
 起点课堂会员权益
起点课堂会员权益模型评测“测什么”才不跑偏?三类评测一把捋清!
模型评测中最危险的陷阱不是缺乏测试,而是测试泛滥却无法推动决策。本文将揭秘一套实战验证的分类评测体系:专项能力、功能模块、性能指标三大航道,教你如何将评测从散点检查升级为精准决策工具。从模型选型到系统上线,每个阶段都有对应的评测策略,确保每一次测试都能转化为明确的行动指南。

我做模型评测时,最怕的不是“没测”,而是“测了很多,但结论推不动任何决策”。因为一旦评测目标不清晰,团队就会进入一种很典型的状态:今天跑一下文本效果,明天看一下推理速度,后天再试试 RAG,最后堆出一堆表格——看起来很努力,但没人能回答一句话:这次评测到底是为了哪个上线动作服务?
所以我会先把“测什么”定成三类,并且把它当成导航:专项能力、功能模块、性能指标。我每次评测都先选“航道”,再决定题目、方法和产出形式。这样做的好处很简单:评测不再是散点式的“检查”,而是能落到产品选择与迭代优先级上的“决策工具”。
我把评测拆成三类:能力、链路、成本
下面这张“导航图”就是我常用的心智模型。我会把它直接放在文章中间,当作读者的地图(也是我自己做评测时的 checklist)。
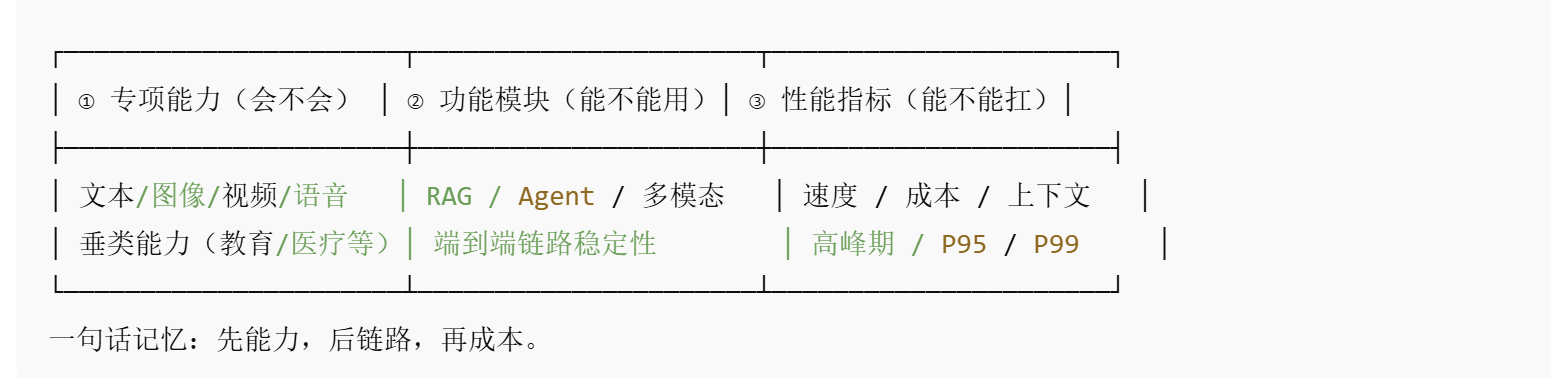
这三类不是“都要做”,而是“按阶段做”。我会用它来决定:先证明它会,再证明它能稳定用,最后证明它在预算里跑得动。
① 专项能力评测:我先确认“它会不会这件事”,再谈系统化
专项能力评测在我这里更像“岗位技能面试”:我要它承担什么工作,就先测它在这个技能上到底行不行。它最适合用在模型选型、模型升级、或者我刚拿到一个新模型时——因为这时候我不需要它完美,我只需要知道它有没有资格进入下一轮。
我会用非常具体的业务场景去拆专项能力,而不是泛泛地说“生成效果好不好”。比如:
文本生成(客服/助手类)
我会专门测三件事:会不会装懂、会不会走流程、会不会说人话。
- 会不会装懂:我会设计一些它“必然不知道答案”的问题,观察它是坦诚说不知道、引导补充信息,还是硬编一个听起来很合理的解释。上线后最容易引发投诉的,往往不是“答错”,而是“自信地胡说八道”。
- 会不会走流程:我会拿一类“必须追问才能解决”的问题压它,比如“订单一直显示已揽收怎么办”。一个合格的系统应该先追问订单号、渠道、收件信息、是否加急、是否可改地址,然后再给下一步,而不是甩一段万能话术。
- 会不会说人话:同一个正确答案,用不同语气会得到完全不同的用户反馈。我会把“能解决问题”当底线,把“让用户愿意继续聊”当加分项。
文生图(电商/内容生产类)
我不会只问“好不好看”,而会把问题拆成四个很容易执行的检查点:要素齐不齐、风格稳不稳、材质光影真不真、细节有没有崩。
比如白底主图场景,我会重点看:主体是否居中、阴影是否自然、透视是否一致、包装文字/标识是否变形、材质是否符合描述(磨砂/金属/玻璃的反光逻辑是不同的)。
垂类能力(教育/医疗/法律等)
我会把垂类当成“逻辑考试”而不是“语言考试”。因为垂类风险最大的问题不是它不会说话,而是它会用很流畅的表达讲一个不符合行业逻辑的结论。所以我会用更严格的题型:有明确推导过程的任务、或强约束的判断题,并要求答案能解释“为什么”。
对我来说,专项能力评测的目标很明确:它不是为了找“最强模型”,而是为了确定“它有没有资格进入下一关”。我宁愿在这一关把明显不合格的模型挡掉,也不想把它带进系统链路里浪费工程时间。
② 功能模块评测:我测的是“链路”,不是“模型看起来很聪明”
当我进入功能模块评测,我的关注点会从“模型单点能力”切换到“系统协作能力”。我会把 RAG、Agent、多模态都当成一个端到端链路来测,因为很多线上翻车根本不是模型不行,而是链路不稳定、约束没做好、工具调用不可靠。
我会用一句话定义这一类评测:我不是在测“它会回答”,我是在测“它能不能可靠地完成任务”。
RAG 评测:我盯“检索 + 引用 + 约束”
我最关心的是:检索是否找得到、找得准、引用是否正确、回答是否被证据约束。
我会故意塞进“相似但错误”的干扰材料,因为最可怕的错误是:检索拿到了错文档,模型还非常自信地给出结论。一个稳定的 RAG 系统,应该能在证据不足时降低自信、提示缺失信息,或者明确“我需要更多资料”。
Agent 评测:我盯“计划—调用—校验—收尾”
我会把 Agent 当成一个做事的人来考:它能不能先拆目标、再调用工具、再校验结果、最后把动作收口。
我会重点观察三种常见翻车:漏步骤(比如忘记确认关键信息)、调用错工具(把查询当成修改)、以及没校验就下结论(工具返回为空,它也能编一个结果)。
多模态评测:我盯“看懂 + 结构化输出 + 一致性”
我不会满足于“能描述图片”。我更在意的是:它能不能把图里信息结构化,并且在多轮里保持一致。
比如我让它看一张商品图,我希望它输出材质、颜色、版型、细节;下一轮我换一种问法,它还能保持一致,而不是前后自我打脸。
这一类评测做得越好,我越容易定位责任:到底是模型问题、检索问题、工具问题,还是提示词/约束问题。对产品来说,这意味着我能更快迭代,而不是在“模型不行/系统不行”的争论里来回拉扯。
③ 性能指标评测:我不等上线才发现“太慢/太贵/撑不住”
性能指标这类评测看起来偏工程,但它经常是产品成败的分水岭。我见过太多项目:效果评测很好,结果上线后因为响应慢、成本高、上下文撑不住,体验直接崩掉——前面所有“质量优化”瞬间失去意义。
我会用非常朴素的产品语言来定义这类评测:我能不能以可承受的成本,稳定交付这个体验?
- 速度:我不仅看平均时间,还会盯 P95/P99。因为用户体验往往死在长尾:平时都快,高峰期突然慢到不可用。
- 成本/资源:同样的效果,如果成本差一倍,产品策略就完全不同:能不能全量、要不要分层路由、是否需要降级。
- 上下文:我会拉长多轮对话,观察它会不会“前面说过的自己忘了”。很多复杂任务并不是模型不会推理,而是上下文一断,链路就断。
我用一个“选择流程”让评测不再散
为了避免“什么都测一点”,我会用下面这个极简决策流程来决定本次评测的主战场。它同样适合你直接放在文章里当作总结图。
我现在处在什么阶段?
未更改: │
未更改: ├─ 选模型 / 换模型 / 新模型到手 → 先做①专项能力(确认有没有资格)
未更改: │
未更改: ├─ 做成系统 / 接 RAG / 上 Agent / 做多模态 → 主做②功能模块(把链路测稳)
未更改: │
未更改: └─ 准备上线 / 扩量 / 预算敏感 / 高峰期风险 → 补齐③性能指标(跑得动、扛得住)
这套逻辑对我最大的价值是:每一轮评测都能产出“能推动行动”的结论——我能明确告诉团队:这次评测是为了“选谁”、还是为了“修哪里”、还是为了“能不能全量上线”。
我这篇文章最后想留下的一句话:
我做模型评测不是为了跑分,也不是为了做漂亮的报告。我真正想要的是:**用一套清晰的分类,把“我觉得”变成“我有证据”,把“争论”变成“决策”。只要评测能推动下一步动作,它就是有价值的;反过来,如果评测做完没人知道该做什么,那它大概率只是一次“看起来很努力”的自我感动。
共勉!棒棒,你最棒!
本文由 @青蓝色的海 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自unsplash,基于CC0协议






- 目前还没评论,等你发挥!


