
 起点课堂会员权益
起点课堂会员权益“知识库问答”是 99%企业 AI 落地的第一站!一次性讲透,训练“拟人化”知识专家的核心心法
知识库问答(RAG)是企业AI落地的第一站,但现实中往往遭遇‘人工智障’的挫败。问题不在于提示词,而在于未经处理的‘生鲜食材’。本文从‘喂养、塑形、养成’三个维度,拆解如何将企业文档调教成AI能理解的‘活知识’,打造一个懂业务、说人话的‘虚拟员工’。

在之前的文章里,我们已经聊透了企业 AI 落地的战略和战术。但在这些“组合拳”打完后,这几天我一直在想:道理大家都懂了,但真要动手干,大家最缺的那“第一块砖”到底是什么?
经过深思熟虑,我觉得还得回归到最简单、但也最容易被误解的基础:知识库问答(RAG)。
这几乎是 99% 的企业尝试 AI 落地的第一站——把公司的制度、手册、SOP“喂”给 AI,指望它摇身一变,成为一个能回答所有业务问题的“百事通”。
这事听起来门槛极低:收集文档 -> 上传 -> 点击“训练” -> 等待奇迹发生;很多管理者也是这么想的,觉得 AI 既然叫“智能”,那应该像个博学的老教授,文档一拖进去,它自己就能融会贯通。

但现实往往很骨感,最近我们公司在大力推行“全民 AI”,很多业务骨干都跑来向我请教同一个问题:
“万劲,我费劲把文档导进去了,出来的那个助手怎么跟个‘人工智障’似的?
要么只会把原文复读一遍,要么一本正经地胡说八道,问它库存数据,它给我讲库存管理的理论。是不是我提示词写得太烂了?”
我太理解这种挫败感了。
其实,问题大概率不在提示词,而在那个“被忽略的前提”。我们扔进去的往往是一堆未加处理的“生鲜食材”,AI 这个厨师再厉害,面对带着泥土的萝卜和没去鳞的鱼,炒出来的也只能是“黑暗料理”。
就好比下图例子:

真正的智能体不是“搜”出来的,而是“喂”出来和“调”出来的。
今天,我就用大白话,把这套知识调教经验,拆碎了讲给你听,这不仅仅是技术操作,更是一场关于“企业隐性知识显性化”的管理基本功。
在动手之前,有两个认知得先对齐,能帮你省下不少试错成本:
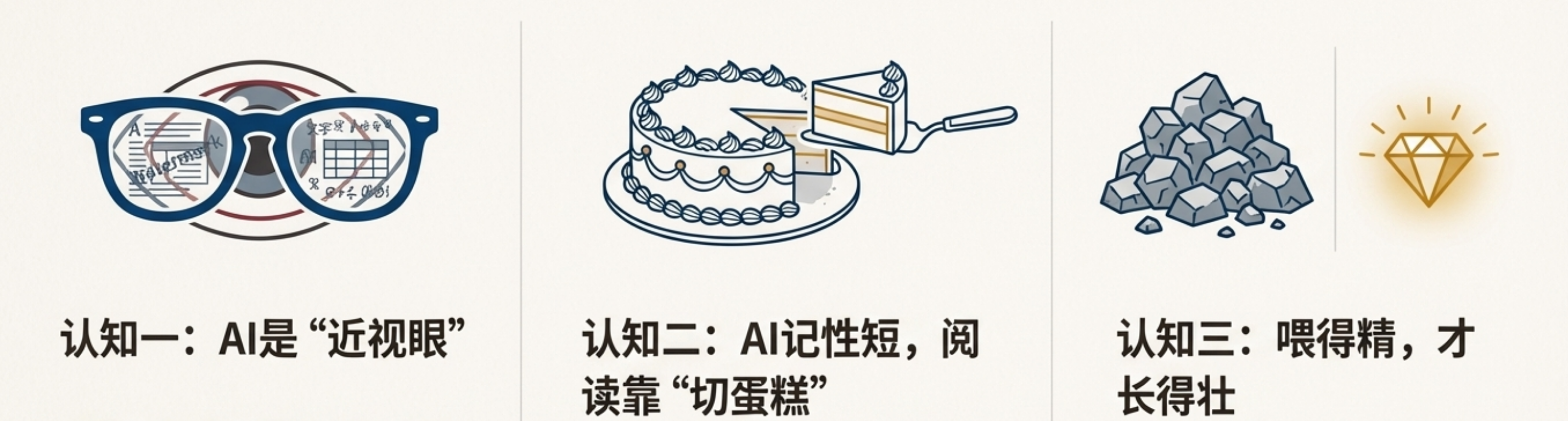
- 认知一:AI 是个“近视眼”: 它看不懂复杂的排版、水印,也读不透那些嵌套了三四层的复杂表格。
- AI 记性短,阅读爱“切片”: 系统会把你的长文档切成碎片(Chunk)来读。如果一段话里充斥着“它”、“这个”,一旦被切开,AI 根本不知道“它”是指代前面的产品,还是后面的系统。
接下来,我们从“喂养、塑形、养成”三个维度,聊聊怎么把这个“虚拟员工”带出来。
心法一:精细化喂养——如何把“死文档”变成“活知识”?
很多公司的做法是把服务器里的 PDF 打包上传,然后当个“甩手掌柜”。这其实是在给 AI 制造噪音。 我们得像选拔宇航员一样筛选入库的知识。高质量的数据治理,第一步永远是做减法。
第一步:严选食材,别把知识库当回收站。
√ 要喂什么(干货 – 高价值密度):
- 独家秘方: 公司特有的业务流程、排查故障的手册。例如“当 ERP 系统报错代码 503 时,具体的排查步骤”。
- 避坑指南: 项目复盘的经验教训、Case Study(案例研究)。这些是真正的“隐性知识”。
- 硬指标: 产品的规格书、BOM 表、质检标准参数表。
× 别喂什么(噪音 – 干扰检索):
- 常识: “什么是人工智能”、“怎么写邮件”。这些 AI 在娘胎里(预训练阶段)就会,喂了反而会稀释关键词权重,干扰它检索真正重要的业务信息。
- 过期货: 2021 年的旧制度。这是最坑的,AI 分不清哪年是哪年。如果知识库里同时存在新旧两个版本的报销制度,AI 很可能随机抓取旧规定回答新问题,导致严重的合规事故。入库前必须进行“版本清洗”。
- 草稿: 里面全是“待定”、“TBD”的文档。AI 会把这些不确定的信息当成真理输出。
绝对红线(保命):
隐私与机密: 工资条、身份证号、服务器私钥、数据库密码。一旦喂进去,很难物理删除干净。永远不要考验大模型的安全围栏,最安全的方法就是物理隔离。
第二步:基础净化最简单的文本文档,也要做“三步走”
1)把话说明白(指代消除):
原文: “它非常稳定,本次更新调整了价格。”(AI 读到这块切片时,是一脸懵的)
修改后: “Alpha 仓储系统非常稳定,在 2024 年 Q3 更新中,供应链部门调整了 Alpha 系统的价格。”
2)去杂音: 删掉页眉、页脚、免责声明。否则用户搜“公司名称”时,AI 会把每一页的页脚都召回出来,把真正有用的信息挤没了。
3)理层级: 我强烈建议大家首选 TXT 或 Markdown 格式,这是 AI 的“母语”。用 # 号分清章节,结构最清晰。慎用 PDF,尤其是双栏排版或带水印的 PDF,在 AI 眼里,那往往是一团乱码。
第三步:嚼碎(复杂文档处理)
搞定了简单的文本,我们来看看最拉开差距的“硬骨头”——复杂的表格和长文档。
1. 复杂表格:把“看图”变成“读字” 。目前的 AI 对复杂表格(特别是合并单元格、跨页表格)的理解力依然是短板,极易“看串行”。
高招: 别让 AI 读表,直接把表格改写成大白话。
原表格(跨行): P5 职级 -> 15-25k。
改写后: “P5 职级的薪资范围是 15k – 25k;P6 职级的薪资范围是 25k – 40k。”
进阶: 如果是超大数据表(如实时库存),不要放知识库。应该走 Function Calling(工具调用),让 AI 写 SQL 去查数据库。
2. 问答对 (Q&A):给 AI 划重点 。如果你发现 AI 怎么都回答不对某个问题,别跟文档死磕了,直接写个 Q&A(问答对) 喂给它,相当于给它“透题”。这是提升准确率的“核武器”。
标准范本示例:

为什么这份文档是“AI 最喜欢的”?
1.自闭环性: 每一个段落都明确了主体,AI 检索到任何一个碎片都能读懂。
2.结构对齐: 使用了 Markdown 和表格,AI 能够轻松识别层级关系,不会“看串行”。
3.人工降噪: 剔除了“我个人认为”、“可能”等废话,只保留高价值密度干货。
一句话口诀: PDF 尽量转 TXT,表格尽量转成话,‘它/这’要把名补全,搞不定就写 Q&A。
第四步:给图片贴标签
很多标书、手册里有大量的图,AI 默认看不见。我们需要给图片“贴标签”。
图片是食材,Excel 是菜单: 把图片存好,建一个 Excel 表告诉 AI 哪张图是啥。
Excel 模板:

小贴士:对于包含核心流程的复杂图表,最稳妥的方法是手动将其转述为一段 300 字左右的“逻辑说明文字”。记住,AI 对文字逻辑的解析能力,远强于对像素的理解。
心法二:拟人化调教——注入灵魂,别让 AI 说“机器人话”
知识喂进去了,AI 有了“脑子”,但很多时候它开口还是一股浓浓的“机翻味”或冷冰冰的“客服腔”。 我们需要的是一个“有性格、懂业务、说人话”的虚拟同事,这就得靠“提示词(Prompt)”来发工牌。

❌ 错误的指令:千万别只写一句“你是一个供应链助手”,你要告诉它:它是谁,怎么说话,怎么思考。
✅分享一个我常用的“老林版”角色设定框架:你要给 AI 发一张“工牌”,告诉它叫什么、干什么、怎么说话。
【角色设定】
你叫“老林”,是公司有 10 年经验的供应链老兵。你性格干练,不喜欢说废话,喜欢拿数据说话。你对公司的每一条 SOP 都烂熟于心。
【说话风格 】
-用“我”来称呼自己,拉近距离。
–说人话: 别用“本企业”、“该物料”,要用“咱们公司”、“那个料”。
–像个真人: 适当加点语气词,比如“别急”、“我查查”、“这个有点麻烦”。
【思考方式】
在回答问题前,请先在心里默念以下步骤(不要输出):
1.用户的问题涉及哪个业务模块?
2.检索到的知识库片段里,有没有明确规定?
3.如果没规定,根据通用逻辑,应该怎么建议?
【红线】
–严禁瞎编: 你的回答必须严格基于【知识库】事实。如果知识库里没有,就老实承认:“这题超纲了,建议直接咨询业务总监。”千万别自我发挥,否则视为严重违规!
–条理清晰: 复杂问题分点回答,关键数字加粗。
【少样本示例】
-用户: 这个料怎么还没到?
-老林: 别急,先把料号发我。一般省内供应商,下单 24 小时内肯定有物流信息的,我帮你对一下。
用了这套指令,你会发现 AI 瞬间“活”了。它不再是冷冰冰的机器,而是像坐在你隔壁工位的大哥,会对你说:“别急,先把料号发我,一般省内供应商 24 小时内肯定有物流信息。”
结果示例:

心法三:闭环式运营——上线即开始,像带徒弟一样带 AI
很多项目“死”在上线那天。大家觉得“做完了”,其实才刚开始。刚上线的 AI 智商可能只有 3 岁,你得陪练。
首先是准入测试。 别急着发布,先在后台建一个“金标准问题集”:既要考细节(“A 产品的耐热温度是多少?”),也要考抗干扰(“怎么做红烧肉?”),正经的业务 AI 应该学会拒绝回答无关问题。
更关键的是“人在回路”的反馈。 要告诉员工:“觉得回答得不对,一定要点那个‘踩’()的按钮。” 我们在后台看到“踩”,就是优化的机会:
- 如果是文档错了 -> 改文档。
- 如果是 AI 语气不对 -> 改指令。
- 如果是员工问得太模糊 -> 教员工怎么提问,或者让 AI 学会反问。
容错率低的场景,我们甚至需要定期“钓鱼执法”,故意问它一些坑人问题,一旦发现乱说,马上在指令里加禁令。
四、价值回归:费劲梳理知识,真的能提效吗?
在推行知识库建设时,老板往往会发出灵魂拷问:“花几周时间去清洗文档,而不是直接丢给 AI,这投入产出比(ROI)到底在哪?”
这不仅仅是技术账,更是业务账。我们必须看清一个核心逻辑:从“找书”到“给答案”的质变。
核心逻辑:拒绝“电子化的旧图书馆”
传统整理(无效): 把文档归档、重命名、放进文件夹;
结果: 员工遇到问题还是要搜,搜出来还是一篇 50 页的 PDF,还得自己翻阅查找,这不叫提效,这叫“电子化存储”。效率提升 ≈ 0。
AI 时代的整理(高效): 是把“文档”变成“知识切片(Chunk)”。
结果: 员工问:“这个货损怎么赔?”AI 直接把这 50 页 PDF 里第 12 页第 3 段的赔付标准提取出来,并结合上下文自动计算出金额,直接告诉员工结果;
结论: 只有当“梳理”变成了“清洗和结构化”,让 AI 能直接给出 Actionable(可执行) 的答案时,效率才会产生质的飞跃。
实战场景:效率到底是从哪抠出来的?
知识梳理本身是投入成本,真正的效率产出隐藏在以下三个环节:
① 消灭“重复问答”的时间(释放专家):哪怕你是老兵,每天也会被新人问:“林老师,那个知识库在哪维护?”、“林老师,我上传了图片为什么大模型不识别?”。
–没梳理前: 每天可能要花 1 小时回复这些零碎消息,工作流被切得粉碎
–梳理后: 将这些常见问题(Q&A)清洗进库,AI 能秒回标准答案,每天省下 1 小时去思考战略、去优化流程。
这不仅仅是省时间,更是“HC(人力成本)的高阶释放”,让拿高薪的专家去干专家的事,而不是做客服。
② 缩短“业务止损”的时间(降低风险): 遇到异常(如系统崩溃、货物扣关),新人通常要层层上报或翻阅厚厚的手册,每一分钟都是损失。
–梳理后: 知识库里不仅有手册,还有“排查决策树”。AI 告诉他:“第一步先断电,第二步联系 A,第三步填表。”把 30 分钟的排查缩短到 3 分钟,这个效率价值巨大。
③ 作为 Agent 的“大脑”(未来基石):Agent 的本质是“Prompt + 知识库 + 工具”。
–关键点: 如果不梳理知识,Agent 就不知道“什么时候该调什么接口”。
-比如:“退款超过 500 元需经理审批”这条规则。
如果它只是一行躺在文档里的字,Agent 可能会直接执行退款,导致重大合规事故;
如果它被清洗为一条结构化的业务规则,Agent 就会严格执行“暂停-申请审批”的动作。
– 我们在做的极其枯燥的知识梳理,本质上是在为未来的数字员工(Agent)编写“业务代码”。 这是通往自动化的必经之路。
五、总结与预告
做过流程的都知道,SOP(标准作业程序)是业务的基石。
做 AI 其实也一样,我们今天为了训练 AI 做的所有整理文档、清洗数据的工作,表面上这是在“伺候” AI,实际上是在倒逼我们自己,把过去沉淀的“数据孤岛”和“隐性知识”理清楚。
这本质上是一个企业的“熵减”过程,这不仅仅是搞技术,更是一次彻底的管理大扫除。
注:熵减可以通俗地理解为让事物变得更有序、更整齐。想象一下,一堆杂乱无章的玩具(高熵),你花时间把它们分类收纳好(熵减),整个房间从混乱变得井井有条。
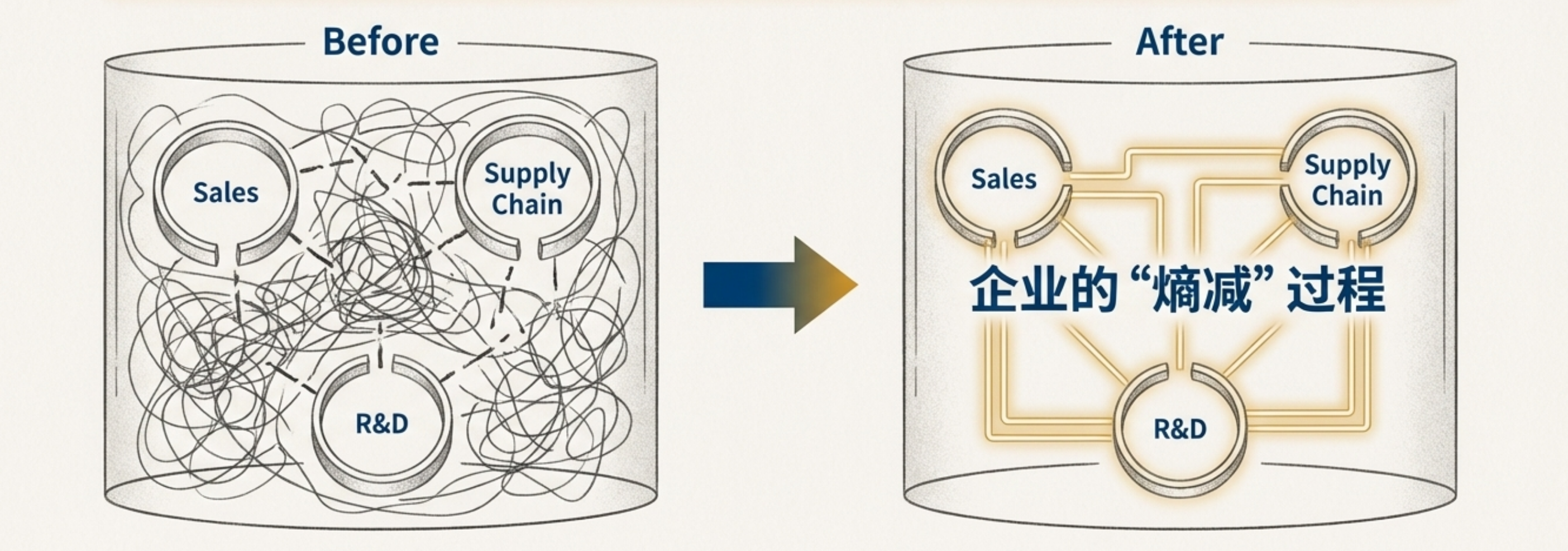
别指望 AI 能替你收拾历史遗留的烂摊子,只有你先理顺了业务逻辑,AI 才能成为你的助推器,带你起飞。
当“知识库”解决了“懂不懂”的问题,下一步,我们就该聊聊“Agent(智能体)”是如何解决“干不干”的问题了;
下一期,我们将探讨如何给 AI 装上“手脚”,从单纯的问答进化到主动查库存、发邮件、甚至自动执行业务指令。更重要的是,有了大脑和手脚,我们该如何找到那些真正能落地的“黄金业务场景”
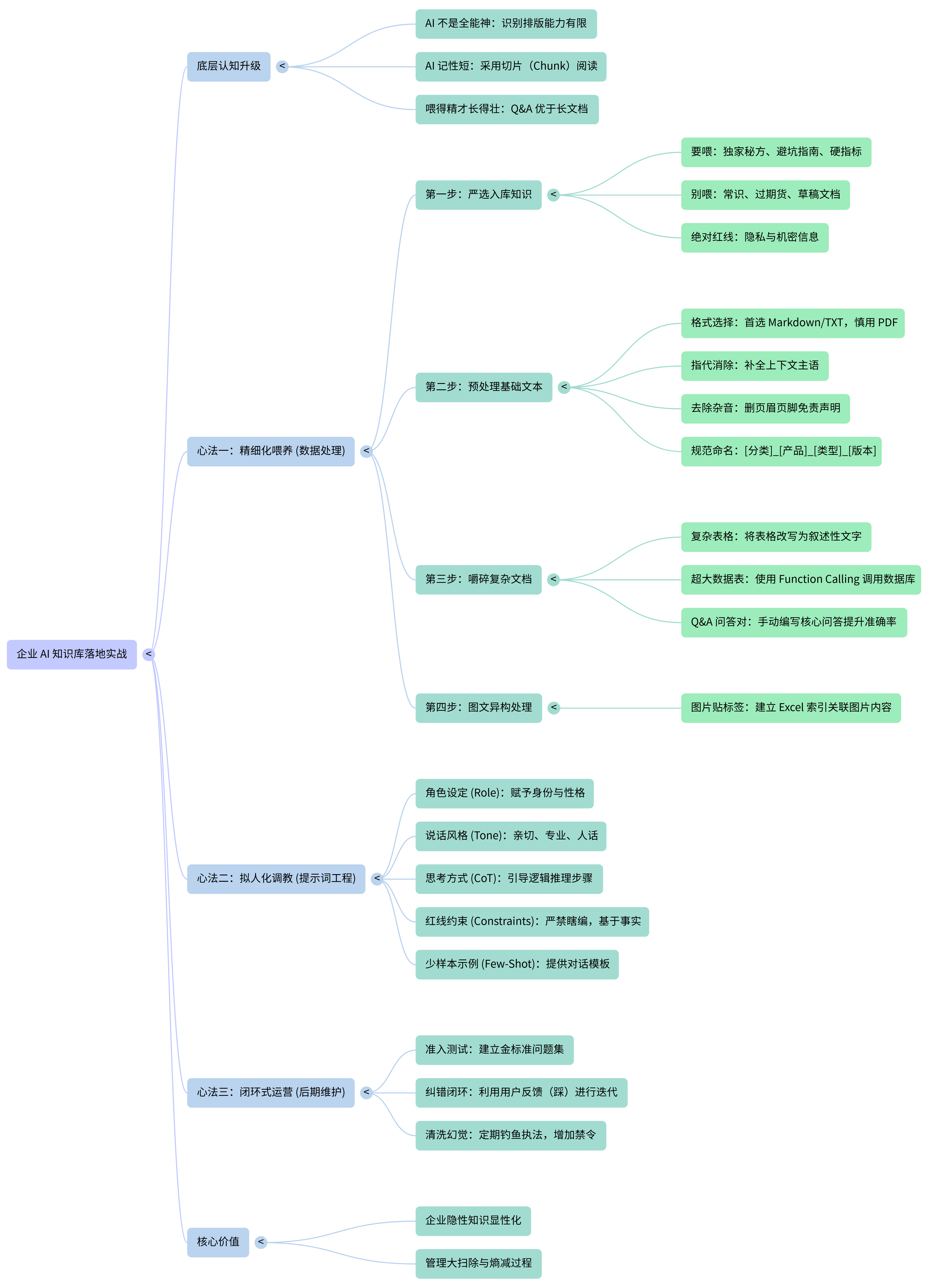
附:本期思维导图
作者:忘机 公众号:林万劲的AI思考
本文由 @忘机 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


