
 起点课堂会员权益
起点课堂会员权益AI产品经理必修课:从“半成品”到“杀手级应用”——深度解析后训练(Post-training)
2025年AI领域最深刻的变化,不是算力的军备竞赛,而是后训练技术的战略崛起。从SFT塑造产品人格、RLHF量化用户体验,到推理模型实现System 2思考,本文以卡帕西的经典理论为框架,揭示AI产品经理如何将原始模型雕琢成商业产品。这不仅是技术解码,更是一份从'数据贵族化'到'工具路由'的实战指南。
对于产品经理(PM)而言,预训练结束后的基座模型(Base Model),仅仅是一个充满了潜力的“半成品”。它就像是一个刚刚开采出来的巨大钻石原石——虽然价值连城,但如果不经过切割、打磨和镶嵌,它不仅无法佩戴,甚至可能会因为棱角尖锐而划伤用户。
今天是2025年的最后一天。在这个辞旧迎新的时刻,让我们再次回到卡帕西那发布于年初、却依然被奉为圭臬的视频,用AI产品经理的视角,深度拆解他是如何讲述AI“从0到1”的下半场——后训练(Post-training)。
如果说预训练是“拼算力、拼资源”的军备竞赛,那么后训练就是“拼策略、拼体验”的产品战场。
前言:除了算力,我们还能拼什么?
站在2025年的尾巴上回望,你会发现今年是“后训练”技术井喷的一年。虽然各大厂的基座模型参数量还在增长,但真正拉开产品体验差距的,往往是SFT的数据质量、RLHF的调优策略以及推理时(Test-time Compute)的思考能力。
对于由于资源限制无法进行大规模预训练的大多数企业和PM来说,后训练阶段才是我们真正的战场。
卡帕西在视频中极其精准地指出了基座模型的缺陷:它不是一个助手,它只是一个“文档补全器”。它不知道什么时候该停止,不知道如何礼貌拒绝,甚至不知道它是谁。
后训练的目标,就是完成从“技术原型(MVP)”到“商业化产品(Product)”的惊险一跃。
第一章:SFT(监督微调)—— 定义产品的“人格”与“规范”
如果把基座模型比作一个通读了图书馆所有书籍、但毫无社会经验的“天才书呆子”,那么**监督微调(Supervised Fine-Tuning, SFT)**就是岗前培训。
1/技术原理:从“续写”到“对话”
在预训练阶段,模型的目标是“预测下一个词”。在SFT阶段,目标依然没变,但数据集变了。
卡帕西指出,我们不再喂给它杂乱的网页,而是喂给它格式极其严整的<User, Assistant>对话数据。
PM视角解读: 这不仅是技术微调,更是**产品交互设计(Interaction Design)**的固化。通过SFT,我们将“提示词工程(Prompt Engineering)”内化到了模型权重里。如果你希望你的AI产品在面对用户辱骂时能礼貌回击,或者在写代码时遵循PEP8规范,这些都需要在SFT阶段通过数据“教”给它。
2/数据的“贵族化”:Quality over Quantity
预训练数据追求“大”,SFT数据追求“精”。
视频中卡帕西强调,SFT的数据量通常很小(几万到几十万条),但必须由人类专家精心编写。
- PM实战痛点: 这解释了为什么Scale AI这样的数据标注公司估值在2025年依然坚挺。作为PM,你的核心壁垒不再是拥有多少GPU,而是拥有多少高质量的、垂直领域的SFT数据。
- 如果你做医疗AI,你需要的是真正的医生去编写“标准答案”,而不是随便找个兼职大学生。
- 成本结构变化: 预算从购买显卡转移到了聘请专家(SME)上。
3/局限性:SFT无法创造知识
卡帕西做了一个非常形象的比喻:SFT就像是让模型模仿专家的“语气”和“解题格式”,但如果模型本身在预训练阶段没见过某个知识点,SFT是教不会它的。
- 幻觉(Hallucination)的来源之一: 如果你强行要求模型回答它不知道的问题,SFT会让它学会“不懂装懂”,用自信的语气胡说八道。
- 产品决策: 永远不要指望通过SFT来注入新知识(例如昨天的股价)。SFT是用来规范行为的,新知识必须依靠RAG(检索增强生成)或工具调用。
第二章:幻觉与工具使用(Tool Use)—— 承认缺陷,外挂“大脑”
任何成熟的产品经理都知道,产品的核心竞争力往往在于“如何优雅地处理边缘情况”。对于LLM来说,最大的边缘情况就是——它不知道自己不知道。
1/为什么会有幻觉?
卡帕西演示了询问一个不存在的人名,模型编造了一段生平。这是因为模型本质上是一个概率统计引擎,它的任务是维持对话的流畅性(Probability),而不是事实的准确性(Truthfulness)。
2/解决方案:把模型变成“路由(Router)”
在后训练阶段,我们教会模型使用“工具”。
- PM视角解读: 这标志着AI从“内容生成器”向**“Agent(智能体)”**的转型。
- 以前的逻辑: 用户提问 -> 模型靠记忆硬答 -> 可能是幻觉。
- 现在的产品逻辑: 用户提问 -> 模型识别意图(Intent Recognition) -> 模型决定调用搜索工具/计算器/代码解释器 -> 获取真实数据 -> 整合输出。
- 关键指标: 这里的核心KPI不再是单纯的Token生成速度,而是工具调用的准确率(Success Rate)。作为PM,你需要设计测试集来评估:模型是在该查天气的时候查了天气,还是在那胡编乱造?
第三章:RLHF(人类反馈强化学习)—— 用户体验的量化与对齐
SFT教会了模型“怎么说话”,但没教会它“什么是好话”。比如写一首诗,文法正确(SFT能做到)和意境优美(RLHF的目标)是两码事。
1/奖励模型(Reward Model):构建“品味裁判”
- 让全人类给模型的每一次回答打分是不现实的。所以,我们训练了一个小一点的模型——奖励模型(RM)。
- 工作流: 人类对两个回答进行排序(A比B好) -> 训练RM学会人类的偏好 -> 用RM去给主模型(LLM)的回答打分。
- PM视角解读: 这就是自动化、规模化的A/B测试。
- 在传统互联网产品中,我们需要上线功能看用户点击率。
- 在AI模型开发中,RM就是那个模拟用户的“虚拟体验官”。它可以24小时不间断地对模型进行“灰度测试”和反馈。
2/RLHF的本质:Vibe Check(感觉对齐)
卡帕西提到,RLHF更多是改变模型的分布(Distribution),让它更倾向于生成人类喜欢的回答(如:乐于助人、无害、诚实)。
- 风险提示(Goodhart’s Law): 当一项指标变成目标,它就不再是一个好指标。
- Reward Hacking: 模型可能会为了讨好RM而学会“拍马屁”,生成虽然得分高但实际上无意义的废话(Verbose)。
- PM实战: 必须警惕模型变得过于“油滑”或“政治正确”而失去了个性。你需要在Prompt和RLHF数据中引入多样性(Diversity)约束。
第四章:思考(Thinking)与推理 —— 从System 1到System 2
这是卡帕西视频中最令人兴奋的部分,也是2025年下半年爆发的**“推理模型”(如DeepSeek-R1, OpenAI o1)**的理论基石。
1/AlphaGo时刻的重现
卡帕西将AlphaGo的原理映射到了LLM上。AlphaGo之所以能赢,是因为它自己跟自己下棋(Self-play),并由系统判定输赢。
在数学和编程领域,我们也有完美的判定标准(代码能否运行?答案是否正确?)。
这意味着,我们不需要人类老师(SFT),只需要让模型自己尝试成千上万次,做对得奖励,做错受惩罚。
2/思考链(Chain of Thought)的内化
通过强化学习,模型学会了在输出最终答案前,先在内部生成一段“思考过程”。它可以自我纠错、反思、尝试不同路径。
- System 1(快思考): 也就是ChatGPT-3.5/4的模式,张口就来,凭直觉回答。
- System 2(慢思考): 现在的推理模型,在回答前会“停顿”几十秒。这几十秒里,它在进行高强度的思维推演。
3/PM视角的颠覆性变化
这完全改变了AI产品的商业逻辑和交互逻辑。
- 交互设计: 用户不再期待“秒回”。你需要设计一个“思考中…”的优雅动效,甚至展示(或部分展示)它的思考步骤,以增加用户的信任感。
- 成本与定价(Token Economics):
- 以前:用户输入100词,输出100词,收200词的费。
- 现在:用户输入100词,模型思考了5000词(隐藏不输出),输出100词。
- PM决策: 这5000个隐性Token的成本谁来买单?是提高单次对话定价?还是在B端场景中按效果付费?
- 应用场景: 对于闲聊、写邮件,System 1足够了且更便宜。对于复杂的逻辑推理、写长代码、法律文书分析,System 2是必须的。PM需要构建“模型路由”,根据问题的难易程度动态调用不同模型,以平衡成本与体验。
结语:从“炼丹师”到“产品架构师”
安德烈·卡帕西的这个视频,虽然发布于2025年2月,但它不仅讲透了原理,更预言了全年的技术走向。
通过对后训练(Post-training)的拆解,我们看到AI产品的构建不再是单一的“训练模型”。它变成了一个复杂的系统工程:
1/SFT 确立了产品的交互规范。
2/工具使用(Tool Use) 拓展了产品的能力边界。
3/RLHF 保证了产品的用户满意度。
4/强化学习(Thinking) 提升了产品的智力上限。
作为2025年的AI产品经理,我们的职责不再是盲目地追求“更大的模型”,而是像一位精明的指挥家,协调这些技术手段——在需要准确性时调用搜索,在需要人性化时依赖SFT,在需要攻克难题时启动推理模式。
技术在飞速迭代,但“理解用户需求”并用“最合适的技术组合”去满足需求的底层逻辑从未改变。
如果你还没看过原视频,请务必抽出一个小时。因为在AI的世界里,理解了“从0到1”的原理,你才能看清“从1到100”的路。
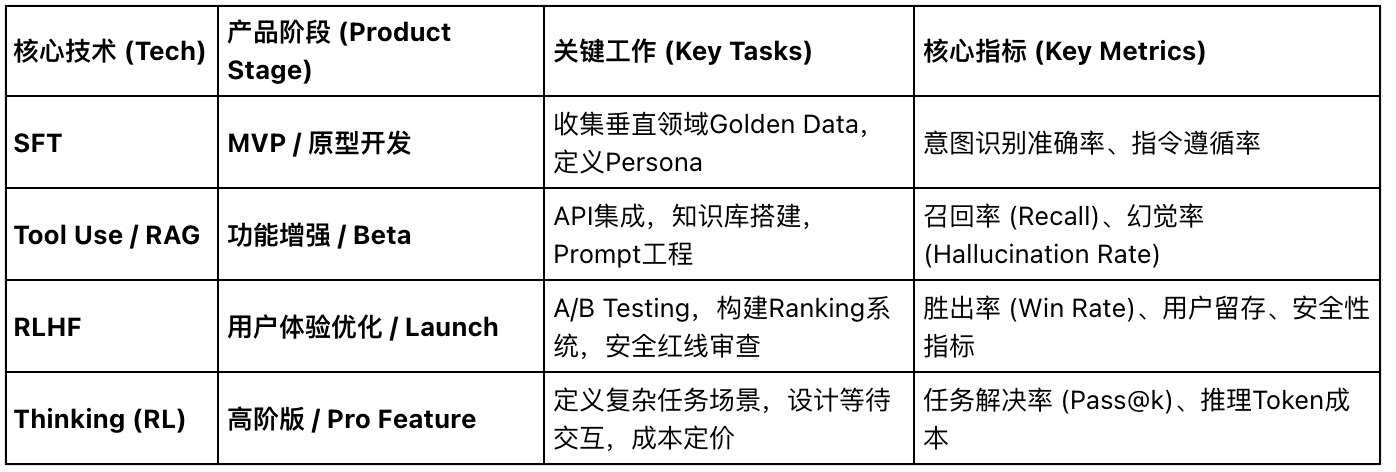
AI PM 核心术语与工作流映射表
本文由 @Echo想要全链跑通 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


