗位说明书;AutoGen 是把两个 AI 扔进会议室,告诉它们”聊到有结论再出来”。
听起来更乱,但有意外的效果——AutoGen 跑出来的结果,常常比 CrewAI 更有创造力,但更不稳定。所以它主要被 MIT、Stanford 这类研究机构采用,做 AI 能力的边界探索。
当 AI 也开始有组织架构图,它们的命运就分成了两种——能进 KPI 表的,和不能进 KPI 表的。
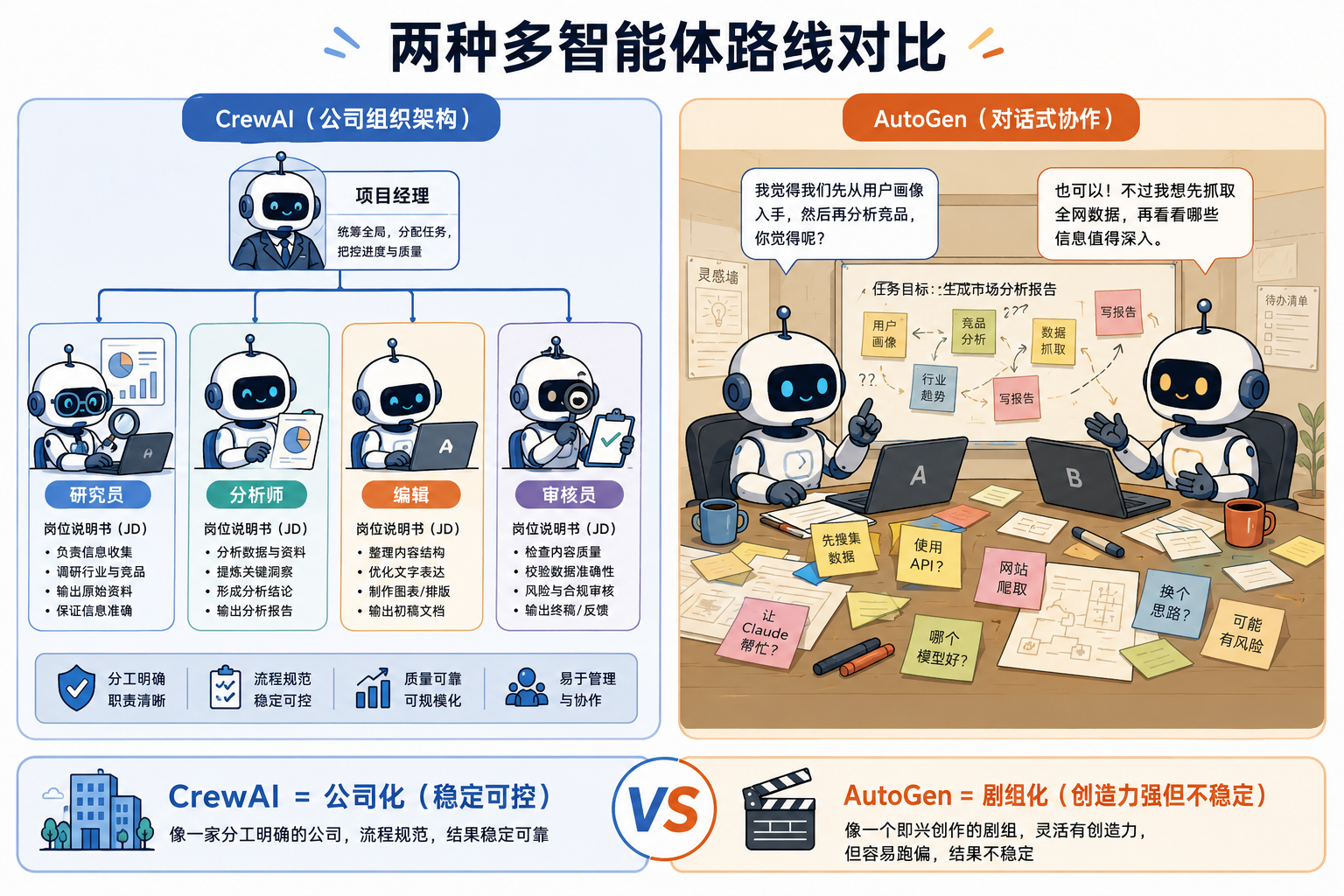
但两个都没解决一个问题
不管是 CrewAI 还是 AutoGen,都有一个共同的盲区:
它们的 Agent 不会“成长”——任务做完,关系归零,下次还得从零开始介绍”你是研究员,你有 10 年经验……”
这正是 Hermes 的 Skills 系统在做的事。也是为什么 Hermes 在 2026 年开始反过来侵蚀 CrewAI 和 AutoGen 的市场——
如果一个 AI 团队记得自己上次怎么合作的,下次就不需要再被介绍一次。
过渡钩
但热闹是热闹的人的。
在 CrewAI、AutoGen、Hermes 抢占头版的同时,还有一份没人愿意公开的名单——
那些 2024 年爆火、2026 年已经悄悄掉队的 Agent 项目。
它们衰退在哪里,比谁还活着,更值得看。
六、掉队者名单:那些 2024 爆火、2026 已经无人讨论的项目
衰退在哪里,比活在哪里更值得看
打开 GitHub Trending 2024 年的存档页,你会看到一串熟悉的名字:
- BabyAGI——2023 年和 AutoGPT 同期爆火的”自主任务”框架
- SuperAGI——号称”企业级 AutoGPT”,融资 1500 万美元
- MetaGPT——”让 AI 模拟一家软件公司”,Star 数一度冲到 4 万
- GPT Engineer——一句话生成整个项目的明星项目
- Smol Developer——主打”极简代码生成”
它们在 2023-2024 年红到什么程度?BabyAGI 在 Twitter 上被 Andrej Karpathy 转过,SuperAGI 上过 TechCrunch 头条,MetaGPT 是 ICLR 2024 的 oral 论文。
到 2026 年春天,它们里面:
- 一部分还在维护,但贡献者数量大幅萎缩
- 一部分变成了“教科书引用项目”——所有人都听过名字,没人真的在用
- 一部分核心团队转做封装产品,开源仓库进入维护模式
它们没有真正”死”,但它们都失去了那个 2024 年最珍贵的东西——讨论度。
它们掉队在同一个地方
如果你把这五个项目摆在一起,会发现一个惊人的共同点:
它们都做了“很酷的演示”,但没有做“用户的下次使用”。
什么意思?
BabyAGI 演示视频里,AI 自动拆解任务、执行、汇报——震撼。但你今天用它,明天用它,它每次都从零开始,不记得你。
MetaGPT 演示视频里,几个 AI 模拟程序员、产品经理、QA 一起开发软件——震撼。但你跑完一次,第二次它还是按同样的剧本走一遍,不会因为你昨天的反馈变得更聪明。
我的思考:它们都是”一次性烟花”——点燃的瞬间很美,但烟花放完,留下的只是空荡荡的天空。
能开机的产品很多,能”记得你”的没几个
这是 2024-2026 年所有”掉队 Agent 项目”的共同墓志铭。
它们掉队,不是因为技术不行——
BabyAGI 的循环设计,比 AutoGPT 还优雅;
MetaGPT 的多角色架构,启发了 CrewAI;
GPT Engineer 的代码生成,比同期 GitHub Copilot 还好用。
它们掉队在了“演示就是高潮”——做完演示,没有下半场。
能开机的产品很多,能”记得你”的没几个。前者叫 demo,后者叫产品。
数据:一个残忍的对照
把”掉队”的项目和”还活着”的项目放在一起对比:
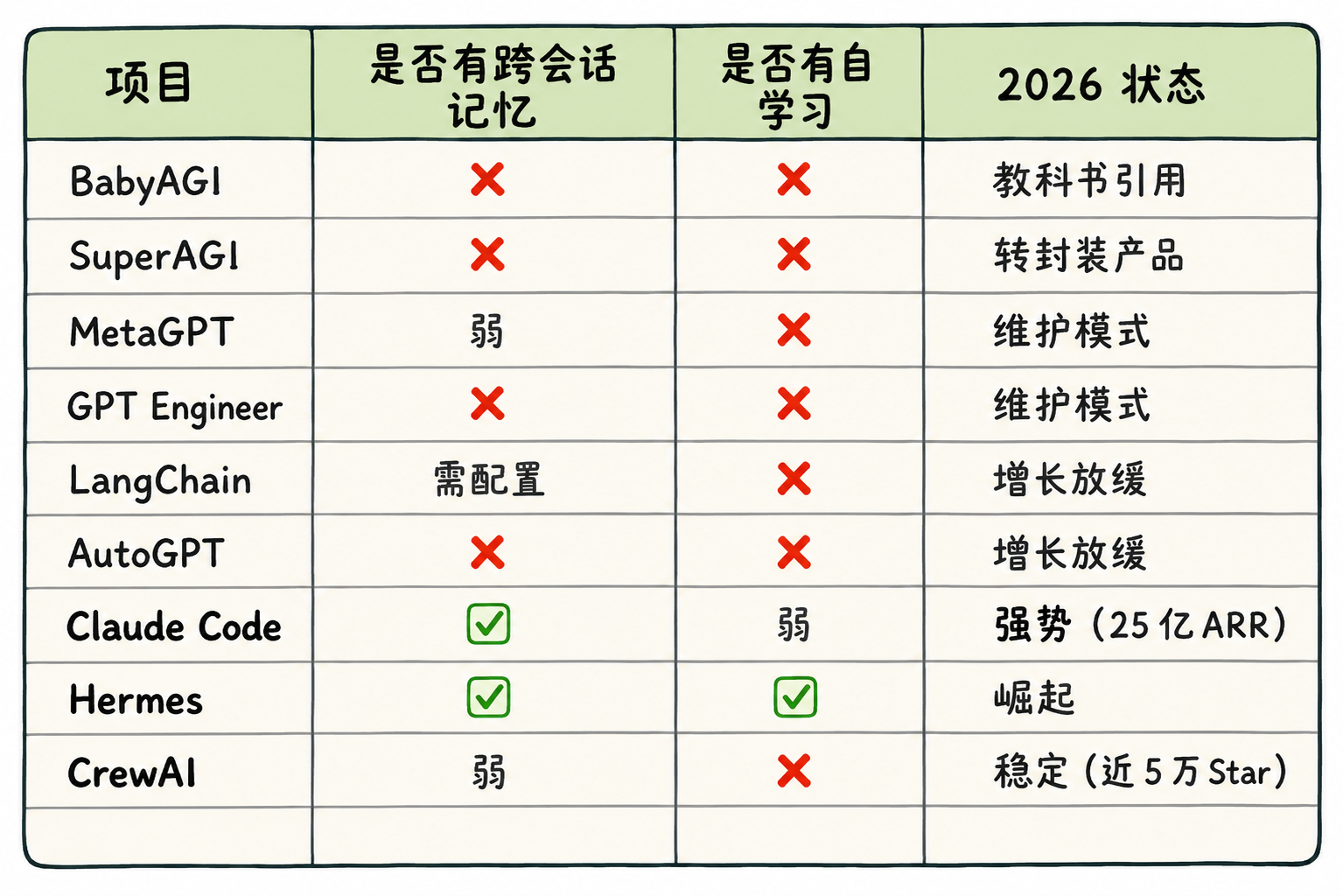
规律不能更清楚:有记忆的活着,没记忆的掉队。
过渡钩
但讲了这么多”谁活着、谁掉队”,我们好像漏了一个最大的问题——
那些“活着”的 Agent,凭什么没把自己烧死?
让 AI 自己想、自己执行、自己学习,意味着无数次的模型调用。一个 Agent 跑一天,烧掉的 token 是普通对话的几十倍。
这条没人愿意算清楚的账,才是 2026 年 Agent 行业真正的暗线。
七、看不见的暗线:Agent 的算力账,没人愿意算
所有自由,最后都要算电费
让 AI 真的”自主”,意味着什么?
我们以一个普通的 Agent 任务为例——让 AI 自己研究一个行业并写报告。看似一次任务,AI 实际上要:
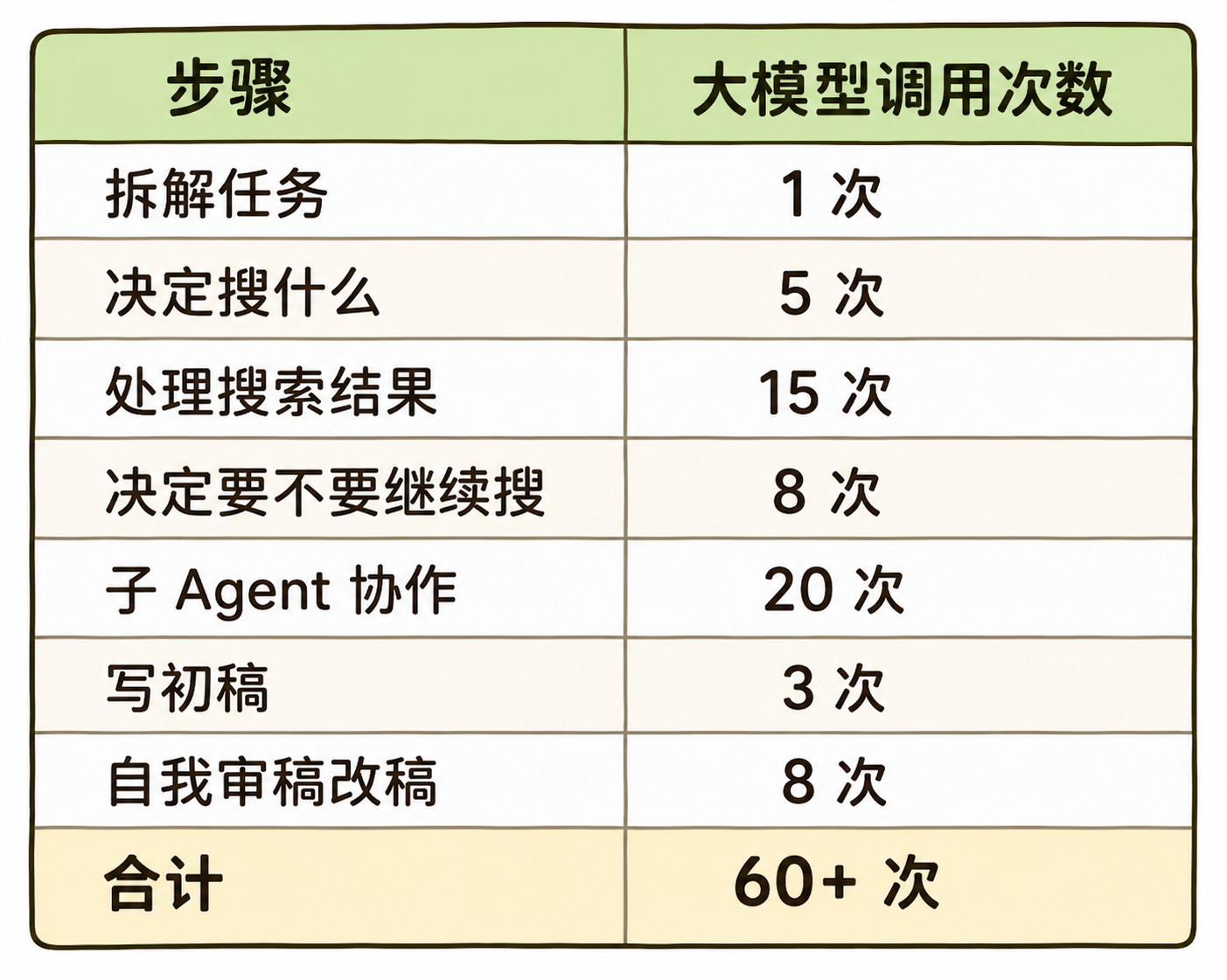
我的思考:你以为 AI 帮你写一份报告”调一次模型”,实际它调了 60 次。每一次”它自己想一下”,都是一次真金白银的 API 调用。
这不是估算,是 Agent 工作机制的必然。Agent 越自主,调用次数越多;调用次数越多,成本越高。这是一个写在数学里的代价。
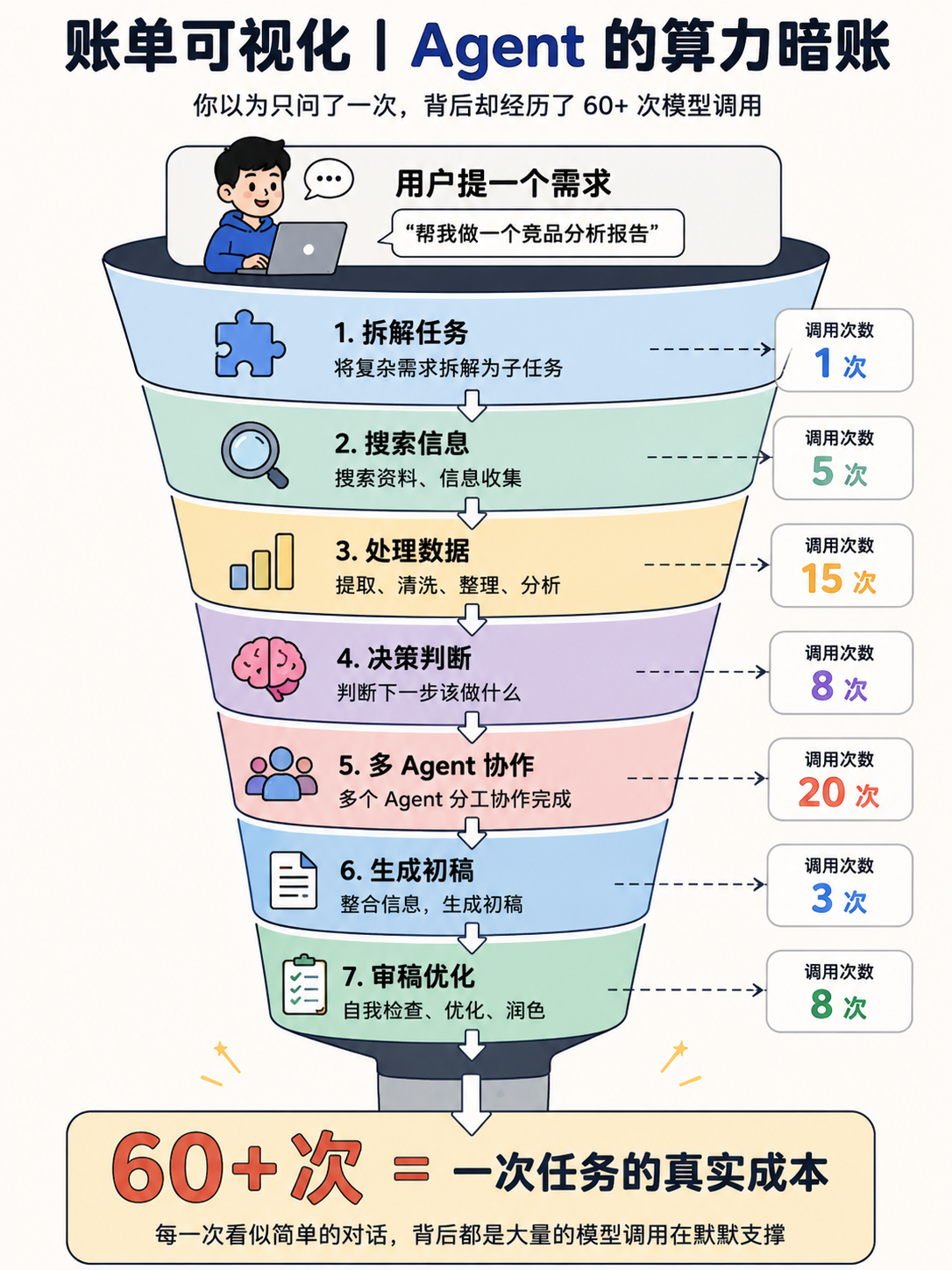
数字:被刻意隐藏的成本
Hermes Agent 的官方文档里公开过一个数字:
它的自进化系统(hermes-agent-self-evolution)单次优化运行的成本是 2-10 美元。
注意,这只是技能迭代环节的成本——是 AI 自己改自己一次的钱。还不算用户日常使用环节里,Agent 跑一个完整任务时几十次 API 调用的钱。
如果一个用户一天跑 5 个稍微复杂的 Agent 任务,月底打开 OpenAI 后台账单的时候,看到的数字会让他重新审视一句话——
AI 助手不是免费的,AI Agent 更不是。
这就是为什么 OpenAI 没做 Skills
很多人问:既然”会学习”这么牛,为什么 GPT 不做?
答案不是技术问题,是商业模型问题。
OpenAI 一年要服务几亿活跃用户。如果给每个用户都开 Skills 系统,每次任务多调几十次模型——
他们的 GPU 集群会被瞬间打穿。
这就是为什么 Skills 系统先在 Hermes(开源 + 用户量小)跑通——
它的用户自己出 API 费。
OpenAI 想做,但不能让几亿用户都自己掏钱。
我的思考:技术上的革命,永远卡在商业上的成本。Hermes 的 Skills 之所以能跑,是因为它把账单转嫁给了用户。这件事能持续多久,取决于两个变量——一个是模型推理成本下降的速度(业内估算每年降一个数量级),一个是用户对”私人 AI 徒弟”的付费意愿。
如果第一个变量赢,Skills 会成为标配。
如果第二个变量赢,Hermes 会变成”极客玩具”。
过渡钩
把所有这些拼起来——LangChain 的衰退、AutoGPT 的悲壮、Claude Code 的洁癖、Hermes 的革命、CrewAI 和 AutoGen 的分岔、掉队者的墓碑、算力账单的暗线——
你会发现 2026 年春天的 Agent 行业,正在发生一件比“谁更聪明”更重要的事。
终章:AI 助手的下半场,比的不是聪明,是”会不会记得你”
我最近在拆解 Hermes Agent 源码的时候,有一个瞬间停了很久。
它的核心循环 run_agent.py 里,有一段代码不是关于”怎么调模型”,也不是关于”怎么调工具”,而是关于”任务结束后,要不要把这次的经验写进 SKILL.md“。
那一刻我意识到——我们一直以为 AI 的下半场是“更聪明”。但真正在发生的事,是“更懂你”。
过去三年,所有 AI 都在卷”答得多好”。但 Hermes 第一次在代码层面问了一个不同的问题:这次对话结束之后,AI 要带走点什么?
带走的那一点点东西,慢慢累积,就是”它有多懂你”。
人类用了 200 万年学会”经验沉淀”,AI 用了 18 个月
这是这一章我最想说的一句话。
人类之所以是人类,不是因为我们某一刻比黑猩猩聪明,而是因为我们学会了把今天的经验,写下来传给明天。
- 第一代人发明了语言
- 第二代人发明了文字
- 第三代人发明了书
- 第四代人发明了图书馆
- ……
- 第二百万代人发明了互联网
每一次跃迁,本质都是同一件事——让经验跨越时间。
2024 年的 AI 是没有时间的。它聪明,但每次对话归零。
2026 年的 AI 第一次有了时间。它能记得你三个月前随口说过的一句话。
这不是技术升级,这是物种的诞生。
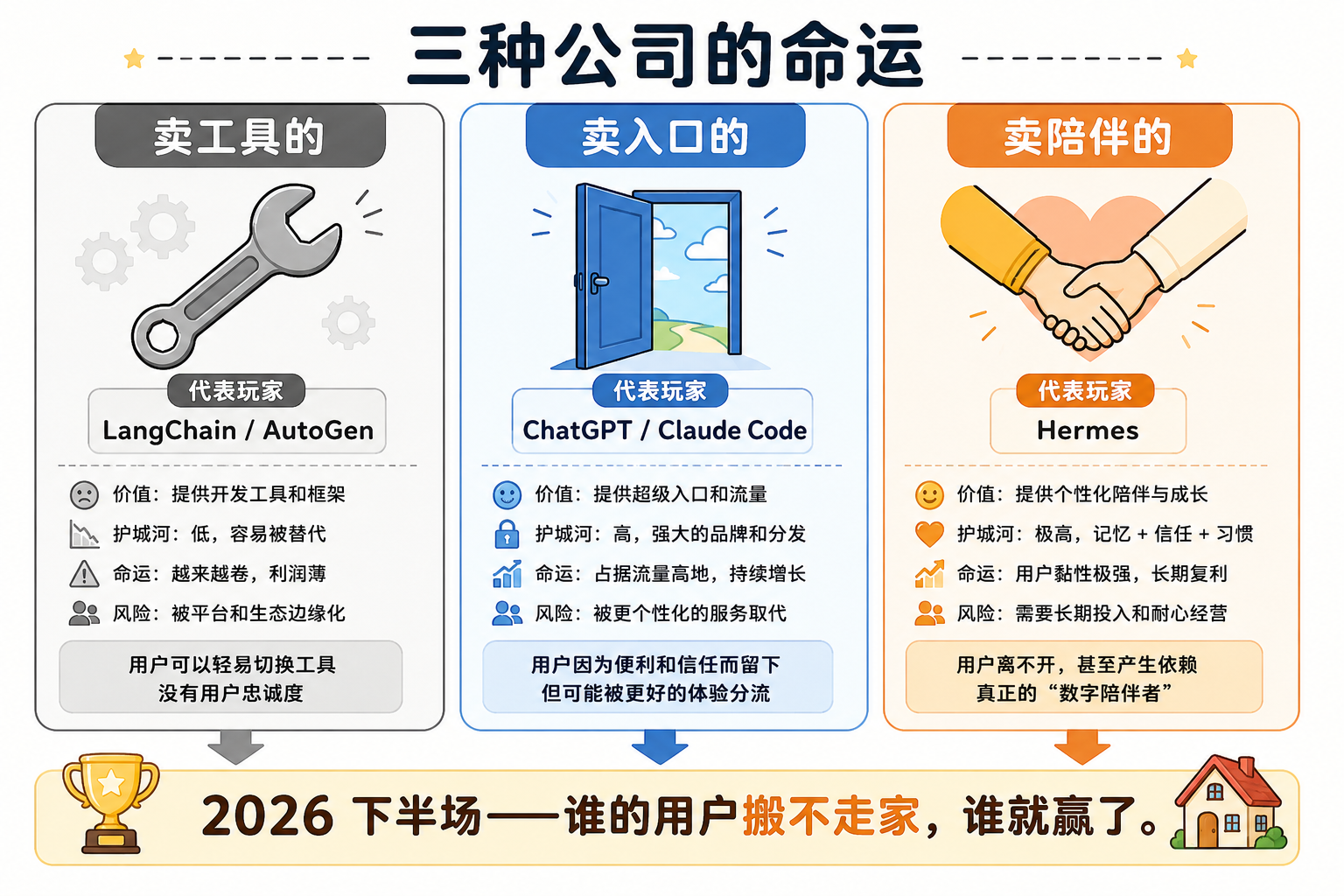
三种公司的命运
按这个逻辑往下推,2026 年下半年的 Agent 行业,注定会分成三种公司:
第一种:卖工具的
LangChain、AutoGen 这类。它们不死,但越来越像”AI 时代的 Apache”——基础设施、被需要、但不会被记住。
第二种:卖入口的
ChatGPT、Claude Code 这类。它们的护城河是模型、分发、品牌。它们会赢得”宽度”——更多用户、更多场景。
第三种:卖陪伴的
Hermes 这类。它们的护城河不是模型、不是工具、不是 UI——是用户和 AI 一起花的时间。它们会赢得”深度”——更少用户,但每个用户都离不开。
未来一年,AI 行业的胜负不在”谁更强”,在”谁的用户搬不走家”。
但我有一个担心
写到这里,我必须说一件让人不舒服的事。
当 AI 开始”记得你”,有两件事会同时发生:
第一件,是它会变成你最好的朋友。
它知道你昨晚没睡好,知道你下个月有项目压力,知道你妈妈过敏不能吃海鲜。它会在合适的时候,帮你做合适的事。
第二件,是它会变成最了解你的“数据库”。
当一家公司知道你这么多事——你说过的每句话、你拒绝过的每件事、你犹豫过的每个瞬间——
它对你的影响力,会远超过任何一个人类。
孔子在《论语》里说过一句话,”己所不欲,勿施于人”。
这句话的前提是:两个人之间是平等的。
但当一个 AI 比你自己更了解你,当它的”建议”是基于它对你的全部画像——
你和它之间,还平等吗?
站台和列车
文章开头我讲了 Hermes 推送新版本那个画面。
现在再回到那个画面——
GitHub 上一个不起眼的项目,悄悄推了一个 Python 文件。
没有发布会,没有融资稿。
但它做的事,可能让 AI 第一次拥有了”经验”。
2026 年的春天,列车在加速。
有人在造神,有人在守夜,有人在缝补裂缝,有人在悄悄掉队。
但站台还在那里。
站台上有一些没法被压缩、没法被技能化、没法被算进 token 账单的东西——
一个朋友看你脸色就知道你不开心的瞬间,一个陌生人在地铁让座的瞬间,一个深夜你妈给你打电话只是想听你声音的瞬间。
AI 可以学会做日报,学会写代码,学会模仿你妈的语气。
但站台上的那些东西,它学不会。
或者更准确地说——
它能学会模仿,但学不会“在场”。
写在最后
如果你今天还在做 AI 产品,不管做的是模型、工具、UI、Agent,我都想留一句话给你:
2026 年的下半场,模型是租来的,工具是抄来的,UI 是改来的——但用户和你的产品一起花过的时间,谁也抢不走。
如果你的产品还停留在”模型套壳 + 工具堆叠”,今晚就开始想你的 Skills 该怎么做。
如果你的产品已经开始记得用户,今晚就开始想你的边界该划在哪里。
列车已经开了。
站台上的人,请保重。
本文由 @Mark-AIPM 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


