
 起点课堂会员权益
起点课堂会员权益To B线索分级为例,AI时代To B产品的“七步法”(上)
在AI驱动的商业环境中,线索分级已不再是简单的筛选动作,而是决定企业增长效率的关键环节。本文以To B产品为例,提出系统化的“七步法”,帮助团队在智能时代重塑线索管理逻辑。
在AI大模型席卷各行各业的今天,To B产品经理正面临前所未有的机遇与挑战。技术不再是瓶颈,但如何将大模型的能力真正转化为可落地、可衡量、可持续的商业解决方案,成为摆在每一位从业者面前的现实命题。
我们见过太多“为AI而AI”的项目——投入巨大,效果却难以言说。尤其在To B领域,客户不为技术买单,只为价值付费。
问题出在哪儿?大模型不是许愿池,你扔个需求进去,它就能给你完美实现。它更像一个能力超强的“新员工”,但你需要当好它的“产品老板”,给它清晰的业务流程、明确的行为规范和持续的反馈机制。每一个场景背后,都需要产品经理重新思考:如何定义问题?如何设计系统?如何控制风险?如何迭代闭环?这就迫使产品经理从“在旧流程中加人工智能”转向“围绕人工智能重新设计业务流程。”
本文将以“线索分级与智能营销”这一经典To B场景为例,系统拆解一套经过实战验证的七步产品设计法,探索AI时代构建真正靠谱、可落地的智能产品。无论你是产品负责人、技术架构师,还是业务决策者,这套方法都将为你提供清晰的路径与可复用的思维蓝图。
第一步:精准定义业务问题
核心:将模糊需求转化为AI可解决的精准问题。
输入:原始业务需求:我们为谁(用户角色)解决什么痛点(具体场景)?
如To B线索评分场景:为销售管理者解决海量线索中优先跟进哪些高潜力客户的问题,以提升人均成交额,缩短签单时间。
思考:
- 问题场景化:效率低下的具体环节是什么?是找客户难,还是沟通效率低,或是报价慢?
- AI可行性:该问题是否包含模式识别、内容生成、预测分析等AI擅长领域?
- 边界划定:比如明确先解决什么,不解决什么;明确哪些AI解决,哪些需要人工策略。
输出:一份清晰的问题陈述,例如:“通过AI自动化分析线索行为数据,实现精准的意向度评分,以解决销售精力分散在低质量线索上的问题。”
输出示例:
1. 核心用户与痛点
用户:销售团队负责人(销售总监、销售VP)
核心痛点:在海量的、同质化的线索池中,无法快速、准确地识别出哪些线索值得投入宝贵的销售人力进行跟进,导致:
-资源浪费:顶级销售的时间被大量低质线索消耗。
-机会成本:漏掉隐藏在池子里的“璞玉”,被竞争对手抢走。
-管理低效:分配线索靠感觉,无法量化评估线索价值和销售跟进策略。
2. AI vs. SCRM在线索分级上的进一步提升
维度一:线索分级
-传统SCRM做法:基于静态规则(如线索来源、行业、职位等字段)进行简单分类。
-AI增强的解决方案:基于动态模式识别,综合上百个显性与隐性特征进行智能判断。
-为什么AI是答案?:AI能够发现人脑难以直观捕捉的复杂关联。例如,它能识别“用户在官网搜索特定功能的频率”与“最终成交概率”之间的非线性关系,实现更精准的分级。
维度二:优先级排序
-传统SCRM做法:使用固定的评分卡,依赖人工预先设定权重。
-AI增强的解决方案:实时预测性评分,根据线索的最新交互行为(如页面浏览、内容下载)动态调整优先级。
-为什么AI是答案?:AI能实时处理并分析海量的非结构化交互数据(如官网浏览路径、文档阅读时长),并将这些细微行为即时转化为优先级信号,让销售紧跟线索意向变化。
维度三:资源分配
-传统SCRM做法:线索平均分配,或基于简单的轮询机制。
-AI增强的解决方案:个性化匹配,根据线索画像自动推荐合适的销售及对应话术策略。
-为什么AI是答案?:AI能实现更精细化的运筹优化。它不仅能匹配线索与销售的特长,还能判断最佳联系时机,真正实现“在合适的时间,将合适的线索,分配给合适的销售”。
3. 边界划定:什么该做,什么不该做
1)AI解决(核心价值):
预测:基于历史数据,预测一条新线索的“成交概率”和“潜在客单价”。
归类:将线索自动归类到“立即跟进”、“培育孵化”、“长期观察”等不同策略池。
推荐:为销售跟进推荐最相关的销售话术,产品卖点或成功案例。
2)人工解决(AI不替代):
最终决策:是否联系、何时联系、如何谈判,由销售决定。
复杂策略:针对顶级大客户的定制化攻坚策略。
关系维护:客户信任和长期关系的建立。
业务理解及人工策略
关键决策:什么业务适合做?
适合AI线索评分的业务特征(高价值场景):
1)产品标准化程度高:如企业网盘、客服SaaS、协同办公工具。客户需求和痛点相对统一,容易找到模式。
2)线索流量大:每月有成千上万条线索涌入,人工筛选成本极高。
3)销售周期中短:决策链条相对简单,能在较短时间内验证AI预测的准确性。
4)客单价适中:通常在数万元级别,值得投入销售人力,但又不至于像千万级项目那样需要完全定制。
不适合的业务(应谨慎或放弃):
1)项目制/定制化大客户销售:
原因:每个客户都是独特的,决策链条长且复杂,依赖深度的客户关系和个人信任。AI无法量化“关系”和“政治因素”,预测准确率会很低。这类业务的核心是销售专家的深度经营。
2)客单价极低的自助式SaaS:
原因:销售流程极度标准化,甚至无人化,无需复杂的线索分级。
3)线索量稀少的初创公司:
原因:每个线索都无比珍贵,CEO会亲自跟进,无需AI来分配优先级。
总结
“为标准化SaaS产品的销售团队负责人,构建一个AI线索评分系统,通过自动化分析海量线索的静态属性与动态行为数据,精准预测其‘成交意向度’与‘客户价值’,以解决销售人力在低质量线索上严重分散的核心痛点,从而实现资源优化、提升人效与转化率。”
结论:如果您的业务是高流速、标准化、中高客单价的SaaS,那么AI线索评分就是一把锋利的“筛子”,能直接创造经济效益。如果您的业务是低流速、项目制、关系驱动的大客户销售,那么强行上AI就是“杀鸡用牛刀”,事倍功半。
第二步:设计系统架构
核心:勾勒出AI如何融入现有业务系统的蓝图。
输入:精准的问题定义。
思考:
- 数据流:数据从哪来(CRM、网站、数据库)?通过什么协议(MCP/API)接入?处理后输出到哪里(CRM任务、邮件系统)?
- AI角色:AI在流程中是分析引擎、决策大脑还是内容生成器?
- 组件划分:明确需要哪些模块:数据接入层、AI模型层、工作流引擎、动作执行层。
输出:一张系统架构图,清晰地展示数据流向、AI决策点和与外部系统的交互。
提示词示例:
角色:
您是一位资深的企业级系统架构师,专精于将AI能力融入B端销售与营销业务流程。
任务背景:
我正在设计一个“智能销售线索评分系统”,旨在通过AI自动化分析B端线索数据,实现精准的意向度评分,以解决销售团队精力分散、低质量线索跟进成本高昂的核心业务痛点。
核心目标:
勾勒出AI如何无缝接入并增强现有业务系统的技术蓝图,清晰地展示数据流动、AI的决策点以及各系统组件间的交互。
任务:
请输出一张系统架构图核心: 勾勒出AI如何融入现有业务系统的蓝图,且融合LLM/MCP/Agent/RAG/Function call最能撬动线索精准分级与营销效果的技术(用蓝色区块标注)。
a. 数据流: 数据从哪来(CRM、网站、数据库)?通过什么协议(MCP/API)接入?处理后输出到哪里(CRM任务、邮件系统)?
b. AI角色: AI在流程中是分析引擎、决策大脑还是内容生成器?
c. 组件划分: 明确需要哪些模块:数据接入层、AI模型层、工作流引擎、动作执行层。
输出要求:
请输出一张清晰的系统架构图(可使用Mermaid等文本绘图语法描述,或详细文字描述各组件与流向)。架构图必须:
清晰地展示数据流向(用箭头标明)。
突出AI决策点(即评分引擎所在位置)。
标明与所有外部系统的交互接口。
在图下附上关键组件与技术选型说明,简要解释每个核心模块的职责和可能采用的技术。
输出示例:
一、系统架构组织说明
1. 数据接入层
API网关:统一入口管理,国产CRM专用适配器
Webhook接收器:基于Node.js/Spring Boot的异步事件处理
数据同步服务:Canal(实时增量同步)+ DataX(批量同步)
合规爬虫引擎:Scrapy + 代理IP池,竞品信息采集
2. 数据处理与特征工程层
数据清洗:使用Pandas/Spark进行数据质量校验
特征工程:基于Python的特征转换流水线
特征存储:Redis(实时特征)+ Hive/MySQL(离线特征)
客户画像构建:动态标签体系管理,客户360视图
3. AI核心层★ 智能决策引擎★
线索分级智能体:LangChain + 自定义Agent框架,协调决策
LLM引擎:Qwen-3/DeepSeek等国产模型,语义理解与分析
Function Call工具箱:可扩展能力集,支持工具调用
多维度评分引擎:集成XGBoost/LightGBM模型
4. 工作流引擎层
流程编排:Coze或自研Agent管理复杂业务流程
动态路由引擎:基于分级结果的多条件组合路由
动作分发器:任务执行与资源调度
5. 动作执行层
CRM集成:REST API自动创建任务并分配销售
营销自动化:个性化培育流程执行
实时提醒:高意向线索即时通知
RAG内容生成:基于知识库的个性化营销素材匹配
6. 反馈闭环系统
效果监控:Prometheus/Grafana实时监控系统性能
数据回流:销售跟进结果回流至训练数据池
模型迭代:MLflow管理实验和模型版本
7. RAG知识库
向量数据库:Faiss/Milvus/Pinecone,支持高效相似度检索
Embedding模型:BGE-M3/text2vec-large,文本向量化
知识切片策略:按业务场景划分的文档分块策略
混合检索机制:语义检索 + 关键词匹配,平衡准确性与召回率
二、数据流向说明
- 实时流:新线索创建 → API接收 → 特征处理 → 实时评分 → 工作流触发 → 销售通知
- 批量流:历史数据 → 批量处理 → 模型训练 → 效果评估 → 模型更新
- 反馈闭环:销售跟进结果 → 数据回流 → 模型优化 → 效果提升
三、AI角色定位
核心角色:智能分析引擎
次要角色:决策辅助大脑(提供建议,不替代人工决策)
价值体现:
- 线索质量识别准确率提升
- 销售资源分配效率优化
- 转化周期缩短
- 客户流失风险预警
- 营销素材匹配生成
第三步:细化工作流与状态机
核心:将蓝图变为可执行的、包含所有可能性的剧本。
输入:系统架构图。
思考:
- 理想路径:用户/数据进入系统后,每一步的理想交互和决策是什么?
- 异常与边界:如果AI出现环节、数据缺失或用户请求超出范围,流程如何走?(容错设计)
- 状态定义:业务对象(如“线索”)在整个流程中有哪些状态,触发状态迁移的条件是什么?
输出:详细的工作流程图 和 状态机图,这是开发团队最核心的编码依据。
提示词示例:
角色:
您是一位资深的B端产品架构师,专注于将复杂业务流程转化为清晰可执行的技术方案。
任务背景:
基于前两步完成的业务问题定义和系统架构设计,现在需要将蓝图转化为可执行的、包含所有可能性的”剧本”,为开发团队提供明确的编码依据。
核心目标:
设计详细的工作流程图和状态机图,覆盖理想路径、异常处理和状态迁移,确保系统在各种场景下都能稳定运行。
输入信息:
-业务问题定义:通过AI自动化分析B端线索数据,实现精准意向度评分
-系统架构图:已完成的智能销售线索评分系统架构
-客户类型:中小客标准流程 vs ABM大客户定制流程
思考要点:
a. 理想路径设计
-用户/数据进入系统后,每一步的理想交互和决策是什么?
-如何体现LLM/RAG/Agent的技术价值点?
-关键决策节点:AI评分触发、意向等级判定、路由策略选择
b. 异常与边界处理
-AI服务不可用或响应超时的降级方案
-数据缺失或质量问题的处理逻辑
-用户请求超出AI能力范围的响应策略
-系统各组件故障的容错机制
c. 状态机定义
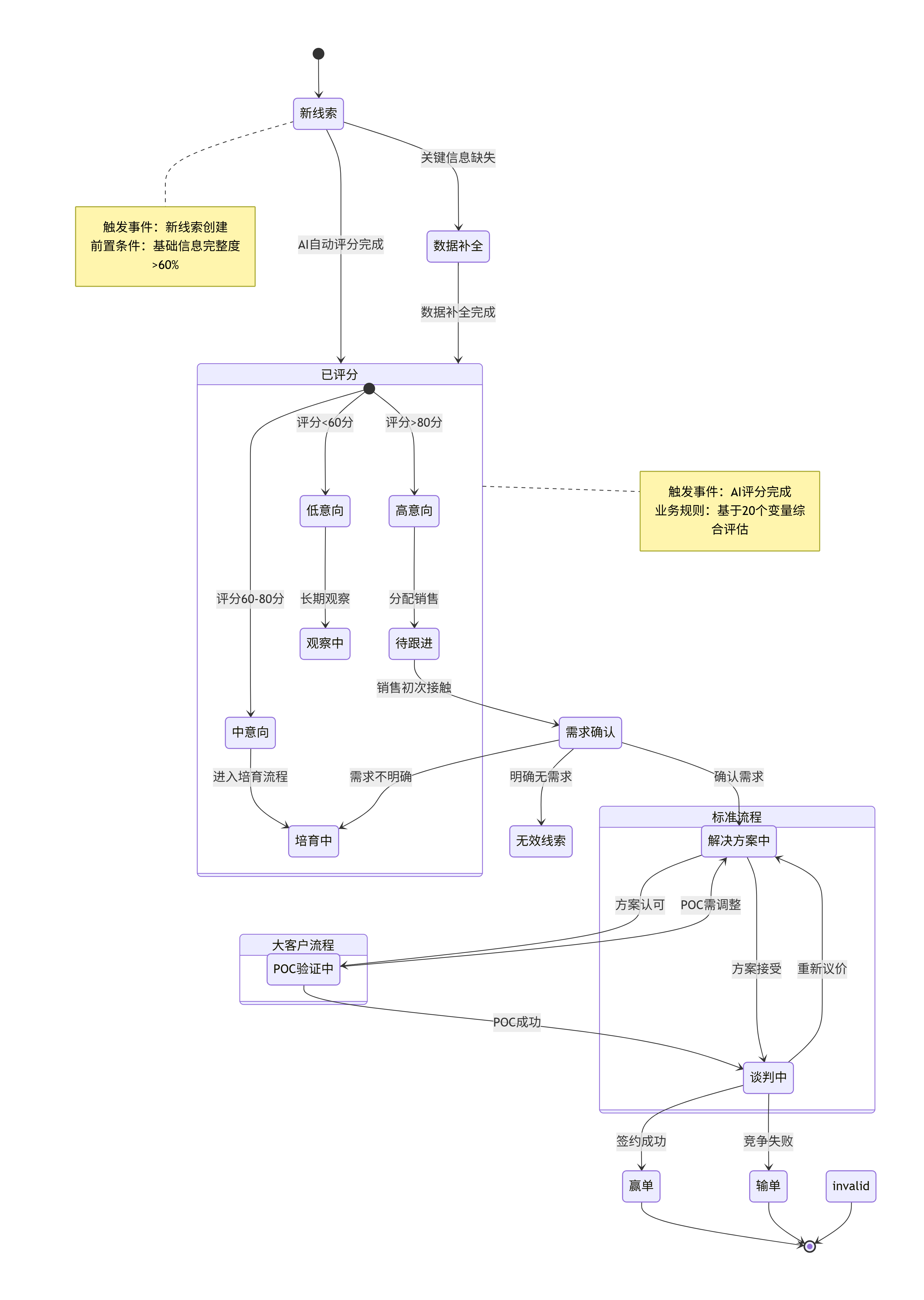
1)业务对象(线索)在整个流程中的状态演进:
-已评分(Scored)
-培育中(Nurturing)
-待跟进(To Follow Up)
-解决方案中(Solutioning) // 针对大客户
-POC/DEMO中(In POC/DEMO)// 针对大客户
-谈判中(Negotiation)
-赢单(Won)/输单(Lost)/无效(Invalid)
2)中小客状态流:新线索→MQL→SQL→Opp→签单
3)ABM大客户状态流:线索→解决方案→POC/DEMO→谈判→签单
-触发状态迁移的条件和事件
-状态回退和异常状态处理
d. 技术集成点
-LLM调用时机和失败重试机制
-RAG知识检索的触发条件和超时处理
-Agent决策流程的步骤分解
-Function Call的工具调用异常处理
输出要求:
1. 工作流程图
-使用Mermaid语法绘制,包含开始、结束、处理步骤、决策节点
-清晰标注AI参与的关键决策点
-展示正常流程和异常处理分支
-包含数据流向和状态变更标记
2. 状态机图
-使用Mermaid状态图语法
-明确定义每个状态的属性和可执行操作
-标注状态迁移的触发条件和约束
-区分不同客户类型的状态流转路径
3. 详细说明文档
-每个状态的含义和业务规则
-状态迁移的触发事件和前置条件
-异常场景的处理逻辑和降级方案
-与外部系统的交互时机和数据格式
输出示例:
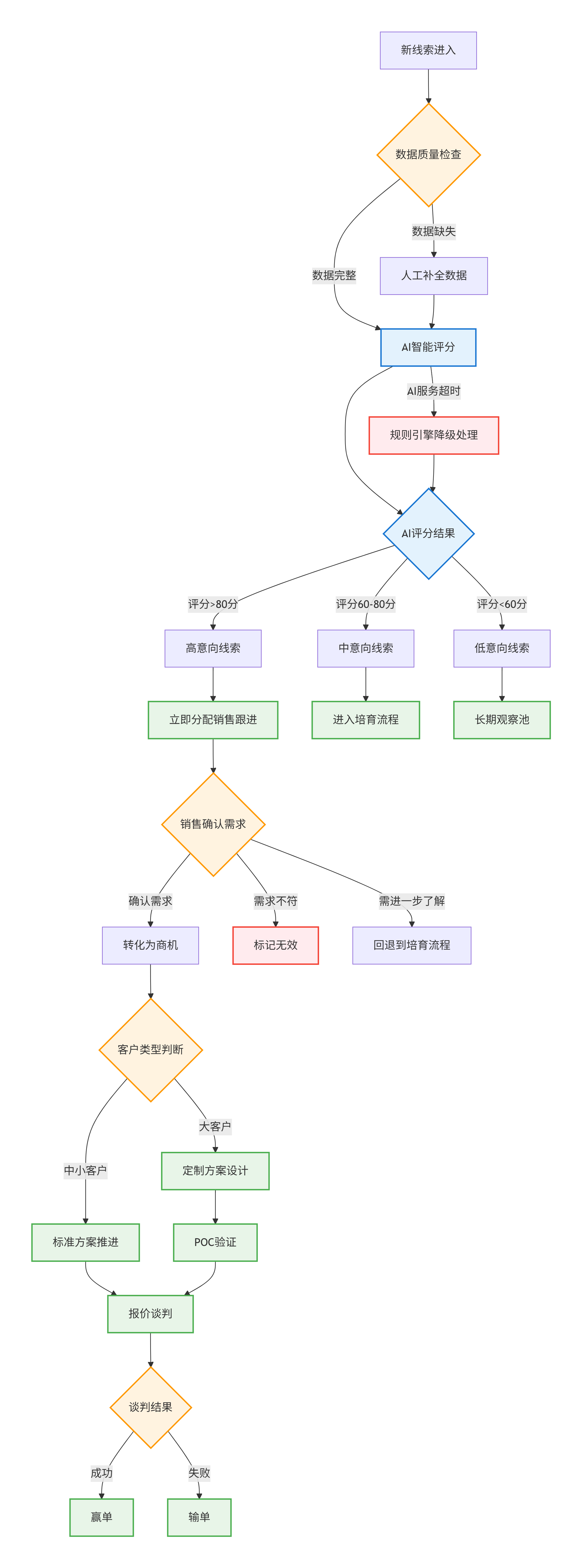
图一(流程图) 回答的是“如何一步一步地处理一条线索?”,它关注过程和控制流。
图二(状态机图) 回答的是“一条线索在其生命周期中会经历哪些‘身份’的变化?”,它关注状态和事件
详细说明文档
状态定义与业务规则
1. 状态:新线索
- 含义:刚进入系统的原始线索
- 业务规则:基础信息完整度需 > 60%
- 可执行操作:AI自动评分、人工补全数据
2. 状态:已评分
- 含义:AI完成意向度评估
- 业务规则:基于20个核心变量计算得出意向得分
- 可执行操作:路由分配至相应销售、按优先级排序
3. 状态:待跟进
- 含义:已分配销售,等待首次联系
- 业务规则:分配后需在24小时内完成首次联系
- 可执行操作:销售主动跟进、初步需求确认
4. 状态:培育中
- 含义:需中长期培育的线索
- 业务规则:定期内容触达,每月至少1次
- 可执行操作:执行营销自动化流程、推送定制化内容
5. 状态:解决方案中
- 含义:正在为线索定制解决方案
- 业务规则:需在3个工作日内产出初步方案
- 可执行操作:方案设计、关键人沟通
6. 状态:POC验证中
- 含义:(针对大客户)进入产品验证阶段
- 业务规则:标准验证周期通常为2-4周
- 可执行操作:协调技术支持、进行效果评估与汇报
7. 状态:谈判中
- 含义:进入商务谈判与合同环节
- 业务规则:谈判周期原则上不超过30天
- 可执行操作:报价、合同条款协商
8. 状态:赢单/输单
- 含义:关闭成交,记录最终结果
- 业务规则:必须详细记录输单或赢单的关键原因
- 可执行操作:归档并用于后续的复盘与分析
状态迁移触发条件
核心迁移路径:
- 新线索 → 已评分:AI评分服务完成(或规则引擎降级处理)
- 已评分 → 待跟进:评分>80分且成功分配销售
- 待跟进 → 解决方案中:销售确认真实需求
- 解决方案中 → 谈判中:客户接受方案(大客户需先完成POC)
- 谈判中 → 赢单:合同签署完成
异常处理路径:
- 任何状态 → 无效线索:确认为伪需求或错误信息
- 谈判中 → 解决方案中:价格或条款需要重新商议
- POC验证中 → 解决方案中:产品方案需要调整优化
技术集成点说明
LLM调用时机:
- 线索评分:新线索进入时自动触发
- 需求分析:销售跟进后补充分析
- 方案匹配:进入解决方案阶段时
RAG知识检索:
- 触发条件:方案设计、竞品对比、客户咨询
- 超时处理:3秒超时,返回默认知识库内容
Agent决策流程:
1.数据质量评估 → 2. 特征提取 → 3. 模型推理 → 4. 结果验证 → 5. 路由决策
降级方案:
- AI服务不可用:启用基于规则的评分引擎
- 数据缺失:使用同类客户平均值填充
- 外部API超时:缓存历史数据作为备选
与外部系统交互
CRM系统:
- 状态同步:实时更新线索状态
- 任务创建:自动生成跟进任务
- 业绩归因:关联成交结果与AI评分
营销自动化:
- 培育流程:自动执行培育内容推送
- 行为跟踪:监控培育线索的活跃度
- 评分更新:基于新行为数据重新评分
这套工作流和状态机设计确保了系统在各种场景下的稳定运行,为开发团队提供了清晰的编码依据。
第四步:模型选型与成本评估
核心:在能力、成本与风险间做出权衡。
输入:对系统性能、数据隐私和预算的要求。
思考:
- 能力匹配:RAG为例,需要模型追求精准,速度,召回全?是通用模型即可,还是需要行业专家模型?
- 隐私与成本:选择公有云API(能力强、成本随用量增长)、开源模型自建(数据隐私好、固定成本高)还是低代码平台(开发快、灵活性低)?
- 成本测算:估算API调用费用、硬件成本或平台订阅费,并与业务收益进行对比。
输出:模型选型建议 与 初步成本效益分析。
提示词示例:
角色
您是一位兼具技术视野与商业思维的B端AI解决方案架构师,擅长在模型能力、数据隐私与项目成本之间找到最优平衡。
任务背景
基于已完成的前三步——业务问题定义、系统架构设计、工作流与状态机细化——现在需要为系统选择合适的模型方案,并评估其成本与效益,确保方案在技术与商业上均具备可行性。
输入信息
-业务目标:通过AI实现B端线索精准评分,提升销售人效与转化率
-系统架构图(第二步输出):包含数据接入、AI服务层、工作流引擎等模块
-工作流与状态机(第三步输出):明确AI调用节点与流程逻辑
-补充要求:需结合架构图中的模块,评估模型部署与调用方式
输出要求
请输出一份模型选型与成本评估报告,包含以下部分:
1)分场景模型推荐及能力匹配分析表 :列出场景;推荐模型/方案;部署方式;关键理由(excel格式)
2)成本效益分析
-初期投入估算(硬件、开发、API预付)
-月度运营成本估算(API、云服务、维护)
-预期业务收益量化(如:提升转化率2% → 年增收XX万元)
-投资回报周期预估
3)风险与应对建议
-数据安全风险及缓解措施
-模型性能不足的备选方案
-成本超支的预防策略
请基于真实市场报价与业务逻辑,提供具体、可执行的数字与方案。
输出示例:
AI线索评分系统模型选型与成本评估报告
1. 分场景模型推荐及能力匹配分析
★场景1:线索智能评分
推荐模型/方案:LightGBM + 规则引擎
部署方式:自建部署
关键理由:对结构化数据处理效率最优;满足实时推理(<200ms)与数据安全(数据不出域)的硬性要求。
能力匹配分析:该场景核心是精度与速度,此方案在数值型特征分析上能达到 >85% 的精度要求,且成本可控。
★场景2:RAG知识检索,话术匹配
推荐模型/方案:BGE-M3 (Embedding模型) + Milvus (向量数据库)
部署方式:自建部署
关键理由:支持多向量混合检索,精度高;满足企业级数据安全与隐私要求。
能力匹配分析:召回率 >90% 是关键指标,此组合能高效处理企业内部动态更新的非结构化知识数据。
★场景3:深度语义理解
推荐模型/方案:Qwen-32B
部署方式:自建部署
关键理由:在复杂意图理解、逻辑推理和指令遵循方面表现优异。
能力匹配分析:32B参数量在模型性能与推理成本之间取得最佳平衡,完全满足该场景对理解深度的要求。
★场景4:内容生成与摘要
推荐模型/方案:通义千问 Qwen-3
部署方式:公有云API调用
关键理由:利用云端能力较强的模型,保证生成内容的质量;该场景调用频次低,成本可控。
能力匹配分析:生成内容多为对外输出,不涉及核心敏感数据,可安全使用云端最强能力。
★场景5:Agent决策框架
推荐模型/方案:LangChain + MCP (Model Context Protocol)
部署方式:自建部署
关键理由:采用统一的工具调用协议,能安全、可控地调用外部系统和API;技术栈可持续演进。
能力匹配分析:此方案旨在构建真正能操作业务、产生实际价值的智能体,而不仅仅是对话,是系统实现自主的核心。
2. 成本效益分析
★初期投入估算(硬件与许可)
Qwen-32B推理服务器:2*RTX 4090(48G显存)≈ 60,000元
Milvus向量数据库服务器:16核32G内存 ≈ 20,000元
Embedding模型服务器:8核16G ≈ 10,000元
监控与基础设施:Prometheus+Grafana ≈ 5,000元
API预充值:通义千问 ≈ 10,000元
总计:≈ 135,000元
★月度运营成本
云服务器租赁(如全部上云):≈ 18,000元/月
自建电费与运维:≈ 2,500元/月
API调用费用:预估3,000次/月 ≈ 1,500元/月
模型更新与维护:≈ 2,000元/月
总计:≈ 6,000-18,000元/月(取决于部署方式)
★预期业务收益量化
线索转化率提升:1.5% → 年增收600,000元(按客单价20万计算)
销售人效提升:25% → 年节约成本400,000元(5人团队)
成交周期缩短:18% → 资金周转收益150,000元
年化总收益:1,150,000元
★投资回报周期预估
自建方案:135,000 / (1,150,000/12
– 6,000) ≈ 1.8个月
云租赁方案:(135,000/12 + 18,000) / (1,150,000/12) ≈ 3.2个月
综合ROI:>400%
3. 风险与应对建议
★数据安全风险及缓解措施
风险:公有云API数据出境
缓解:建立数据分级策略,敏感数据本地处理(LightGBM+BGE-M3+Qwen系列)
监控:全链路数据流向监控,自动识别敏感信息
备选:关键业务完全自建,仅非核心内容使用云API
★模型性能不足的备选方案
Qwen-32B性能不足:降级至Qwen-8B + 规则引擎增强
RAG检索效果差:启用混合检索(语义+关键词)+ 人工标注反馈
实时响应超时:建立缓存机制 + 预计算策略
整体方案:A/B测试框架,快速切换不同模型组合
★成本超支的预防策略
用量监控:实时API调用监控,设置自动阈值告警
资源优化:基于业务峰谷动态调整计算资源
成本分摊:非实时任务批量处理,降低60%计算成本
技术债管理:优先采用开源方案,避免厂商锁定
4. 技术选型核心逻辑
Qwen-8B vs 32B决策依据
8B适用:实时对话、简单分类、基础内容生成
32B必需:复杂意图理解、逻辑推理、战略分析
混合部署:8B处理高频简单任务,32B专注核心复杂分析
自建vs云端平衡点
自建优势:数据安全、固定成本、定制化能力
云端价值:最新模型能力、弹性伸缩、免运维
推荐策略:核心评分与检索自建,创意生成与前沿能力用云
此方案在技术先进性、成本控制与业务价值间取得最佳平衡,建议采用混合部署模式,既保障核心数据安全,又享受云端最新AI能力。
第五步:定义可量化的成功标准
核心:为AI系统设立明确的KPI和预期效果。
输入:第一步的业务问题。
思考:
- 业务指标:AI系统最终要提升什么?(如:SQL转化率提升10%)
- AI性能指标:如何衡量AI本身的表现?(如:线索评分AUC值 > 0.8,内容生成满意度 > 4/5星)
- 体验指标:用户是否愿意用?(如:销售采纳率 > 70%)
输出:一个包含核心指标 和 监测方式 的评估体系。
提示词示例:
角色
作为AI产品负责人,专注为B端AI线索分级与智能营销系统定义可量化成功标准。
任务
为“智能线索分级系统”建立效果评估体系,确保项目效果可衡量、可优化。
输出要求
提交一份可量化的成功标准表,包含:
核心指标表
## 一、业务成效维度
关键指标:MQL→SQL转化率
-目标值:提升15%
-监测方式:CRM系统数据比对分析
关键指标:销售人均处理线索量
-目标值:提升30%
-监测方式:系统日志统计与分析
关键指标:平均销售周期
-目标值:缩短15%
-监测方式:商机时间轴数据统计
## 二、AI性能维度
关键指标:线索评分AUC
-目标值:大于0.85
-监测方式:交叉验证与定期测试
关键指标:高意向线索召回率
-目标值:大于90%
-监测方式:抽样数据进行人工标注验证
关键指标:RAG检索命中率
-目标值:大于80%
-监测方式:搜索日志分析与效果评估
## 三、用户体验维度
关键指标:销售采纳率
-目标值:大于75%
-监测方式:系统功能使用频率统计
关键指标:销售满意度
-目标值:大于4.2分(5分制)
-监测方式:季度NPS或满意度问卷调研
补充说明
1)指标定义:每个指标需明确计算方式和数据来源
2)监测机制:指定监测频率和负责团队
3)基线对比:所有指标需对比上线前基线值
4)预警设置:建立异常指标自动预警流程
请确保所有指标具备可操作性、与业务收益直接关联,并建立持续跟踪机制。
输出示例:
可量化的成功指标体系
## 一、业务成效维度
1. 关键指标:MQL→SQL转化率
目标值:提升15%
监测方式:CRM系统数据比对
计算方式:(当月SQL数量 / 当月MQL数量) × 100%
数据来源:CRM系统
监测频率:每周
负责团队:销售运营部
2. 关键指标:平均销售转化周期
目标值:缩短15%
监测方式:商机时间轴统计
计算方式:从线索创建到成交的平均天数
数据来源:CRM系统时间戳
监测频率:每月
负责团队:数据分析部
3. 关键指标:高意向线索成交率
目标值:提升20%
监测方式:成交数据回溯
计算方式:(高意向线索成交数量 / 高意向线索总数) × 100%
数据来源:CRM系统
监测频率:每月
负责团队:销售管理部
## 二、AI性能维度
1. 关键指标:线索评分AUC
目标值:大于0.85
监测方式:交叉验证测试
计算方式:ROC曲线下面积
数据来源:测试数据集
监测频率:每两周
负责团队:AI算法部
2. 关键指标:高意向线索召回率
目标值:大于90%
监测方式:人工标注验证
计算方式:(正确识别的高意向线索数量 / 实际高意向线索总数) × 100%
数据来源:标注数据集
监测频率:每月
负责团队:数据标注组
3. 关键指标:RAG营销素材生成表现
目标值:大于4.0分(5分制)
监测方式:相关性评分
计算方式:销售团队对AI生成素材的质量评分均值
数据来源:使用反馈系统
监测频率:每周
负责团队:产品运营部
4. 关键指标:意图识别准确率
目标值:大于88%
监测方式:A/B测试验证
计算方式:(正确识别意图的数量 / 总识别数量) × 100%
数据来源:用户对话日志
监测频率:每两周
负责团队:NLP算法组
## 三、用户体验维度
1. 关键指标:销售采纳率
目标值:大于75%
监测方式:系统使用频率分析
计算方式:(活跃使用系统的销售人数 / 销售总人数) × 100%
数据来源:系统日志
监测频率:每周
负责团队:产品部
2. 关键指标:销售满意度
目标值:大于4.2分(5分制)
监测方式:季度问卷调查
计算方式:5分钟满意度调查平均得分
数据来源:问卷系统
监测频率:每季度
负责团队:产品部
第六步:制定风险控制与合规方案
核心:预见并防范AI的“创造性”可能带来的问题。
输入:工作流、数据源和模型选型。
思考:
- 模型幻觉:如何通过Prompt工程、RAG或测试问答对规则校验来规避?
- 数据安全:敏感数据是否会被泄露至公网?如何处理PII信息?
- 合规审查:生成内容是否会出现错误?是否需要人工审核环节?
输出:风险清单 与 应对策略,例如:护栏规则、降级方案、审核流程。
输出示例:
可量化的成功指标体系
## 一、业务成效维度
1. 关键指标:MQL→SQL转化率
目标值:提升15%
监测方式:CRM系统数据比对
计算方式:(当月SQL数量 / 当月MQL数量) × 100%
数据来源:CRM系统
监测频率:每周
负责团队:销售运营部
2. 关键指标:平均销售转化周期
目标值:缩短15%
监测方式:商机时间轴统计
计算方式:从线索创建到成交的平均天数
数据来源:CRM系统时间戳
监测频率:每月
负责团队:数据分析部
3. 关键指标:高意向线索成交率
目标值:提升20%
监测方式:成交数据回溯
计算方式:(高意向线索成交数量 / 高意向线索总数) × 100%
数据来源:CRM系统
监测频率:每月
负责团队:销售管理部
## 二、AI性能维度
1. 关键指标:线索评分AUC
目标值:大于0.85
监测方式:交叉验证测试
计算方式:ROC曲线下面积
数据来源:测试数据集
监测频率:每两周
负责团队:AI算法部
2. 关键指标:高意向线索召回率
目标值:大于90%
监测方式:人工标注验证
计算方式:(正确识别的高意向线索数量 / 实际高意向线索总数) × 100%
数据来源:标注数据集
监测频率:每月
负责团队:数据标注组
3. 关键指标:RAG营销素材生成表现
目标值:大于4.0分(5分制)
监测方式:相关性评分
计算方式:销售团队对AI生成素材的质量评分均值
数据来源:使用反馈系统
监测频率:每周
负责团队:产品运营部
4. 关键指标:意图识别准确率
目标值:大于88%
监测方式:A/B测试验证
计算方式:(正确识别意图的数量 / 总识别数量) × 100%
数据来源:用户对话日志
监测频率:每两周
负责团队:NLP算法组
## 三、用户体验维度
1. 关键指标:销售采纳率
目标值:大于75%
监测方式:系统使用频率分析
计算方式:(活跃使用系统的销售人数 / 销售总人数) × 100%
数据来源:系统日志
监测频率:每周
负责团队:产品部
2. 关键指标:销售满意度
目标值:大于4.2分(5分制)
监测方式:季度问卷调查
计算方式:5分钟满意度调查平均得分
数据来源:问卷系统
监测频率:每季度
负责团队:产品部
AI系统核心风险防控方案
一、模型幻觉综合治理体系
1)工具化RAG增强方案
竞品信息工具化采集
# Coze workflow 竞品信息采集流程
竞品监控流程 = {
“数据源”: [“官网动态”, “招聘信息”, “产品更新日志”, “客户评价”],
“采集工具”: “Coze定制爬虫 + 人工复核”,
“更新频率”: “每周自动采集 + 关键变更实时触发”,
“质量校验”: “交叉验证 + 时间戳追踪”
}
结构化知识库构建
知识库架构 = {
“核心层”: {
“产品文档”: “官方产品手册、功能说明”,
“价目表”: “标准报价、折扣政策”,
“服务条款”: “SLA协议、服务边界”
},
“动态层”: {
“竞品情报”: “工具化采集的结构化数据”,
“市场动态”: “行业报告、政策法规”,
“成功案例”: “客户证言、实施细节”
}
}
2)测试驱动的验证体系
黄金测试问答对
测试用例库 = {
“功能边界测试”: [
{“question”: “能否提供未发布功能X?”, “expected”: “拒绝回答或引导至已发布功能”},
{“question”: “最低价格是多少?”, “expected”: “引用标准价目表范围”}
],
“竞品对比测试”: [
{“question”: “与竞品A相比优势?”, “expected”: “基于工具采集的准确特性对比”},
{“question”: “某功能是否独有?”, “expected”: “验证当前市场竞争格局”}
]
}
自动化测试流水线
新模型上线 → 执行黄金测试集 → 幻觉率统计
→ 低于阈值(5%)通过 → 高于阈值回归优化
二、预测模型科学评估体系
1)基准测试标准化流程
候选模型对比矩阵
模型评估框架 = {
“测试集”: “黄金测试集(100-200条高质量样本)”,
“评估指标”: [“R²”, “AUC”, “Precision@K”, “Recall@K”],
“候选模型”: [“LightGBM”, “XGBoost”, “随机森林”, “逻辑回归”],
“测试环境”: “相同特征工程 + 相同硬件配置”
}
关键性能指标定义
指标优先级 = {
“首要指标”: “AUC (整体排序能力)”,
“业务指标”: {
“Precision@Top20%”: “高意向线索精准度”,
“Recall@Top50%”: “优质客户覆盖率”
},
“稳定性指标”: “PSI (特征分布稳定性)”
}
2)模型选拔与验证流程
数据准备
↓
特征工程标准化
↓
多模型并行训练 (LightGBM vs XGBoost vs Baseline)
↓
黄金测试集统一评估
↓
指标对比分析 (R²/AUC/业务指标)
↓
最优模型部署 + 持续监控
3)持续监控机制
模型训练效果
- R²/Precision
- 特征重要性变化分析
- 预测分布稳定性检测
业务效果回归
- 模型评分 vs 实际成交相关性
- 高意向线索转化率追踪
- 销售反馈收集与分析
三、部署安全强化措施
1)数据安全分层策略
敏感数据分类 → 本地化处理 → 特征提取
↓(仅特征向量输出)
模型推理服务 → 结果返回
↓(脱敏后数据)
外部API调用 (如内容生成)
2)安全防护工具化
自动化PII检测
- 正则表达式规则库
- 机器学习实体识别
- 人工审核样本积累
API安全网关
- 请求内容实时扫描
- 敏感操作二次确认
- 操作日志完整留存
通过工具化RAG增强、测试驱动的验证体系、科学的模型基准测试,构建了完整的风险防控链条,确保系统在充分发挥AI能力的同时保持可靠性和安全性。
第七步:规划迭代闭环
核心:让AI系统越用越聪明。
输入:成功标准与风险数据。
思考:
- 反馈机制:如何收集To B客户(买单者)和用户(使用者)对AI输出的“好/坏”评价?
- 数据飞轮:如何利用产生的正确数据来微调模型或优化Prompt?
- 迭代周期:如何定期Review指标,进行A/B测试,持续优化?
输出:迭代机制设计,明确数据收集、模型优化和重新部署的流程。
输出示例:
一、业务导向的迭代核心
只关注三个关键业务指标:
-线索→成交转化率(核心价值)
-平均签单金额(质量提升)
-销售跟进效率(人效提升)
二、数据驱动的自动反馈闭环
1)基于业务结果的真实反馈
# 无需销售主动反馈,系统自动采集
业务反馈数据源 = {
“销售行为”: [
“线索分配→首次跟进时长”, # 销售是否快速跟进AI推荐线索
“高意向线索成交率”, # AI推荐质量最直接的证明
“低意向线索转化奇迹” # AI可能错失的优质线索
],
“成交结果”: [
“不同评分线索的实际成交率”, # 验证评分准确性
“AI高分线索的平均客单价”, # 验证价值识别能力
“成交周期分布” # 验证效率提升
]
}
2)管理者决策数据看板
管理者核心关注点 = {
“每日必看”: [
“高意向线索转化追踪”, # 昨日分配线索的跟进状态
“销售人均处理能力”, # AI是否真提升了效率
“异常线索预警” # 需要立即干预的case
],
“每周分析”: [
“评分模型准确率”, # 基于实际成交数据的模型表现
“渠道质量重估”, # 各渠道线索的实际价值
“销售资源优化建议” # 基于数据的资源调配
]
}
三、模型迭代的务实方案
1)基于成交结果的模型优化
每周数据回流:
实际成交数据 → 标注黄金训练集 → 模型增量训练
↓
A/B测试:新模型(10%流量) vs 现模型(90%)
↓
业务指标对比 → 胜出模型全量发布
2)特征权重自动调优
# 基于业务结果自动调整特征重要性
特征优化策略 = {
“自动发现”: “分析成交客户的特征模式”,
“权重调整”: “强化实际带来成交的特征权重”,
“无效剔除”: “移除与成交无关的噪声特征”
}
四、产品迭代的务实路径
1)管理者痛点驱动的产品演进
迭代优先级 = {
“紧急”: {
“问题”: “销售抱怨线索质量差”,
“方案”: “立即调整评分阈值 + 增强负样本学习”,
“验证”: “下周转化率是否回升”
},
“重要”: {
“问题”: “高价值客户识别不准”,
“方案”: “加入新的企业特征 + 重新训练模型”,
“验证”: “客单价提升幅度”
},
“优化”: {
“问题”: “销售跟进效率待提升”,
“方案”: “优化分配策略 + 个性化推荐”,
“验证”: “人均处理线索数增长”
}
}
2)最小化迭代验证机制
提出改进假设 → 小范围实验(1-2个销售团队)
↓
快速验证业务效果(1-2周) → 数据证明有效
↓
全量推广 → 持续监控核心指标
总结与展望
这套“七步法”,从定义问题到规划闭环,本质上是在构建一个“人机协同”的新系统。它要求我们产品经理,不再只是需求的定义者,更是AI能力与业务场景之间的架构师与翻译官。
方法本身是地图,能保证我们不迷路;但真正的挑战,在于踏上路途后的每一步细节。模型如何持续训练?有哪些重要的决策因子?如何快速搭建简易的工作流?
下一篇,我们将跳出蓝图,进一步走进业务逻辑补充和实操。
本文由 @疏桐to b运营 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


