起点课堂会员权益
起点课堂会员权益0 基础搭一个“在线健康管家”AI 客服:RAG、槽位填充、数据库怎么配合?
当医疗健康服务遇上AI客服,如何精准划分技术边界成为生死攸关的命题。本文深度拆解一个在线健康管家项目中AI落地的实战经验,从RAG架构搭建、权限硬隔离到槽位填充设计,揭示医疗场景下如何用数据库铁律锁死AI能力边界,以及为什么‘精确查询绝不交给大模型’会成为项目生命线。

之前干了一个活,给一个“在线健康管家”服务做 AI 客服,这几天复盘一下。需求很朴素:用户半夜不舒服,先有个东西接住他,问清情况,再帮他对接合适的医院、科室、医生,别让人干等。
听起来不难。真上手才发现,光是搞清楚“哪些该用 AI、哪些不能”就花了不少时间。我不是技术出身,一开始连 RAG、Embedding 是什么都说不利索,追着工程师和资料一个个问,才把整条链路捋顺。这篇按“我要交付这东西,到底得搞懂哪些”的顺序写下来,业务细节做了模糊化,逻辑是真的。
这个需求要做成什么样?
一个 7×24 在线的 AI 客服,用户来了得干四件事。
- 认人:服务是会员制,会员分级,权益不同——能问几次、能不能约线下陪同、能不能对接更高级别医生都不一样;会员之间还有绑定关系,一个主账号挂着家人账号。用户一开口,系统得先知道“你是谁、你这级别能用什么”。
- 问清楚:用户说“我不舒服”没用,得追问哪儿不舒服、多久了、哪个城市、有没有想去的医院。信息不齐没法匹配。
- 给方案:根据症状判断挂什么科,结合城市和权限,推荐医院、科室、医生。
- 落地:用户点头后派到后台,由人去跟医生敲时间、安排陪同。
四件事里真正“智能”的只有第二、第三。第一和第四本质是数据库和工单系统的活儿。这个判断很重要,后面会反复回到它。
第一件事不是选模型,是分清哪些能交给 AI
我踩的第一个坑,是上来就想“用哪个大模型、要不要做 RAG”。后来想明白,顺序反了。第一步是把这四件事掰开,一件件问:这步能不能交给 AI,交错了会怎样。
最要命的例子:会员“还能问几次”,系统里记着 0 次。交给 AI 去“理解”,它有概率算成“还有 2 次”——大模型输出是概率性的,不保证算术对。用户本来没权益,AI 放进来,后面一连串服务全做了,这账谁担。
所以我定了条死规矩:
凡是涉及“对不对、有没有、剩几次、有没有资格”的精确判断,一律走数据库精确查询,绝不交给大模型。
反过来,“这症状大概挂哪个科”“这问题知识库里哪段能答”——没有标准答案、靠语义相近能解决的,才是 AI 该干的。四件事重新分工:
- 认人、查权限、查剩余次数 → 数据库精确查询,不碰 AI
- 听懂用户、收集信息 → 对话模块(AI 参与,但流程被代码管着)
- 症状对科室、知识库问答 → RAG
- 派单、安排陪同 → 工单系统,不碰 AI
很多 AI 项目翻车,不是模型不行,是该用 AI 的地方没用、不该用的地方瞎用。
RAG 这块怎么搭
一句话说清 RAG:让大模型回答前,先去你自己的资料库查一遍相关内容,依据查到的来答,而不是凭记忆瞎编。类比开卷考试——模型还是那个模型,但手边有了参考资料。医疗这种特别怕“一本正经胡说”的场景,这个“开卷”几乎是必须的。
这个项目里 RAG 要建几个库:症状到科室的分诊知识、常见问题 FAQ(改预约、爽约怎么算、能不能退这些提前写好标准答案)、医生擅长方向的描述。
搭 RAG 实际要处理这么几件事,按踩坑顺序讲。
文档怎么切
资料不能整篇丢进去,得切成小块。切太大,一块混了几个主题,检索不精准;切太小,一句话被拦腰斩断,语义就废了。我大致按语义和小标题切,一块几百字。
有个词叫 Overlap(重叠),一开始没明白:相邻两块故意留一段重复——第一块到 500 字,第二块从 450 开始,中间 50 字两块都有。因为一句完整的话可能正好卡在切割线上,不留重叠就被劈成两半,检索就漏了。留重叠等于给接缝上了个保险。
文字怎么变成能比对的东西:Embedding
Embedding 做的事:把一段文字变成一串数字(向量),意思相近的文字数字也相近。“猫”和“小猫咪”挨得近,“猫”和“汽车”离得远。检索就好办了:用户问题也变成数字,去库里找最接近的那几块。
医疗场景建议用中文效果好的开源模型,比如 BGE(智源研究院做的开源向量模型,中文不错、能本地部署)。医疗数据敏感,能不往外部接口传就别传,本地部署的开源模型有天然优势。
补一句,我当时也卡在这:Embedding 不是和 RAG 并列的东西,它是 RAG 里的一个零件——RAG 是整台机器,Embedding 是负责“把文字转成可比对向量”的那个部件。
光靠语义检索不够,得混着来
只用向量找语义相近的,有个毛病:对精确关键词、人名、数字不敏感。用户找“李建国医生”,向量检索可能给一堆“语义上和看病相关”的内容,反把“李建国”排后面,因为它算的是“意思像不像”,不是“字对不对”。
办法是混合检索:向量负责“意思相近”,再叠一个 BM25 负责“关键词精确匹配”。两路各出一个排名,用 RRF(倒数排名融合)合并——按名次打分,越靠前分越高,两边加起来重排,它只看名次不纠结分数量纲,各家向量库大多内置。最后再加一道 Rerank:把前十几条用更精的模型仔细排一遍,取最好的三五条喂给大模型,对答案质量提升明显。
向量存哪儿
向量得有地方存、还要能快速找最近邻,这就是向量库。起步图省事,本地用 Chroma、FAISS,几行代码跑通;要上生产、数据量大,就上 Milvus、Qdrant。我最后选 pgvector,理由下一节讲,这俩是连在一起的。
串起来,RAG 这条链路就是:资料切块、转向量、存库;用户提问转向量,混合检索(向量+BM25)、RRF 合并、重排精排,把最相关那几段连同问题丢给大模型,组织成人话回答。
数据库别省,这是底线
那条死规矩落实就在这。会员信息、绑定关系、剩余次数、权限、医生医院档案,老老实实存关系型数据库,用 SQL 精确查询。“查北京、心内科、职称是专家的医生”,写成 SQL 几个条件一卡,结果确定,没有“大概、差不多”。
我选 PostgreSQL:开源关系型里比较硬的一个,数据一致性强。还有个关键原因——它有插件 pgvector,能顺带把 RAG 的向量也存了,业务数据和向量放一个库,少维护一套系统。对团队不大的项目,能少一个要运维的组件是实打实的减负。
数据库查询和 RAG 到底什么区别?两点。一是查的东西不一样:RAG 查非结构化文本,靠语义相近,差不多就行;数据库查结构化精确数据,条件必须完全对;二是查完给不给模型分情况:查“剩余次数是不是 0”,查出来程序直接走分支,根本不经过大模型,它是个判断不是个表达,交给模型只会引入风险;查到“还剩 3 次、有陪同权益”,这些事实可以塞给模型,让它用友好话术讲给用户。
权限我还做了一层硬过滤:会员能不能对接更高级别医生,这条件直接写进 SQL。没这权益的会员,SQL 那层就把高级别医生过滤掉,根本到不了推荐环节。不靠 AI“记得别推荐”,靠数据库“压根查不出来”。
对话怎么不跑偏:槽位填充和状态机
只把用户的话丢给大模型自由发挥,体验会很飘:漏问关键信息,或者用户症状还没说清就开始推荐医生。医疗场景不能这么飘。靠两个东西把流程框住。
槽位填充
就是“系统要办一件事,需要凑齐几个必填信息,缺哪个追问哪个”,每个必填信息是一个槽。我这个看诊匹配,真正必须问的就三个:症状、持续多久、哪个城市。该挂什么科、急不急是系统根据症状自己推的,不用问;想去哪个医院是选填,不说就跳过。
对话大概是:
用户:我想看个病。
系统(症状槽空):您主要哪儿不舒服?
用户:胸口闷,有三天了。
系统(一句话填了症状和持续时间两个槽,只剩城市):您打算在哪个城市就诊?
注意用户一句话填了两个槽,系统别再分两次问。设计时要支持一句话填多个槽,也支持中途改(“不对,是上海不是北京”)。实现上:让大模型负责“听懂并抽取”,每轮返回结构化结果,有值填值、没提到留空;让代码负责“流程和校验”,合并值、查城市在不在服务范围、决定下一个追问哪个。模型管理解,代码管规矩。
状态机
得有个东西记着“对话进行到哪了”,这就是状态机里那个 status 标记,像网购订单的“待付款、待发货、已完成”。我大致几个状态:身份核验、信息收集中、待推导科室、待用户确认方案、已完成,外加两个特殊状态:转人工、急症中断。
为什么非要这标记:多轮对话里同一句“嗯”,在“信息收集中”是补充信息,在“待用户确认方案”是同意方案、该派单了。没有 status,系统就失忆了。
急症中断单拎出来:每轮抽取完先过一遍危急关键词——剧烈胸痛、呼吸困难、意识不清这些。一旦命中,立刻跳出槽位流程,直接提示打急救电话、就近就医,同时转人工。慢就是错,这个兜底在医疗产品里没有商量余地,必须先于主流程。
槽位填一半问不出来:同一个槽设追问上限,问三次还问不到有效信息,status 直接转人工。别让用户死循环,也别让 AI 硬撑。
拼起来:一张图和一条路线
零件齐了,拼起来是三层:最上层对话控制(状态机+槽位填充)管流程不跑偏;中间层调度大脑判断这步该调谁,查权限走数据库、答知识走 RAG、拿不准转人工;最下层两类数据源,数据库管精确、RAG 管知识。
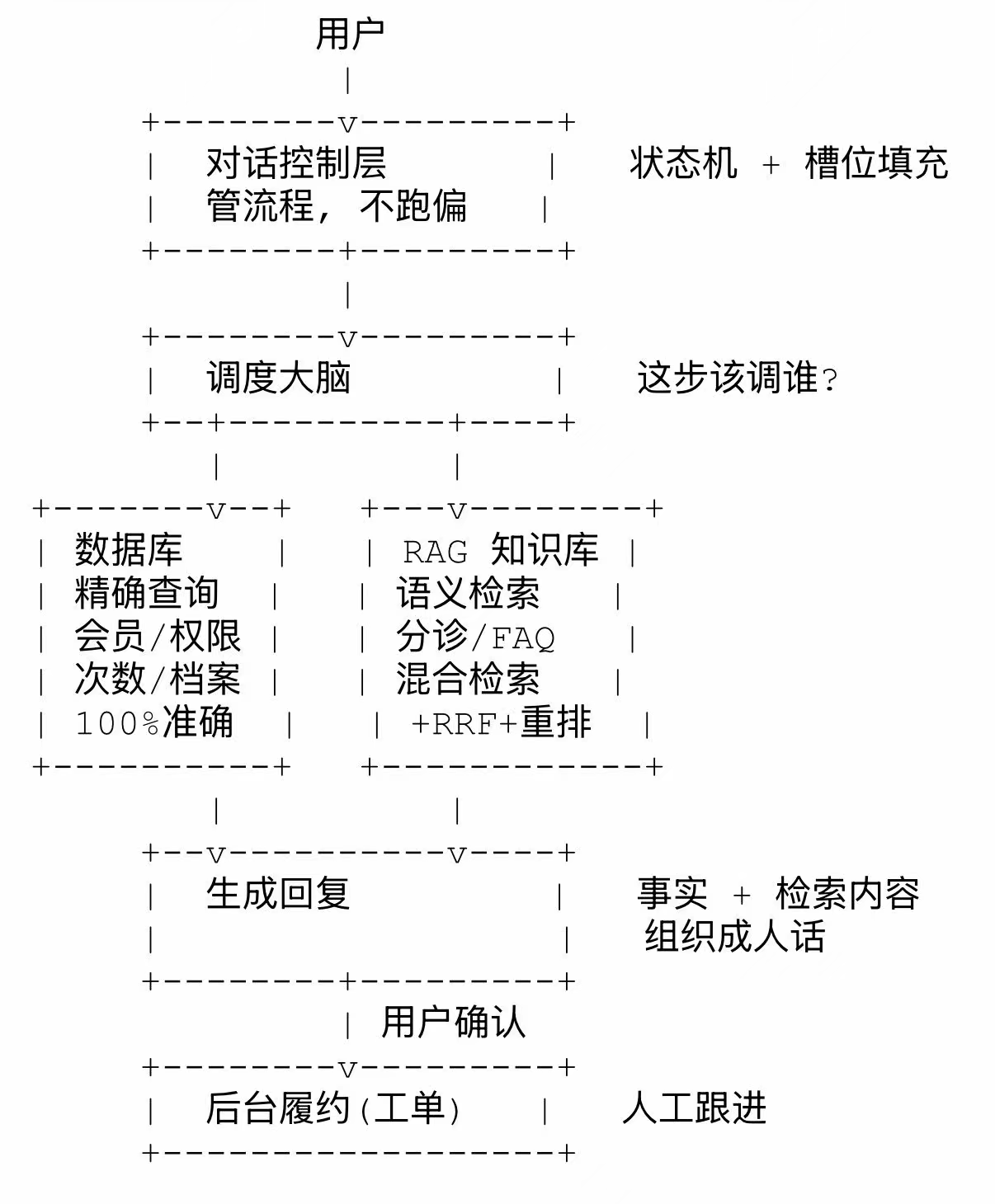
铁律: 权限/次数/档案永远走数据库
知识/分诊走 RAG
拿不准就转人工, 不许编
别想着一上来全做完,我是分阶段的:
- 第一阶段:FAQ 问答 + 症状推荐科室,把 RAG 跑通
- 第二阶段:接会员库,权限和次数判断接上
- 第三阶段:医生匹配,加权限硬过滤
- 第四阶段:上状态机管多轮对话
- 最后:对接后台工单
每阶段都能单独上线、单独验证,别一口气憋大招。
几个我希望早点知道的事
医疗场景容错率比一般业务低得多。同一句答错,在电商是体验问题,在这儿可能是大事。所以“低置信转人工”“急症直接劝就医”这种兜底,不能等主流程做完再补,得和主流程一起设计。
知识库质量决定产品上限。症状到科室那张映射表,我不敢让模型自己编,得拉医学背景的同事一条条核。喂进去的错了,出来的也错。
那条死规矩值得再说一遍:能力边界写进数据库查询条件,别写进给模型的提示词。提示词靠模型“记得遵守”,查询条件是“压根查不出来”,合规这事后者才靠得住。
技术名词我也是这一趟才慢慢搞明白的。但真正难的不是听懂 RAG、Embedding 这些词,是想清楚哪些环节能交给 AI、哪些一寸都不能让。这个判断,反倒是不写代码的产品最该拿主意的地方。
本文由 @Niney 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!