
 起点课堂会员权益
起点课堂会员权益a16z:Agent 表现不好,可能是缺乏正确的数据上下文
市场终于明白了,数据和分析 Agent 要是没有正确的上下文,基本等于摆设。

最近在数据和 AI Agent 的圈子里,上下文层和上下文图谱成了一个绕不开的话题。跟任何一个做数据和 AI 的组织聊天,不出五分钟就会聊到上下文这个话题
这很正常。过去一年,市场终于想明白一件事:数据和分析 Agent,如果没有正确的上下文,基本上就是废物
它们拆不开模糊的问题,读不懂业务定义,也没办法在分散的数据之间有效地推理
这怪不了 Agent。现代数据栈经历了十多年的演进,从分散的数据源走向集中化的数据和清洗过的定义,这是好事。但集中化从来都做不到完美,过程中引入了大量的混乱。大致的演进脉络是这样的:
1、现代数据栈的崛起
我们之前跟 dbt 的 Tristan Handy 聊过这个话题,也在自己的参考架构文章里写过。
过去十年,数据架构在摄取、转换、仓库和存储各个环节都经历了改造,目标是把数据集中起来,让人能快速方便地用上。
理想的画面是:数据整理干净了,团队写写 SQL 就能从数据仓库里提数据,做图表,做仪表板,让整个组织都用上商业智能
2、Agent 狂潮
2024 年进入 2025 年,LLM 的能力越来越强,几乎每一个组织都想在现有的数据栈上搭 Agent。我们以前讨论过怎么定义 Agent。
从组织的角度看,用更少的时间做更多的事,提升效率,这种天然的吸引力把大家都拉向了 Agent 化的工作流。
各公司开始做「跟你的数据聊天」的聊天机器人,做客服 Agent。这股热潮自下而上和自上而下同时发生。开发者想用上最新最亮眼的 LLM 能力,管理层在施压要求 AI 落地,提高自动化,降低成本
3、撞墙
乐观没持续多久。很快就清楚了,大多数这类努力都失败了。组织们部署 Agent,撞了墙。MIT 发表了那份著名的「2025 年商业 AI 现状」报告,说 AI 部署「大多数失败是因为脆弱的工作流、缺乏上下文学习能力、以及与日常运营的脱节」
Agent 表现不好,一个关键原因是缺乏恰当的数据上下文。今天的企业数据依然极度分散和混乱。数据 Agent 连「上个季度的收入增长是多少?」这样的问题都答不好,因为它面对的是横跨结构化和非结构化数据的各种架构
多年前「完全自助式分析」的愿景没有实现。而在数据 Agent 的愿景上,似乎也走上了同一条路
上下文问题:远不止 text-to-SQL
最初那一波 Agent 部署,到底为什么举步维艰?
起初很多人觉得,问题在模型那边,是数据推理能力和 SQL 代码生成能力不够。一般的想法是这样的:模型接收一个自然语言查询,对现有的数据系统做推理,按照传统 BI 的方式生成对应的 SQL 代码,拉取正确的数据,回答问题。如果模型失败了或者不准确,那就是模型 SQL 写得不好,等它慢慢变强就行了
这话也不算全错。模型在代码生成和数学推理方面的能力确实大幅提升了,但在数据方面仍然落后,Spider 2.0 和 Bird Bench 这些 SQL 基准测试可以佐证。模型能力确实有了飞跃,但我们很快意识到,问题远远超出了 text-to-SQL 的范畴
把收入增长的例子再拆细一点来看:
1. 假设一个数据 Agent 在组织内部建好了。用的是现代基础模型,连上了所有该连的数据源,配了个漂亮的界面,让内部用户可以来问数据问题
2. 查询来了。「上个季度的收入增长是多少?」一个看起来很简单的问题。平时看一眼 Looker 或者 Tableau 仪表板就能答上来,对一个高级智能 Agent 来说应该不难吧
3.挑战一:Agent 怎么知道这个组织里「收入」和「季度」到底是怎么定义的? 收入其实是一个业务定义,并没有硬编码在数据仓库或管道里。用户要看的是 run rate 收入还是 ARR?财务季度的划分在不同组织里可能完全不一样,换一家公司,同一个「季度」对应的三个月可能完全不同。该看什么时间窗口?
4. 好在数据平台负责人站出来说:「我们建了语义层,专门解决这个问题,收入定义就在里面。」Agent 应该能把所有语义层作为上下文吃进去。听起来有前途。但团队翻了几个 YAML 文件之后发现,这些文件是去年离职的一个数据团队成员更新的,BI 工具已经不再调用它们了,而且也没有包含后来新上线的两条产品线。Agent 根本不知道收入在今天到底怎么算
5. 为了绕过这个障碍,有人手动把收入和时间窗口的定义硬编码进去了。数据 Agent 继续跑,但很快又撞上了挑战二:正确的数据源在哪里?哪些才是真正的事实源? 原始数据分散在多张表和多个数据仓库里。财务团队用的是 fct_revenue 表,可能是对的。但数据团队还建了物化视图,mv_revenue_monthly 和 mv_customer_mrr 都摆在那里
很明显,数据 Agent 需要一个持续更新的知识库,里面装着业务定义和数据源信息,才能翻过这些坎儿
上下文层登场
问题的要害在这里:Agent 没有被给予恰当的业务上下文,连最基本的问题都答不了。这反映的是一个更大的缺口。在组织内部构建自动化 AI 系统,需要有持续更新和维护的上下文。这个上下文要理解企业怎么运作,数据系统怎么组织,还要承载那些把一切串起来的部落知识
由此催生了上下文层。今天的讨论里冒出来很多名字,Context OS、Context Engine、上下文数据层、本体论(ontology),等等。底层概念是一样的:把企业所有混乱的数据串联起来,在上面加一个帮助 Agent 理解业务逻辑的上下文层,封装好,让 Agent 能用上
上下文管理的既视感
这里停一下…我们说的这些,听起来跟语义层(semantic layer)是不是太像了?
确实有相似之处。但如果 Agent 工作流要真正走向自主化,它们需要的东西比目前语义层所能提供的更多
传统 BI 语境下的语义层,擅长处理特定的指标定义,比如收入、流失率、ARPU。但它们通常是数据团队用非常特定的语法手动构建的,通过 LookML 这样的专用层来写,直接连到 Looker 这样的 BI 工具上
现代数据上下文层应该成为传统语义层所覆盖内容的超集
特定的指标定义当然可以硬编码,但一个现代上下文层要保证 Agent 的自主性,就得包含更多:规范实体、身份消解、拆解部落知识的具体指令、恰当的治理指引,等等
本文主要聚焦于串联传统记录系统的数据上下文。另一个同样重要且有重叠的机会是,捕获组织的决策逻辑和工作流逻辑,这样才能造出真正多用途的 Agent,让它们扎根于组织的全部数据和决策上下文之中
全部串联起来
基于我们最近跟客户的交流和对需求的理解,以下是我们认为一个现代上下文层配合 Agent 化数据系统应该有的样子,分步来讲:
1、接入正确的数据
第一件事是确保所有正确的数据都是可访问的。
这是基本功。
理想情况下,组织应该在用某种形式的现代数据栈,通过湖仓一体架构做一定程度的统一。
即便如此,还得确保 Agent 能访问它需要的所有数据,可能超出仓库和操作型应用里已有的范围。
内部系统里沉淀的部落知识,GDrive 里的,Slack 里的,都算
2、自动化上下文构建
数据都能访问了,下一步是开始建上下文层。用 LLM 的好处是,初始的上下文收集工作很大程度上可以自动化。
重点要放在高信号的上下文上。比如回顾历史查询记录,可以高效地找出被引用最多的表和最常见的 join。
dbt 或 LookML 这样的数据建模工具,能为业务指标提供清晰的定义
3、人工精修自动化
上下文构建也许能覆盖语料的大部分,但拼不出完整的图景。让 Agent 自己去收集所有内部知识,想法很诱人,但一些最重要的上下文是隐式的、条件性的、跟历史偶然相关的,只存在于团队内部的部落知识里
人工输入提供了最后那些关键的连接,让 Agent 的真正自动化成为可能。比如:「CRM 数据,2025 年之后所有北美新交易看 Affinity,之前的全球线索看 Salesforce。」
这样上下文层就可以变成一个多维语料库,代码和自然语言共存,捕获 Agent 可能需要的一切上下文。就像开发者可以设置 .cursorrules 文件来引导 Agent、控制输出行为一样,数据从业者也可以维护自己的规则和指引
4、Agent 接入
上下文层建好了,把它暴露给 Agent,实现实时可访问就行。通常通过 API 或 MCP 来完成
5、自更新的上下文流
系统搭好了,但数据系统永远不是静态的,上下文层也不应该是。上游的数据源和格式可能会变,人员可能有自定义指令想根据业务需求的变化来增删修改。数据 Agent 给出了错误的数据需要修正,修正内容当然也应该反馈回上下文层。这样,上下文层就变成了一个活的、持续演化的语料库

上下文层架构
从这整个过程里,可以看出来一件事:构建一个合格的数据 Agent 绝非易事技术层面有数据基础设施和工程的挑战,人力层面有部落知识收集的挑战,两种挑战搅在一起
OpenAI 团队最近发了一篇很好的文章,详细讲了他们自己内部数据 Agent 的创建过程。写得很透明,实现很细致也很优雅,但也说明了走到那一步需要多长的路。Palantir 在为组织构建本体论方面有很长的历史,能从混乱的数据里理出清晰的上下文,靠这个建了一门大生意
市场走向
上面说的这些,自然为外部方案打开了一扇窗。现实地说,不是每个企业都能(或应该)自己在内部建这套东西。各种方案已经开始进入市场了
我们认为还处在早期阶段,但以下是正在形成的方案的高层市场地图:
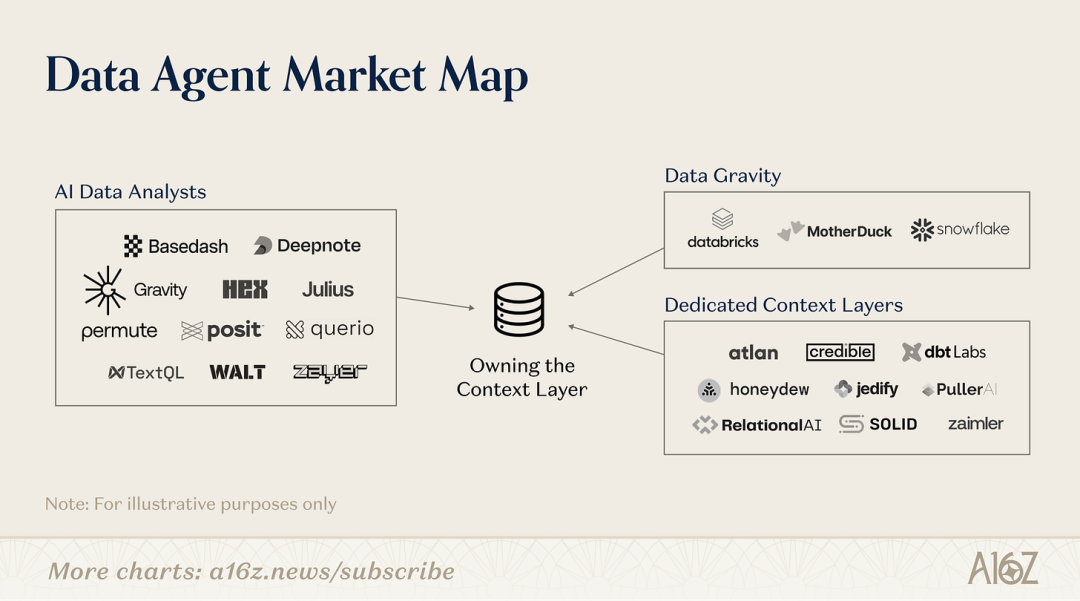
市场地图
分几类来看:
数据引力平台
Databricks 和 Snowflake 这样的平台,数据摄取、转换、存储的全流程都走过了,数据引力效应很强。它们已经在做 AI 数据分析产品,比如 Databricks Genie 和 Snowflake Cortex Analyst,建在数据仓库之上,用基础模型做 text-to-SQL,让用户可以用自然语言查数据。这些平台目前还没有特别成熟的上下文层功能,但支持轻量级的语义建模,通过收购或内部开发把上下文层引入平台,路是走得通的
现有的「AI 数据分析师公司」
已经涌现了一批公司,用 AI 让客户「跟数据聊天」。很多公司在市场上摸爬滚打之后明白了,做好数据 Agent 的关键其实在于构建上下文层。于是一些公司已经把数据上下文构建变成了产品的核心部分
新兴的、专门的上下文层公司
一个新品类出现了,从零开始建上下文层。它们要走完我们上面描述的整条路:摄取数据、收集部落知识,等等。而且每接一个新客户,就得重新走一遍
往前看
我们现在,正处在一个有意思的节点上。缺乏上下文这个问题已经被看清楚了,但构建解决方案的工作仍然处在非常早期的阶段
未来令人期待。也许真正自助式分析的愿景终于可以完全实现了。BI、数据分析和数据科学,可以被 AI 真正改变
当然,很多问题还是开放的。这个上下文层会住在哪里?它可以同时存在于多个地方吗?它会成为一个独立的产品吗?
本文是翻译稿,原文出自 a16z,地址:https://www.a16z.news/p/your-data-agents-need-context
本文由人人都是产品经理作者【赛博禅心】,微信公众号:【赛博禅心】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


