
 起点课堂会员权益
起点课堂会员权益如何通过三个信息来源辅助大模型选型:Benchmark、Arena AI与 OpenRouter 的分工与边界
模型版本更新比产品迭代还快,但大多数对选型的讨论还停留在"谁的分数高"。
跑分高不等于用起来好,用起来好不等于能落地——这三件事,分别对应三套完全不同的评估逻辑:Benchmark 看能力边界,Arena 看用户真实偏好,OpenRouter 看生产环境里的实际使用情况。
本文不推荐具体模型,只做一件事:把这三个信息源拆清楚,说明它们各自在回答什么问题、有什么盲区,以及怎么组合使用才不容易踩坑。

大模型慢慢变成了产品里的标配,但”选哪个模型”这件事,说实话一直没有特别清晰明确的方法。不是模型太少了,而是评估信息太分散。有人拿benchmark说话,有人靠Arena排名,还有人看谁的调用量高——每一种说法都有道理,但放在一起又互相冲突。
问题不在于信息不够多,而在于这三类信息根本不是在回答同一个问题。搞清楚它们各自在说什么,才能知道什么时候该看哪个。
一、能力评估:Benchmark 解决的是“模型能不能做”
Benchmark 是最传统的一类模型评估方式,核心是通过标准化测试集来衡量模型在特定任务上的能力,例如数学推理、知识问答、代码生成等。从产品视角看,它回答的是一个基础问题:模型是否具备完成某类任务的能力上限。
这类方法的优势在于结构清晰、结果可量化,并且便于横向对比不同模型版本。例如同一任务下,模型A与模型B在准确率上的差异,可以较直观地反映能力差距。

但它的问题也同样明显:首先是“考试化偏差”。Benchmark 本质上是固定题库,而大模型训练数据的覆盖范围极广,很难排除数据污染的可能性。模型在某些 benchmark 上表现优异,并不必然意味着它具备真实泛化能力。
其次是与真实任务的脱节。产品中的任务往往是开放式的、多轮的、包含上下文和工具调用的,而 benchmark 更接近“单点答题”,很难反映复杂系统能力。
因此,从产品决策角度,Benchmark 更适合作为“能力上限参考”,而不是选型依据。
二、体验评估:Arena回答的是“用起来感觉怎么样”
第二类信息来源是以 Arena AI平台为代表的人类偏好评估体系。这类方法的核心机制是盲测:用户在不知道模型来源的情况下,对不同模型输出进行比较,并基于主观体验投票。
与 benchmark 不同,这一类评估更接近真实使用体验,因此它在产品选型中具有独特价值。从结构上看,这类评估已经不再局限于“聊天能力”,而是拆分为多个任务维度,包括:
- 文本对话(chat)
- 搜索增强任务(search)
- 代码生成与调试(code)
- 网页开发(webdev / image-to-webdev)
- 文档理解(document)
- 图像生成与编辑(image)
- 视频生成与编辑(video)
- 以及逐渐加入的 agent 类任务
这意味着它本质上是在评估一个更复杂的问题:模型在不同任务类型下的主观表现质量。

它的优势在于:首先,它反映的是人类真实偏好,而不是抽象指标。这使得它在“写作质量”“表达自然度”“指令遵循程度”等方面具有较强参考意义。其次,盲测机制在一定程度上减少了品牌偏见,使不同模型可以在相对公平的条件下比较。
它的局限同样明显:一方面,评估任务本身分布并不等同于真实生产环境。复杂的企业级任务,例如长链路 agent 执行、多轮工具调用稳定性、或高约束 RAG 系统,在这类评测中往往覆盖不足。另一方面,评审机制本质上仍然是主观的,容易受到回答长度、表达风格等因素影响,而这些因素并不一定等价于真实任务质量。
因此,Arena 更适合用来判断“用户体验层面的表现”,而不是系统能力结论。
三、生产数据:OpenRouter 反映的是“模型在现实中是否被使用”
第三类信息来源是基于 API 调用与真实应用行为的数据统计,例如 OpenRouter 所展示的模型使用情况、调用量、延迟表现以及工具调用能力等。
与前两者不同,这一类数据更接近生产环境本身,它关注的不再是“模型理论能力”或“用户主观偏好”,而是一个更现实的问题:模型在真实产品中是否被采用,以及使用成本与稳定性如何。
常见指标包括:
- 模型调用量(usage / tokens)
- 不同任务类别分布(chat / code / reasoning / multimodal)
- 推理与工具调用能力(tool calls)
- 延迟表现(fast models / latency)
- 上下文长度能力(context length)
- 在真实产品中的集成情况(top apps)
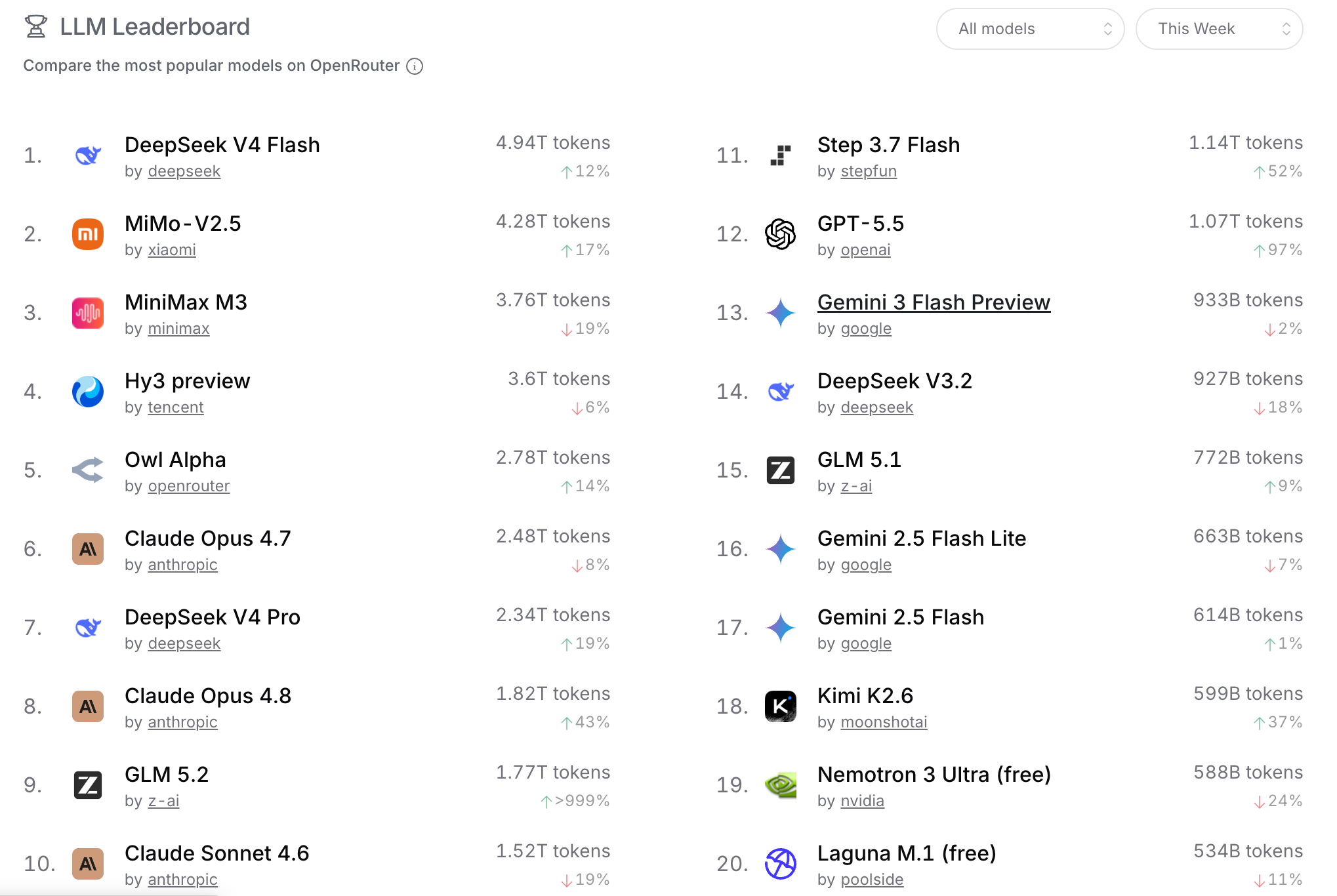
从产品角度看,这类数据的价值在于它提供了“真实选择结果”。用户和开发者在实际业务中如何使用模型,往往比评测分数更能反映综合权衡。
但它也存在明显限制。首先是“分发偏差”。某些模型使用量高,并不一定意味着能力最强,而可能是因为价格更低、接入更容易,或被设为默认选项。其次是“生态影响”。模型在平台中的可见度、推广策略、以及集成成本,都会影响使用量数据,使其不完全等价于能力排名。
因此,生产数据更适合用来判断模型的“工程落地能力”,而不是纯技术能力排序。
四、三种信息来源的关系
如果从产品决策的角度来看,这三类信息其实对应的是三个不同层面的问题:
- Benchmark:模型“能不能做”
- 体验评估:模型“用起来怎么样”
- 生产数据:模型“在现实中是否被用”
它们之间并不是替代关系,而是互补关系。单独依赖任何一种信息,都容易在选型中产生偏差:只看 benchmark 容易高估实验室能力,只看 Arena 容易忽略工程约束,只看生产数据又可能被生态分发和价格策略影响。
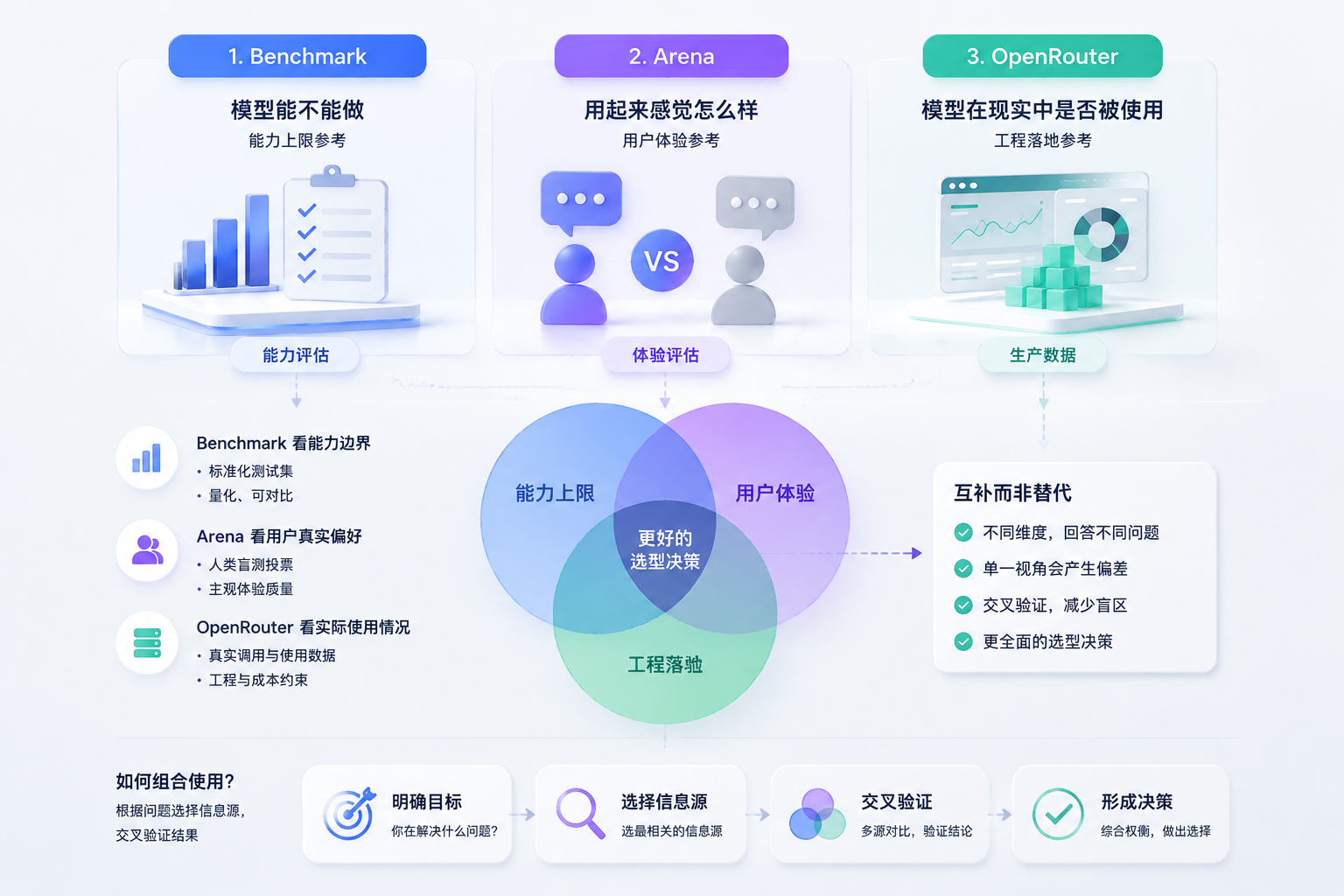
更关键的一点是,这三类信息并不是必须同时使用的,而是可以根据具体的调研目标进行选择。不同阶段、不同问题,应该选用不同的信息来源来支撑判断。例如,当你关注的是“模型是否具备某种能力边界”时,benchmark 是更直接的参考;当你评估的是“用户实际体验是否更好”时,Arena AI类评测更有意义;而当你在做“是否可以在生产环境落地以及成本是否可控”的决策时,生产数据与工程指标会更接近真实约束。
换句话说,这三类信息更像是三种不同的观察工具,而不是必须同时开启的仪表盘。在实际工作中,关键不在于“收集更多信息”,而在于“选择正确的信息来源来回答当前的问题”。
在具体的产品决策过程中,更合理的方式是:根据问题类型选择信息源,再在多个信息源之间交叉验证结果,而不是用单一指标去解释所有问题。
五、结语
大模型选型从来都不是一道有标准答案的题目。
Benchmark 会被刷,Arena 会受风格偏好影响,生产数据会被价格和生态扭曲。每一种信息来源都有盲区,这不是缺陷,而是现实。
真正的问题从来不是”哪个模型最好”,而是”对我的业务来说,什么是好”。
这三类信息源的价值,不在于给你一个答案,而在于帮你把模糊的直觉,变成可以被拆解、被验证、被质疑的判断。
能力上限、用户体验、工程落地——把这三件事搞清楚,选型就不再是拍脑袋,而是一个可以被推导的过程。
本文由 @WB 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









这个分类框架很实用,尤其提醒自己别只盯着benchmark,很多团队内部评估时往往把跑分当唯一标准,忽略了用户真实感受。