
 起点课堂会员权益
起点课堂会员权益身边小伙伴把Harness Engineering搭出来啦,半个小时上架一款web端产品
当工程师Ryan Lopopolo宣布5个月不写一行代码,完全依赖AI编程Agent完成项目时,整个行业都为之震动。他的团队在1500次代码提交中累积近百万行代码,人均产能不降反升。这背后隐藏着一个颠覆性的工作模式变革:Harness Engineering(马具工程)。本文将深入解析这套让AI自主运转的系统设计,揭示信息结构化如何成为新时代的核心竞争力,以及为什么产品经理的判断力正在被AI放大十倍。

一、一个让我坐不住的实验
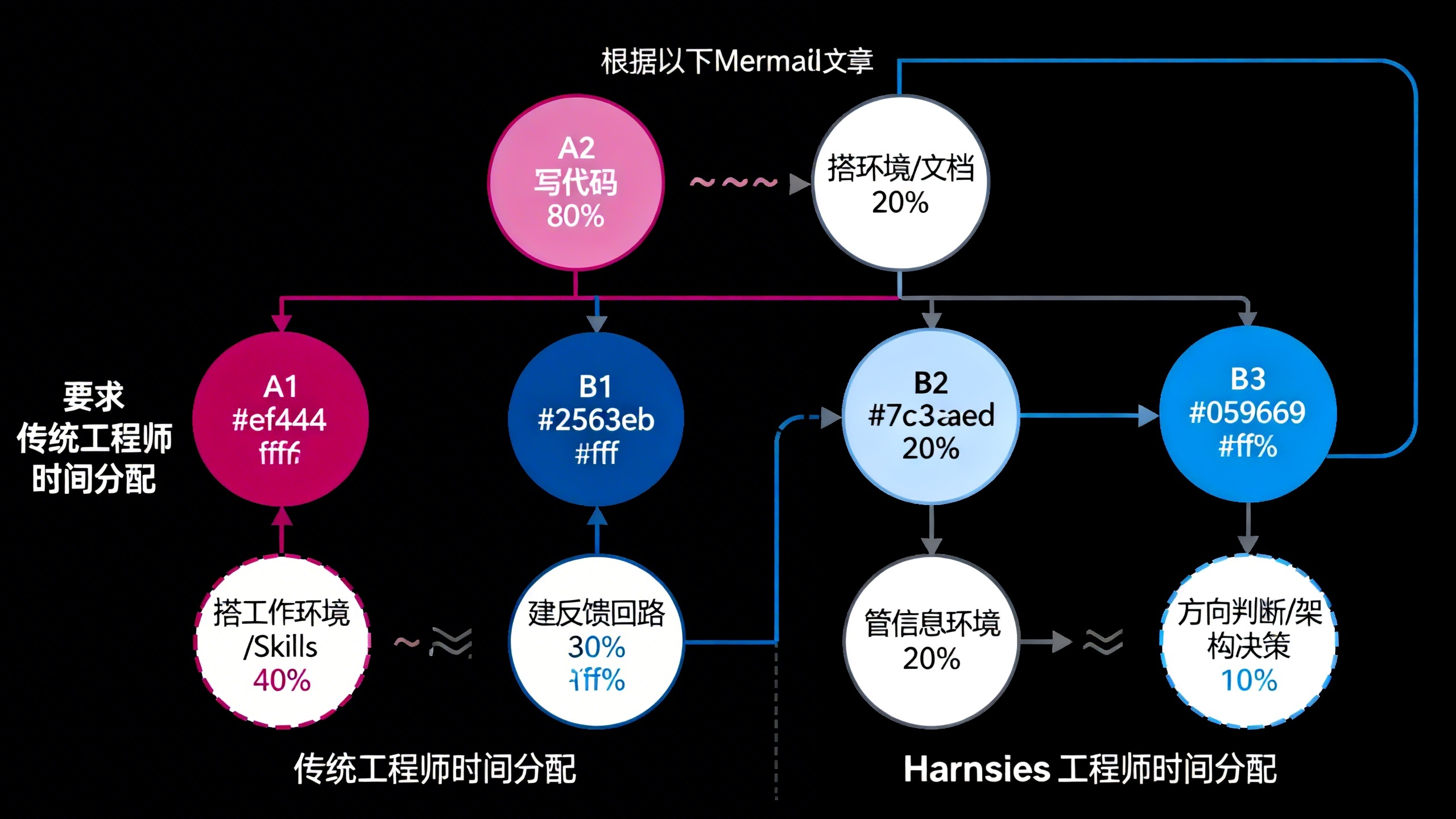
我身边的小伙伴,已经把harness架构搭出来啦,半个小时就能做上架一款web端,把架构图放在最后留个悬念吧!
前阵子看到OpenAI官方博客上一篇文章,看完之后在椅子上坐了好一会儿没动。
一个叫Ryan Lopopolo的工程师——之前在Snowflake、Stripe、Citadel都干过,履历挺硬的那种人——给自己立了一个规矩:5个月内不写任何代码。一行都不写。 所有代码全部交给Codex(OpenAI的AI编程Agent)。
结果怎么样呢?3个人的小团队起步,后来扩到7个人。5个月,大概1500个PR(代码提交请求),仓库里累计将近100万行代码。产品上线了,有真实的OpenAI内部日活用户,还有外部的Alpha测试者。东西能跑、能部署、能出bug、也能修好。用Ryan自己的话说,整个过程大概是手写代码所需时间的十分之一。
更反直觉的是:团队从3人扩到7人之后,人均产能不降反升——每人每天3.5到10个PR不等。加人不仅没拖慢速度,反而更快了。
我第一反应跟你们一样:那他每天干嘛?跟AI聊聊天?也太舒服了吧。
然后我把他的博客原文翻出来看了,又找到他后来在Latent Space做的一期播客。看完发现完全不是那回事——Ryan自己说,他的工作量比以前写代码的时候更大了。播客主持人也挺意外的,追问了好几次。
这才是这个故事里真正值得琢磨的地方——代码不用写了,人怎么反而更忙了?多出来的工作量花在了什么地方?
说个自己的事。之前我让AI帮我做一个页面的UI设计,来来回回改了十几轮,越改越不对味,最后出来的东西还不如我自己画的原型草稿。当时我觉得是AI做设计不行。看完Ryan的文章才反应过来——不是AI不行,是我没告诉它”好”长什么样。我脑子里有画面,但我给它的只是一句”做个简洁大气的界面”。它能拿到的信息就这么多,能做出什么呢?
二、他不写代码,那他在干什么——搭马具
Ryan给自己的新工作起了个名字:Harness Engineering。
Harness在英文里是马具的意思——缰绳、鞍子、笼头、嚼子,一整套东西。马的力量很大,跑得很快,但如果没有这些装备,它就是一匹在旷野里乱冲的野马。骑手通过马具来控制方向、分配力道、防止失控。
AI就是那匹马。Ryan做的事,就是给这匹马搭一套好用的马具。
他的时间具体花在三件事上。我先说最重的一件,后面两件简短点——但回头看其实第三件才是地基,只是当时没想到。
搭工作环境。
Ryan团队花了大量精力写skills文件。注意,这不是代码,是写给AI看的”工作说明书”——告诉AI怎么启动本地服务、怎么跑测试、怎么部署上线、怎么提PR、怎么处理合并冲突。他们甚至设计了一套完整的自动化流程,让AI能自己创建ticket、自己写PR描述、自己等CI跑完、自己修flake test、自己合并到主分支。
Ryan在博客原文里写了一个让我印象很深的数据:他们经常看到单个Codex agent连续跑6个小时处理一个任务——通常是在工程师睡觉的时候。
这不是偷懒。这是他把”怎么干活”的全部知识编码成了AI能读懂的文件,让AI可以在没人盯着的情况下自主运转。
他们还踩了一个大坑。一开始试过写一个巨大的AGENTS.md文件,把所有规则、规范、约定全塞进去。失败了。Ryan的原话是”给AI一张地图,不是一本一千页的手册”。原因很实在:上下文窗口是有限的,你塞一本百科全书进去,真正有用的任务信息反而被挤掉了。当所有东西都”重要”的时候,其实什么都不重要了。而且大文件腐烂得特别快,三天前写的规则可能今天就过期了。
所以他们的做法是:AGENTS.md只留大概100行,当一个入口目录用,指向仓库docs/目录里的详细文档。详细文档分层组织、交叉引用、版本化管理。AI从地图出发,根据当前任务按需深入——要改认证模块?先读地图找到路,再读docs/design-docs/auth.md拿细节。用不上的文档根本不加载。
建反馈回路——这件事的优先级排第二,但踩的坑最多。
AI一天能产出10个PR,人一天最多认真review 3个。传统的code review流程直接卡死了。而且不只是速度的问题——当AI的产出速度远超人的审核速度,积压起来的PR会互相冲突、互相依赖,越积越乱,到最后你review的那个版本可能已经不是最新的了。
他们的解决办法不是”review更快”,而是”不靠人review”。验证靠机械化手段——自定义linter(代码检查规则)、结构性测试、架构边界校验。这些检查工具本身也是AI写的。他们甚至把Chrome DevTools接进了Agent运行环境,让AI可以自己打开浏览器、操作UI、截图,验证自己写的东西到底对不对。不光能写代码,还能自己QA——这一步跨得挺大的。
一开始每周要花20%的时间清理”AI垃圾代码”——他们管这个叫AI slop。整个周五都在擦AI的屁股。后来发现这不可持续,于是把质量标准编码成规则,跑后台Agent自动扫描和修复。Ryan管这叫”垃圾回收”——不做新功能,只做清理,但没有这个环节,系统的信息质量会不可逆地腐烂。技术债就像高利贷——每天还一点没感觉,攒几个月你就还不起了。
走到最后他们做了一个很激进的决定:大部分PR合并前不做人工review了。Agent和Agent之间互相review代码,人只在合并后偶尔抽查。说实话我第一次看到这个的时候有点心惊——这也行?但仔细想想,如果你的linter、结构测试、架构校验、Agent review加起来已经覆盖了99%的常见问题,人再花时间逐行看代码,性价比确实低得离谱。
(写到这里我意识到,Ryan团队做的这些事听起来都是工程细节,好像跟产品经理没关系。但别急,后面第四第五节会解释为什么这些事恰恰是产品经理应该关心的。先看完他做了什么。)
管信息环境。 这件事我一开始觉得没什么好说的,看完才发现是根基。
他的原则非常简单:不在代码仓库里的东西,对AI来说等于不存在。
Slack里的讨论、Google Docs里的设计稿、会议上的口头约定——这些对人来说是”大家都知道的事”,对AI来说是完全不可见的黑暗物质。你跟一个不在群里的新人说”去看我们之前在Slack讨论的那个方案”,新人会懵。AI也一样。
所以他们把所有的设计决策、架构规范、团队共识,全部从Slack和Google Docs搬进仓库,变成版本化的markdown文件。仓库就是AI的全部世界观。仓库之外的一切,不存在。
这里插一句题外话。三周前Claude Code源码泄漏那事,社区扒出来的东西跟Ryan做的事情惊人地像。Anthropic搞了一套三层记忆系统——索引层常驻上下文、主题文档按需加载、原始对话只grep不全文灌进去——说白了就是在做同样一件事:管好AI的信息环境。Ryan从”怎么让AI干活”这个方向走到这一步,Anthropic从”怎么让AI产品好用”走到这一步。殊途同归。
三、一句话让我愣了很久
Ryan在Latent Space的播客里说了一句话,我反复听了两遍。
原话是这样的:
“I do feel like the models are there enough, the harnesses are there enough where they’re isomorphic to me in capability and the ability to do the job.”
isomorphic,同构。数学里的词,大意是”两个东西在结构上等价”。
Ryan说的不是”AI已经跟人一样强了”——这种话每个月都有人说,听麻了。他说的是一个带条件的判断:模型加上足够好的harness之后,能力边界跟他重合了。注意那个”the harnesses are there enough”——没有这个前提,后面的话不成立。
什么意思呢?就是harness的质量等于天花板。你搭的马具好,马跑得远。你搭的马具烂,马再猛也白搭。
我在这句话上卡了一会儿。后来想明白了它为什么让我不舒服——
AI不是来补短板的。它是一个放大器,而且不挑方向。
你架构审美好、对质量有清晰标准,它帮你高效产出高质量代码。你架构审美差、自己都说不清”好”长什么样,它就帮你批量制造精致的垃圾。好坏一起放大,公平得残忍。
我做AI产品的,看到这句话第一个想到的不是工程师,是产品经理。你对业务理解多深、对”什么叫做得好”定义多清晰,AI就能帮你做到多好。你脑子里糊的,AI产出就是糊的。没有例外。
以后这行拼的可能真不是谁更勤奋了。是谁脑子里的东西更值钱。
我自己有一个特别贴合的经历。之前帮朋友做一个二次元角色的定制手办,需要把一张角色图拆解成不同角度和姿势的参考图,给手工娘照着做。我把原图截图丢给AI,说”帮我拆成几个角度的参考”。出来的东西完全不能用——比例走形,细节丢失,关键配饰直接被吞了。
后来我换了一种方式:先自己把角色的核心特征一条条列出来——发型结构、配色方案、饰品位置、服装层次——然后告诉AI需要哪几个具体角度、每个角度重点展示什么。同一个AI,出来的东西可用度直接翻了几倍。手工娘说”这组参考图可以直接开工”。
前后两次用的是同一个模型。区别在哪?在我脑子里的东西有没有结构化地”倒”出来。第一次我给了一张图和一句话,AI在猜我要什么。第二次我把需求拆到了AI不可能误解的程度。Ryan说的”同构”就是这个意思——你清楚,它就清楚。
四、判断力的价格飙升了
上面那段我写完之后又想了想,觉得还没说到位。”脑子里的东西更值钱”听起来像鸡汤,得再往下推一步才落地。
Ryan的团队做了一个在传统软件工程里几乎不可想象的决定:大部分代码,合并前不做人工review,合并后也很少人去看。Agent和Agent之间互相review,人只管三件事——方向对不对?架构合不合理?用户体验说不说得通?
Ryan自己说:人类的时间和注意力是整个系统里唯一真正稀缺的资源。
这话没问题。但我觉得光说”注意力稀缺”还不够,这不是什么新鲜见解,随便一本时间管理的书都在讲。
真正让我觉得不一样的是后面半步——
以前,一个工程师做了一个架构决策,好或者坏,影响的是自己手下那几百行代码。范围有限,错了改就是了。
现在不一样了。Ryan做一个架构决策,这个决策通过harness传导给了10个AI agent。每个agent按照这个决策跑一周,产出几十个PR。如果决策是对的,一周之后仓库里多了几十个高质量模块。如果决策是错的,一周之后仓库里多了几十个方向跑偏的垃圾,而且这些垃圾之间还互相依赖,清理起来比从头写还麻烦。
同样一个判断,杠杆率完全不同了。
回头看上一节那个”同构”,它的残酷就在这儿——你的判断力不仅决定了AI的上限,还通过harness被放大到了整个系统。判断好,系统级的好。判断差,系统级的灾难。以前犯错的代价是浪费自己一周时间。现在犯错的代价是浪费十个Agent一周的算力和产出,外加清理它们互相缠绕的垃圾代码。
你说这事该叫”机遇”还是”压力”?我觉得看你站哪边。
所以”AI会不会取代产品经理”这个问题,我现在觉得问法就不太对。不是取代不取代的事,是你做的每个判断都被放大了十倍。对了十倍收益,错了十倍浪费。
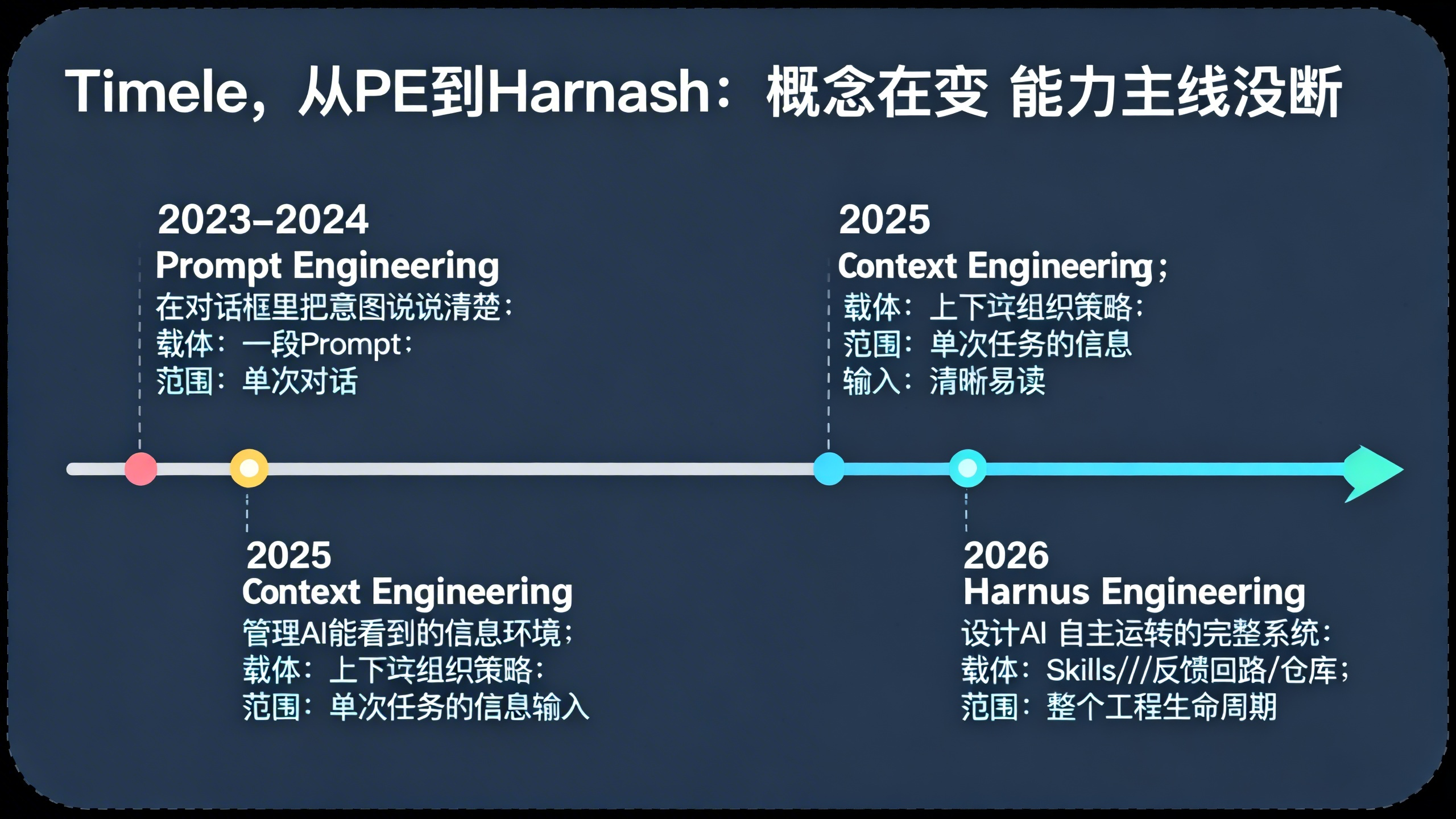
五、概念在演进,核心没断
过去两年行业造了三个词:Prompt Engineering → Context Engineering → Harness Engineering。
每个新词出来都有一波”旧时代终结”的宣言,PPT越做越漂亮。
但你仔细看Ryan做的事——写skills文件教AI用工具、把设计文档结构化让AI读得懂、把质量标准编码成机器可以跑的规则——再回头看PE时代大家在干什么,底层有一条线一直没断过:把自己的意图变成AI能理解的结构。
当然”没断”不等于”没变”。变化是真实的。
PE时代你的工作范围是一个聊天框。CE时代你开始操心”给AI看什么信息、什么顺序、什么时候给”。到了HE,你管的东西扩展到了整个工程系统——配置文件、skills文件、架构约束、自动化测试、反馈回路、仓库里的全部知识资产。从对话框管到了整个系统,这个变化不是PPT上的概念游戏,是工作重心的真实迁移。
但核心动作没变。绕了一大圈,最值钱的能力还是:你能把一件事说清楚——说到AI不会误解的程度。 只不过”说清楚”的载体从一段对话变成了一个系统。
产品经理本来就是干这个的。以前你把事情说清楚给工程师执行,现在给AI执行。受众换了,但”把脑子里的东西变成别人能执行的东西”这个事,一直是PM吃饭的家伙。这么看的话,这个岗位在AI时代可能没有大家想得那么被动——前提是你真的能说清楚。
六、看完想动手的话
说几个我觉得门槛最低、但回报明显的事。
第一步:花30分钟给你的AI工具写个“说明书”。
不管你用Claude Code、Cursor还是别的,写一个CLAUDE.md或者AGENTS.md放到项目里。内容不复杂——你的项目是干什么的、核心模块有哪些、团队有什么规范和禁区、常用命令是什么。100行以内,当目录用就行。
写完之后你大概率会有一个”卧槽”的瞬间——同一个AI,回答质量明显不一样了。不是它变聪明了,是它终于看见地图了。之前在黑暗里乱撞,现在知道北在哪了。
第二步:把一条“口头共识”写成文件。
你脑子里肯定有一些东西是”大家都知道但从来没写下来”的——”我们不用这个库””这个接口别碰””新功能先写测试”。挑最重要的一条,花10分钟写成markdown扔进仓库。就一条就行。Ryan的团队说,一条从Slack救回来的架构决策,能让AI一整周不偏航。10分钟换一周,够划算了。
第三步:搞一个最简单的“自动检查”。
这一步说实话对不写代码的PM来说有门槛。但道理不复杂:AI做完事之后,别全靠自己手动检查,搞一个自动的东西帮你看一眼。跑个测试也行,让另一个AI扫一遍也行。哪怕只是”让AI跑完linter再给你看结果”,也算迈出去了。从0到1永远是最难的,但也是杠杆最大的。
写在最后
Ryan的实验回答了一个很多人在焦虑的问题:AI什么都能做的时候,人的价值是什么?
他的答案挺朴素的——不是执行能力,是判断力。知道该做什么、知道做得对不对、知道什么时候该叫停。
但他自己也说了:他还在学习,不知道这个系统随着模型进步会怎么演化。
这句话让我想到一个问题。Ryan说”模型加上harness跟自己同构”——但模型还在进步啊。如果有一天模型不需要你搭的harness就能自己跑呢?如果”同构”的那个对象,从”你+harness”变成了”模型本身”呢?
到那时候,人的判断力还够用吗?
暂时,够用。
但Ryan自己在播客最后说了一句话,大意是:他最想把时间花在的地方,是那些”纯粹的白色空间”——全新的问题、没有现成答案的架构决策、需要从零定义的产品方向。这些东西现在只有人能做。至于”已知怎么做”的那些事,模型加harness已经能接住了。
问题在于,”已知”和”未知”的边界线不是固定的。模型每升级一代,”已知”的领地就扩大一圈。今天需要Ryan亲自判断的事,明天可能就变成harness里的一条自动规则了。后天呢?后天那条规则可能连写都不用人写,模型自己总结出来了。
但我已经见过身边的人,把harness架构搭出来啦,半个小时就能做出来
文中Ryan Lopopolo的实验细节来自OpenAI官方博客”Harness engineering: leveraging Codex in an agent-first world”及Latent Space播客采访,不涉及代码展示。
本文由 @苏苏的AI笔记 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









同为医疗人,北京欢迎你~