
 起点课堂会员权益
起点课堂会员权益如何靠 AI “三位一体”实现全量轨迹下的用户增长?
在《智能时代》中,吴军博士指出:任何一次技术革命,都是由于发现了一种可以极大地提高效率的新能源或新动力。在当前的数字化战场,App 用户增长的“新能源”正是数据,而驱动增长的引擎则是 AI 的“三位一体”。

大数据(新能源):从“局部样本”到“全量轨迹”
传统的增长依赖于抽样调查或单一维度(如年龄、地区)的标签。但在 AI 框架下,大数据意味着全维度、全流程、实时性。相对传统增长更依赖于用户深度行为数据相互依赖关系,关注数据的集中性和全流程的数据规律总结。
1. 数据深度(深度行为)
数据深度是指:不再仅关注点击和下载,而是挖掘用户进入 App 后的微观轨迹(滑动热点、停留时长、功能点击顺序)。这些是预测 LTV(生命周期价值)最真实的燃料。
传统的 LTV 计算往往是滞后的(Post-Factum),比如看 30 天或 90 天的实际收入。但增长需要预测(Prediction)。微观轨迹数据的价值在于它们是先导性指标(Leading Indicators),最长用的是数据来源:滑动热点追踪+页面停留时长+页面点击顺序。
1)滑动热点 (Scroll Heatmaps & Touch Heatmaps)
记录用户手指在屏幕上滑动和点击的精确位置。
为什么重要?
它揭示了用户的注意力分布和操作阻力。
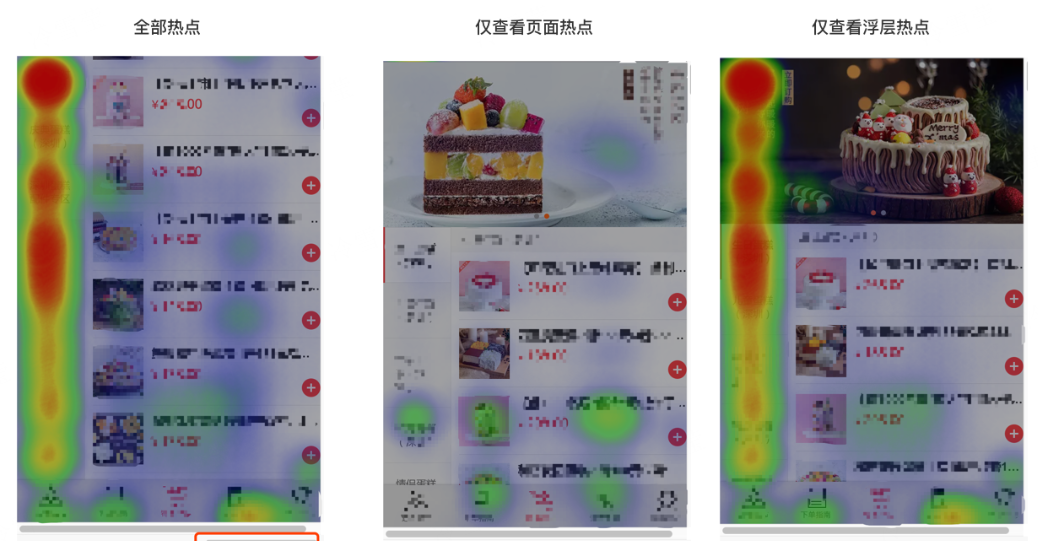
例如一个电商公司如何通过滑动热点进行LTV 预测逻辑:
如果一个电商 App 用户在详情页上,手指反复在“商品参数”和“评论区”之间滑动,但迟迟不点“购买”,这预示着他是一个高意向但价格/质量敏感的用户。这种行为模式可能指向一个中等 LTV 但需要促销刺激的群体。相反,如果用户在页面上快速滑动到底部,然后退出,这可能是一个低 LTV 的“闲逛者”。
2) 停留时长 (Dwell Time & Hover Time)
精确到毫秒记录用户在某个页面、甚至某个特定元素(如一张图片、一段文字)上停留的时间。它反映了用户的兴趣深度和信息处理难度。
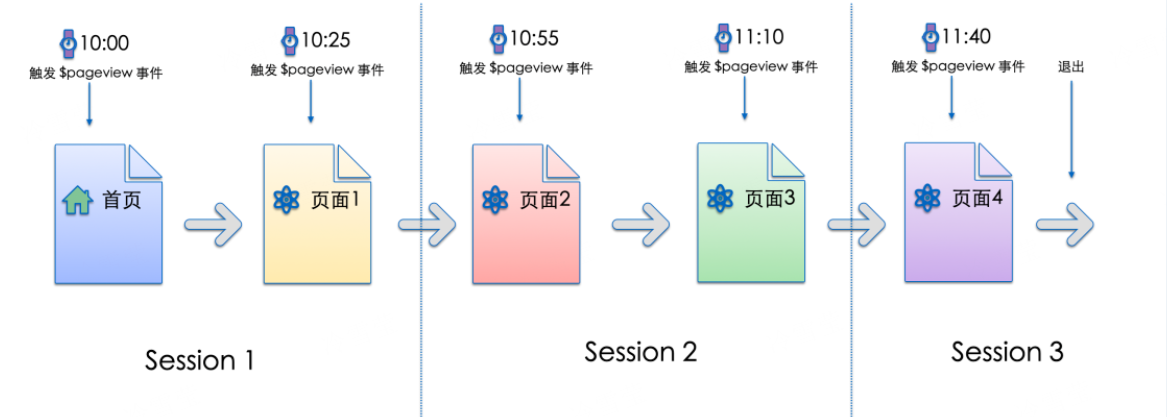
利用停留时长对LTV 预测逻辑:
- 内容类 App (如小红书/TikTok): 一个新用户在某篇关于“高定礼服”的笔记上停留了 45 秒(远超平均的 15 秒),即使他没有点赞,这个微观停留时长也强烈暗示了他对高客单价商品的潜在兴趣,是高 LTV 用户的重要特征。
- 工具类 App: 如果用户在“设置”页面停留过久,可能意味着他遇到了困难,这反而是流失风险的信号。
3. 功能点击顺序 (Click Sequence / User Path)
用户在 App 内操作的具体步骤和先后顺序。它揭示了用户的目的性和使用习惯。
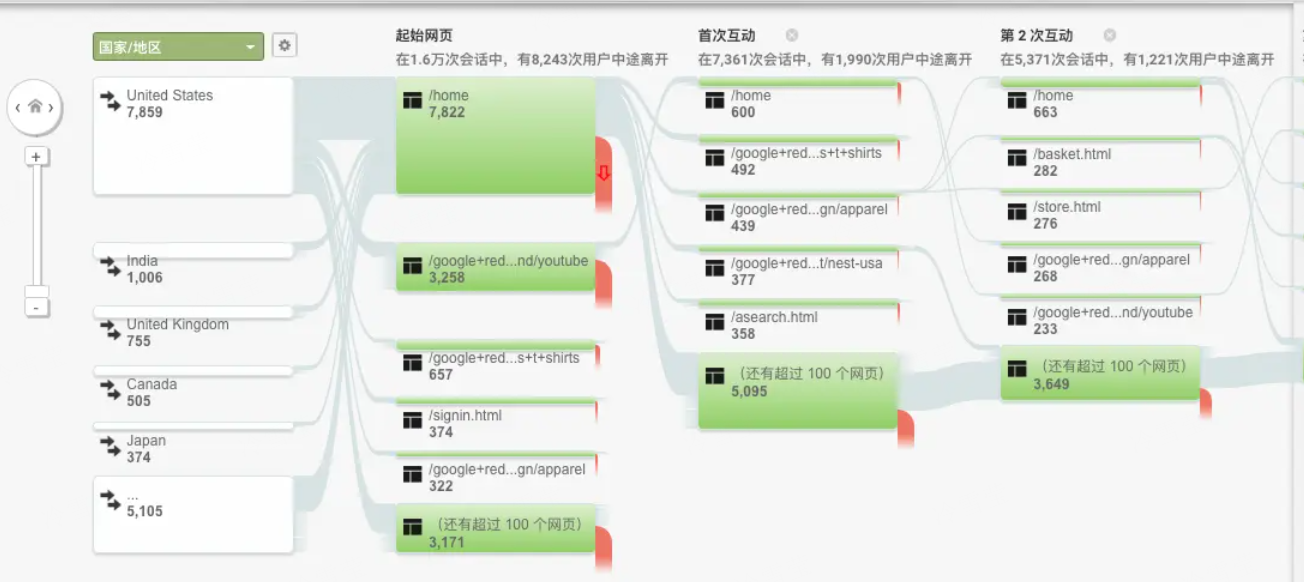
利用功能点击顺序进行LTV 预测逻辑:
- 路径 A(高 LTV 特征): 新用户注册 -> 首页 -> 搜索特定品牌 -> 进入商品详情页 -> 收藏。这条路径显示了强烈的目的性和明确的购买意图。
- 路径 B(低 LTV 特征): 新用户注册 -> 首页 -> 点击横幅广告 -> 立即退出 App。这条路径显示了低质量流量的特征。
传统增长 VS AI智能增长
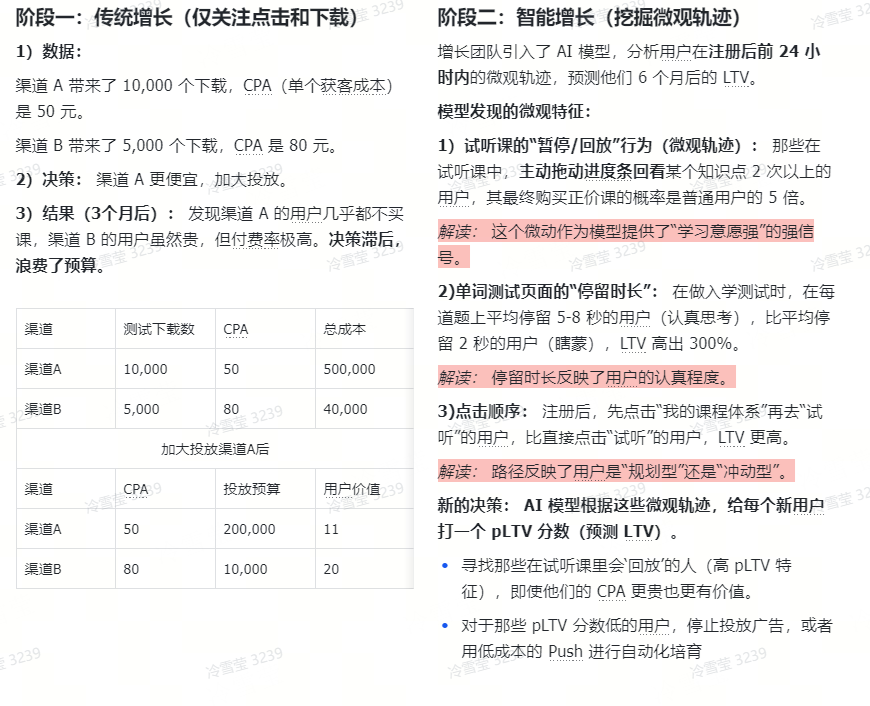
“挖掘深度行为和微观轨迹”,本质上是利用 AI 的算力,捕捉人类肉眼无法观察到的、海量的、细微的行为模式,从而比用户自己更早地预判他们的价值。
2.关联性取代因果
AI 不问“为什么”,它只看“是什么”。在大数据时代,只要相关性强度足够,它就可以直接转化为商业决策,而不必纠结于背后的动机。

为什么这种方式在 2026 年的 App 增长中更有效?
- 反应速度: 心理分析需要定性研究(慢),关联性分析只需要机器学习(快)。
- 规避偏见: 运营人员的经验往往带有个人偏见,而 AI 的关联性是纯粹基于结果的。
- 灰度成本低: 你可以同时针对 100 种莫名其妙的“关联性”进行小流量测试,最终留下的那个关联性就是你的“增长密码”。
增长应用: 建立全链路数据追踪系统,将过去散落在各渠道的归因数据、App 内行为数据和交易数据打通,形成统一的用户资产(Single Source of Truth)。
企业案例实战:AI “三位一体”如何驱动增长
1. 字节跳动(ByteDance / TikTok):极致的推荐与自动化留存
字节跳动是全球公认将“算法+数据+算力”融合得最完美的增长机器。
- 大数据(全量轨迹): TikTok 记录的不仅是你的点赞,还有你滑过视频的速度、在某帧的停顿、音量大小等极其细微的行为数据。
- 算法(强化学习): 它的推荐算法本质上是一个大规模强化学习系统。每当你滑掉一个视频,AI 就会收到一个“负反馈”,瞬间调整下一条内容的推送权重。
- 实际增长案例: * 获客: 字节在投放时,会利用 Lookalike(相似人群扩展) 算法。它先分析 App 内最高价值的 1% 用户特征,然后利用算力在全球数十亿设备中找出最像这群人的潜在用户进行精准投放。
- 留存: 著名的“沉默唤回”。如果一个用户 3 天没打开 App,AI 会根据其历史偏好预测哪一条内容最能吸引他点开,并在他最习惯看手机的时间点(算力预测)发送 Push。
2. 某视频 App 的“音量调节”与流失预测
这是一个更细微的、非直觉的相关性案例。
- 发现相关性: 数据平台监测到,如果一个新用户在观看第一个视频时,频繁调节音量或反复拖动进度条,其 24 小时流失率比普通用户高 3 倍。
- 分析: 机器不关心他是否心情烦躁。机器只看到这个行为模式。
- 增长动作(实时干预): 当 AI 发现新用户正在“频繁调音量/进度条”时,立即判定该用户处于“体验挫败”状态,系统瞬间弹出一个高清切换指引或赠送一张会员体验券,强制打断流失路径。
3. Netflix(奈飞)的“色调偏好”与留存
- 传统心理猜测: 运营认为用户流失是因为“最近没好剧看”。于是花大钱买版权、推大片。 AI 特征识别: Netflix 的算法发现,用户点击视频的决定因素,往往不是剧情简介,而是预览海报(Thumbnail)的色调和构图。
- 特征发现: 数据显示,某些用户群对“暗黑、冷色调、特写镜头”有极高的点击相关性;而另一些用户对“明亮、多人合影”有强反应。
- 增长动作: Netflix 针对同一部电影,实时生成几十种不同风格的海报。如果算法识别出你过去点开的都是暗色调封面,那么即便是一部喜剧片,它推给你的海报也会选一张色调较深、带有忧郁感的剧照。
- 结果: 这一动作极大降低了用户的“决策成本”,从而大幅提升了长期的订阅留存。
增长思维的升维:从“经验主义”到“数据主权”,过去的增长: 人工看数据(少量) -> 人工想策略(简单算法) -> 人工执行(低算力)。未来的增长: 系统收全量数据 -> AI 自动建模 -> 机器实时执行(高算力)。
总结一句话: 高阶增长专家的价值在于:能够定义好业务场景,然后组织起最合适的“数据”,选择最有效的“算法”,并利用公司的“算力”去实现规模化增长。
本文由 @ Sherryyyyy 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


