
 起点课堂会员权益
起点课堂会员权益拒绝“玩具感”:如何用商业闭环思维构建一份降维打击的AI产品作品集
AI作品集如何摆脱‘玩具感’?本文深度剖析了‘极客思维’与‘产品思维’的本质差异,揭秘了面试官真正在意的商业闭环能力。从L1/L2需求分类到PMC分析框架,从Copilot到Agent的进化路径,手把手教你打造一份能降维打击的AI作品集。

前言: 为什么你的AI作品集在面试官眼中只是一个“Demo”?
一个朋友最近看了不少简历,他说,有点审美疲劳。尤其是AI产品方向的,打开作品集,十个里面有八个,长得都差不多。要么是一个界面简陋的PDF对话助手,上传个文档就能问答;要么就是一个调用了某个开源模型的文生图小工具,输入几个词,生成几张图。
你问他,这个产品解决了什么问题?他会说,解决了信息检索效率的问题。你再问,相比于传统的Ctrl+F,它的核心优势在哪?他可能就有点卡壳了,支支吾吾地说,它更智能,能理解自然语言。
这些作品,不能说完全没用。至少,它证明了你会调API,知道什么是Prompt。可是在我这种看了上百份作品集的老油条眼里,这些东西,顶多算个“Demo”,离一个真正的“产品”,还差得远呢。它们充满了浓浓的“玩具感”。
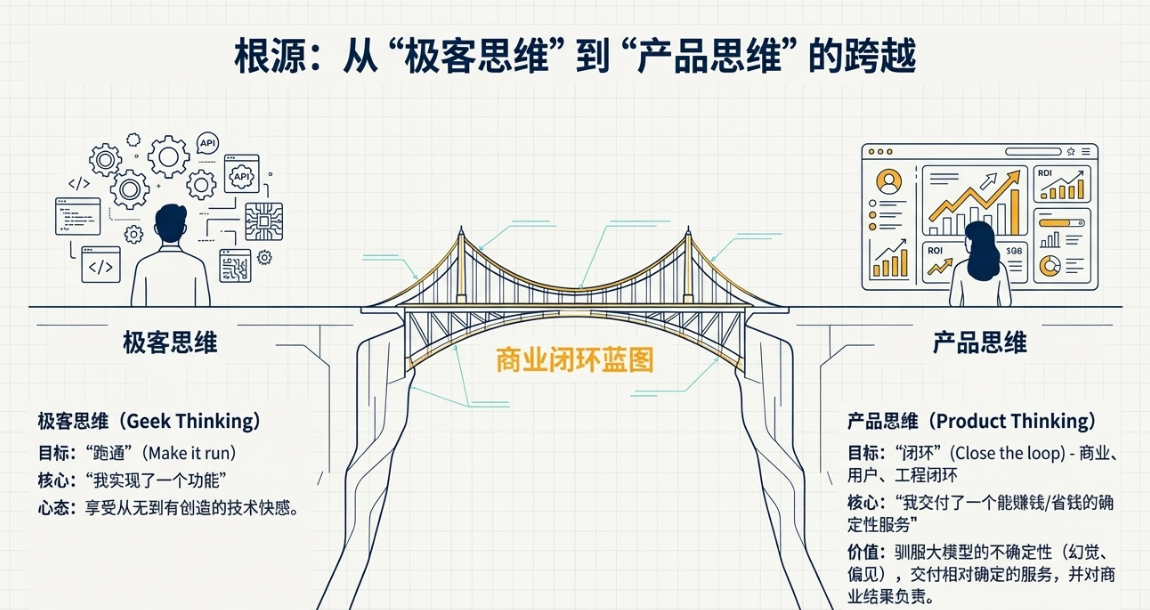
你知道吗,这种“玩具感”的根源,在于一种思维惯性。我管它叫“极客思维”。这种思维的核心是“我实现了一个功能”,目标是“跑通”。只要技术上可行,API一调,数据一跑,诶,成了,就觉得大功告成。这在技术圈子里很常见,大家享受的是从无到有创造的快感。
可企业招产品经理,尤其是在AI这个烧钱不见底的领域,要的根本不是这种思维。企业要的是“产品思维”。产品思维的核心是什么?是闭环。商业闭环、用户体验闭环、工程闭环。企业需要的是一个操盘手,一个能驾驭不确定性的人。大模型这东西,本身就是个不确定性的黑盒,充满了“幻觉”、偏见和不稳定性。一个成熟的AI产品经理,他的价值恰恰体现在,如何用各种产品设计、工程策略和商业考量,把这个“不确定”的黑盒,驯化成一个“相对确定”的服务,交付给用户,并且还能帮公司赚到钱,或者省下钱。
明摆着的事,公司不是慈善机构,也不是技术研究院。每一个API调用,背后都是哗哗流走的真金白银。面试官,特别是业务负责人,在看你的作品集时,脑子里盘算的根本不是你的UI画得有多好看,或者你用的模型有多新。他在算一笔账。他想看到的是,你是否具备控制成本、识别伪需求、设计兜底方案、预估商业回报的能力。他想找的,是一个能帮他解决实际问题,并且能对最终的商业结果负责的人,而不是一个只会跟风玩票的技术尝鲜者。
所以,如果你还在为自己做了一个“全能AI聊天机器人”而沾沾自喜,我劝你冷静一下。这篇文章,就是想跟你聊聊,怎么从“极客思维”的自嗨里跳出来,用“商业闭环”的逻辑,去重新审视和构建你的AI产品作品集。让它不再是一个脆弱的“玩具”,而是一份能真正体现你产品操盘能力的、具备降维打击实力的“商业计划书”。
一、选题策略——逃离“拿着锤子找钉子”的低维陷阱
聊到做AI产品,我发现一个特别普遍的现象,就是“拿着锤子找钉子”。大模型这把“锤子”太火了,太强大了,于是很多产品经理就满世界找“钉子”,想方设法把这把锤子用上。为了做AI而做AI,强行在一些根本不需要AI的地方接入大模型。结果呢?做出来的东西又慢又贵,效果还不如原来简单的规则系统。
这章的核心,就是想跟你掰扯清楚,怎么从源头上就选对方向,找到那些真正需要、也真正能被大模型赋能的“高价值场景”。说白了,就是怎么找到那个值得你花力气去砸的“真钉子”。
真伪需求鉴定(L1/L2分类法)
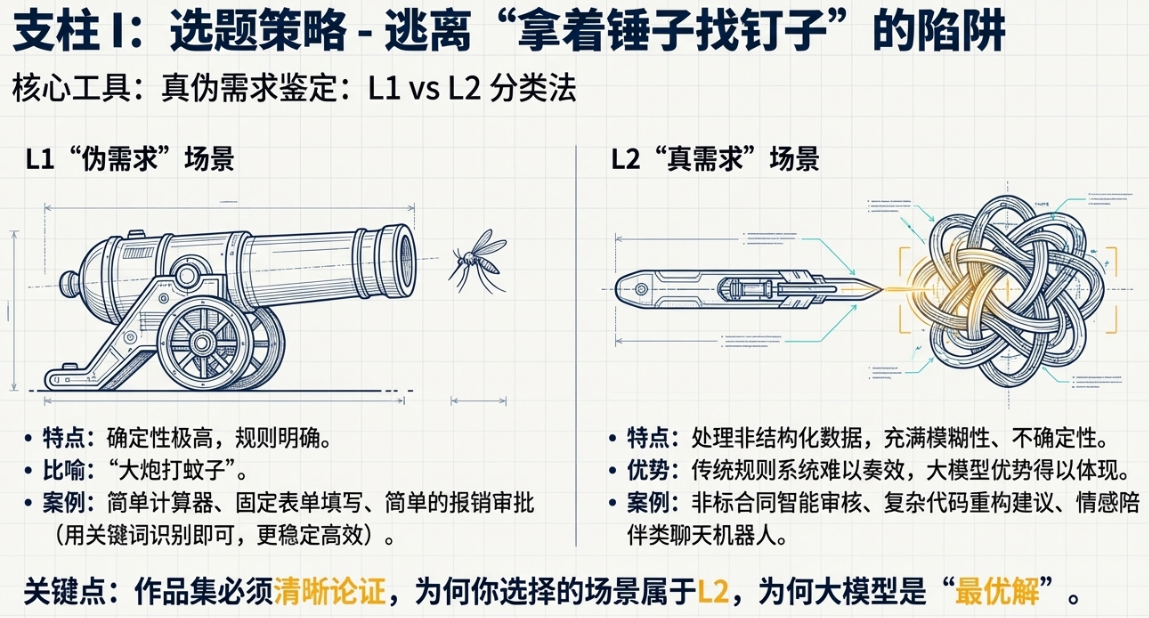
在我看来,想做AI产品,第一步就是要学会分辨什么是真需求,什么是伪需求。我这里提一个简单的分类法,就叫L1/L2分类法吧,方便理解。
L1,就是我眼里的“伪需求”场景。
这些场景有什么特点?确定性极高,规则非常明确。比如,一个简单的逻辑计算器,你输入一加一,它就得等于二。或者一个固定的表单填写流程,第一步填姓名,第二步填手机号,流程是死的,不能变。在这种场景里用大模型,简直就是“大炮打蚊子”。
你想想,你问大模型一加一等于几,它可能给你返回“根据数学公理,一加一等于二”,甚至有时候网络一抖,它还可能胡说八道。它不仅慢,返回结果的格式还不稳定,你还得写一堆代码去解析它的回答。更要命的是,它还贵。一次API调用几分钱,你用传统的代码实现,成本几乎为零。这笔账,怎么算都亏。
我见过一个作品集,做了一个“智能报销审批”系统。听起来很高大上吧?结果一看,就是让用户用自然语言说“我要报销三百块钱的出差打车费”,然后系统自动填到报销表单里。这个场景,用一个简单的关键词识别加上规则判断就能搞定,稳定又高效。非要上大模型,用户说一句话,等个三五秒,结果还可能填错金额或者费用类型。你说,这除了炫技,有什么实际价值?这就是典型的L1伪需求。
L2,这才是我说的“真需求”场景。
L2场景的特点,恰恰是L1的反面。它们通常处理的是非结构化数据,充满了模糊性、不确定性和开放性。在这些地方,传统基于规则的系统很难奏效,而大模型的优势就体现出来了。
举几个例子你就明白了。
比如,非标合同的智能审核。每一份商业合同,措辞、条款、格式都可能不一样。你想用规则去提取“甲方”、“乙方”、“合同金额”、“违约责任”,那得写到猴年马月去,而且永远有你覆盖不到的case。大模型不一样,它见过海量的法律文本,能理解上下文,哪怕条款换了一种说法,它也能大概率正确地识别出来。这就是处理非结构化文本的威力。
再比如,复杂的代码重构建议。一个老旧的系统,代码写得跟意大利面一样,你想让一个工具自动帮你分析哪里可以优化、哪里有潜在的bug、如何提高可读性。这种任务,需要对代码的逻辑、设计模式有深刻的理解,不是简单的语法检查能搞定的。大模型通过学习海量的开源代码,具备了这种“代码品味”,能给出非常 insightful 的建议。
还有一个,情感陪伴类的聊天机器人。用户的每一句话都带着情绪,意图是模糊的,话题是跳跃的。今天可能跟你聊工作不顺心,明天可能分享一只可爱的猫。这种开放式的、需要共情能力的对话,是规则系统的噩梦,却是大模型的绝佳舞台。它能生成富有同理心、符合人设的回答,提供真正的情绪价值。
所以,在你的作品集里,第一步就是要向面试官清晰地展示,你选择的这个场景,它属于L2,而不是L1。你要说清楚,这个场景的“非结构化”和“不确定性”体现在哪里,为什么传统的方案搞不定,为什么大模型是解决这个问题的“最优解”,而不是“唯一解”。这种思考深度,一下子就能把你和那些“为了AI而AI”的候选人区分开。
PMC分析框架
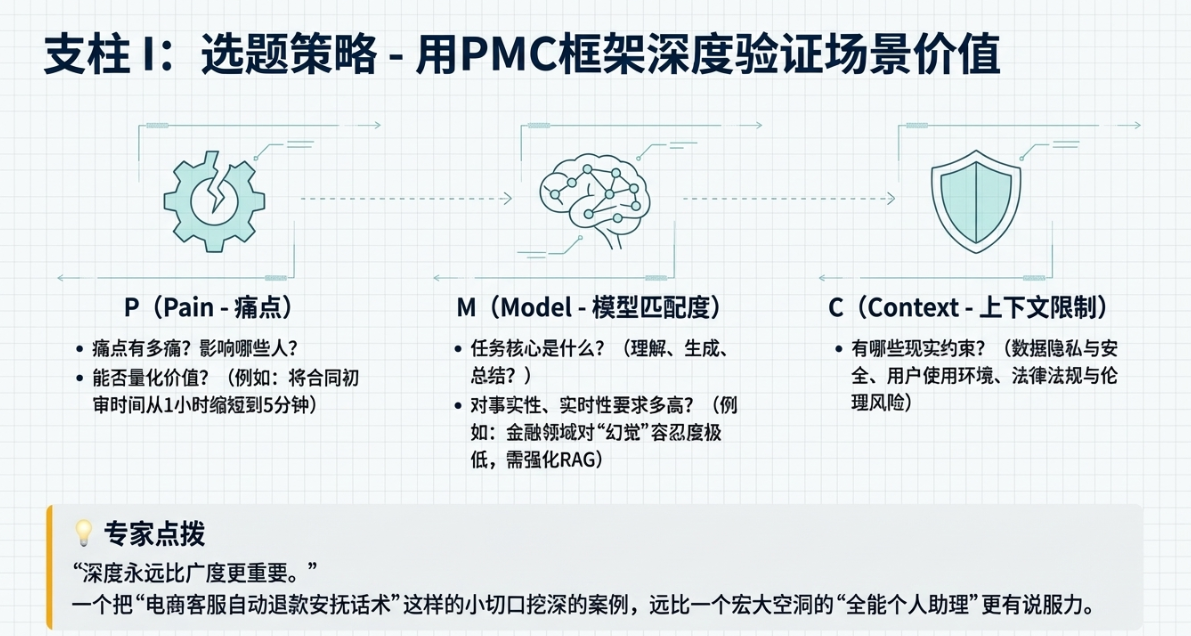
好,现在你找到了一个看似靠谱的L2场景,怎么进一步验证它的价值,并且在作品集里把它讲清楚呢?我习惯用一个简单的框架,叫PMC分析框架。P就是Pain(痛点),M是Model(模型匹配度),C是Context(上下文限制)。
在你的作品集里,专门拿一页出来,就用这三个维度来剖析你的选题,会显得非常专业。
先说P,Pain,痛点。
做产品,不解决痛点,就是在自嗨。这个痛点,不能是你自己想象出来的,必须是真实存在的,而且最好能被量化。你要问自己几个问题:
- 这个痛点影响了哪些人?是C端用户,还是B端企业的员工?
- 这个痛(或者痒)的程度有多深?是每天都遇到,烦得要死?还是一年才碰到一次,无伤大雅?
- 如果解决了这个痛点,能带来什么可量化的价值?是节省了多少工作时间?提升了多少转化率?减少了多少客户流失?
比如你做合同审核,痛点就是法务团队每天要花大量时间在重复、枯燥的条款比对上,不仅效率低,还容易出错。价值就是,能将单份合同的初审时间从1小时缩短到5分钟,让法务能聚焦在更复杂的风险判断上。你看,这么一说,价值感就出来了。
再说M,Model,模型匹配度。
这个场景,真的适合用大模型吗?是不是所有的大模型都适合?你要思考:
- 任务的核心是理解、生成、总结,还是分类?不同的任务类型,对模型的要求是不一样的。
- 这个任务对事实性的要求有多高?如果是医疗、金融这种领域,对“幻觉”的容忍度极低,你可能需要更强的RAG(检索增强生成)能力,或者选择在特定领域精调过的垂直模型。
- 这个任务对实时性的要求呢?如果是实时对话,那模型的响应速度就至关重要,你可能得在效果和速度之间做权衡。
在作品集里,你要展示出你对模型能力的边界有清晰的认知。不是简单地说“我用了最新的模型”,而是“针对这个场景对事实性要求高的特点,我选择了具备强大RAG能力的某类模型架构”。这种表述,含金量完全不同。
最后是C,Context,上下文限制。
这是最容易被忽略,但也最体现产品经理成熟度的一点。一个产品不是活在真空里的,它有各种各样的现实约束。
- 数据隐私和安全。你做的合同审核工具,客户敢把他们最机密的商业合同上传到你的服务器吗?你的数据隔离和加密方案是怎么设计的?
- 用户的使用环境。他们是在PC上用,还是在手机上用?是在安静的办公室,还是在嘈杂的户外?这些都影响你的产品形态和交互设计。
- 法律法规和伦理风险。你的AI生成的内容,会不会有版权问题?会不会散播歧视性言论?你有没有设计相应的过滤和审核机制?
把这些限制条件想清楚,并且在作品集里提出来,哪怕只是初步的思考,都会让面试官觉得,你是一个靠谱的、有大局观的成年人,而不是一个只活在理想世界里的学生。
专家点拨:
我跟你讲,作品集真的不在于你做的东西有多宏大。我见过太多简历写着“打造下一代通用人工智能助理”,结果一问三不知。反而,一个把小切口挖深的案例,更能打动我。
就拿刚才说的“电商客服的自动退款安抚话术生成”这个点来说。这个场景非常小,但它五脏俱全。你可以用PMC框架去分析:Pain是客服处理大量重复的退款请求,情绪劳动强度大,话术水平参差不齐;Model匹配度很高,这是一个典型的风格化文本生成任务;Context也很明确,需要符合平台的服务规范,不能过度承诺。只要你把这个小场景的逻辑讲透,证明它能自洽,能产生商业价值,这远比做一个宏大但空洞的“全能个人助理”要有说服力得多。记住,深度永远比广度更重要。
二、方案设计——超越“对话框”,设计智能体工作流
好了,选题这关过了,我们选了一个靠谱的L2场景。下一步就是方案设计。这一步,是区分“调包侠”和“架构师”的关键分水岭。
现在市面上90%的AI作品集,方案设计都停留在同一个维度:一个对话框。用户输入,模型输出,结束。这种千篇一律的Chatbot UI,已经完全无法体现你的产品设计能力了。说实话,看到这种作品,我心里想的是,这不就是把一个API套了个壳吗?你的价值在哪里?
一个真正有深度的AI产品,它的核心魅力不在于那个光鲜的UI,而在于后台那一套看不见的、精心编排的逻辑工作流。这章,我们就来聊聊,怎么在作品集里,展示出你设计这套“智能体工作流”的能力,让你超越简单的“对话框”层面。
从助手(Copilot)到智能体(Agent)的进化
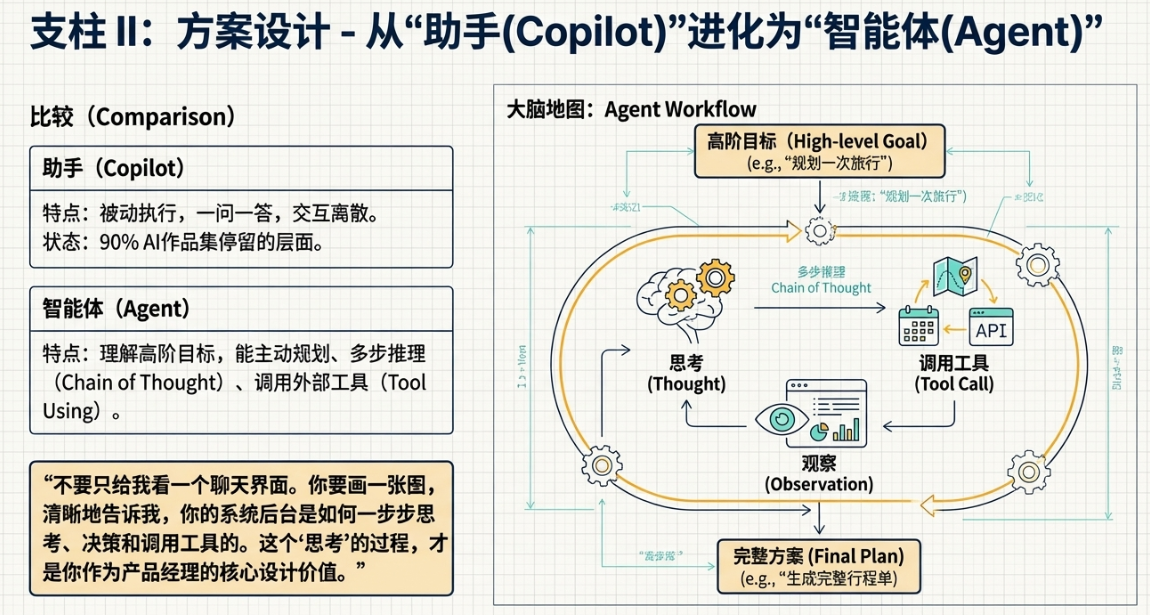
首先得搞清楚一个概念,Copilot和Agent的区别。在我看来,这是理解现代AI产品设计的关键。
Copilot,是副驾驶,是助手。 它的特点是“一问一答”,你给它一个明确的指令,它执行一步操作。比如,在代码编辑器里,你让它帮你补全一段代码,它就补全。你让它解释一段函数,它就解释。它的交互是离散的、被动的。你推一下,它动一下。
绝大多数作品集里的产品,都停留在Copilot这个层面。这没有错,很多场景下Copilot已经足够好用。但如果你想展示更深的产品架构能力,你就必须往Agent的方向去思考。
Agent,是智能体,是自主驾驶员。 它的核心能力是理解一个高阶的目标,然后自主地进行多步推理(Chain of Thought),甚至调用外部工具(Function Calling/Tool Using)来完成这个目标。它不是被动地等你给指令,而是能主动地规划和执行。
举个例子。你想规划一次去某个城市的周末旅行。你对Copilot说:“帮我找找那个城市有什么好玩的。”它可能会给你列一堆景点。然后你得自己一个个去查门票,查开放时间,查路线。但你对一个旅行Agent说:“帮我规划一个周末去某城市的旅行,我喜欢历史古迹,预算一千块。”
这个Agent会怎么做?它会开始思考和规划:
- 第一步(拆解任务): 它会把“规划旅行”这个复杂任务拆解成几个子任务:找景点、查交通、订酒店、排行程。
- 第二步(调用工具): 它会调用“地图工具”查找符合“历史古迹”的景点,调用“票务工具”查询机票和酒店价格,调用“天气工具”查询周末天气。
- 第三步(推理和决策): 它发现某个古迹周末不开,会主动放弃。它发现机票加酒店超预算了,会去寻找更便宜的交通方式或者酒店。
- 第四步(生成结果): 最后,它会给你生成一个完整的、可执行的行程单,包含时间、地点、交通方式和预算明细。
看到了吗?Agent的核心是“思考链”和“工具调用”。在你的作品集里,不要只给我看一个聊天界面。你要画一张图,一张业务流程图或者状态机图,清晰地告诉我,当用户提出一个复杂意图时,你的系统后台是如何一步步思考、决策和调用工具的。这个“思考”的过程,才是你作为产品经理的核心设计价值。
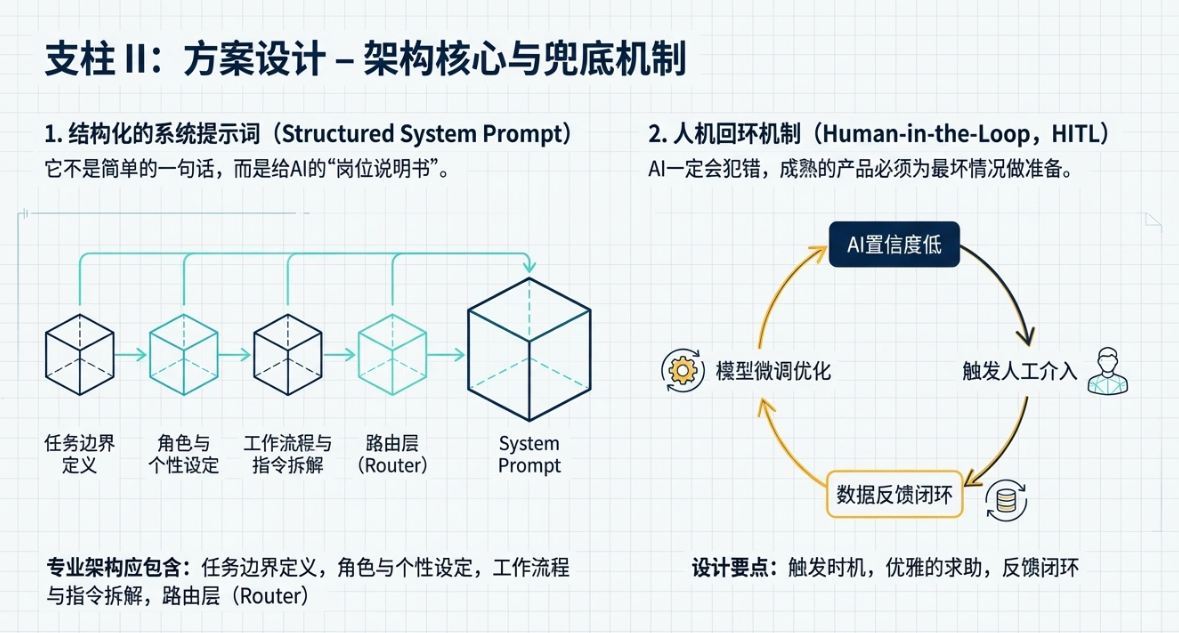
系统提示词架构(System Prompt Design)
要让大模型像Agent一样工作,光靠用户输入的几句话是不够的。关键在于你如何设计那个看不见的“系统提示词”(System Prompt)。这玩意儿,就像是给AI员工写的一份详尽的“岗位说明书”和“操作手册”。
很多人的作品集里,提到Prompt,就是简单的一两句,比如“你是一个乐于助人的助手”。这太初级了。一个专业的AI产品经理,应该展示的是一套结构化的、模块化的Prompt架构。
你是怎么设计这套架构的?在作品集里可以这么展示:
- 任务边界定义: 你要明确告诉模型,它的职责是什么,不能做什么。比如,“你是一个专业的法律合同审核助手,你的任务是识别合同中的风险条款。你不能提供任何法律建议,不能创造新的条款。” 这种清晰的边界定义,是控制模型行为、避免风险的第一道防线。
- 角色与个性设定: 你希望模型以什么样的口吻和风格与用户交流?是严谨专业的律师,还是亲切耐心的老师?把这些设定写清楚,能保证产品体验的一致性。
- 工作流程与指令拆解: 这是最重要的部分。你要把复杂的任务,拆解成一步步的具体指令。比如前面说的旅行Agent,它的System Prompt里可能就包含了类似这样的指令:“当用户提出旅行规划需求时,你必须遵循以下步骤:一,识别目的地、时间和偏好;二,调用工具查询景点和交通;三,基于预算进行筛选和组合;四,生成格式化的行程单。”
- 路由层(Router)设计: 当你的产品需要处理多种不同类型的用户意图时,一个“路由层”就显得尤为重要。你可以设计一个前置的Prompt,它的唯一任务就是判断用户的意图属于哪一类。比如,用户输入一句话,Router Prompt先判断这是“闲聊”,还是“查询订单”,还是“技术咨询”。然后,系统再根据这个分类,调用后续专门处理该任务的Prompt和工作流。在作品集里画出这个路由分发的逻辑图,会非常加分,因为它体现了你处理复杂系统的能力。
把你的System Prompt拆解逻辑、模块化设计的思路展示出来,这比你贴一百个“神级Prompt”的例子更能证明你的专业性。
人机回环机制(HITL)
AI不是万能的,它一定会犯错。一个成熟的AI产品,绝对不是把所有事情都丢给AI,而是要设计一套优雅的“人机回环”(Human-in-the-Loop, HITL)机制。说白了,就是当AI搞不定的时候,怎么把问题“甩”给人类,让人来介入和兜底。
这是体现一个产品经理成熟度的关键加分项,因为这表明你对技术的边界有清醒的认知,并且在为最坏的情况做准备。
在作品集里,你应该专门设计一个环节来展示你的HITL方案。比如:
- 触发时机: 你是怎么判断AI“搞不定”了?可以基于模型的置信度分数。当模型返回结果的置信度低于你设定的阈值(比如70%),系统就自动触发人工介入流程。或者,当模型连续两次无法理解用户意图时,也主动请求人工帮助。
- 优雅的求助: 系统如何向用户或后台操作人员求助?绝对不是简单地弹出一个“我不知道”。可以设计一些更友好的交互。比如,“这个问题有点复杂,我需要请我的同事(人类专家)来帮您解答,您介意稍等一下吗?” 或者,在B端系统里,直接在后台生成一个待处理工单,清晰地列出问题、AI的初步回答和不确定性在哪里,方便人工快速接手。
- 反馈闭环: 人工介入后,这个宝贵的“人工数据”不能浪费。你要设计一个机制,让人类的正确答案能够被系统记录下来,用于未来对模型的微调(Fine-tuning)。比如,客服修改了AI的回答后,系统可以弹出一个按钮“将此作为优质答案范例”,一键入库。这个“数据飞轮”的闭环设计,是产品能持续进化的关键。
在作品集里,详细描述你设计的这套从“AI搞不定”到“人工介入”再到“反馈优化”的完整闭环,能瞬间让你的方案厚重起来,充满实战感。
专家点拨:记住一句话,面试官看AI产品作品集,看UI是次要的,看你的业务流程图才是主要的。一张清晰的、包含了多步推理、工具调用和人机回环的流程图,胜过千言万语。它能直观地告诉面试官,你的思维是结构化的,你不是在“玩”AI,你是在“驾驭”AI去完成一个复杂的业务任务。
别再纠结你的界面好不好看了,花点时间,用任何你顺手的工具,画出你产品背后的那张“大脑地图”。这张图,就是你区别于其他候选人的“杀手锏”。它展示的是你作为产品经理,如何去“教”一个强大的、但不完美的模型,一步步学会如何正确地工作。
三、工程与体验——直面“幻觉”与“延迟”的防御性设计
聊完了高大上的选题和架构,我们得回到地面,聊点实在的。AI产品不是魔法,它充满了各种各样的缺陷。其中最臭名昭著的两个,一个是“幻觉”(Hallucination),就是一本正经地胡说八道;另一个是“延迟”(Latency),就是反应慢,等得人心焦。
一个业余的产品经理会假装这些问题不存在,或者把锅甩给技术。而一个专业的PM,会正视这些缺陷,并且通过一系列“防御性设计”来主动弥补它们,保障用户的体验和产品的可靠性。在作品集里展示出你对这些“脏活累活”的思考,恰恰能证明你的实战能力。
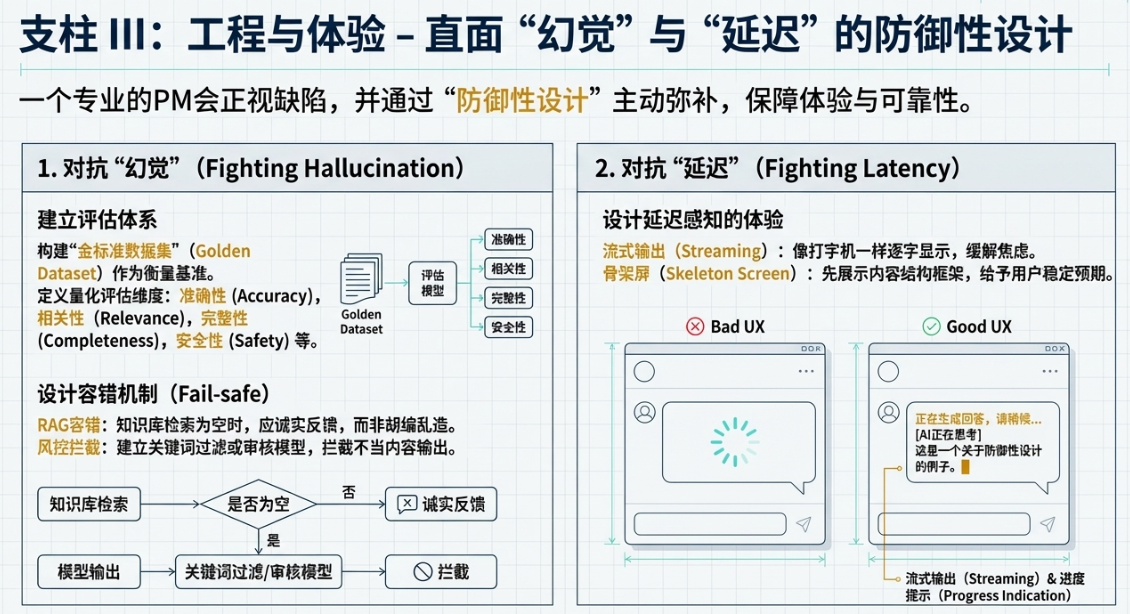
评估体系建设
在开始优化之前,你得先有个尺子。你怎么定义你的AI产品是“好”还是“坏”?没有一个量化的评估体系,所有的优化都是凭感觉,都是玄学。
在你的作品集里,我强烈建议你包含一个章节,专门讲你是如何构建评估体系的。这部分内容技术感很强,但非常能体现你的严谨性。
构建“金标准数据集”:
什么是“金标准数据集”(Golden Dataset)?说白了,就是一套高质量的、能代表真实用户场景的“考题”。每一道考题(输入),都配有一个由人类专家撰写的“标准答案”(理想输出)。这个数据集就是你衡量模型好坏的基准。
在作品集里,你可以说明你是如何构建这个数据集的。比如,你从线上收集了100个匿名的、有代表性的用户问题,然后请领域专家为每个问题写出最完美的回答。这个过程本身就体现了你的专业性。
定义具体的评估维度:
有了考题和标准答案,怎么打分呢?不能只用一个模糊的“好”或“不好”。要把“好”拆解成多个可衡量的维度。比如:
- 准确性(Accuracy): 模型回答的内容,事实层面是否正确?有没有出现“幻觉”?
- 相关性(Relevance): 回答是否切中用户问题的要点?有没有答非所问?
- 完整性(Completeness): 是否覆盖了用户问题的所有方面?有没有遗漏关键信息?
- 安全性(Safety): 回答内容是否合规?有没有包含暴力、歧视或其他不当言论?
- 风格一致性(Style Consistency): 回答的语气和风格,是否符合你预设的产品人设?
你可以设计一个评估表格,让评测人员针对每个回答,在这些维度上打分。有了这套体系,你就可以对不同版本的模型、不同的Prompt进行A/B测试,用数据说话,告诉面试官,你的每一次优化,带来了哪个维度上百分之几的提升。这比任何空洞的描述都有力。
容错机制(Fail-safe)
防御性设计的核心,就是假设一切都会出错,然后为这些错误准备好预案。AI产品尤其如此。
在作品集里,你要像一个经验丰富的老兵一样,展示你都预见了哪些“雷”,并且埋下了哪些“保险丝”。
RAG的容错: 现在很多问答产品都用了RAG(检索增强生成),就是先从知识库里检索相关文档,再让模型基于这些文档来回答。一个常见的问题是,如果知识库里没有相关内容,怎么办?
一个糟糕的设计是,模型可能会基于自己的通用知识胡编乱造,或者直接说“我不知道”。一个好的设计是,系统能明确地告诉用户:“根据我查阅的XX文档,没有找到关于您问题的直接信息。不过,根据通用知识,这个问题可能与YY有关……” 这种诚实的、有边界感的回答,能极大地提升用户的信任感。你要在作品集里说明,当检索为空时,你的产品是如何反馈的。
风控拦截: 如果用户诱导模型输出违规内容,或者模型自己“发疯”,生成了不当言论,怎么办?你必须有一套风控拦截机制。这可能是一个前置的关键词过滤器,也可能是一个后置的、专门用于内容审核的小模型。当检测到风险时,系统应该立刻拦截输出,并给出一个预设的、安全的、模糊的回答,比如“我们换个话题聊聊吧”。在作品集里画出你的内容安全审核流程,是体现你责任感和成熟度的重要一环。
延迟感知的体验设计
大模型推理慢,这是一个物理现实,短期内很难彻底解决。用户每输入一句话,都要盯着屏幕干等三五秒,这种体验是灾难性的。一个优秀的产品经理,不会坐等技术进步,而是会通过巧妙的体验设计,来“欺骗”用户的感知,让等待变得不那么难熬。
在你的作品集里,展示你为“慢”做了哪些优化,能体现你对用户体验的细腻把控。
流式输出(Streaming): 这是最基本,也最有效的策略。不要等模型生成完所有内容再一股脑地显示出来。而应该像打字机一样,一个字一个字地“流”出来。这不仅能让用户立即看到系统正在“思考”和“工作”,极大地缓解了等待的焦虑感,还能让用户在内容生成到一半时,如果发现方向不对,可以随时打断,节省了时间和计算资源。
骨架屏(Skeleton Screen): 在等待模型返回结果的空白期,可以先展示一个内容的“骨架”。比如,如果用户要的是一份报告,你可以先展示出报告的标题、各个章节的标题,内容部分用灰色的占位符填充。这给了用户一个稳定的预期,让他们知道即将生成的内容大概是什么结构,体验比一个空白页面或者一个旋转的菊花好得多。
预加载与乐观更新: 在某些场景下,你甚至可以预测用户的下一步行为,并提前开始加载。比如,在一个多轮对话的引导流程里,当用户选择了某个选项后,你可以“乐观地”假设他会继续下去,并提前开始为下一步生成内容。这种策略虽然有一定风险,但在特定场景下能创造出“瞬时响应”的惊艳体验。
把这些针对延迟的设计思考和UI/UX方案放进你的作品集,面试官会觉得,你是一个真正懂用户、关心细节的人。
专家点拨:
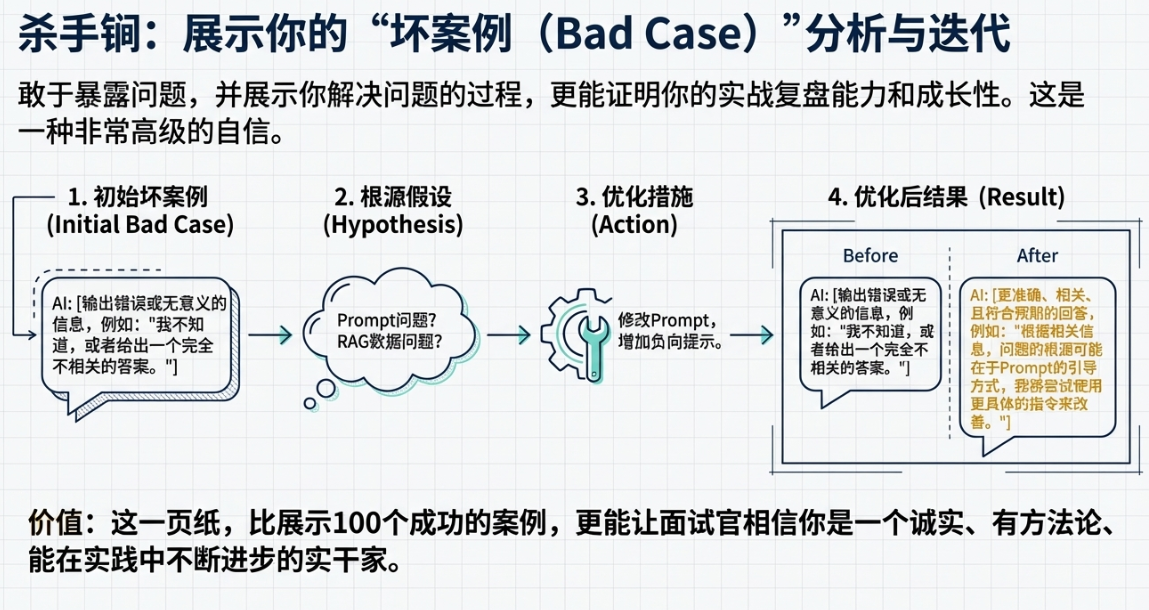
说个能让你作品集脱颖而出的“大杀器”:专门增加一页,叫做“Bad Case(坏案例)分析与优化记录”。
别光展示你成功的案例,那看起来像广告。敢于暴露问题,并展示你解决问题的过程,更能证明你的实战复盘能力和成长性。你可以用一个简单的格式:“初始坏案例(截图或描述) -> 我对问题根源的假设(是Prompt问题?还是RAG数据问题?) -> 我采取的优化措施(比如,修改了Prompt,增加了负向提示) -> 优化后的结果(新旧结果对比)”。
这一页纸,比你展示100个成功的案例,更能让面试官相信,你是一个诚实、有方法论、能在实践中不断迭代和进步的实干家。这是一种非常高级的自信。
四、商业闭环——产品经理的终极试金石:单体经济模型
聊到这儿,我们已经把一个AI产品的选题、架构、体验都聊得差不多了。如果你的作品集能把前面三章的内容都讲透,说实话,已经能超过80%的候选人了。但如果你想成为那顶尖的10%,想真正打动那些手握预算、决定你薪资的业务负责人,你还必须展示你的最后一项,也是最硬核的能力:算账。
AI产品,尤其是基于大模型的产品,是一个不折不扣的“吞金兽”。每一次API调用都在烧钱。一个不懂成本、不考虑商业回报的AI产品经理,在企业眼里就是个巨大的风险。所以,在作品集的最后,你必须向面试官证明,你不仅能做出好玩、好用的产品,你还能算得清这盘生意的账。这就是我说的“商业闭环”思维。
这部分内容,是90%的候选人作品集中完全缺失的,也是最能让你实现“降维打击”的部分。
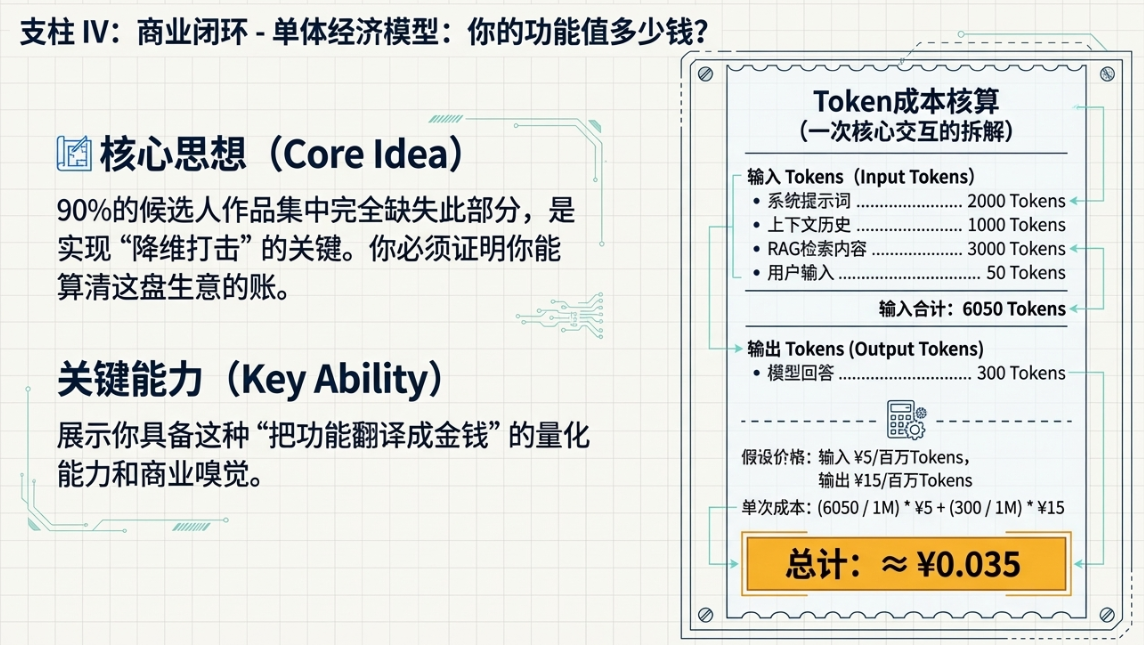
Token成本核算
这是最基础,也是最核心的一步。你必须对你的产品每一次核心交互的成本有精确的认知。在作品集里,你需要像写一份财务报告一样,清晰地列出你的成本构成。
找一个你产品的核心使用场景,然后详细地拆解一次完整交互的Token消耗。你可以这么列:
1)输入Token(Input Tokens):
- 系统提示词(System Prompt):这是固定成本,比如2000个Token。
- 上下文历史对话(Context History):这是变动成本,假设保留最近5轮对话,平均每轮200个Token,就是1000个Token。
- 检索增强内容(RAG Context):如果用了RAG,从知识库检索出的内容,比如3000个Token。
- 用户当轮输入(User Query):比如50个Token。
2)输出Token(Output Tokens):
- 模型生成的回答:平均长度,比如300个Token。
好了,现在算总账。一次交互的输入Token是 2000 + 1000 + 3000 + 50 = 6050 个Token。输出Token是 300 个Token。
接下来,去查一下市面上主流模型提供商的公开报价(不需要指明是哪家)。比如,某个旗舰模型的输入价格是每百万Token 5块钱,输出价格是每百万Token 15块钱。那么,这次交互的成本就是:
(6050 / 1,000,000) * 5元 + (300 / 1,000,000) * 15元 = 0.03025元 + 0.0045元 ≈ 0.035元
你看,一次看似简单的问答,成本是三分五厘钱。这个数字本身不重要,重要的是,你向面试官展示了你具备这种“把功能翻译成金钱”的量化能力。这是一种极其宝贵的商业嗅觉。
权衡决策(Trade-off)
算清楚了成本,你就要开始做产品经理最核心的工作之一:权衡(Trade-off)。在AI产品里,最常见的权衡就是“效果”、“速度”和“成本”这个不可能三角。
在作品集里,你要解释你为什么在产品的不同环节,选择了不同的模型。这能极大地体现你的策略性思考。
比如,你可以这样设计和阐述你的模型调用策略:
“在我们的系统中,我们采用了一种分层模型策略。当用户输入一个问题时,我们首先会调用一个速度极快、成本极低的开源小模型或Mini模型。这个小模型的唯一任务,就是对用户的意图进行快速分类(比如判断是闲聊、查询还是复杂分析)。这个环节,我们追求的是速度和低成本,对智能程度要求不高。”
“一旦小模型判断出用户的意图是需要进行复杂分析的‘高价值任务’,系统才会切换到昂贵的、能力最强的旗舰大模型(比如GPT-4o这一级别的)。因为在这个环节,回答的质量和深度是第一位的,我们愿意为此支付更高的成本。而对于那些被判断为‘闲聊’的请求,系统会继续使用那个便宜的小模型来应付,从而把好钢用在刀刃上,极大地优化了整体的运营成本。”
看到这种描述,面试官会怎么想?他会觉得,你不是一个只会用最贵最好的模型的“技术小白”,你是一个懂得精打细算、会做资源调配的“管家”。这种思维,在任何一个需要考虑成本控制的商业环境里,都是极受欢迎的。
ROI(投资回报率)推演
成本算清楚了,接下来就要算收益。你做的这个AI功能,到底能给公司带来多大的价值?这就是ROI(Return on Investment)分析。这是说服业务负责人为你投入资源的最强武器。
在作品集里,你可以构建一个简单的ROI推演模型。哪怕数据都是估算的,这个思考过程本身就价值千金。
假设你做的产品是一个“AI智能客服”,用来辅助人类客服回答用户问题。你可以这样推演:
1)现状分析(As-Is):
我们公司有100名客服。
- 每名客服的人力成本(工资、社保等)是每月1万元。
- 每名客服每天处理100个工单。
公司每月的客服总成本是 100人 * 1万元/人 = 100万元。
2)引入AI后的预测(To-Be):
我们的AI功能,经过测试,可以独立处理30%的重复性工单。
- 处理一个工单的AI成本,根据前面的核算,是0.5元。
- 公司每天总工单量是 100人 * 100单/人 = 10000单。
- AI每月处理的工单量是 10000单/天 * 30天 * 30% = 90000单。
AI每月的调用成本是 90000单 * 0.5元/单 = 4.5万元。
3)ROI计算:
AI的引入,相当于替代了 100人 * 30% = 30名客服的工作量。
- 节省的人力成本是 30人 * 1万元/人 = 30万元/月。
- 净收益 = 节省的人力成本 – AI调用成本 = 30万元 – 4.5万元 = 25.5万元/月。
- 年化净收益约为 25.5万 * 12 ≈ 300万元。
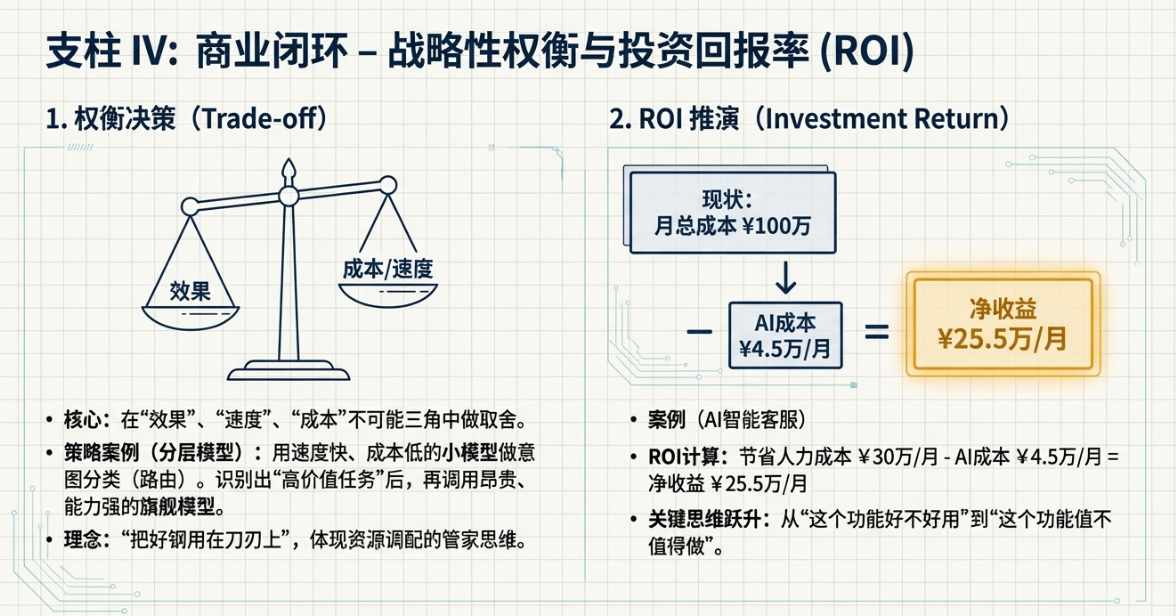
把这个简单的计算过程放在你的作品集里,效果是震撼性的。它告诉面试官,你思考问题的维度,已经从“这个功能好不好用”,跃升到了“这个功能值不值得做”。
定价策略初探
如果你的产品是直接面向外部客户的SaaS服务,那么定价就是商业闭环的最后一公里。在作品集里,你可以基于你的成本模型,给出初步的定价建议。
你可以分析不同定价模式的优劣:
- 按月订阅(Subscription): 优点是公司收入稳定可预测,用户也省心。缺点是对于用量少的用户不公平,对于用量大的用户,公司可能会亏本。
- 按量付费(Pay-as-you-go): 优点是完全公平,用多少付多少。缺点是用户对成本不可控,可能会因为担心费用而不敢用;公司收入也不稳定。
- 混合/分层定价(Tiered Pricing): 这是最常见的模式。比如,每月99元,包含1000次基础交互;超出部分按量计费。或者,提供不同等级的套餐,功能越强、用量越大的套餐越贵。
你不需要给出一个完美的定价方案,但你需要展示你对定价逻辑的思考。比如,“基于我们单次交互0.035元的成本,考虑到研发、运营和利润空间,我们建议基础套餐的定价可以覆盖约2000次交互的成本,从而设定一个对用户有吸引力,同时保证公司盈利的起步价。”
专家点拨:我知道,很多人看到算账就头大,觉得这些数据都是估算的,不准确,没意义。这是个巨大的误区。在作品集阶段,没有人要求你的数据是100%精确的。面试官看重的,根本不是那个最终的数字,而是你展示出来的这个“计算过程”本身。
这个过程证明了你具备从“玩票”到“商业落地”的思维跨越。它证明了你理解,产品经理的最终职责,是为商业结果负责。只要你敢于去算这笔账,哪怕算得很粗糙,你就已经赢了90%的竞争者。因为你和面试官,开始用同一种语言——商业的语言——在对话了。
结语 :AI时代,产品经理是“不确定性”的驯服者
聊了这么多,从选题、设计、工程到商业,其实我想说的核心观点只有一个。
AI时代,产品经理的核心价值到底是什么?不是写出几句花里胡哨的Prompt,也不是追逐最新最热的模型。在我看来,AI产品经理的真正价值,在于他是一个“不确定性”的驯服者。
我们面对的是一个充满不确定性的世界。技术本身是不确定的,大模型有幻觉,有偏见,随时可能给你“惊喜”。用户需求是不确定的,他们带着模糊的意图而来,你很难预料他们会问出什么千奇百怪的问题。商业环境也是不确定的,成本在波动,竞争在加剧,一个今天看起来还不错的商业模式,明天可能就不成立了。
而一个优秀的产品经理,他的工作,就是在技术的不确定性、用户体验的确定性与商业成本的可控性之间,去寻找那个微妙的、动态的平衡点。
他用L2场景定义和PMC框架,在模糊的需求中找到确定的价值锚点。
他用Agent工作流和模块化Prompt,把一个不可控的黑盒模型,调教成一个遵循特定规则的、可预测的执行者。
他用评估体系和防御性设计,为技术的“幻觉”和“延迟”建立起一道道防波堤,为用户提供一个相对确定的、可靠的体验。
他用成本核算和ROI推演,把飘在天上的技术概念,拉回到地面,变成一笔可以计算、可以衡量的生意。
你看,整个过程,就是不断地用各种方法论和工具,去消解不确定性,去构建确定性。这才是AI产品经理真正的、不可替代的价值所在。
所以,如果你想让你的作品集真正发光,就请忘掉那些表面的“玩具感”。我给你一个非常具体的行动建议:找一个你过去做过的、你最熟悉的传统互联网项目,无论是一个电商功能,一个社区产品,还是一个效率工具。然后,用我们今天聊的这套框架,去对它进行一次“AI重构”。
问问自己:
- 这个产品里,有没有可以用AI解决的L2场景?
- 如果引入AI,它的Agent工作流应该如何设计?
- 它会遇到哪些幻觉和延迟问题,我该如何设计防御方案?
- 它的单体经济模型是怎样的?引入AI后,ROI是正还是负?

把这个思考和设计的过程,完整地、有深度地呈现在你的作品集里。我相信,这样一份充满了商业闭环思考的“重构方案”,会成为你面试时最锋利的“杀手锏”,足以让你在众多千篇一律的“PDF对话机器人”中,实现真正的降维打击。
本文由 @大叔拯救世界 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!

