
 起点课堂会员权益
起点课堂会员权益GPT-image2深度复盘:3000+次调用总结的生图经验!
掌握AI模型的核心特性是产品经理打造优质AI产品的关键。本文深度解析GPT-Image2生图模型的应用技巧,从提示词设计到性能优化,揭秘3000+次调用实战经验。你将学习如何规避常见尺寸错误、提升生成稳定性,以及通过中转站策略将成功率提升至96%的实战方法论。

“一个出色的AI产品经理或者vibe coder,一定是充分的了解并深度的使用模型的人!”这是我一直以来的观点,因为产品经理和普通的使用AI的用户不同,产品经理是要运用模型缔造产品的,所以你对模型的理解和使用的上限,决定了你做出来的产品能力上限。
所以不管是对我自己,或者是对身边想要学习转型AI产品的同学,我都有一个建议,必须深入的去看官方对于模型的说明文档和技术文档,并且在使用模型的过程中摸清楚模型的脾气和特点。
至今为止,目前有2个模型是我在自己开发的产品中高频的调用,一个是gemini 3.1 Pro,另一个是生图模型GPT-Image2,每个模型的个人调用生成的次数,应该累计不低于3000次,今天这篇打算深度的复盘一下自己这段时间对GPT-image2这个模型的理解和使用经验,这也是我在开发点赞AI这个图文笔记创作AI工具的这段时间解决了不少技术问题的过程中积累下来的经验,它有两个作用:
- 对于想要将image2引入到自己的产品中,实现更好的生图效果的产品经理,或者vibe coding的通过,可以帮助大家更深入的了解这个模型,将image2应用到不同的场景中,解决具体的问题;
- 对于普通人而言,可以更深度的懂得怎么设计提示词,让image2生成出自己想要的设计作品。
以下内容总结来自两部分来源:
- 3000多次使用,以及调试了很多次生图提示词,解决了很多生图技术问题后总结;
- 详细的解读OpenAI的官方说明文档,以及结合自己的使用经历总结,官方文档链接:
https://developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide
1.生图提示词设计经验:怎么更好的和image2对话,获得想要的生成结果?
1.遇到过的问题

在开发点赞AI这个产品的过程中,我有一个实现场景,要将一段3000字以上的文本,一次性批量生成8~10张小红书封面卡片,在这个过程中,我高频的遇到如下几个生成异常的问题:
- 图片尺寸经常出现问题:比如小红书官方的尺寸比例是3:4,但是模型经常会生成出1:1的卡片,一开始我一直把这个问题归咎于模型不稳定导致的,其实后来研究才发现并不是,实际上是因为自己要求的尺寸不合理导致的;
- 生成结果的质量有时好,有时差:这个问题我也经常遇到,同样一段提示词,输入A文本内容的时候生成结果很完美,输入B文本内容的时候,就出现各种异常问题,然后就再次的把问题归咎于模型不稳定,官方算力调整等原因,其实也并不是。
- 同时提供多个垫图的时候,模型容易混淆图片的用户:比如我上传了3张图,其中一张要作为封面风格复刻的参考图,另外2张是作为插图放到封面里面,生成结果经常会搞错,比如风格参考了错误的那张;
2.提示词经验总结
1.image2的生图尺寸是有特定要求的

这点可能很多人都不知道,比如可能就有人在生图的时候要求输出4000×4000这种尺寸的图片,门外汉看不出问题,内行人一看就知道有问题,根据OpenAI中关于image2的官方说明,image2的输出尺寸是有特定要求的,相关要求如下:
- 最长边必须小于3840px,所以刚刚举例提到的4000×4000这种尺寸就明显不对;
- 两条边都必须是 16 的倍数;
- 长边:短边 ≤ 3:1
- 总像素 ≤ 8,294,400(≈4K)
- 总像素 ≥ 655,360
另外官方还分享了一个经验,一旦尺寸超过 2560×1440(≈3,686,400 像素,也就是”2K”)生成结果就容易不稳定,因此生成尺寸限定在 ≤2K(≈3.69M 像素)就是一个比较”可靠区间”,一旦结果设置为2K~4K ,生成结果则”能出但容易飘“。
基于以上这几点,就可以理解前面自己遇到的问题的原因,比如生成的尺寸不是3:4,很可能是因为自己除了限定了比例,也限定了具体的尺寸,比如1500×2000(问题:尺寸不是16的倍数);以及生成结果质量不稳定,有可能是因为输入的文本内容太长,导致展示的内容尺寸被迫撑大超过2K,超过2K的时候,就容易不稳定。
因此,在设计提示词的时候,输出尺寸必须要遵循以上规则,否则就容易出现这那的问题;
2.提示词结构建议:
- 采用md或者json格式;
- 内容结构可以按照“背景/场景 → 主体或目标 → 关键细节 → 限制条件”这样的组合结构撰写提示词;
- 适当的采用带标签的段落或换行,不要采用长段落;
3.在提示词中注明预期的用途
比如生成图片是用于广告、UI模型、信息图,会有利于提高生成结果准确性;
4.在提示词中标明quality的level 值
包括low、medium、high,这三个会影响画质,当然也影响生成速度,对于文字密集,信息比较多的场景,可能用medium、high更好;
5.多图输入情况下:通过索引和描述引用每个输入(“图像 1:产品照片……图像 2:样式参考……”),并描述它们如何交互(“将图像 2 的样式应用于图像 1”),比如前面我提到的多个垫图情况下模型容易混淆的问题,通过这个方式就可以解决;
6.善用n参数,控制生成方案数量;
7.不要把判定规则写到提示词中,尽量减少生图模型里面的推理负担
举个例子,比如我之前有一版生图的提示词,要求模型根据生成宫格的数量(四宫格或九宫格等)判断输出尺寸,不同的宫格输出不同的尺寸,我一开始的做法是把整个规则表放到提示词里面让模型自己判断应该输出什么尺寸。
但是这种方式导致的结果就是生成尺寸经常出问题。后来我换了一个方式,改成通过程序自己先确定输出的宫格数量和尺寸,然后直接通过参数的方式,将宫格数量和生成的尺寸直接透传插入到提示词里面,这个方式的生成结果相比之前的方式稳定了很多。
8.一个通用小技巧:优化提示词最简单直接的方式就是,把如下这段官方的要求发给模型,让模型根据这个的要求,帮你修改你的提示词。
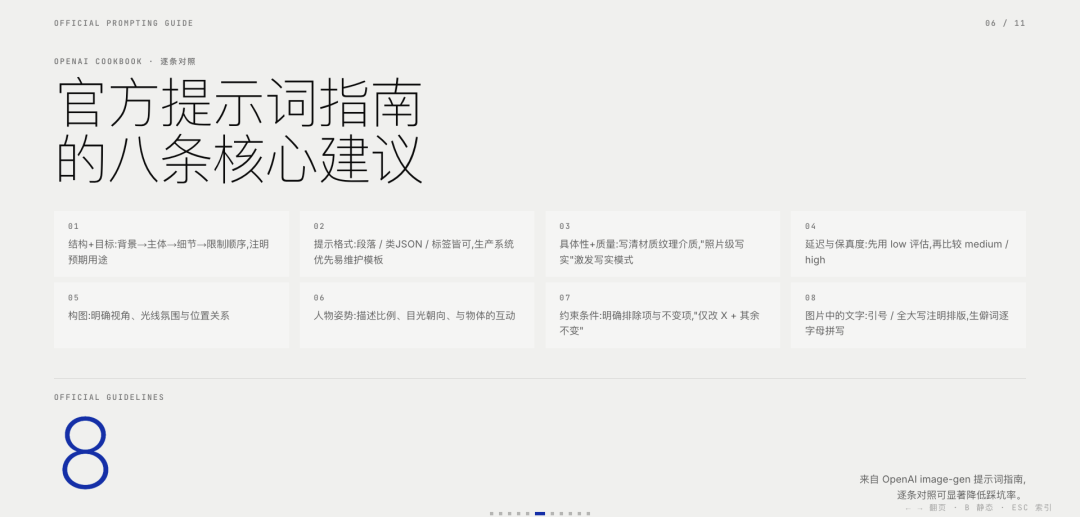
以下为image2的官方提示词建议:
结构+目标:提示语应按一致顺序编写(背景/场景 → 主体/目标→关键细节→限制条件),并注明预期用途(广告、UI模型、信息图),以确定“模式”和润色程度。对于复杂的需求,请使用简短的带标签的段落或换行符,而不是一个长段落。
提示格式:使用最易于维护的格式。只要意图和限制清晰,简洁的提示、描述性的段落、类似JSON的结构、指令式的提示以及基于标签的提示都可以很好地发挥作用。对于生产系统,应优先考虑易于浏览的模板,而不是复杂的提示语法。
具体性+质量提示:明确描述材质、形状、纹理和视觉媒介(照片、水彩、3D渲染),仅在必要时添加针对性的“质量控制点”(例如,胶片颗粒、纹理笔触、微距细节)。对于照片级写实效果,直接在提示中包含“照片级写实”一词,以强烈激发模型的写实模式。类似“真实照片”、“使用真实相机拍摄”、“专业摄影”或“iPhone照片”等短语也有帮助,但详细的相机规格可能会被随意解读,因此主要用于营造整体视觉效果和构图,而非精确的物理模拟。
延迟与保真度:对于对延迟敏感或高容量的应用场景,请先quality=”low”评估其是否满足您的视觉需求。在许多情况下,它能够在显著提高生成速度的同时提供足够的保真度。对于小字或密集文本、精细的信息图表、特写肖像、涉及身份信息的编辑以及高分辨率输出,请medium在high发货前进行比较。
构图:
明确构图和视角(特写、广角、俯视)、透视/角度(平视、低角度)以及光线/氛围(柔和漫射光、黄金时段、高对比度)以控制拍摄效果。如果布局至关重要,请注明位置(例如,“标志位于右上角”、“主体居中,左侧留白”)。
对于广角、电影感、弱光、雨景或霓虹灯场景,请添加关于比例、氛围和色彩的额外细节,以免模型为了追求表面真实感而牺牲氛围。人物、姿势和动作:对于场景中的人物,请描述其比例、身体构图、目光以及与物体的互动。例如:“全身可见,包括双脚”、“相对于桌子来说像个孩子”、“低头看着打开的书,而不是看着镜头”,或者“双手自然地握住车把”。这些细节有助于展现人物的身体比例、动作几何以及目光方向。
约束条件(哪些需要更改,哪些需要保留):明确说明排除项和不变项(例如,“无水印”、“无额外文字”、“无徽标/商标”、“保留标识/几何/布局/品牌元素”)。
对于编辑操作,请使用“仅更改X”+“保持其他所有内容不变”的规则,并在每次迭代中重复保留列表以减少偏差。如果编辑需要精确到极致,还应说明不要更改饱和度、对比度、布局、箭头、标签、相机角度或周围对象。
图片中的文字:
将文字用引号括起来或全部大写,并指定排版细节(字体样式、大小、颜色、位置)作为约束条件。
对于难以辨认的词语(品牌名称、不常用拼写),逐个字母拼写出来以提高字符准确性。
对于小字、信息密集的面板和多字体布局,请使用高亮显示medium或高质量显示。
high多图输入:通过索引和描述引用每个输入(“图像1:产品照片……图像2:样式参考……”),并描述它们如何交互(“将图像2的样式应用于图像1”)。合成时,明确指出哪些元素移动到哪里(“将图像1中的鸟放到图像2中的大象身上”)。
迭代而非重复:冗长的提示固然有效,但从一个简洁的基础提示开始,然后通过小的、每次只做一项修改的后续提示(例如“让光线更暖”、“移除多余的树”、“恢复原始背景”)进行细化,会更容易调试。使用“与之前相同的风格”或“主题”之类的参考信息来利用上下文,但如果提示开始偏离主题,则需要重新指定关键细节。
综合以上的这些要求,写一个如下提示词作为示例,该示例基本汇总了以上需要关注的提示词设计注意事项:
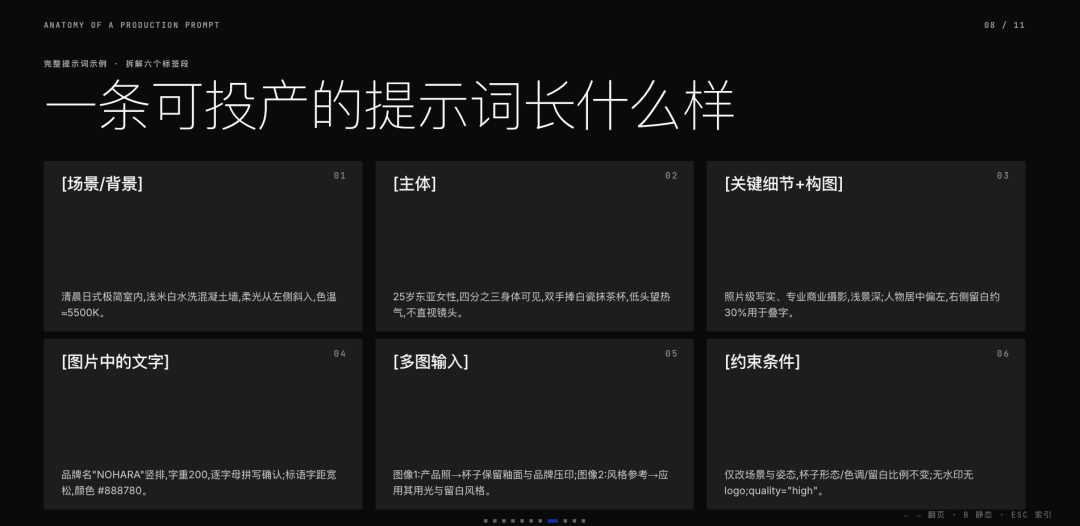
用途:社交媒体品牌广告图,尺寸1080×1600px[场景/背景]清晨的日式极简室内空间,浅米白色水洗混凝土墙面,柔和漫射自然光从画面左侧斜入,无强硬阴影,整体色调偏暖(约5500K)。
[主体]一位25岁左右的东亚女性,四分之三身体可见(含双手与手腕),双手自然捧住一只白色哑光陶瓷抹茶杯,低头望向杯中冒出的热气,不直视镜头。身穿宽松米白色麻质上衣,发型简单束起。
[关键细节]
-视觉媒介:照片级写实,使用真实相机拍摄,专业商业摄影
-材质与纹理:陶瓷杯表面细腻哑光釉面,杯口有少量抹茶粉末残留; 女性手部皮肤自然,可见毛孔细节,无过度修饰
-景深:浅景深虚化背景,对焦点落在杯口与女性下半面部
[构图]平视角度,人物居中偏左,右侧留出约30%画面宽度的干净留白用于文字叠加;画面下方留出约10%底部边距。
[图片中的文字]
-品牌名:「NOHARA」置于右侧留白区上方,竖向排列, 细线无衬线字体(字重200),字号约为画面高度6%,颜色 #2C2C2A 拼写逐字确认:N-O-H-A-R-A,共6个字母-标语:「EVERYSIP, A STILLNESS」置于品牌名正下方, 字号更小,字间距宽松,颜色 #888780
[多图输入]
-图片1:NOHARA 产品官方照(白色陶瓷杯正面) → 将此杯作为女性手中所持的杯子,保留杯子的形态、釉面质感和杯身品牌压印
-图片2:风格参考图(日本 MUJI 系列广告大片) → 将图片2的用光方式、低饱和暖色调和构图留白风格应用到本次生成 → 保持图片1的产品可识别性完全不变
[约束条件]
-仅改变场景环境和人物姿态——保持图片1杯子的形态、品牌压印、釉面颜色完全不变
-保持图片2的色调、饱和度和用光逻辑不变-无水印、无额外文字、无商标 logo、无道具摆拍感
-不改变构图留白比例,不改变人物面部朝向(始终低头不直视镜头)
-人物面部自然真实,无过度美颜,无滤镜感quality=”high”
2.如何提升image2生图的速度、流畅度、成功率?
生成时间、流畅度、失败率的问题,也是我在开发点赞AI的过程中经常遇到,而且很头疼的问题,比如我经常会遇到图片生成了十几分钟都没有生成出来的问题,以及生图失败率比较高的问题。
这几点困扰了我很久,直到最近特意花了点时间研究了一下,总算能很好的解决这个问题,平均一批图片生成的时间从5~10分钟,提升到2分钟以内,生图成功率从80%提升到96%,总结经验如下:
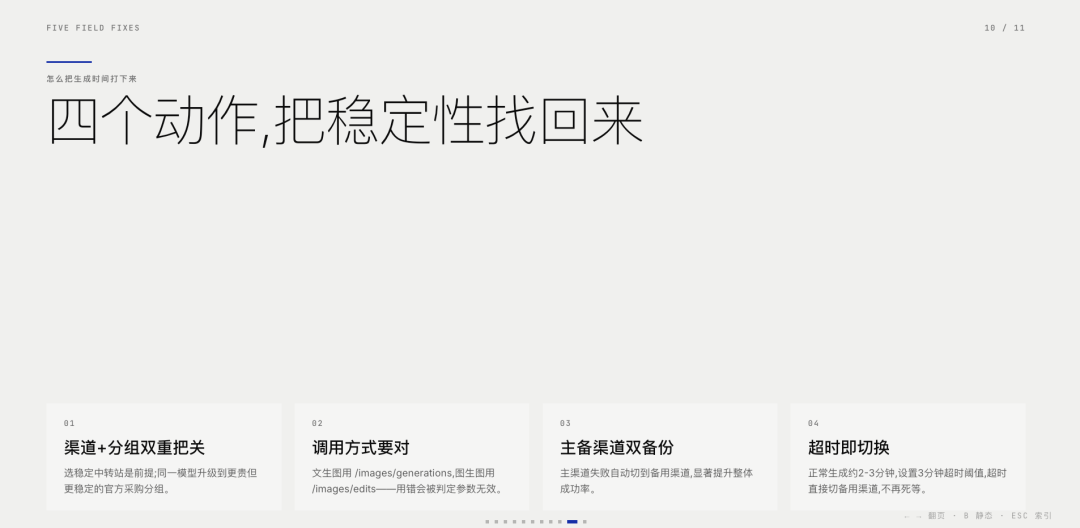
挑选稳定和可靠的中转站:这个是前提,有些中转站本来就不稳定,生成的失败率容易很高,并且速度也比较差,所以挑选好的渠道中转站是第一件事,关于中转站的挑选相关的问题,后面我会单独写一篇,这里先不细细展开;
采用合适的生图模型调用方式:比如之前有一段时间,我的生图产品的失败率非常高,出现了高频的失败的情况,生成速度也很慢,后来细查原因才发现是模型的调用方式不对导致的,这个也是官方调用方式的一些限制要求,目前image2的官方调用方式有两种:
方式一:采用/images/generations的调用方式,该方式是适合文生图模式;
方式二:采用/images/edits,该方式适合图生图模式;
我之前出现的问题就是,图生图的模式,使用了/images/generations的调用方式,所以中转站那边高频的反馈无效参数问题;
模型使用更加稳定的分组资源:熟悉中转站的同学一定比较了解分组这个东西,简单讲,中转站的每一个模型,都有指定的分组,不同的分组的可以理解为模型资源的来源,有些资源是渠道通过官方渠道薅羊毛的,比较便宜,有些资源是走官方渠道正经采购的,会贵一些,但是比较稳定;所以在模型分组上添加更贵的分组,可以一定程度上解决以上问题。
采用多个中转站渠道备案的方式:因为中转站渠道经常容易出现限流而不稳定的情况,因此备用多几个中转站渠道就很有必要,而且在渠道的调用机制上,可以设置主渠道和备用渠道,一旦主渠道调用失败,就切备用渠道,由此可以提升生成结果的稳定性和成功率;
设置超时切换备用渠道的调度方式:前面提到了主渠道和备用渠道的逻辑,但是什么时候切换备用渠道,这里也有一些讲究,正常模型如果生成成功或者失败,渠道是会有response信息响应的,但是很多时候,渠道出现了问题,该响应一直处于loading状态,渠道没有返回响应信息,就会导致一直处于生成中状态无限loading;
这时候可以设置一个超时的逻辑,一旦超过指定时间,即使没有response信息,也直接切换备用渠道。根据个人经验,目前稳定的渠道image2的生成时间通常是2~3分钟左右,超过3分钟,一般就是调用失败,所以超时时间可以设置3分钟。
3.了解image2能应用于哪些生图场景?
这个也是你在只用image2的时候必须知道的事情,而且必须看官方公开的生成演示案例,说白了,模型是人家提供的,能生成什么,官方说的最有代表性,相应的,没有哪一个模型是万能的,通过这些信息,也能知道模型的能力边界情况。
根据官方公开的资料显示,image2可以适合如下应用场景的生成。
1.将高信息密度的文本内容生成可视化图表
比如如果是官方示例的生成效果:
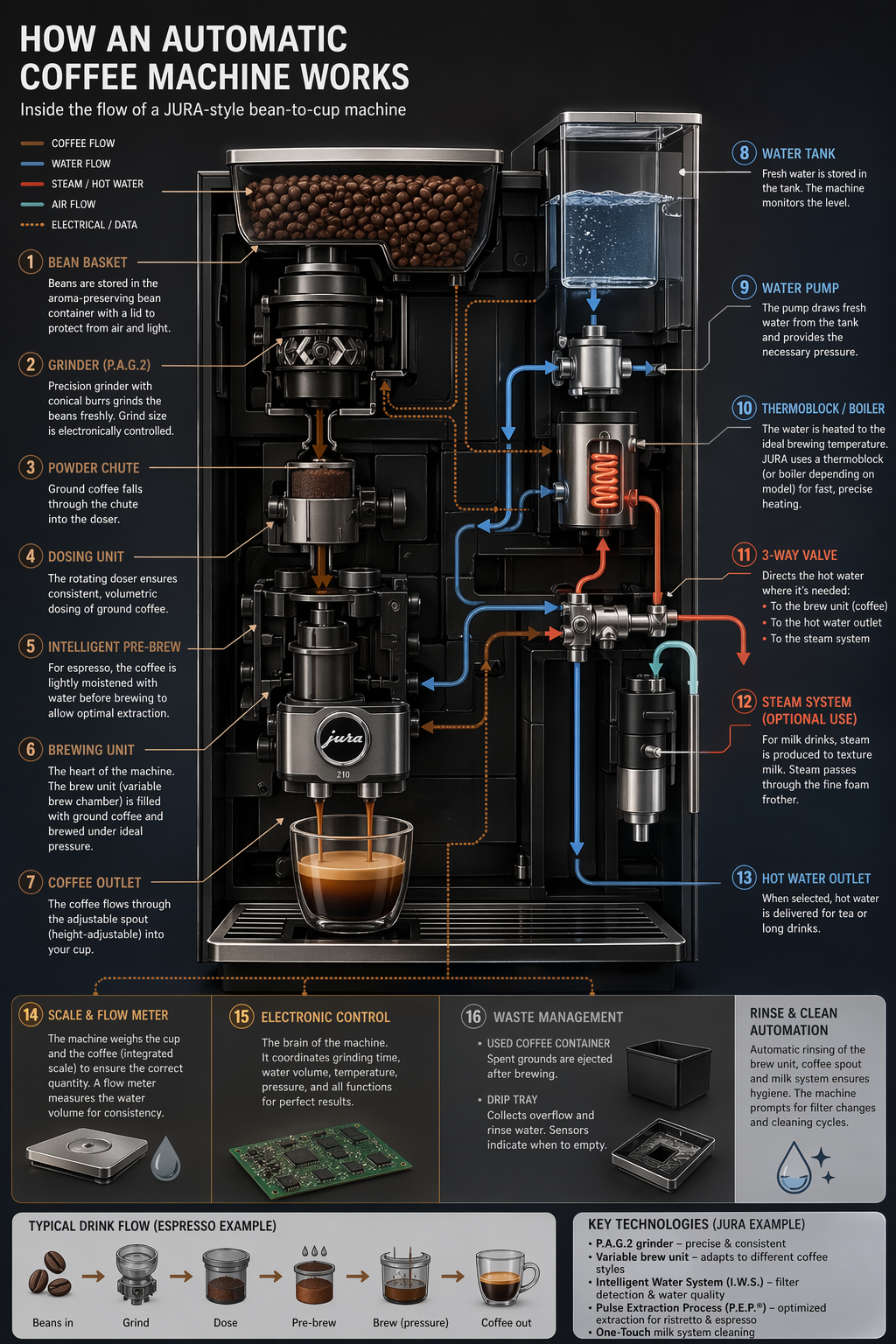
2.图片翻译:该场景很适合PPT翻译的场景,用户的需求是保持PPT原本的设计,然后将文字进行翻译
其关键效果在于可以保留除文本以外的所有内容,包括保持字体样式、位置、间距和层级的一致性——同时逐字逐句地准确翻译,不添加任何多余的词语,除非必要,否则不进行重排,并且不会对徽标、图标或图像进行任何意外的修改,除了PPT翻译的场景,还可以用于将现有设计(广告、用户界面截图、包装、信息图表)本地化为另一种语言,而无需从头开始重建布局。
3.生成带真实的相机拍摄参数的实拍效果图
image2支持你提供使用摄影术语中的镜头、光线、构图等相关的描述,你甚至可以把摄影中的参数(包括光圈、K值、快门等)告诉模型,模型帮你渲染出效果图,同时还可以明确要求展现真实的纹理(毛孔、皱纹、衣物磨损、瑕疵)等。

4.需要世界知识的生成场景
GPT图像生成模型能够将强大的推理能力与世界知识相结合,也就是说,有很多东西,你可能不需要告诉模型背景,它自己也能知道,比如你让它生成特朗普的形象,它知道特兰普是谁,也知道他长什么样子;
5.故事漫画集、视频画板、视频切片
image2具备很强的一致性能力,所以可以用它生成故事画集,视频的切片和分镜等;

6.逻辑图:将文本信息,通过逻辑图、流程图的方式展现出来
7.单页PPT生成
除了生图,image2也是一个很不错的PPT生成模型,除了编辑不太方便,现在image2生成的PPT效果一点都不比那些专业的PPT生成工具差;
8.风格复刻和迁移的功能
参考某一个图片的风格,生成相似风格的卡片,这个已经是我非常高频的在使用的一个能力。
9.虚拟服装试穿
比如你可以提供商品图和模特,然后生成试穿效果;

10.图像消除/抠图:image2还支持传统的图像编辑的能力,包括抠图和消除功能;

OK, 以上便是这段时间总结的关于image相关的知识和经验,其实有很多信息,OpenAI的官网都已经公开了,并且我其实也已经是第三次复习这个官网的内容。
前面两次因为只是了解为主,没有代入实际的使用经验,所以没有太大的共鸣,随着使用的次数越来越多,以及经历的问题越来越多,才发现,官方公开的这些经验信息,就是最好的学习素材,外面那些所谓的AI高手们,基本分享内容也不会超过这个框架,所以总结起来:官方解读+应用实操,就是最好的学习方式。
我打算在第三次学习之后,接下来深度的使用这些掌握的经验,除了解决目前我开发的产品的问题,也希望能增加更多的能力到产品中。
作者:三白有话说,公众号:三白有话说
本文由 @三白有话说 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议









那个把规则表从提示词里移出来放到程序逻辑处理的优化,确实能大幅降低模型的推理负担,类似的做法在调用其他API时也是通用技巧。
是的,这个其实是一种意识,道理都很简单,但我们经常会不注意的在提示词做很多判断逻辑