
 起点课堂会员权益
起点课堂会员权益真正能落地的AI项目是怎么做的?
AI Agent的热潮中,人们热衷于探讨RAG、多Agent协作等前沿概念,却往往忽略了一个致命盲点:你真的会拆解任务吗?本文深度剖析Human SOP、Skill与Agentic Workflow的本质差异,揭示从人类流程文档到AI可执行工作流的关键转化法则,教你用报销审批等实战案例掌握任务拆解的核心方法论。

今年很多人都在聊 AI Agent。
RAG、Prompt Engineering、模型微调、Agentic Workflow、MCP、多 Agent 协作……这些词越来越频繁地出现。
但我发现一个很有意思的现象是:
很多人一上来就想研究最复杂的框架、最强的模型、最炫的工具调用,却忽略了一个更基础的问题:
你到底会不会把一个大任务,拆成 AI 能真正执行的小任务?
这件事听起来不性感。甚至有点像项目管理里的老话题。但它恰恰是 Agent 能不能稳定落地的关键。
现在前沿模型的能力已经很强了。很多任务,它不是完全做不了,而是经常被我们用错了。
我们常见的做法是:
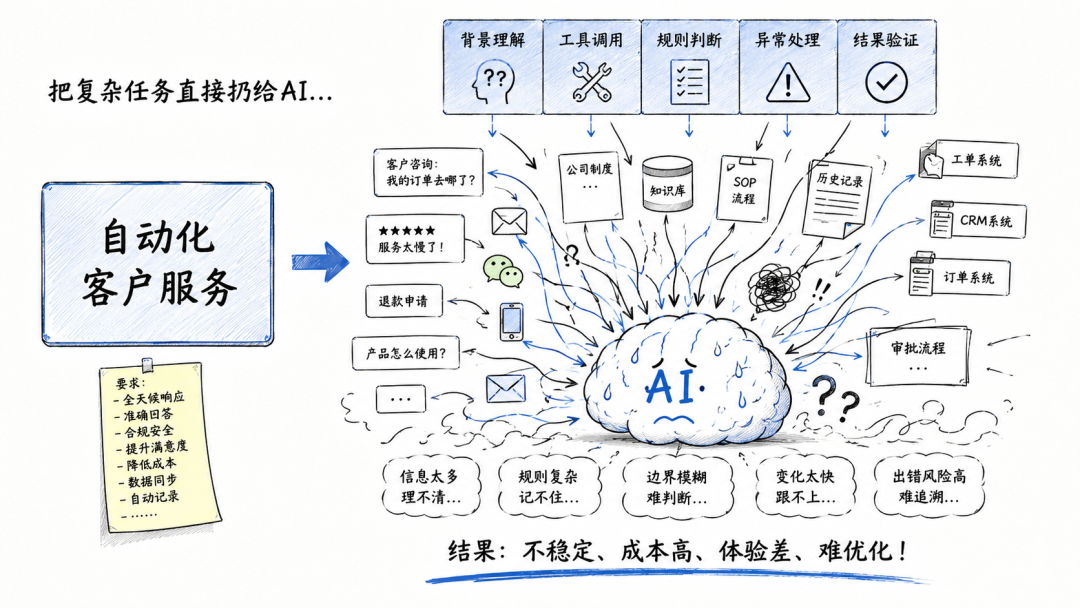
把一个模糊的大任务整包丢给 AI,然后期待它自己理解背景、判断边界、规划步骤、调用工具、检查结果,最后还要稳定交付。
比如:
“帮我把销售线索跟进流程自动化。”“帮我处理客户咨询。”“帮我把这份内部 SOP 改造成 Agent 工作流。”“帮我把几篇资料整合成一篇公众号长文。”
这些需求听起来都很正常。
但如果你真的把它们整包丢给一个 Agent,大概率会得到一个看起来很完整、实际很难落地的结果。
不是模型不够聪明。
而是任务本身太大、太散、太依赖人类脑补。
所以这篇文章想聊一个 Agentic Workflow 里非常重要、但经常被低估的能力:
Task Decomposition,任务拆解。
先讲清楚三个概念:Human SOP、Skill、Agentic Workflow
在讲任务拆解之前,我们先把三个概念分清楚。
很多人会把 Human SOP、Skill、Agentic Workflow 混在一起讲。
但它们不是一回事。
它们分别处在不同层级。
如果这个层级关系没搞清楚,后面很容易把一份普通流程文档,当成 Agent 可以直接执行的工作流。
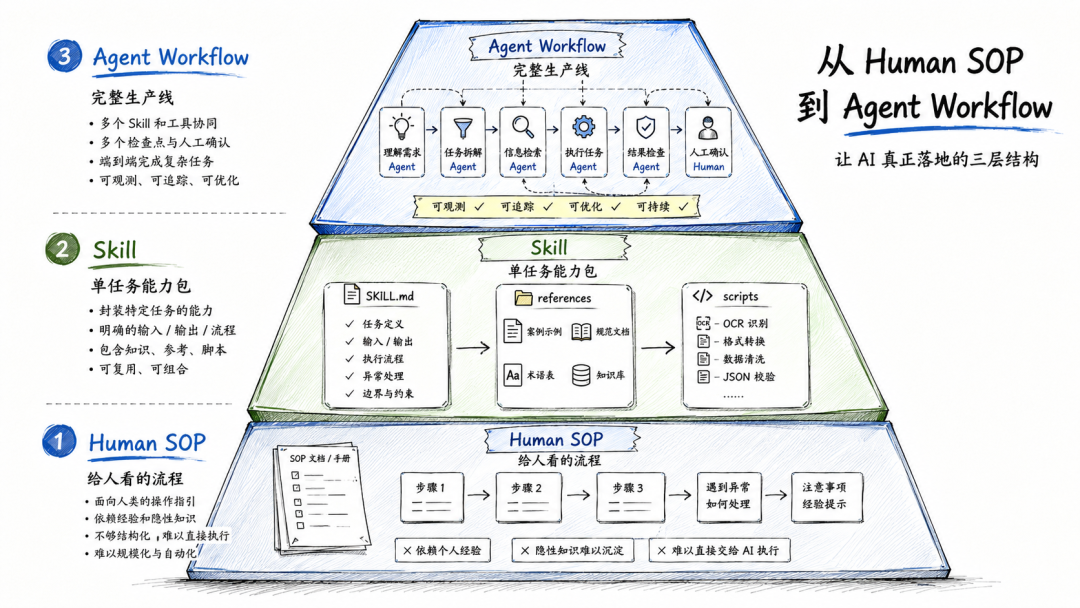
1. Human SOP:写给人看的流程
Human SOP,就是传统意义上的流程文件。
它可能是一份 Word 文档,也可能是一份飞书文档、企业微信文档、钉钉知识库、PPT,或者团队内部的操作手册。
它会告诉你:
第一步做什么。第二步做什么。遇到异常怎么处理。有什么注意事项。哪些地方新人容易踩坑。
这种 SOP 对人类来说很好用。
因为人类看 SOP 的时候,脑子里会自动补很多上下文。
比如一个财务报销 SOP 里写:
发票、付款截图和审批单齐全后,提交OA审批。
人看到这句话,会自然理解很多隐藏规则。
如果只是几十块的打车费,金额不大,发票抬头没问题,项目也对,你可能直接按普通流程走。
但如果是五千块以上的客户招待费,你就知道事情没那么简单。
你要看有没有招待对象。有没有事前审批。有没有对应项目。预算是不是够。是不是跨月报销。是不是涉及敏感客户。是不是需要部门负责人和财务负责人一起确认。
这些判断,很多公司不会完整写在 SOP 里。
不是因为它们不重要,而是因为大家平时都是靠经验处理。
更现实一点说,很多团队也不愿意把所有例外情况都写进文档里。
维护 SOP 很累。
口头提醒一句,永远比更新文档方便。
所以 Human SOP 的特点是:
它看起来像流程,实际上高度依赖人的理解、经验和补全能力。
这对人没问题。
但对 Agent 来说,问题就来了。
因为 Agent 不知道你们公司里“五百块”和“五千块”意味着什么。
它不知道普通差旅、客户招待、市场活动、采购付款分别该走什么规则。
它不知道哪一步可以省,哪一步不能省。
它也不知道遇到例外时应该继续执行,还是停下来问人。
如果你没有明确写出来,它就只能猜。
而一旦开始猜,稳定性就没了。
2. Skill:把单一任务打包给 Agent 的执行单位
第二个概念是 Skill。
我对 Skill 的理解很简单:
Skill 本质上是把你做事的方法论、判断标准、经验和踩过的坑,打包成一个 Agent 可以调用的能力包。
想详细了解的可以看上期文章。看了很多文章依旧不会写skill?实战分享
一个比较完整的 Skill,通常会包含三类东西。
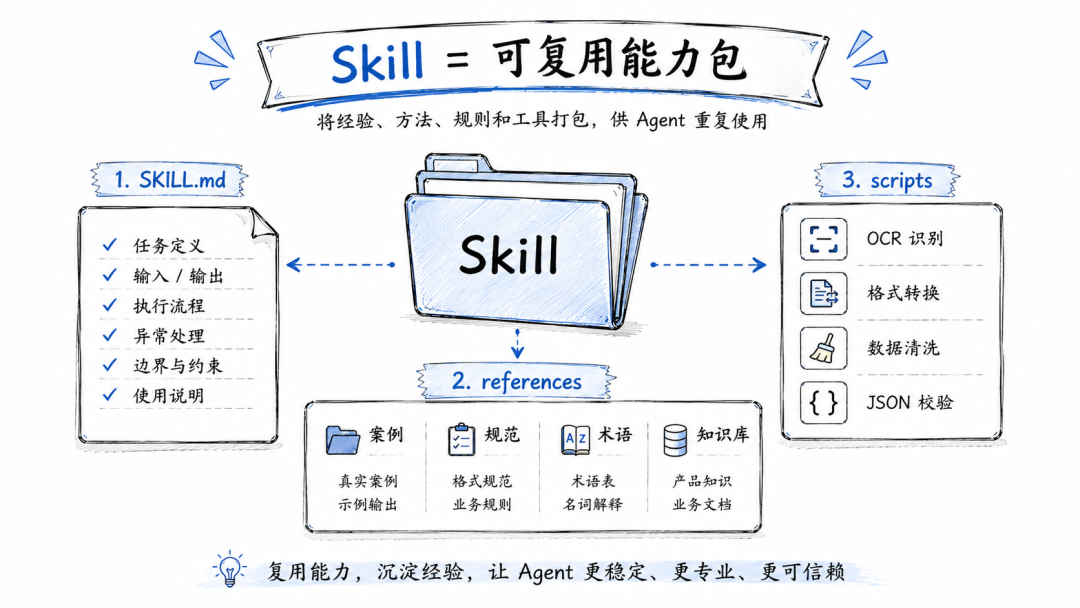
第一类是核心说明文件。
比如SKILL.md。
它告诉 Agent:这个 Skill 是做什么的,什么时候触发,输入是什么,输出是什么,流程怎么走,遇到异常怎么处理。
第二类是 references。
也就是参考资料。
里面可以放示例输出、术语表、历史案例、常见错误、格式规范、业务背景说明。
比如报销场景里,references 可以放:
差旅报销制度。发票样例。常见驳回原因。费用科目对照表。特殊客户招待说明。
这些东西不是每次都要全部塞进上下文,而是让 Agent 在需要时可以取用。
第三类是 scripts。
也就是可执行脚本。
凡是确定性很强的操作,最好不要交给模型自由发挥。
比如文件解析、格式转换、表格清洗、PDF 拆分、JSON 校验、发票字段提取,这些传统工程能稳定完成的事,就交给脚本。
这样不仅省上下文,也更稳定。
但这里有一个关键点:
一个 Skill 最好只对应一个相对明确的任务,而不是整条复杂工作流。
比如:
expense-material-check
lead-intent-classification
customer-reply-drafting
official-account-rewrite
content-fact-check
这些名字一看就知道它负责什么。
Skill 的边界非常重要。
边界太大,它会变成“什么都能做一点,但什么都不稳定”。
边界太小,又会把模型当小孩,每一步都要人类规定,反而失去大模型的泛化能力。
所以 Skill 设计的关键,不是越细越好,也不是越大越好,而是找到一个合适的任务粒度。
3. Agentic Workflow:由多个 Skill 和工具组成的生产线
第三个概念是 Agentic Workflow。
如果说 Human SOP 是写给人看的流程,Skill 是一个 Agent 可以调用的单任务能力包,那么 Agentic Workflow 就是一整条生产线。
它可能包含:
多个 Agent。多个 Skill。多个工具。多个数据源。多个检查点。多个中间产物。多个人工确认节点。
它不是一个 prompt。也不是一个“超级 Agent”它更像一条公司里的业务流水线。
有人负责理解需求。有人负责查资料。有人负责执行动作。有人负责生成结果。有人负责质检。有人负责在高风险节点停下来让人确认。
只不过这条流水线里,很多岗位都变成了 AI。

所以三者的关系可以这样理解:
Human SOP:给人看的流程。Skill:把某个具体任务封装成 Agent 能调用的能力。Agentic Workflow:把多个 Skill、工具、数据源和人工确认节点串起来,形成一条能跑完整任务的生产线。
本篇要讲的,就是如何把原本写给人看的 Human SOP,逐步改造成 Agent 能稳定执行的 Agentic Workflow。
为什么不能把 Human SOP 直接丢给 Agent?
很多人会有一个疑问:
模型越来越强了,上下文越来越大,以后是不是就不用拆得这么细了?
直接告诉它目标不就行了吗?
比如:
“帮我处理这些报销单。”“帮我把客户咨询自动分流。”“帮我把销售线索自动分配给销售。”“帮我把每周内容选题、改写、配图建议都跑完。”
理论上听起来很美。
但现实往往不是这样。
我们用一个更贴近公司日常的例子来理解。
假设你把一个新来的运营同事拉进群里,对他说:
以后客户在企业微信里问问题,你先帮我处理一下。能直接回的直接回,需要销售跟进的转给销售,需要售后的转给售后。
这句话听起来很清楚。
但如果真的让新人独立处理,很快就会出问题。
因为“能直接回”这四个字,背后藏着一堆判断。
用户只是问价格,算不算销售线索?用户说“考虑一下”,要不要打标签?用户问退款,应该安抚,还是直接发售后链接?用户提到竞品,要不要提醒销售重点跟进?用户只是吐槽一句“太贵了”,是低意向,还是需要解释价值?用户连续三次没回复,要不要自动停止跟进?
这些细节,老员工靠经验能判断。但新人不一定能判断。Agent 也一样。
你只说“帮我处理客户咨询”,它当然会做点什么。
但它不知道你们团队对“高意向客户”的定义是什么。
不知道哪些承诺不能随便说。不知道什么时候该转人工。不知道哪些话术会引发售后风险。不知道哪些问题属于产品咨询,哪些问题已经进入投诉处理。所以问题从来不是 Agent 够不够聪明。
问题是:
你有没有把你脑子里的业务判断,拆成它能执行的规则。
很多 Agent 看起来不靠谱,不是因为模型能力差。
而是因为它被要求在一堆没有边界的业务场景里自由发挥。
自由发挥一多,稳定性就没了。
为什么把复杂工作交给 Agent 一步完成,往往会失败?
很多人第一次做 Agent,最容易犯的错误就是:
把一个复杂工作,直接打包丢给 AI。
比如:
“帮我优化整个销售流程。”“帮我处理所有客户评论。”“帮我把这批素材整理、分析、改写、发布。”“帮我把公司内部流程全部自动化。”“帮我检测这条营销链路的问题并自我优化”
看起来很合理。 毕竟 AI 已经这么强了。
既然能写代码、写文章、做分析,那为什么不能一步做到位?
于是很多人会希望:输入一个目标。点击开始。等待结果。然后 AI 自动把所有事情做完。
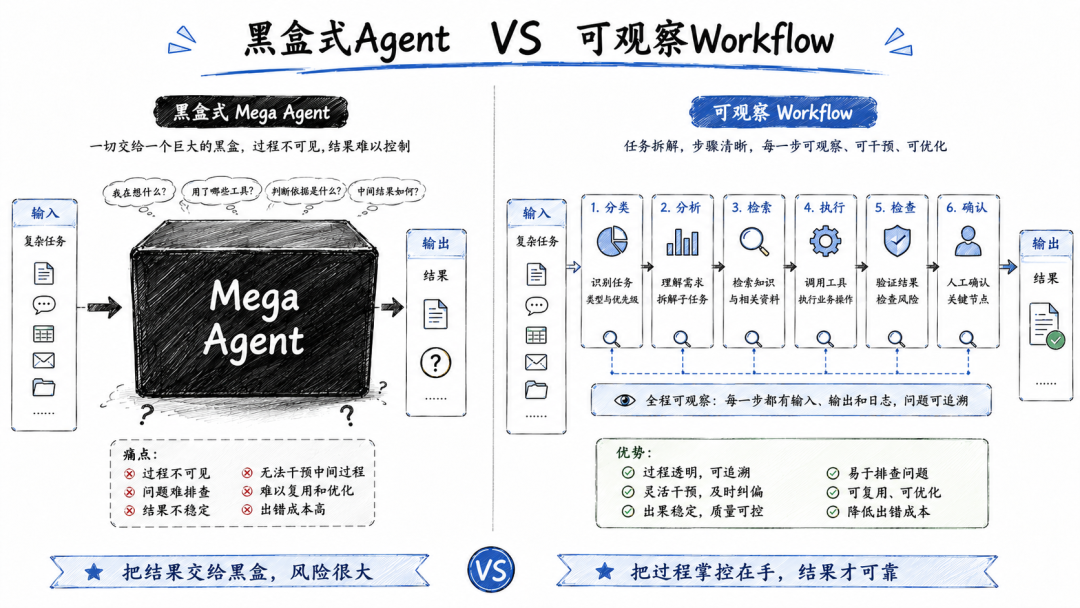
但现实往往不是这样。它确实会输出一些东西。
可能是一份很长的分析报告。可能是一套看起来很完整的方案。可能完成了一堆自动化操作。也可能改动了某些根本不该改的内容。
问题在于:
你不知道它是怎么得到这个结果的。哪些判断是正确的?哪些结论是模型推测出来的?哪些地方调用了工具?哪些地方本来应该由人来确认?
你很难知道。因为整个过程被压缩成了一次输入和一次输出。
中间没有清晰的步骤。没有可观察的过程。没有能够单独验证的结果。更没有方便排查问题的边界。
一旦结果出错。你往往不知道该修改哪里。
很多新手遇到这种情况,第一反应是:
换一个更强的模型。写一个更详细的 prompt。再加一点约束。再塞更多背景资料。
但很多时候,问题不在模型,也不在 prompt。
问题在于:
任务太大了。
一个任务只要大到没有明确输入、明确输出、明确成功标准,它就很难稳定。
反过来,如果你把任务拆成一串小任务,每个任务都有清晰边界,整个系统就会完全不一样。
举一个常见的场景:私域企业微信里的客户咨询。
你不要让一个 Agent 从头到尾全干。可以拆成六个环节:
第一个 Agent,只负责识别用户意图。第二个 Agent,只负责查询用户资料和历史对话。第三个 Agent,只负责匹配产品知识库或营销方案。第四个 Agent,只负责生成回复内容。第五个 Agent,只负责检查话术风险,比如有没有违反法规。第六个 Agent,只负责根据结果打标签、分配销售或转人工。
每个 Agent 看起来都很笨。 但它只做一件明确的事。
意图识别错了,你就改意图分类规则。资料查错了,你就改检索范围。回复不好,你就改话术规范。风险检查漏了,你就补质检规则。分配错了,你就改分配逻辑。
这就叫可修复。
真正能上线的 Agentic Workflow,要的不是“看起来很聪明”,而是:
稳定性、可观测性、可修复性。
这才是能跑到真实业务里的系统。
用报销OA来理解:为什么 SOP 必须被拆开?
很多公司都有报销流程。
员工提交报销材料后,行政或财务先做初审。
大概看这些东西:
发票有没有。抬头和税号对不对。金额和申请单是否一致。费用类型是否合理。有没有项目归属。有没有审批记录。有没有超预算。有没有重复报销风险。
如果你让一个有经验的财务同事处理,她可能只需要扫一眼,就能发现问题。
但她脑子里其实跑了很多判断。
差旅费和招待费不是一回事。会议费和市场活动费也不是一回事。打车费要看出发地和目的地是否合理。餐饮发票要看是不是需要招待对象。住宿发票要看日期是否和出差时间匹配。电子发票要防止重复提交。超过一定金额可能需要更高层级审批。
这些东西如果写成 Human SOP,可能只有一句话:
财务根据公司报销制度审核材料是否完整,必要时退回补充。
对人来说,这句话够了。对 Agent 来说,远远不够。因为 Agent 不知道什么叫“必要时”。
不知道哪些材料缺失可以提醒补充。哪些情况必须直接驳回。不知道金额达到多少要升级审批。不知道不同费用类型分别需要哪些附件。
所以我们要做的,不是把这句 SOP 原封不动丢给 Agent。
而是把它拆成一条 Agent 能执行的工作流。
这件事可以分成四步。
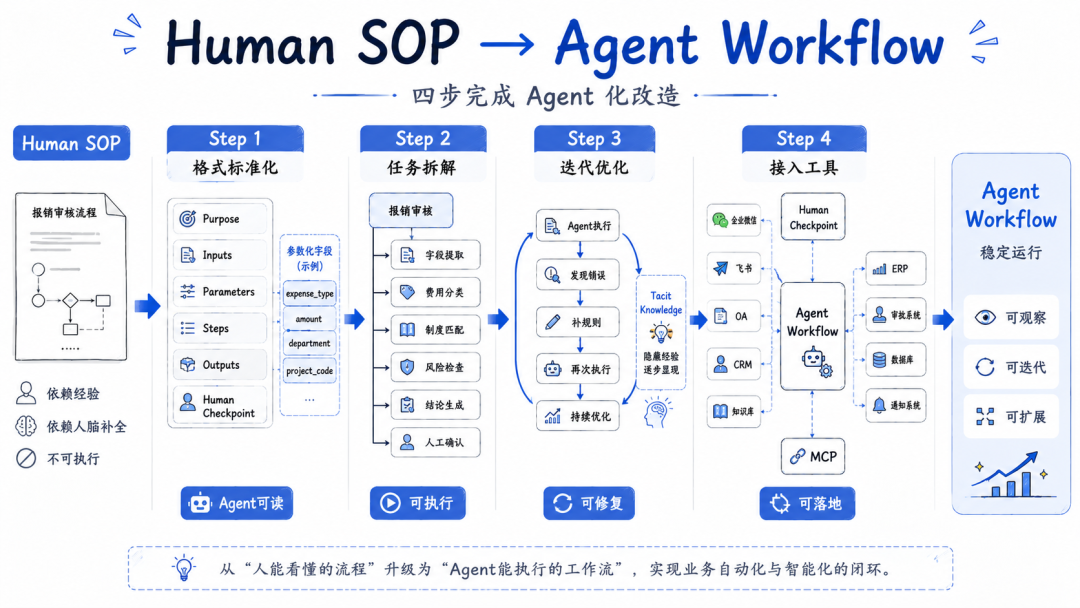
第一步:格式标准化,把人话 SOP 改成 Agent 能读的规格
第一步,不是马上拆 Agent,也不是马上接工具。
而是把一段散文式的流程,改成 Agent 能理解、能复用、能执行的结构。
这里有三个重点。
1. 参数化:不要把流程写死
很多人写 Skill 或 SOP 时,喜欢把场景写死。
比如报销规则里写:
超过五千元,需要主管审批。
这句话本身没错。
但如果不同部门、不同费用类型、不同项目规则不一样呢?
销售招待费超过五千可能要部门负责人确认。采购付款超过五千可能还要财务负责人确认。市场活动费用可能要看活动预算。差旅报销可能要看是否提前审批。
所以更好的写法不是把规则写死,而是参数化。
比如:
- expense_type:费用类型,比如差旅、交通、招待、采购、市场活动。
- amount:报销金额。
- department:提交部门。
- project_code:项目归属。
- invoice_type:发票类型。
- approval_level:所需审批层级。
- policy_version:当前适用的制度版本。
这样同一份 SOP 就不再是一条死规则,而是一套可以根据场景调用的模板。
这点非常重要。
因为一个不能复用的 Skill,很快就会变成只服务某个特殊场景的长文档。
看起来写了很多,实际容错很低。
2. 用 MUST / SHOULD / MAY 区分规则强度
第二个重点,是区分规则强度。
MUST:必须做,不能跳过。SHOULD:建议做,除非有明确理由不做。MAY:可以做,也可以不做。
比如报销初审这件事:
MUST:
• 必须检查发票抬头、税号、金额是否与申请单一致。
• 必须检查费用类型是否与附件匹配。
• 必须检查是否存在重复提交风险。
• 金额超过规则阈值时,必须进入人工确认。
• 涉及客户招待、采购付款、合同付款时,必须检查是否有事前审批。
SHOULD:
• 应该根据费用类型提示缺失材料。
• 应该根据历史驳回原因,提醒可能被退回的问题。
• 应该根据项目归属,推荐对应成本中心或费用科目。
MAY:
• 可以根据历史样例生成补充材料说明。
• 可以根据报销类型推荐常用备注模板。
• 可以在低风险、小金额、材料齐全时直接生成通过建议。
你看,规则一旦分出强度,Agent 就知道哪些地方不能商量,哪些地方可以结合上下文判断。
这比单纯写“根据公司制度审核报销材料”清楚太多。
3. 用结构化格式组织内容
第三个重点,是结构化。
不要把所有内容写成一大段。
而是用清晰的 Markdown 区块拆开:
- Purpose:这个 SOP 解决什么问题
- Trigger:什么时候触发
- Inputs:输入是什么
- Parameters:可配置参数有哪些
- Steps:执行步骤
- Output:输出格式
- Error Handling:异常怎么处理
- Human Checkpoint:什么时候必须问人
这样写的好处是:
人能看懂。Agent 也能看懂。后续还可以接入工具、脚本、MCP、数据库、审批系统。
到这一步,你已经完成了第一层转换:
把一份写给人的流程,翻译成 Agent 能读的行为规格。
但这还不够。
因为你只是让 SOP 变清楚了,还没有真正拆任务。
第二步:任务拆解,把一个大流程拆成多个独立节点
第二步,才是Task Decomposition的核心。
你要把一个完整流程,拆成一串独立节点。每个节点都要有自己的输入、输出和成功标准。
继续用报销初审举例。
原本一句话是:
根据公司制度审核报销材料是否完整,必要时退回补充。
现在可以拆成几个节点:
1. 提取报销信息
2. 校验发票字段
3. 判断费用类型
4. 匹配报销制度
5. 检查缺失材料
6. 识别风险项
7. 生成初审结论
8. 必要时生成补充材料问题
9. 高风险情况进入人工确认
每个节点都可以独立执行。 也可以独立调试。
比如发票字段提取错了,你只需要修 OCR 或字段解析节点。费用类型判断错了,你只需要修分类规则。风险识别漏了,你只需要补风险规则。
不需要把整条流程重写一遍。
这就是拆解的价值。
在 Agentic Workflow 里,每个节点可以是一个小 Skill,也可以是一个小 Agent,也可以是一段脚本。
比如:
字段提取节点:由脚本或视觉模型提取发票金额、抬头、税号、日期。费用分类节点:由 Agent 判断它属于差旅、交通、招待、采购还是市场活动。制度匹配节点:检索公司报销制度。风险检查节点:识别金额超限、重复报销、缺少事前审批等风险。回复生成节点:生成退回说明或通过建议。人工确认节点:遇到高风险金额或敏感类型时停下来。
这些节点之间靠什么连接?上一个节点的输出,就是下一个节点的输入。比如字段提取节点输出一份 JSON:
{“submitter”:”张三”,”department”:”销售部”,
“expense_type”:”客户招待”,
“amount”:5280,
“invoice_title_matched”:true,
“tax_id_matched”:true,
“project_code”:”BD-2026-03″,
“attachments”:[“发票”,”付款截图”,”事前审批单”],
“possible_risks”:[“金额超过普通审批阈值”]}
这份 JSON 会变成下一个节点的输入。
制度匹配节点根据它判断需要走什么规则。风险检查节点根据它判断是否要人工确认。回复生成节点根据它生成给员工看的补充说明。
这就是工作流。不是靠模型之间“心有灵犀”。而是靠清楚定义的输入、输出和中间格式。
第三步:双向开发,用真实执行结果反向修 SOP
很多人以为,写 Agent SOP 就像写说明书。
坐在电脑前,把规则一次性写完整,然后丢给 Agent 执行。
但现实中,这几乎不可能。
因为你第一次写出来的 SOP,一定会漏东西。
不是你不专业,而是很多判断本来就藏在你的脑子里。
这里有一个概念很重要:
Tacit Knowledge,意会知识
它指的是那些你会做,但很难完整说出来的经验。
比如你知道这张发票看起来怪怪的。你知道这个客户招待费用需要提前问老板。你知道这个供应商付款不能直接走普通采购。你知道某个表格字段虽然没写必填,但实际上每次都要填。你知道有些费用在制度里没明说,但财务一定会打回来。
这些知识平时不显眼。因为你自己已经习惯了。只有当 Agent 做错的时候,你才会突然发现:
原来这条规则我没写进去。所以 SOP 不可能一次写完。正确的方法是双向开发。
流程大概是这样:
第一轮,你先用自然语言告诉 Agent:
“我平常大概是这样审核报销的,请你帮我整理成一份 SOP。”
Agent 写出第一版。然后你拿它跑一批真实报销单。跑完一定会发现问题。
比如它把所有餐饮发票都归类成普通餐费,没有识别出客户招待。
这时候你就回头补一条规则:
如果费用说明中出现客户、拜访、商务沟通、合作方等关键词,并且发票类型为餐饮,Agent SHOULD 标记为客户招待候选项,并检查是否存在事前审批和招待对象说明。
下一轮再跑。
又发现它把跨项目费用分错了。
再补一条:
如果报销说明中出现多个项目名,Agent MUST 标记needs_clarification = true,并要求提交人确认费用归属。
再跑。
可能又发现它没有识别电子发票重复提交风险。
再补一条:
Agent MUST 根据发票号码、金额、开票日期与历史记录进行重复风险检查;无法查询历史记录时,MUST 标记为人工确认。
就这样一轮一轮修。每一次出错,都是在把你脑子里的默会知识挖出来。几轮之后,SOP 会越来越稳定。
不是因为第一版写得完美,而是因为你用真实执行结果持续反向修复它。
这也是很多团队做 Agent 落地时最大的误区。他们花两个月写一份所谓“完美 SOP”。结果第一次跑就崩。
因为里面覆盖的都是想象中的情况,真正业务里会发生的问题反而没写进去。
更好的方式是:
先写一个粗糙版本。尽快跑起来。用真实案例测试。发现问题就补规则。用迭代速度换稳定性。
Agent Workflow 不是一次性交付出来的。它是跑出来、修出来、磨出来的。
第四步:接入真实工具,并设计人工确认点
前面三步完成后,你已经有了一套比较清楚的流程。
但它还只是“会写”的流程。
要让它变成真正能执行的 Agentic Workflow,还需要接入真实工具。
在报销的例子里,工具可能是:
企业微信、钉钉、飞书审批或公司OA系统。发票识别接口。报销制度知识库。员工信息表。项目预算表。财务系统。历史报销记录。金蝶、SAP或其他 ERP 系统。
如果没有这些工具,Agent 只能停留在“给建议”。接上工具之后,它才有机会真正完成任务。这也是 MCP 这类协议重要的原因。
MCP 可以理解成一种让 AI 连接外部工具和数据源的标准接口。
它的目标是让不同 AI 应用,用相对统一的方式连接工具、资源和工作流。
有一个简单且形象的比喻:
MCP 有点像 AI 世界里的 USB-C。
过去,不同模型、不同工具、不同系统之间,经常需要单独适配。
每换一个平台,就要重新写一套连接方式。
而 MCP 想解决的,就是这种重复集成的问题。
当然,接工具之后还有一个更重要的问题:
哪些地方必须让人来确认?
任何 Agentic Workflow,只要进入真实业务,就不应该完全放飞。
高风险动作之前,Agent 必须停下来。
比如:
涉及大额付款。涉及客户退款。涉及管理员权限。涉及删除数据。涉及对外发送正式邮件。涉及合同、法务、合规风险。涉及对客户的价格、疗效、交付周期等承诺。
这些动作不能让 Agent 自己猜。它可以准备材料、给出建议、生成草稿、列出风险点。但最后一步要让人确认。
一个成熟的 Agentic Workflow,不是让人完全退出。
而是把人放在最关键的决策点上。
重复、机械、确定性的事交给 Agent。高风险、模糊、需要责任判断的事留给人。这才是现实可用的协作方式。
套到真实业务:AI客服怎么做?
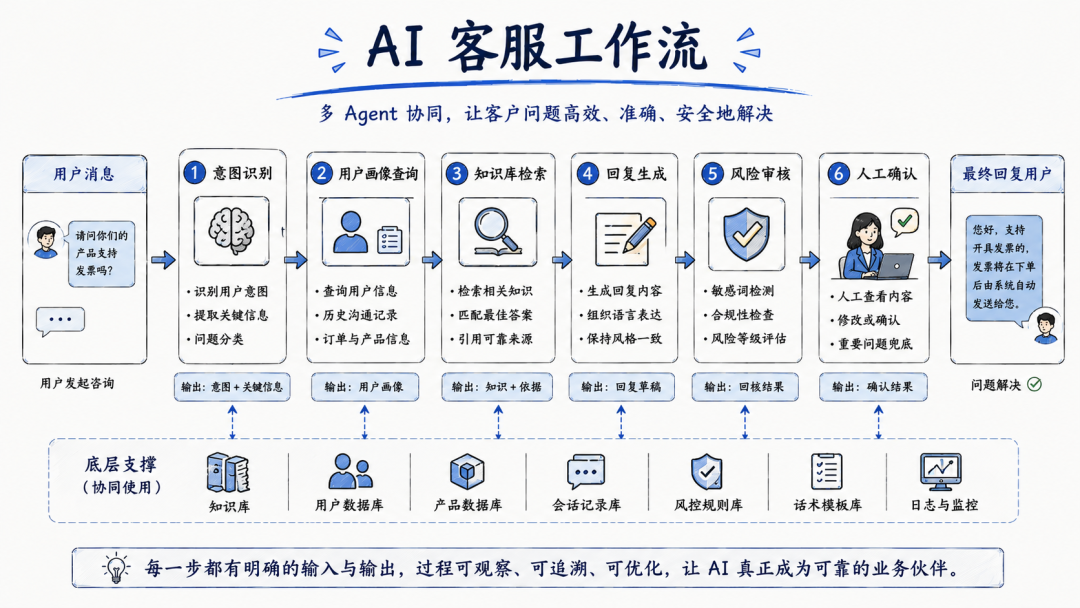
客服是公司与用户之间的重要桥梁,每天都会有人从不同渠道进来咨询:
企业微信。小程序客服。平台店铺。直播间。社群消息。
内容可能是:
“这个产品多少钱?”“我这种情况适合那款产品吗?”“有没有优惠?”“跟其他规格有什么区别?”“你们公司这么多XX产品,我该买哪款?”“这个产品用了以后真的有效果吗?”
这些消息本身不复杂。但数量一多,就很烦。因为你每天都要看、判断、分类、回复、打标签、分配销售、提醒跟进,还要避免客服说错话。这类流程非常适合改造成Agentic Workflow。
我们用前面的四步走一遍。
Step 1:标准化 SOP
先把原来靠人脑判断的流程,写成一份清晰的 SOP。
比如这份 SOP 叫:用户意图识别
它的输入可能包括:
• 用户原始消息
• 来源渠道
• 历史对话
• 用户标签
• 是否购买过
• 咨询产品
• 当前活动政策
• 售后规则
• 法规约束
它的规则可以这样写:
MUST:
• 必须识别用户意图:价格咨询、产品咨询、售后问题、投诉、优惠咨询、购买意向、无效消息。
• 必须判断是否需要转人工。
• 必须检查回复中是否包含不允许承诺的内容。
• 涉及退款、投诉、医疗/功效承诺、合同承诺时,必须进入人工确认。
• 必须输出结构化结果。
SHOULD:
• 应该根据历史对话判断用户意向强度。
• 应该根据用户问题匹配知识库答案。
• 应该根据用户阶段推荐下一步跟进动作。
• 应该识别用户是否需要先被安抚,而不是马上推销。
MAY:
• 可以生成一个简短回复草稿。
• 可以推荐销售跟进话术。
• 可以给用户打标签。
• 可以生成后续跟进提醒。
输出格式可以规定为 JSON:
{“intent”:”价格咨询”,
“lead_level”:”中意向”,
“needs_human”:false,
“recommended_action”:”发送价格说明并补充价值差异”,
“draft_reply”:”这个要看您选择的版本和使用周期,我先简单帮您说明一下……”,
“tags”:[“价格敏感”,”待转化”],
“risk_flags”:[]}
这样一来,Agent 不再是凭感觉处理客户消息。
它有了明确的输入、规则和输出。
Step 2:拆成多个 Skill
接下来,不要让一个 Skill 处理所有事。
可以拆成几个更清楚的 Skill:
第一个Skill:用户意图分类
负责识别用户意图、判断消息类型和紧急程度。输入是用户原始消息和历史对话。输出是意图分类 JSON。
第二个Skill:用户档案查询
负责查询用户标签、购买记录、历史沟通记录。输入是用户 ID。输出是用户画像摘要。
第三个 Skill:知识库/营销库查询
负责匹配产品知识库、营销活动、售后规则。输入是用户意图和用户画像。输出是可引用的知识点和限制条件。
第四个 Skill:用户回复话术
负责生成回复草稿。输入是意图分类、用户画像和知识库结果。输出是对用户可见的回复文本。
第五个 Skill:法规审核
负责检查回复是否存在风险。比如有没有夸大效果、有没有越权承诺、有没有触碰敏感词、有没有和当前政策冲突。
第六个 Skill:跟进计划
负责生成后续动作。比如打标签、分配销售、设置提醒、进入人工处理。
这几个 Skill 各做各的事。
如果意图分类错了,只改分类规则。如果回复口吻不好,只改回复草稿规则。如果法规检查漏了,只补法规规则。如果跟进策略不准,只调整线索分层和跟进规则。
这就是模块化的好处。
Step 3:用真实对话迭代
第一版写完后,不要急着上线。拿真实客户对话跑。你很快会发现问题。
比如:
- 用户问“多少钱”,直接报价格,但没有解释价值差异。
- 用户说“我考虑一下”,直接误判成低意向,其实对方只是想等活动。
- 用户问“有没有效果”,回复太满,存在合规风险。
- 用户发了一段抱怨,没有先安抚,直接开始解释规则。
- 用户已经买过,却又按新客户话术推了一遍。
这些问题都很正常。关键不是第一版不能错。关键是每次出错,都能知道是哪一段错了。
持续迭代三五轮之后,整个流程会越来越稳定。它不会一开始就变成一个完美客服。但它会逐步变成一个能帮你分担大量重复工作的 AI 助手。
Step 4:接入真实系统和人工确认点
最后,把工作流接到真实系统里。
比如:
从企业微信、小程序客服或表单读取消息。查询用户标签和历史记录。检索产品知识库和营销策略。生成回复草稿。写回客服系统。必要时提醒销售跟进。涉及风险时停下来等人确认。
比如:
涉及退款, 涉及投诉, 涉及价格特殊优惠, 涉及功效承诺转人工普通产品咨询,可以自动生成回复草稿。低风险常见问题,可以自动建议回复。
这样一来,原本每天都要人工重复处理的客户咨询,就变成了一条可运行、可观察、可修复的 Agentic Workflow。
它不是全自动魔法。 但它可以先帮你节省 30%-50%-70%的重复工作。
而且最重要的是: 你知道它每一步在做什么。
再举一个内容场景:制作一个 生成公众号长文的Workflow
算了,字太多了。上一篇文章完读率不超过3%
结尾
很多人现在学习 AI,还是停留在“怎么问 AI”。
怎么写 prompt。怎么让模型输出更好。怎么让回答更像人。怎么让它帮我写文案、做总结、生成代码。
这些当然有用。
但它们很快会变成基础能力。因为模型会越来越强,上下文窗口会越来越大。
未来更有价值的能力,是另一件事:
把一个真实流程,拆成 AI 能理解、能执行、能检查、能迭代的工作流。
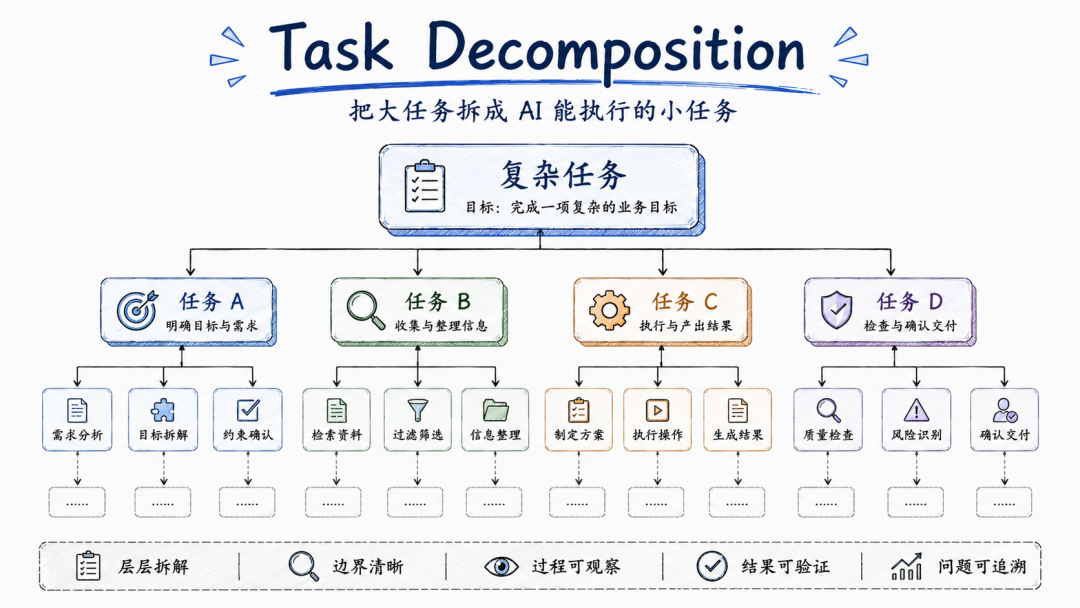
这件事听起来没有那么炫酷。但它更接近真正的生产力。因为 AI 真正进入业务,不是靠一句神奇 prompt。而是靠一条条可执行的 workflow。你不需要一开始就把所有流程都自动化。那样只会把自己搞死。
你可以从一个最小的地方开始。找一份你手上最无聊、最重复、最不想做的 SOP。
可能是每周周报。可能是发布前 checklist。可能是报销材料汇总自动化。可能是需求反馈整理→AI自动分析产出方案。
然后按四步走:
第一步,把它标准化。第二步,把它拆成节点。第三步,用真实执行结果反向修 SOP。第四步,接入工具,并设计人工确认点。
不要一开始追求完美。先做一个能跑起来的版本。哪怕只能省 30% 时间,也值得。
而且你构建好这些基础agent或者Workflow后。再去使用Openclaw和Hermes。那可就太妙了
你会从搭一条不断复用、不断迭代的工作流,升级成去构建一个AI助手
写在最后
Agent 时代,很多人会下意识追求“更强的模型”。
但真正决定效果的,往往不是模型强不强,而是你有没有把任务拆清楚,基础的原子能力有没有构建起来。
未来会用 AI 的人,未必是最会写 prompt 的人。
而是最会拆任务、写流程、定边界、做迭代的人。
前者半年就可能过时。
后者会越来越值钱。
本文由 @流窜AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









‘老员工靠经验判断’,这正是Agent做不好的地方。经验如果不能显式化,系统就只能靠猜。
任务拆解后,每个节点都需要单独维护规则和脚本。如果业务变化快,规则更新跟不上,反而容易产生新的不一致。这也是一个实际成本。
很多团队一上来就追RAG、多Agent,却忽略了最基础的任务拆解。把Human SOP直接丢给AI,结果靠猜。真正能跑的业务系统,得把大任务拆成一个个边界清晰的Skill,每个只干一件事,出错了才好修。