
 起点课堂会员权益
起点课堂会员权益RAG洞察-从FileSearch到GraphRAG的技术选择
大模型在业务落地中面临知识延迟、幻觉问题和数据安全三大挑战,检索增强生成(RAG)成为关键解决方案。本文深度解析全托管File Search、标准RAG和进阶GraphRAG的技术差异与应用场景,帮你找到最适合业务需求的知识增强路径,并展望混合策略与未来发展趋势。
随着大模型(LLM)在业务中的深入应用,我们面临着三大核心挑战:大模型训练截止导致的知识延迟(如最新的优惠活动)、专业领域问题上的“一本正经胡说八道”(幻觉) 、以及病历影像等核心数据安全风险 。
为了解决这些问题,检索增强生成(RAG)已成为让大模型“有据可查”的标准范式 。但在实际落地中,我们需要根据业务复杂度,在全托管 File Search、标准 RAG 和进阶 GraphRAG 之间做出选择。
一、介入流程与架构差异
在引入外部知识库时,不同技术方案的“介入深度”和“数据处理流程”存在显著差异。
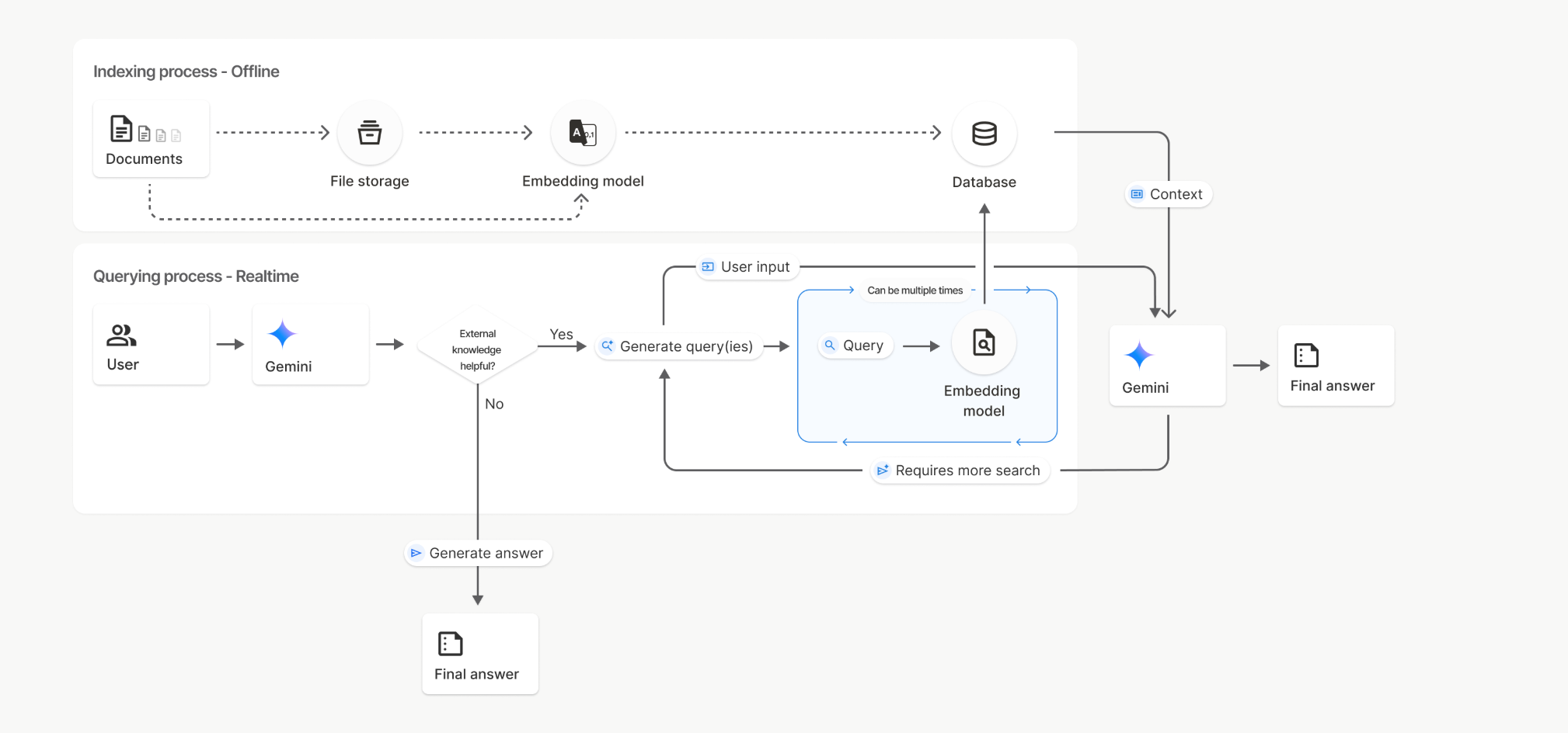
1. Gemini File Search (全托管模式)
这是大厂提供的“开箱即用”服务,适合快速验证。
介入流程: 开发者主要负责上传文件和调用 API。
黑盒风险: 文档解析、分块和检索逻辑由厂商托管。虽开发极快,但无法针对特定术语进行深度调优。
文件搜索的索引和查询过程
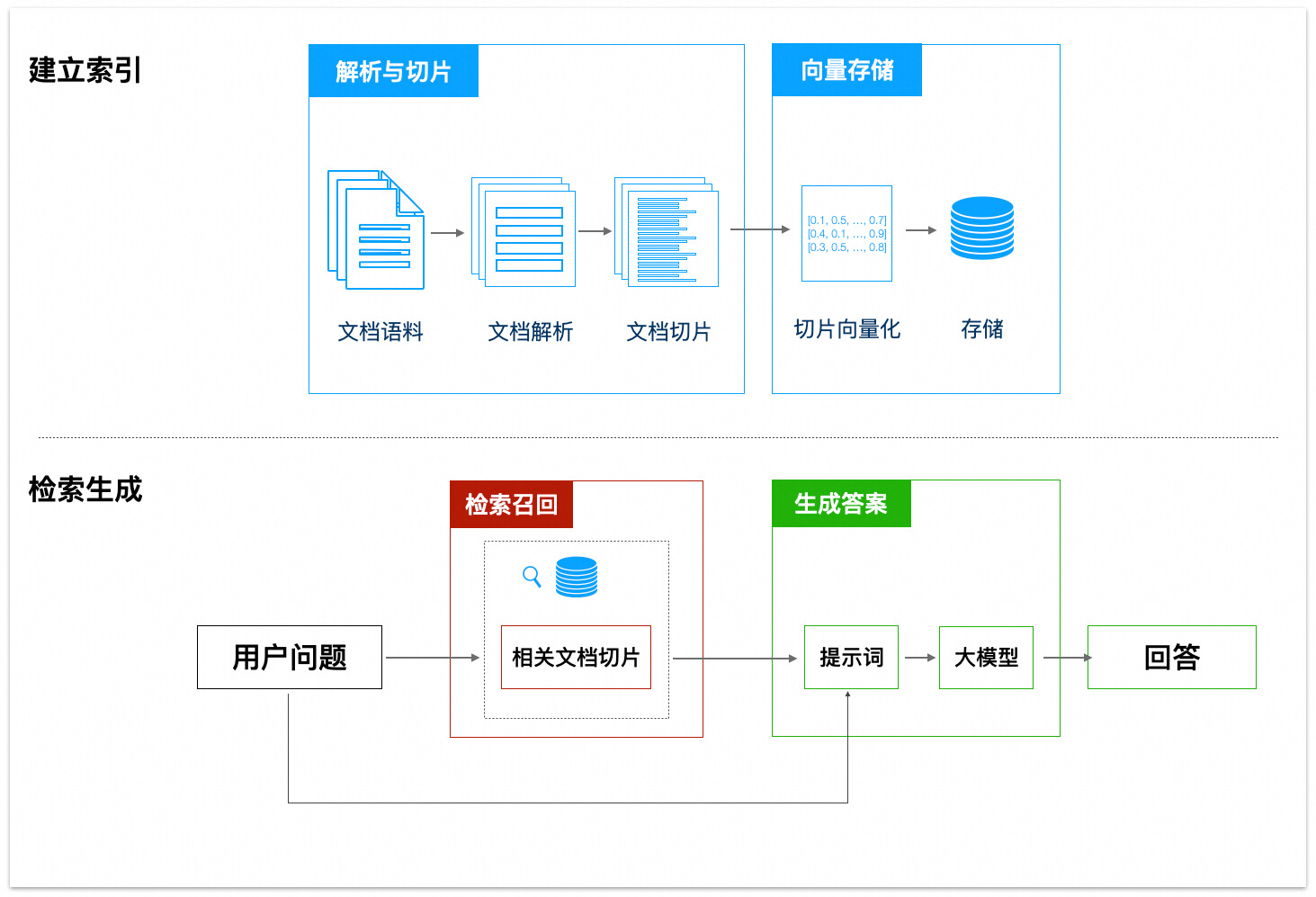
2. Standard RAG (自建标准模式)
这是目前主流的自研路径,核心流程分为“准备”和“问答”两步 。
准备阶段(离线):
- 分片: 将临床指南(PDF)、诊疗常规(Word)切分成知识片段 。
- 向量化 (Embedding): 使用 Embedding 模型将文字转换为计算机理解的“数字坐标” 。
- 索引: 将向量存入向量数据库 。
问答阶段(在线):
- 召回 (Recall): 将用户问题转为向量,寻找最相似的 N 个片段 。
- 重排 (Rerank): 使用 Rerank 模型对召回结果二次排序,优中选优 。
- 生成: 将问题和相关片段打包给大模型生成精准答案 。
3. GraphRAG (知识图谱增强)
当业务涉及深层关联分析时,标准 RAG 不再适用,需引入知识图谱 。
- 介入流程: 在 RAG 基础上增加了结构化知识构建。
- 图谱构建: 提取“节点”(如患者、种植体品牌)和“关系”(如适用、属于) 。
- 检索推理: 不再仅依靠文本相似度,而是在“知识网”中推理,寻找实体间的路径 。
二、适用场景决策
我们需要根据用户需求是“找文档”还是“求洞察”来选择方案。
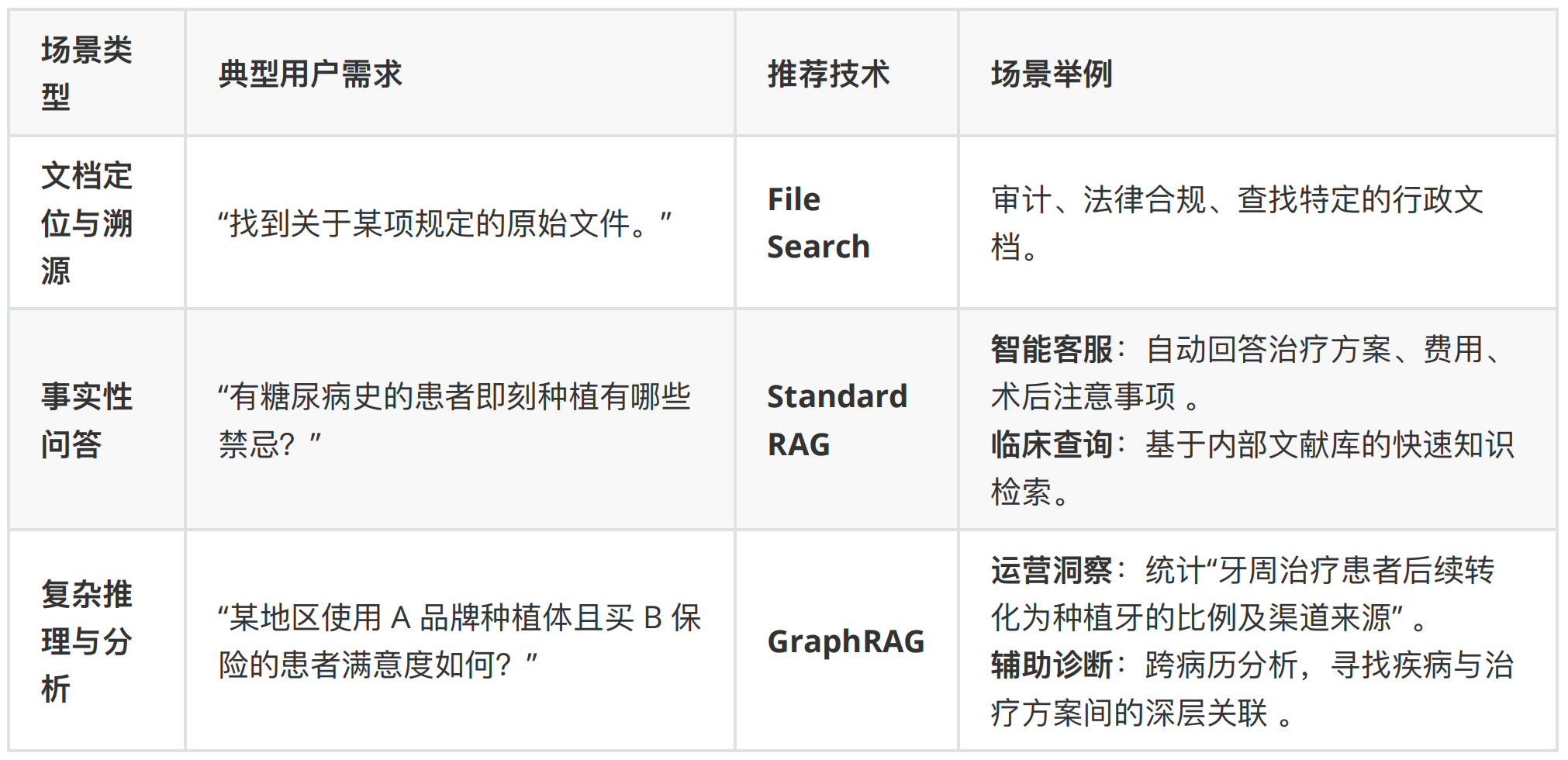
核心价值对比:
- Standard RAG: 优势在于知识更新快(只需更新文档无需重训模型)以及答案可溯源(能标注来源)。
- GraphRAG: 优势在于解决“信息碎片化”,通过图谱关联进行深度推理,提供更有洞察力的答案 。
三、混合策略与未来发展趋势
单一技术难以覆盖所有角落,未来的技术规划将向“更高精度”和“更深理解”演进。
1. 基础设施升级
为了从源头提升召回准确率,我们升级核心组件:
- 模型升级: 部署业界领先的 BAAI m3 系列模型(Embedding 和 Reranker),在中文场景下更精准理解专业术语 。
- 数据库迁移: 将向量数据库从 ES 更换为更专业的 Infinity,以支持更大规模知识库的扩展 。
2. GraphRAG 的深度探索
针对辅助诊断等复杂场景,我们将探索 GraphRAG 技术 。
- 混合检索策略: 结合文本相似度检索(Standard RAG)和图谱关系推理(GraphRAG)。
- 案例演示: 比如分析“武汉地区 + A品牌种植体 + B保险计划”的满意度,GraphRAG 可以先定位符合条件的所有“患者节点”,再聚合分析其“满意度属性”,而非在海量文档中大海捞针 。
3. 场景构建规划
基于上述技术,我们将构建更丰富的应用场景:
- 对外: 打造能回答专业问题、费用咨询的智能客服 。
- 对内: 赋能管理者的运营数据洞察,分析转化率与渠道来源 。
总结: 技术路线图是清晰的——从利用 Standard RAG 解决“大模型幻觉”和“数据私有化”问题起步,通过升级Embedding/Rerank 模型 夯实基础,最终向 GraphRAG 演进,以实现对数据的深度理解和复杂推理,为企业赋能 。
本文由 @里奥 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


