
 起点课堂会员权益
起点课堂会员权益【万字】拆完 Claude Code 51万行源码后,我才明白什么叫 Harness
当AI Coding成为标配,Claude Code的51万行源码揭示了Agent落地的核心真相。文章深度拆解了一条消息从终端输入到模型回复的完整链路,不仅展示了Prompt Cache的极致成本控制、流式工具调度的并发逻辑,更诠释了何为真正的Harness架构。本文将带你透过代码表象,看清长链路执行、多层权限、记忆沉淀与上下文压缩等工程化设计,是如何将大模型从‘聊天玩具’转化为‘生产力工具’的。
引言:Claude Code 源码这种事没办法不万字,本文阅读约 15 分钟,非常简单!
然后,文章基于 Claude Code 源码(TypeScript / Bun 运行时,约 1900 个源文件,51w+ 行代码)进行解读,尝试从一个具体场景出发,追踪一条消息从用户输入到模型回复的完整生命周期
Claude Code 源码暴露已经有些日子了,网上已经有不少解读了,我也也在很多认真的阅读(说实话,不借助 AI 还是有些吃力的…),但一直不知道该如何将这个事情聊清楚,最后决定还是从一次场景出发,也许能串起来!
打开终端,输入 claude,REPL 启动了,你粘贴了一张截图,某个报错页面的截屏——然后敲了一句:这个报错是什么意思?帮我修一下
几秒钟后,终端里开始出现回复。它先认出了图片里的错误信息,然后告诉你它想去看某个文件,再然后它直接把文件改了,最后给你一个总结。
你大概知道背后在调用大模型,但这中间到底发生了什么?模型怎么知道该去看哪个文件?它凭什么能直接改你的代码?改之前有没有什么安全机制?如果你聊了很久、对话已经很长了,它怎么处理?
这篇文章就是回答这些问题的,我会带着你,从你按下回车的那一刻开始,一步步跟完整条处理链路:
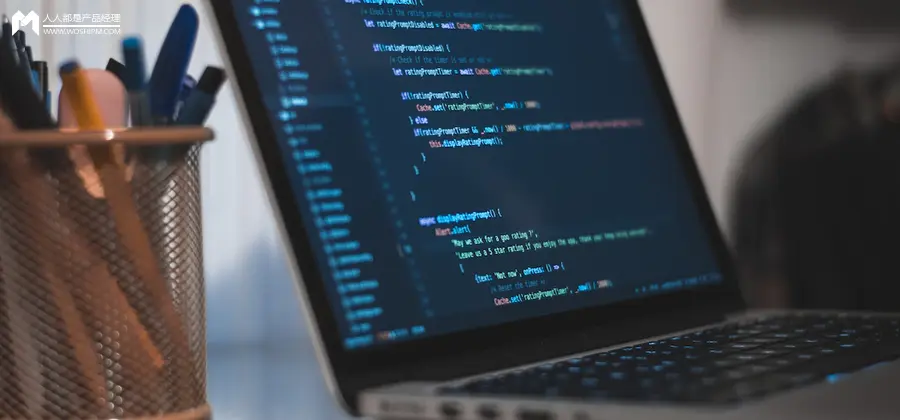
全链路总览:从按下回车到收到回复,消息依次穿过 UI 层、编排层、核心层、服务层
01 按下回车之后发生了什么
你在终端里看到的交互界面,底层是一个 React 应用(前端框架,不是 Agent 的 ReAct 框架,类似的是 Vue 框架),用 Ink 框架渲染在终端里。
整个界面最核心的组件叫 REPL.tsx,这个文件有 5000 多行,算是 Claude Code 里最大的单文件之一了。
你按下回车的那一刻,触发的是 onSubmit 回调,它做几件事:
先看看是不是即时命令,像 /clear 这种带有 immediate 标记的斜杠命令,根本不经过模型,直接执行(清屏就是清屏,不需要大模型参与)。
然后处理一些边缘情况:如果你之前中断过对话,它会尝试恢复上下文。接着把你的输入加入历史记录,清空输入框,开始显示等待动画。
最后调用 handlePromptSubmit(),一路走到 onQuery(),到这里为止,你的输入还只是一段原始文本。接下来,它要被加工成一条正式的消息。
截图是怎么处理的
我们的场景里还有一张截图,图片的处理是另一条独立的管线,入口在 src/utils/imagePaste.ts。
从剪贴板拿到图片,在 macOS 上会优先走原生 NSPasteboard API,这是亚毫秒级的操作,通过 image-processor-napi 模块直接拿到 PNG 字节。
如果原生方式失败,会降级到用 osascript 调系统剪贴板:先把图片存成临时文件,再读字节,遇到 BMP 格式还得转成 PNG。
拿到图片只是第一步,API 对图片有尺寸和大小的限制,所以必须压缩。
压缩的策略是一套多级降级方案:尺寸和大小都合规就直接用;文件大了但尺寸没问题,就依次试 PNG 调色板压缩…
尺寸超了就先等比缩放;缩放后还是太大,就 PNG 压缩再走 JPEG 各级质量,最后还有一手极端压缩。
总之,一定要把它压到 API 能接受的程度。处理完的图片被转成 base64,封装成 API 要求的格式:{ “type”: “image”, “source”: { “type”: “base64”, “media_type”: “image/png”, “data”: “<base64 编码数据>” }}
到这一步,你的文本和图片一起被组装成了一条 UserMessage,准备好进入下一段旅程了。
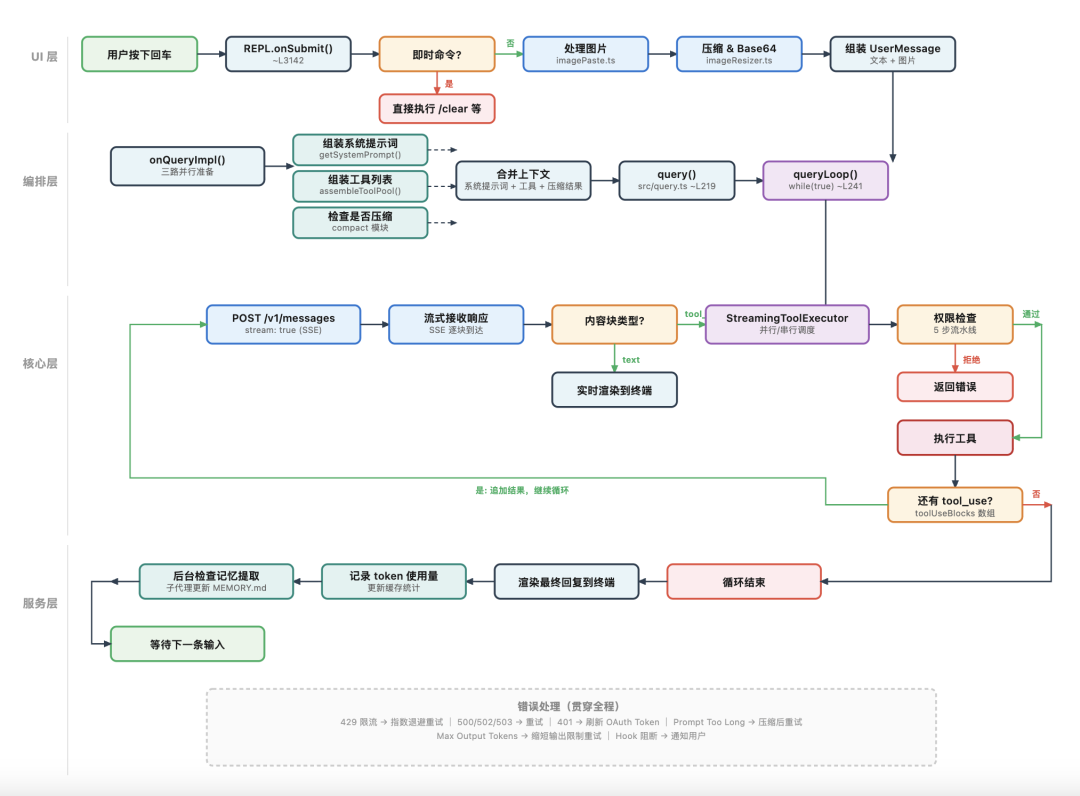
用户输入处理流程:onSubmit 决策 + 图片处理管线(剪贴板 → 多级压缩 → base64)+ 消息组装
02 系统提示词
你的消息要发给模型,但它还不能直接发,在那之前,需要组装系统提示词。
系统提示词是 Claude Code 里最核心的设计之一,它不是一段固定文本,而是由多个模块动态拼出来的,而且拼接的方式经过了精心设计,目的是让 Anthropic API 的 Prompt Caching 尽可能命中。
无论什么 Agent 系统,在换成信息命中这块都是极大的难点!
Claude Code 这里也是如此,后面大家会看到,因为这里的设计,直接决定了成本,命中的时候能省大约 90%。
源码入口是 src/constants/prompts.ts,核心函数叫 getSystemPrompt()。
系统提示词的内容并非全部写在这个文件里,静态段落(身份、指令、编程哲学等)是独立的函数,动态段落通过一个 systemPromptSection 注册表来加载,包括环境信息、记忆、MCP 指令、输出风格等。
哪些内容是”基本不变”的
有一些内容在每次对话里几乎不会变,会被标记上 cache_control: ephemeral。这些是缓存的主要受益者:
- 身份和角色:“你是一个交互式代理,帮助用户完成软件工程任务”
- 系统指令:Markdown 渲染规则、工具权限模式说明、注入攻击防御
- 编码哲学:不要过度工程、不要提前抽象、三行相似代码好过一个过早抽象
- 工具使用指南:优先用 Read 不用 cat、优先用 Edit 不用 sed、优先用 Glob 不用 find
- 语气风格:简洁直接、不用 emoji、一句能说清的别用三句
这些内容加起来不算少,但因为每次都一样,API 会在服务端缓存住,后续每次调用只要缓存没过期,直接省掉 90% 的成本。
哪些内容是每轮刷新的
另一些内容每轮查询都会重新计算:
- 环境信息:当前目录、git 分支、最近几条提交、平台信息、模型知识截止日期
- 用户上下文:CLAUDE.md 的内容、MEMORY.md 的持久记忆
- MCP 指令:已连接的 MCP 服务器提供的工具描述
- 技能列表:当前可用的斜杠命令
- Hook 指令:用户配置的钩子说明
- 输出风格:基于用户配置的格式偏好
怎么拼的,为什么工具列表要按字母排
组装的时候,先把那些需要 IO 的部分并行加载(技能列表、输出风格配置、环境信息),再把静态段落和动态段落拼接起来。
这里有个容易忽略但很有意思的细节:工具列表是按字母顺序排列的,这不是随意的,是为了保持 prompt cache 的稳定性。
如果每次工具的顺序不一样,缓存就会失效,之前花在缓存上的投入就白费了。
Claude Code 几乎每次 API 调用都会带上完整的工具列表,所以缓存命中率直接决定了成本,按字母排看似是个小决定,实际上影响很大。
环境信息
环境信息的注入值得单独说一下,因为它直接回答了”模型怎么知道去哪找文件”这个问题。
每轮查询时,系统会把这些东西嵌入到系统提示词里:当前工作目录的绝对路径、当前 git 分支名和最近几条提交、操作系统和 shell 类型、模型的知识截止日期。
这些东西构成了模型理解当前项目环境的”眼睛/窗口”。当你说帮我修 bug的时候,模型看到的不仅仅是这句话。
它还看到了你在一个 TypeScript 项目里,当前在 feature/auth 分支,最近的提交是 fix login validation,它据此推断该从哪些文件开始找。
这和 IDE 里的 Copilot 不一样,Copilot 有整个项目文件树的索引。
Claude Code 的做法是把关键的环境信息浓缩进提示词,然后让模型自己用工具去探索,好处是不需要维护索引,代价是模型可能需要多调用几次工具才能找到正确的文件。
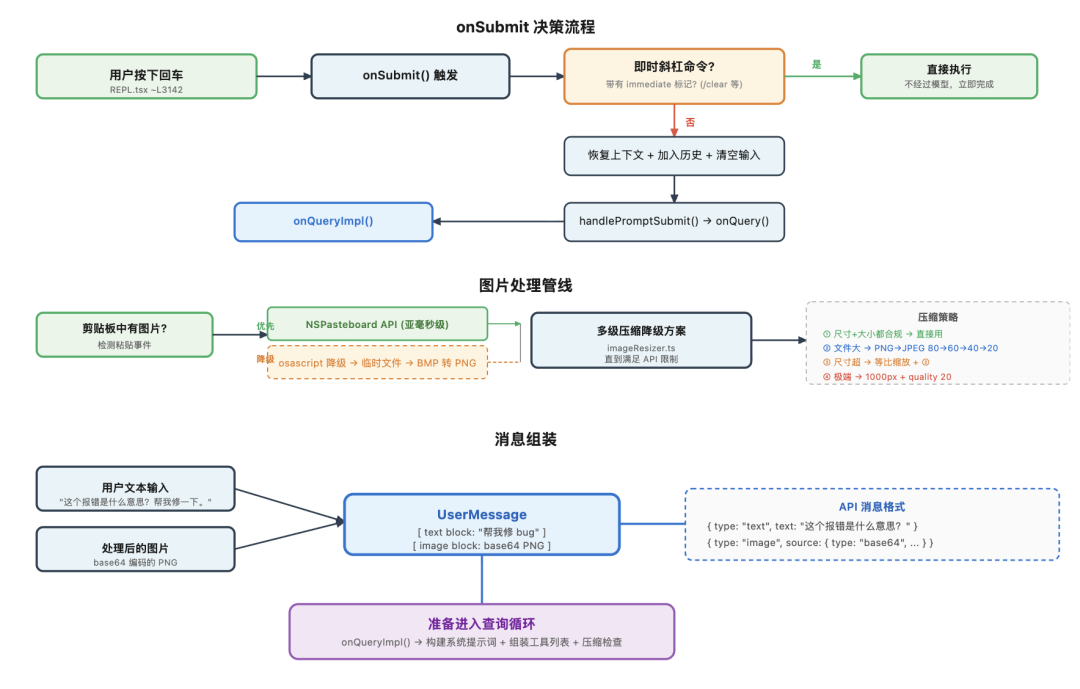
系统提示词组装流程:静态段落(缓存友好)+ 动态段落(每轮刷新)+ 工具列表(按字母排序),三路并行组装
特别注意:工具和技能
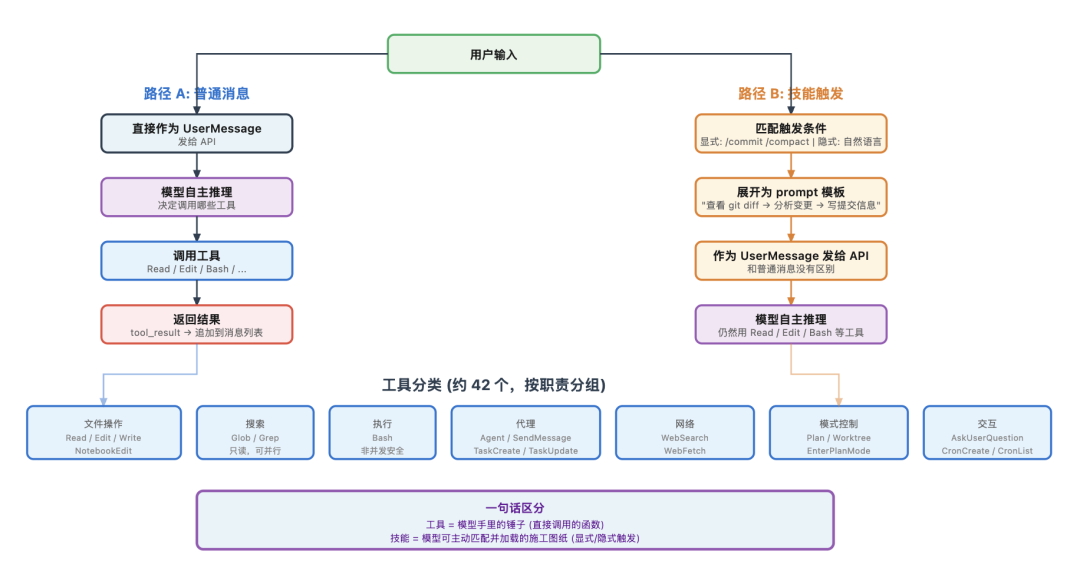
在继续追踪消息之前,需要先把两个容易混淆的概念说清楚。
工具(Tool) 是模型可以直接调用的函数。
Read 读文件、Edit 改文件、Bash 执行命令,这些都是工具。
它们在 API 请求里以 tools 参数发出去,模型在回复里通过 tool_use 类型的内容块来表达”我想调用 Read 工具读某个文件”。
Claude Code 的运行时收到这个意图后执行对应函数,把结果通过 tool_result 返回给模型。
技能(Skill) 是一种能力增强模块,每个技能都声明了自己的触发条件。触发方式有两种:
一是用户显式输入斜杠命令,比如 /commit、/compact。
二是模型收到用户的自然语言请求后,判断是否匹配某个技能的触发条件,自动调用;
比如用户说”帮我提交代码”,模型会自动匹配并调用 commit 技能,用户根本不需要知道斜杠命令的存在。而且这是强制性的:模型在回应用户之前必须先检查是否有匹配的技能,匹配到了就必须优先调用。
技能的本质是一段预设的 prompt 模板,被触发后,Claude Code 把它展开成一条详细指令。
比如 commit 技能展开后变成”查看 git diff,分析变更,写规范的提交信息”。模型收到这段展开后的指令,和收到一条普通用户消息没有区别,它还是通过 Read、Bash、Edit 这些工具来完成任务。
一句话区分:工具是 Tools,技能是模型可以主动匹配并加载的提示词模板,技能(Skills)不能发明新工具,但他可以组合调用 Tools。
工具与技能的两条路径对比:普通消息直接进 API,技能触发后先展开 prompt 模板再进 API,最终都通过同样的工具来完成任务
工具,不是每次都全部加载
Claude Code 有数十个内置工具,具体数量取决于 feature flags 和环境配置,src/tools/ 下有约 42 个工具子目录,按职责分成几类:- 文件操作:Read / Edit / Write / NotebookEdit- 搜索:Glob / Grep- 执行:Bash- 代理:AgentTool / TeamCreate / SendMessage- 任务:TaskCreate / TaskUpdate / TaskGet / TaskList / TaskOutput / TaskStop- 网络:WebFetch / WebSearch- 模式:EnterPlanMode / ExitPlanMode / EnterWorktree / ExitWorktree- 调度:CronCreate / CronDelete / CronList- 交互:AskUserQuestion- 集成:Skill / ToolSearch / LSP / MCP
但它们不是一股脑全部加载的。组装流程有三步过滤:
第一,getAllBaseTools() 收集所有内置工具,但会根据特性门控(Feature Flag)过滤——比如 CronCreate 需要 AGENT_TRIGGERS 特性开启才会被包含。
第二,getTools() 进一步过滤,移除被用户禁用的工具和当前模式不允许的工具。
第三,assembleToolPool() 把内置工具和 MCP 外部工具合并,按字母排序(又看到了吧,为了缓存),去重(内置工具优先)。
最终的工具列表作为 API 请求的 tools 参数发送,每个工具都要实现一个统一的接口,包括参数校验(用 Zod 定义)、执行逻辑、权限检查、以及两个关键标记:isConcurrencySafe(是否可以并行执行)和 isReadOnly(是否只读)。
Read、Grep、Glob 都是只读的,可以并行,Edit、Write、Bash 会改变文件系统,必须串行。这个标记直接决定了工具的调度策略(后面你会看到它是怎么起作用的)。
这里很多工具受特性门控管理。构建的时候,Bun 会做 Dead Code Elimination,没启用的工具代码直接从二进制文件里移除,不会多占一个字节。
03 查询循环
你的消息和系统提示词都准备好了,现在进入整条链路的核心:查询循环。
流程是这样的:你的消息先经过 onQueryImpl(),这个函数并行做三件事:构建系统提示词、组装工具列表、检查是否需要压缩。
然后把用户上下文和系统上下文合并,调用 query() 函数,进入 queryLoop()。
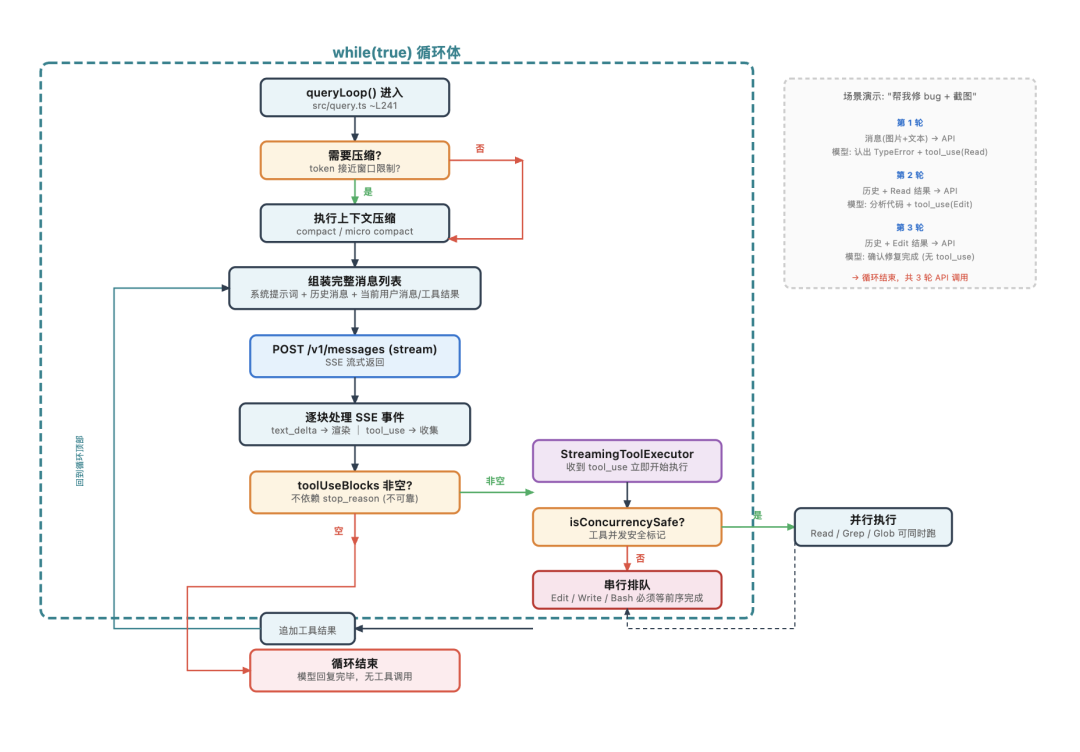
queryLoop() 在 src/query.ts中,是一个 while(true) 循环,每一轮迭代做的事情是这样的:
先把消息准备好。 检查对话是不是太长需要压缩(这个后面会详细讲),然后组装完整的消息列表:系统提示词 + 历史消息 + 当前的用户消息或工具结果。
然后调 API,流式。 向 Anthropic API 发 POST /v1/messages,带上 stream: true。API 通过 SSE(Server-Sent Events)逐块返回内容。
边收边处理。 文本内容实时渲染到终端。如果出现了 tool_use 类型的内容块,交给 StreamingToolExecutor 处理(这个组件值得单独说,稍后展开)。
执行工具。 StreamingToolExecutor 根据每个工具的 isConcurrencySafe 标记来决定怎么调度——能并行的立即启动,必须串行的排队等前面的完成。
具体来说,它用的是一种基于队列的调度:每收到一个 tool_use 块就检查当前是否有工具在运行,如果都在空闲或者当前运行的都是可并行工具且新工具也可并行,就立即启动执行;否则排队。
完成任何一个工具后重新处理队列。每个工具执行前都要过权限检查。
判断要不要继续。 这里的机制可能和你想的不一样:代码并不依赖响应里的 stop_reason 字段(源码注释明确写了”stop_reason is unreliable”)。
实际做法是在流式接收过程中维护一个 toolUseBlocks 数组,每出现一个 tool_use 内容块就记下来。如果这个数组不为空,说明模型还想继续用工具,那就把工具执行结果追加到消息列表,回到循环开头,开始下一轮。
如果数组为空,说明模型说完了,循环结束。
查询循环流程:while(true) 循环,每轮经历压缩检查 → 组装消息 → 调 API → 处理响应 → 执行工具 → 判断是否继续
用场景走一遍
空说流程有点抽象,我们用”帮我修 bug + 截图”这个场景实地走一遍。
第一轮循环: 你的消息(图片 + 文本)和系统提示词一起发给 API,模型看了图片,认出了 TypeError: Cannot read properties of null,然后说”让我查看 src/utils/handler.ts”,附带了 tool_use(要求 Read 这个文件)。因为检测到了 tool_use 内容块,循环不会结束。
第二轮循环: 上一轮的 assistant 回复和 Read 工具返回的文件内容一起追加到消息列表,再次发给 API。模型看到文件内容,分析出问题所在,返回新的 tool_use(要求 Edit 修改文件),循环继续。
第三轮循环: Edit 的执行结果追加进去,再发 API。模型确认修复完成,没有新的 tool_use 请求,循环结束。
循环结束,你在终端里看到了完整的修复过程和最终结论。
从你按下回车到看到结果,经历了三轮 API 调用、两次工具执行,如果问题更复杂,可能是十轮二十轮,但每一轮做的事情,本质上都是一样的。
StreamingToolExecutor
模型可能在一个回复里同时请求多个工具,比如它可能同时要 Read 一个文件、Grep 搜索一个模式、Edit 另一个文件,如果等所有 tool_use 块都收齐了再执行,就会白白浪费时间。
StreamingToolExecutor 的做法是:收到一个 tool_use 就开始执行。
Read 和 Grep 都标记了 isConcurrencySafe = true,所以它们可以同时跑。
Edit 标记了 isConcurrencySafe = false,因为要改文件,必须等前面的都完成后再执行。
实际调度机制不是简单的 Promise.all(),而是一个队列系统——每个工具完成后会重新触发队列处理(promise.finally(() => processQueue())),等待结果时用 Promise.race 逐个等。
如果并行执行的工具中有一个失败了,其他并行的兄弟工具都会被取消,这是为了防止部分失败导致不一致的状态:
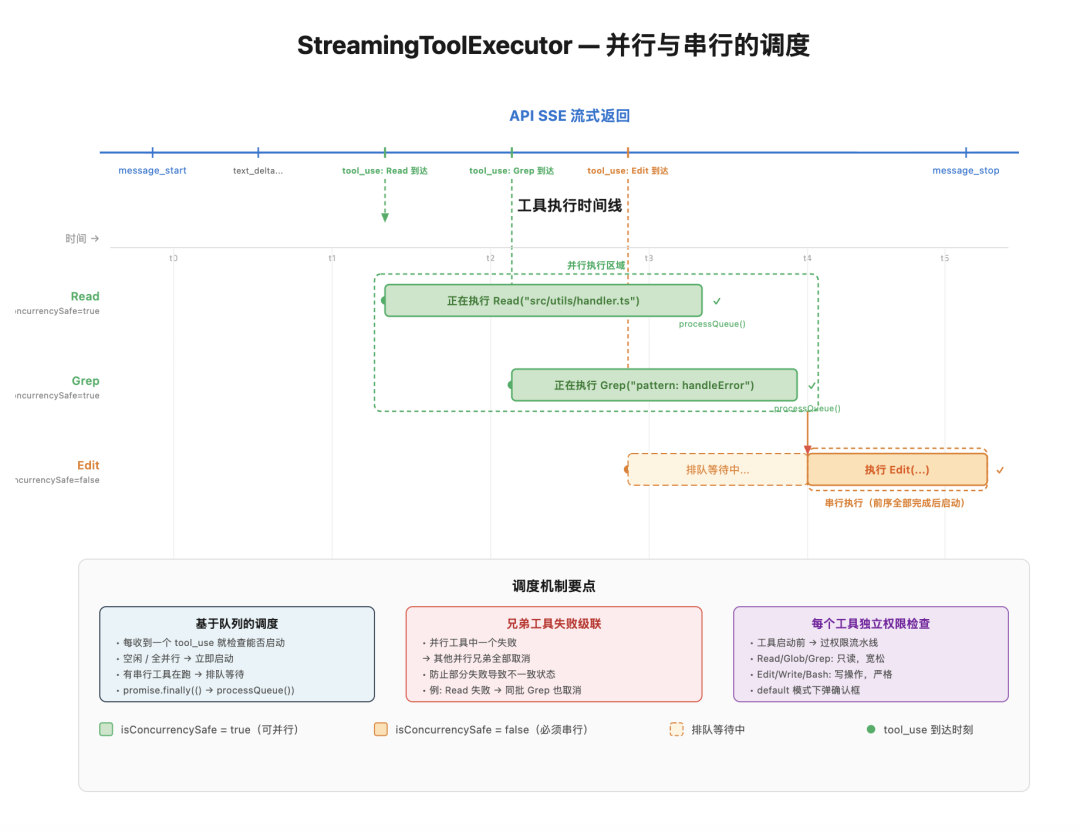
StreamingToolExecutor 时间线:收到 tool_use 立即执行,Read/Grep 并行,Edit 排队等待前序完成后再串行执行。
04 权限系统
上面的流程里,模型要 Edit 一个文件,但不是说了就改,在工具真正执行之前,有一套多层的权限检查。
权限模式:从严到宽
Claude Code 有多种权限模式,从严格到宽松依次是:plan → default → acceptEdits → auto → dontAsk → bypassPermissions
1.普通用户最常用的是 default,对危险操作会弹确认框。
2.auto 模式下会用一个分类器来自动判断操作是否安全(这个模式需要 TRANSCRIPT_CLASSIFIER feature flag 开启)。
3.plan 模式下所有写操作直接拒绝——你只能在计划阶段,不能动文件。
检查流水线
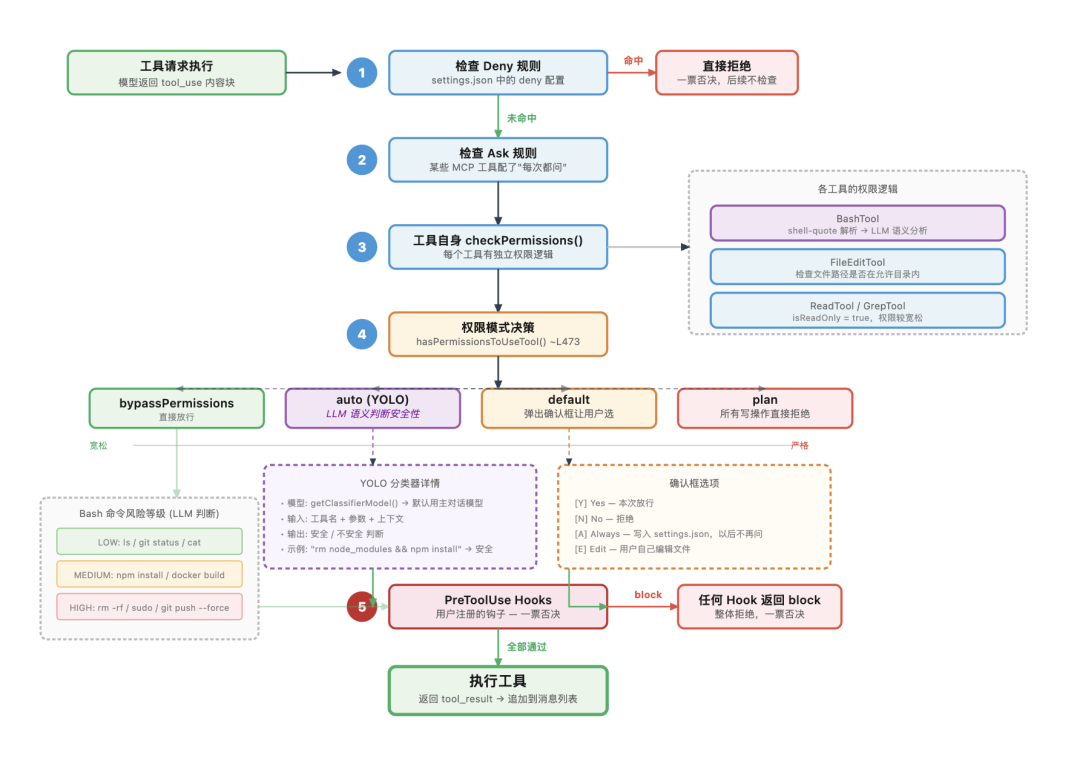
当工具要执行时,过的是这样一条流水线:
第一步,看有没有被你明确禁止。 你可以在 settings.json 里写 deny 规则,禁止某些工具或某些操作。如果命中了,直接拒绝,后面什么都不看了。
第二步,看有没有被你标记为需要询问。 某些 MCP 工具可能配了”每次都问我”。
第三步,工具自己的权限逻辑。 每个工具有自己的 checkPermissions() 方法。BashTool 会解析命令的结构来判断风险等级,底层用 shell-quote 库做命令解析,再结合 LLM 做语义分析,FileEditTool 会检查文件路径是否在允许的工作目录范围内。
第四步,根据权限模式做决策。bypassPermissions 模式下前三步没拒绝就放行,auto 模式下会调用一个叫 YOLO 分类器的东西(用 LLM 做语义判断,模型默认和主对话用的是同一个)。default 模式下弹出确认框让你选。
第五步,Hook 系统。 即便前面都过了,还有一关:用户注册的 PreToolUse 钩子。任何一个钩子返回 block,整体拒绝,一票否决。
权限检查流水线:五步检查依次执行——否决规则 → 询问规则 → 工具自身权限 → 模式决策 → Hook 一票否决
Bash 命令的风险是怎么判断的
Bash 的风险评估比较有意思,实际的命令解析在 src/utils/bash/commands.ts,用 shell-quote 库把命令拆解成结构化 token(处理管道、重定向、命令替换等),再结合 LLM 提取命令前缀做语义分析。
风险等级(LOW/MEDIUM/HIGH)不是硬编码的规则表,而是由 LLM 实时判断的:`ls`、`git status` 会被判定为低风险,`npm install`、`docker build` 是中等风险,`rm -rf`、`sudo`、`git push –force` 是高风险。
这些都是模型根据语义推断出来的,不是写死的映射。
auto 模式下的 YOLO 分类器(src/utils/permissions/yoloClassifier.ts)也会调 LLM 来做语义判断。
它用的模型不固定为某个特定的小模型,而是通过 getClassifierModel() 解析,默认回退到当前会话的主循环模型(getMainLoopModel())。
这比静态规则灵活不少——比如它能理解”删除 node_modules 再重装”虽然包含 rm 命令,但其实是合理的操作。
你在终端里看到的确认框
在 default 模式下,遇到需要确认的操作,终端会弹出这么一个东西:┌─────────────────────────────────────────┐│ Claude wants to edit src/main.ts ││ ││ Allow? [Y] Yes [N] No ││ [A] Always allow for this tool ││ [E] Edit the file myself │└─────────────────────────────────────────┘
选 Yes 这次放行。选 “Always allow” 会把规则写进 settings.json,以后同类型的操作不再询问。
05 记忆系统
聊到这里,你可能有个疑问:如果我对模型说了”以后用 bun 不要用 npm”,下一个会话它还记得吗?如果昨天聊了一半的对话,今天接着聊,上下文还在吗?
Claude Code 的记忆机制有四层,分别解决不同的问题,但在讲每一层之前,先搞清楚一个前提:这些记忆是什么时候加载的,加载了什么?
记忆的加载分两条并行的管线,各管各的:
第一条管线负责读取记忆文件的实际内容
它在一个叫 getUserContext() 的函数里运行,调用 getMemoryFiles() 去发现和读取文件,然后用 getClaudeMds() 把内容格式化成文本,注入到每轮对话的用户上下文里。
第二条管线不注入文件内容,而是注入行为指令
告诉模型”你有一本笔记可以写,规则是这样的,什么时候该更新”。模型知道自己有记忆能力,但具体的笔记内容是从第一条管线看到的。
两条管线并行运行,一起组装成完整的上下文。
第一层:CLAUDE.md
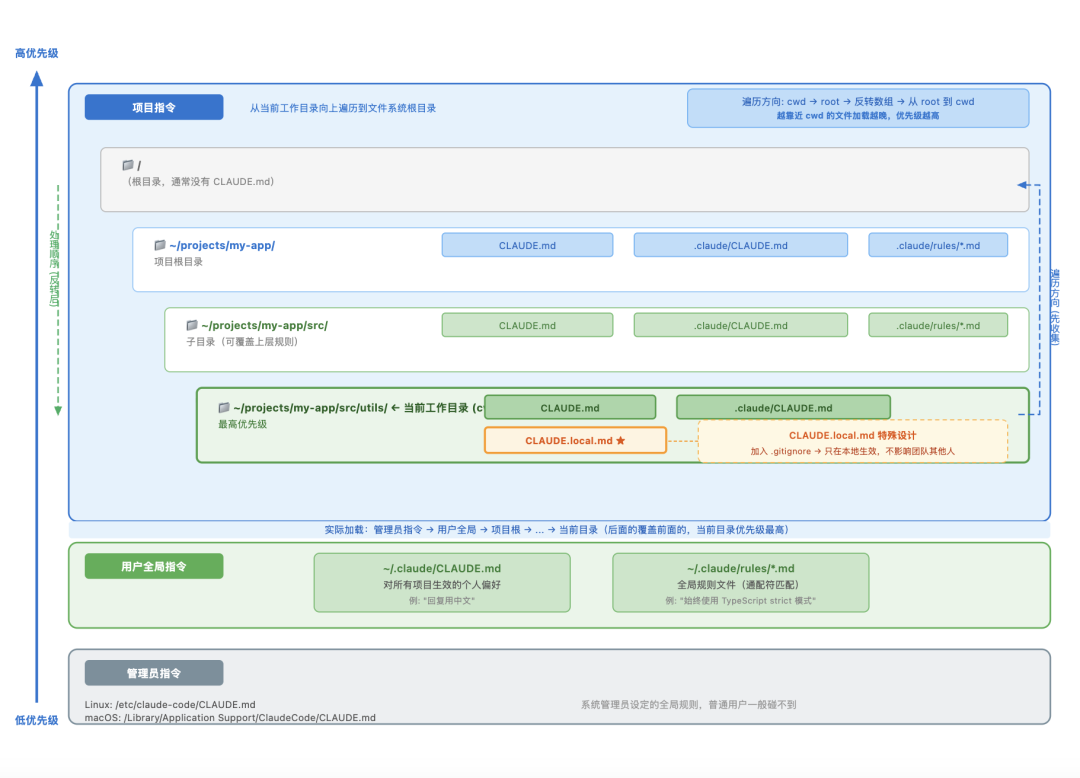
第一条管线具体加载哪些文件?按优先级从低到高:
管理员指令。 路径是 /etc/claude-code/CLAUDE.md(Linux)或 /Library/Application Support/ClaudeCode/CLAUDE.md(macOS)。系统管理员为所有用户设定的全局规则,普通用户一般碰不到。
用户全局指令。~/.claude/CLAUDE.md 和 ~/.claude/rules/*.md。你自己写的、对所有项目生效的偏好,比如”回复用中文”。
项目指令。 这是最常用的。从你的当前工作目录开始,向上遍历到文件系统根目录,收集沿途每一级目录下的 CLAUDE.md、.claude/CLAUDE.md、.claude/rules/*.md、CLAUDE.local.md。
遍历方向有个讲究:代码先把从当前目录到根的所有路径收集到一个数组里,然后反转数组,从根开始处理到当前目录。
这意味着越靠近你当前位置的文件,加载顺序越靠后,优先级越高。你可以在项目根目录写通用规则,在某个子目录写覆盖规则。
这里面有个巧妙的设计是 CLAUDE.local.md,它和 CLAUDE.md 放在同一个目录,但你把它加进 .gitignore,只在自己本地生效。适合放”我喜欢用 bun 而不是 npm”这种个人偏好,不影响团队其他人。
这是最简单的记忆形式:你写什么,模型就看到什么。本质上就是一堆 Markdown 文件被读取后拼进了上下文。
CLAUDE.md 文件发现与优先级:管理员指令 → 用户全局 → 项目指令(从根到 cwd 遍历),越靠近当前位置优先级越高
第二层:MEMORY.md
CLAUDE.md 需要你手动写,MEMORY.md 不需要。
它存放在 ~/.claude/projects/<项目路径>/memory/ 下面,由模型在对话过程中自动维护。
更新的方式是这样的:系统会在后台启动一个子代理(Forked Agent)。
这个子代理继承了父对话的 prompt cache。所以 API 成本很低,但只能执行文件编辑操作,而且只能编辑记忆文件。
它会读取当前的记忆内容,分析最近的对话,然后决定新增、修改或删除哪些条目。
触发条件是几个指标的组合判断:累计 token 数超过 10000、距上次提取新增 token 超过 5000、距上次提取的工具调用超过 3 次、最近一轮没有工具调用(说明对话进入了”总结”阶段,是提取记忆的好时机)。
记忆文件长这样:# 项目记忆## 架构- 前端:React + Ink 用于终端界面- 状态管理:类似 Redux 的 createStore 模式## 用户偏好- 使用 bun 而非 npm- 提交信息使用中文## 调试笔记- queryLoop 中的 while(true) 是有意为之,并非 bug
这一层解决的问题是跨会话的持续性,你在一个会话里告诉模型的东西,下一个会话还能记得,因为 MEMORY.md 在每轮查询时都会被读取并注入上下文。
第三层:Session Memory
Session Memory 和 MEMORY.md 不是一回事。它也是一个 Markdown 文件,但由一个独立的后台服务维护,有自己的模板结构,包含 Session Title、Current State、Task specification 这些章节。
区别在于职责不同:MEMORY.md 是长期的通用笔记,记录架构决策和用户偏好;Session Memory 是面向当前会话的运行摘要,记录当前正在做什么、做到哪一步了。
Session Memory 是保存在磁盘上的,新会话启动时会通过记忆加载机制被读到上下文里。所以新会话能看到上一个会话的进度。
第四层:上下文压缩
对话进行到一定长度时,token 数量会接近模型的上下文窗口限制。这时需要压缩。
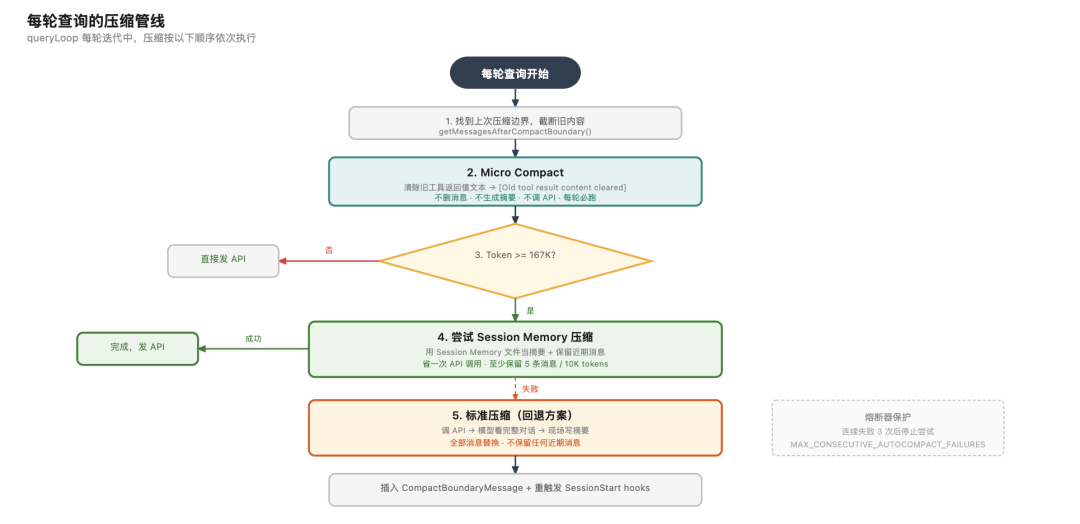
三种压缩机制对比:Micro 压缩只清工具返回值内容;Session Memory 压缩保留近期消息、用现成摘要;标准压缩全部替换、调 API 生成摘要。自动压缩时优先尝试 Session Memory 路径
Micro 压缩是最轻量的。每轮查询前都会跑一次,不生成摘要,不调 API,也不删任何消息。
它做的事情是找到旧的 Read、Bash、Grep、Edit 这些工具的返回值,把文本内容替换成一句 [Old tool result content cleared]。
消息结构还在,只是内容被清空了。早期的工具返回值大概率已经过时了,最近几轮的可能还有用,所以保留近期的。
完整压缩才是真正意义上的”压缩”。把对话历史替换成摘要,但它有两条路径,行为完全不同:
路径一:Session Memory 压缩(优先尝试)。 触发时,系统先检查 Session Memory 是否可用。如果可用,直接拿 Session Memory 文件的内容当摘要,不调 API,而且它会保留近期消息。
Session Memory 后台服务维护了一个 lastSummarizedMessageId,标记”我已经提取到哪条消息了”。
压缩时,这个标记之后的近期消息全部原封不动保留,还有最低保护:至少 5 条消息、至少 1w tokens。模型最终看到的是:Session Memory 摘要 + 保留的近期消息。
路径二:标准压缩(回退方案)。 如果 Session Memory 不可用(比如手动压缩时用户提供了自定义指令),就走标准路径:
调一次 API,让模型看一遍完整对话历史,现场写一段摘要。然后所有消息被替换掉,一条近期消息都不保留,模型最终看到的是:只有摘要。
无论哪条路径,压缩完成后都会在消息列表中插入一条 CompactBoundaryMessage 作为边界标记,还会重新触发 SessionStart hooks,让模型”重新感知”文件系统环境。
这里有个问题:压缩的结果跨会话吗?
压缩摘要本身不会。 它替换了内存中的消息列表,也写入了当前会话的 transcript 文件。用 –resume 恢复同一会话时能看到,但启动全新会话时不会带上。
跨会话的持续性靠的是前面说的 Session Memory 文件——它独立于压缩机制,一直在后台维护。
自动压缩的触发阈值大约是 有效上下文窗口大小 – 13000 缓冲 token。对于 200K 上下文的模型,大约在 167,000 tokens 时触发。连续失败 3 次后会停止尝试(熔断器),避免无限循环。
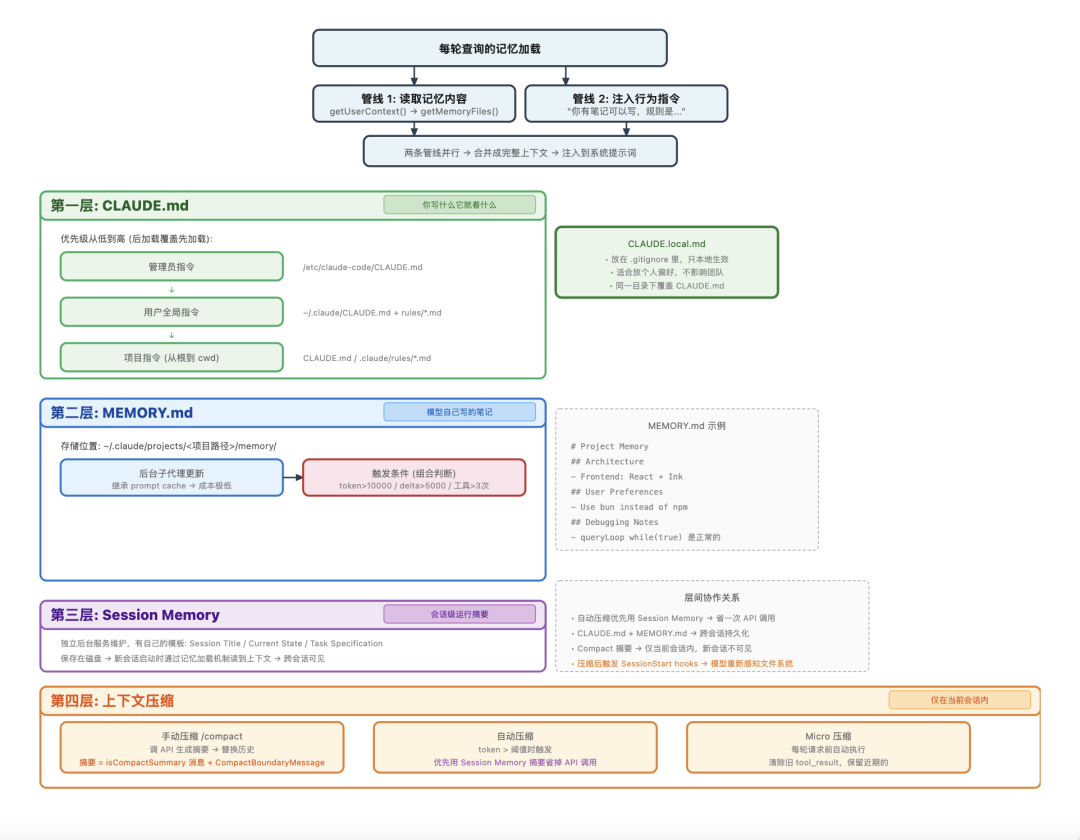
四层记忆系统总览:两条并行加载管线 + CLAUDE.md / MEMORY.md / Session Memory / 上下文压缩四层记忆各司其职
06 流式响应
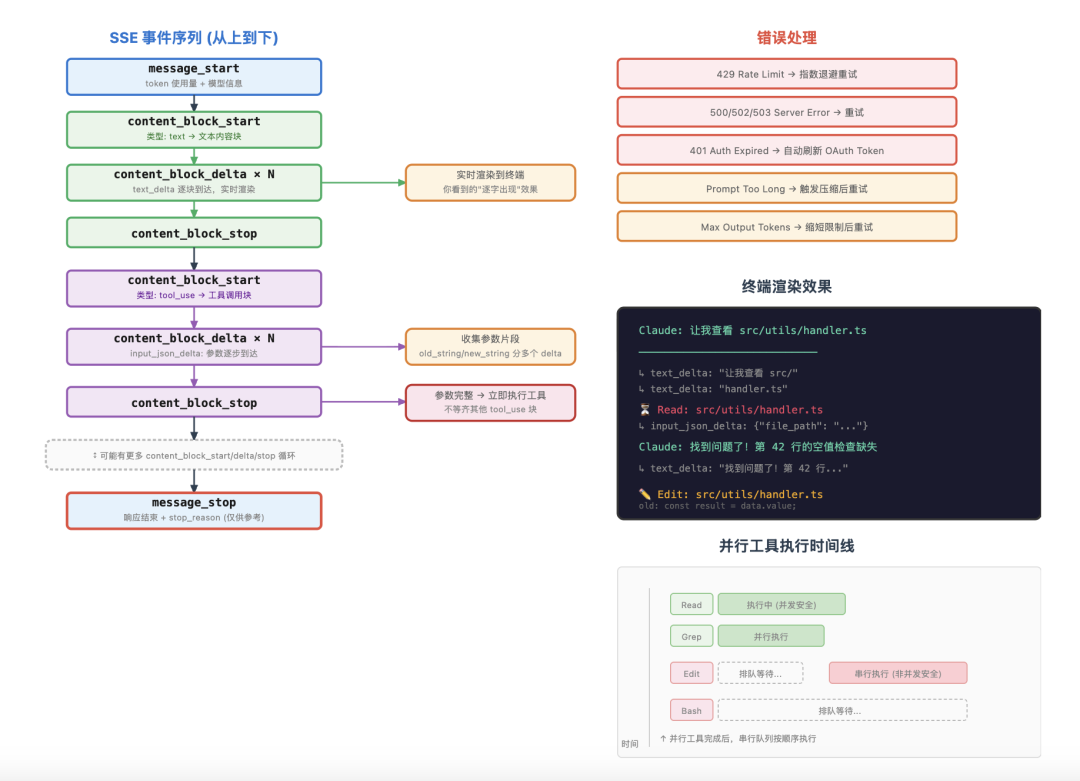
API 返回的不是一次性返回完整 JSON,而是通过 SSE 逐块返回,这是你能实时看到输出、而不是对着空白屏幕等十几秒的原因。
事件序列大概是这样:message_start → 收到 token 使用量、模型信息 │content_block_start → 开始一个内容块(文本或 tool_use) │content_block_delta × N → 文本片段或 tool_use 参数片段,逐块到达 │content_block_stop → 当前内容块结束 │content_block_start → 可能开始下一个内容块 …message_stop → 整个响应结束,附带 stop_reason
每收到一个 text_delta 事件,文本就立即渲染到终端,你看到的”一个字一个字出现”的效果就是这么来的。
tool_use 块的参数也是流式到达的。模型要调用 Edit 工具时,参数 old_string 和 new_string 可能分好几个 delta 事件才传完。
StreamingToolExecutor 会持续收集这些 delta,等参数完整后才开始执行。
SSE 事件序列与终端渲染:message_start → content_block_start/delta/stop → message_stop,文本实时渲染,tool_use 参数流式收集
如果中途出了问题,查询循环也有错误处理:429 限流就指数退避重试,500/502/503 服务端错误也重试,401 认证过期就自动刷新 OAuth Token,Prompt Too Long 就触发压缩后重试,Max Output Tokens 就缩短输出限制后重试。
最后:把所有环节串起来
现在你已经走完了每个环节,我们再把”帮我修 bug + 截图”这条消息的完整旅程快速过一遍:
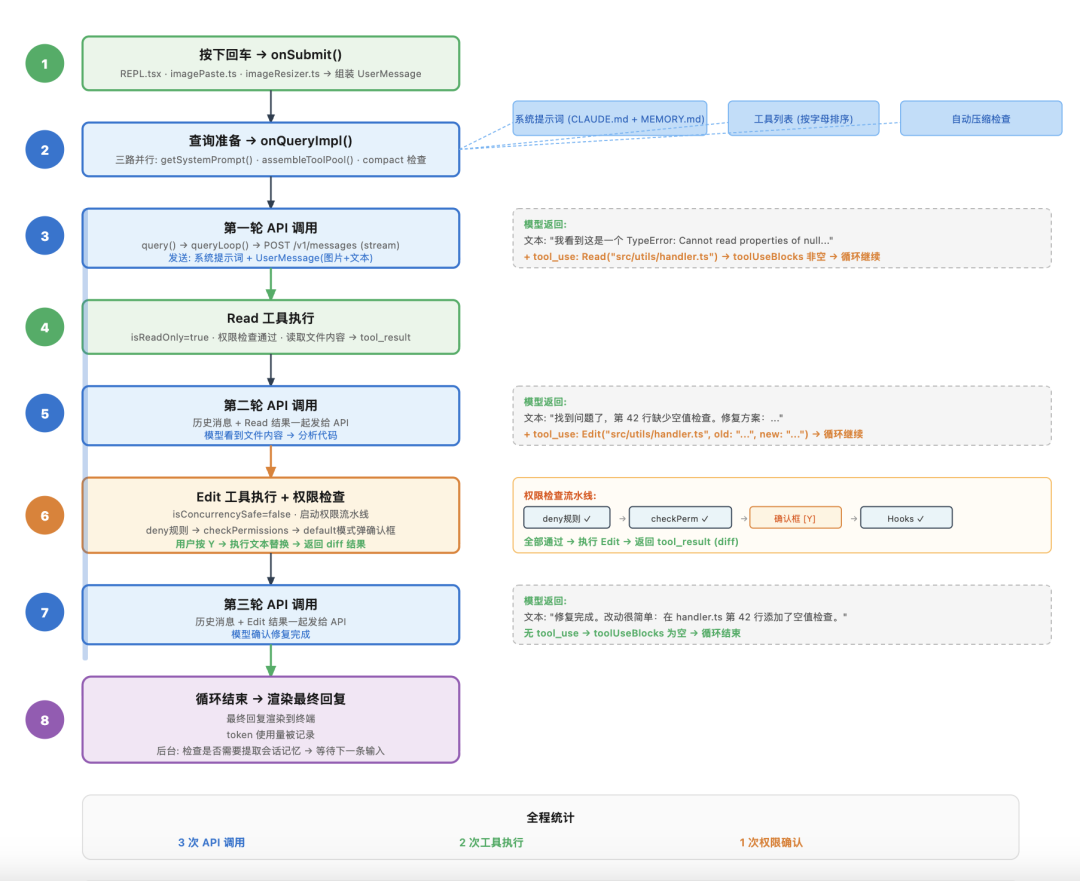
完整链路回顾:8 个步骤、3 轮 API 调用、2 次工具执行、1 次权限确认,从按下回车到修复完成。
你按下回车。 REPL.tsx 的 onSubmit() 触发。imagePaste.ts 从剪贴板拿到图片,imageResizer.ts 压缩编码。文本和图片组装成一条 UserMessage。
查询准备。onQueryImpl() 并行做三件事:getSystemPrompt() 组装系统提示词(加载 CLAUDE.md、MEMORY.md、环境信息),assembleToolPool() 组装工具列表,compact 模块检查是否需要自动压缩。
第一轮 API 调用。query() → queryLoop() → POST /v1/messages(stream)。发给模型的消息里有系统提示词和你的消息(图片 + 文本)。模型返回文本(识别了图片中的错误)+ tool_use(要求 Read 某个文件)。
Read 工具执行。 Read 是只读工具,权限检查通过,读文件,返回内容。
第二轮 API 调用。 历史消息 + Read 的结果一起发给 API。模型分析代码,返回 tool_use(要求 Edit 修改文件)。
Edit 工具执行。 Edit 不是只读的,权限检查流水线启动:没被禁止 → 路径在项目内 → default 模式弹出确认框 → 你按了 Y → 执行替换 → 返回 diff 结果。
第三轮 API 调用。 模型看到编辑结果,确认修复完成,没有新的工具调用请求。
循环结束。 最终回复渲染到终端,token 使用量被记录,后台检查是否需要提取会话记忆,等待你下一条输入。
从按下回车到看到结果,这条消息穿过了 UI 层、编排层、核心系统层、服务层,经过了好几轮 API 调用和工具执行,通过了权限检查,最终带着修复结果回到了你的终端。
走完流程,再看设计
说实话,我之前写文章几乎是不使用 AI 的,但是这篇文章是在跟 AI 协作了 3天 搞出来的,因为那个源码几乎很难完全硬着头皮去读,先不说能不能完全读懂(没办法调试的),核心原因是可能 ROI 没那么高。
换句话说:我更倾向去读 OpenClaw 这种可调式的完整项目
走完全程后,也是有几个点值得拿出来大家看看的,这和最近流行的 *Harness也是有关系的:
子代理模式。 压缩、记忆提取这些”管理对话”的操作,都是通过创建子代理来完成的。子代理共享父对话的 prompt cache,成本极低。这把”管理对话”和”回答问题”分成了两个独立的关注点,是一个很实用的设计模式。
流式工具执行。 不等所有 tool_use 到齐再执行,而是边接收边执行。能并行的并行,必须串行的排队。在模型一次请求多个工具的场景下(这在 Claude Code 里很常见),这减少了等待时间。
多层权限模型。 命令解析结合 shell-quote 结构化分析和 LLM 语义理解来判断 Bash 命令的风险,YOLO 分类器同样用 LLM 来判断操作安全性,Hook 系统给用户留了一票否决的最终手段。不是简单的”允许/禁止”二选一,而是在自动化效率和安全性之间找到了一个不错的平衡。
Prompt Cache 友好设计。 系统提示词分静态和动态两段,工具列表按字母排序,一切都是为了让缓存尽可能命中。缓存命中时成本降大约 90%。对一次会话可能调用几十次 API 的工具来说,不做这个优化,成本会很高。
多层记忆的协作。 CLAUDE.md、MEMORY.md、Session Memory、Compact 是几个独立的系统,但它们有协作:自动压缩时优先用 Session Memory 的摘要省掉一次 API 调用,CLAUDE.md 和 MEMORY.md 跨会话持久化,Compact 摘要只在当前会话内生效。”长期记忆”和”短期压缩”各司其职,不互相干扰。
结语:Harness
总结一下,我们为了更好的理解 Claude Code 的架构,追了一条消息的生命周期:从在终端里按下回车,到图片被处理、系统提示词被组装、工具被加载、查询循环开始转动,再到权限检查、记忆提取、上下文压缩、流式返回,最后把结果送回屏幕。
大家要注意,梳理流程是为了了解架构
所以,如果把这些环节再往上提一层,Claude Code 真正值得看的,是它如何把模型能力包进一整套可以持续运行的工程系统里。
这恰恰就是最近的热词:Harness 的价值。
所谓 Harness,说白了,不是某个新组件,也不是什么玄学黑话,而是把模型能力变成稳定执行能力的那套工程化装置。
它要解决的,从来都不是“模型会不会答”,而是“模型能不能在真实环境里持续、稳定、可验证地把事做完”,从这个角度说,Claude Code 的源码确实是一个很好的 Harness 案例。
因为它已经不只是一个聊天产品,而是在认真处理 Agent 落地时最麻烦的那批工程问题:长链路执行、工具并发、权限分层、记忆沉淀、压缩恢复、子代理协作。这些东西,才是真正把 AI 从“会说”推向“能干活”的关键。
当然,如果是从学习的角度看,Claude Code 也有它的限制,核心问题是他不完整,他能让你看到很多局部设计为什么会长成这样,但实际学起来就差点意思。
所以拿来系统性理解 Agent Runtime / Harness,全局视角 Claude Code 未必是最舒服的,他更适合国内搞 AI Coding 这批公司,我们这些更多是外围赏析下。
真要说看明白 Harness 整套东西是怎么跑起来的,OpenClaw 这种更完整、可调、链路也更外露的项目,学习体验反而会更好一些。
所以这篇文章写到最后,我自己的结论其实很简单:
Claude Code 值得看,但不值得研究,因为各位大概率是学不明白的,他身上涵盖的那套 Harness,我们下次会继续探讨,但是结论可能也很扎心:不建议深度研究…
本文由人人都是产品经理作者【叶小钗】,微信公众号:【叶小钗】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


