
 起点课堂会员权益
起点课堂会员权益定制化企业级知识图谱的6点经验
知识图谱项目的真正挑战,远不止于构建一张复杂的网络。当面对十几万篇分散的文档时,核心问题转向了知识如何有序进入系统、如何被结构化治理与复用。本文深度拆解运营商知识图谱实践中的六大关键环节,从准入判断到AI抽取边界,从规则挂接到证据链验证,揭示如何将杂乱知识转化为可调用的业务资产。

最近我们在做一个运营商的知识图谱项目,越做越觉得,很多人对图谱的期待其实放错了地方。
大家一听“知识图谱”,脑子里很容易出现一张很酷的网:节点很多,关系很多,点开一个产品,旁边连着套餐、权益、活动、规则。
但真正做下去你会发现,问题根本不在“这张网画得够不够复杂”。
知识图谱真正难的地方,不是把知识连起来,而是让知识有秩序地进入系统。
如果只是把文档丢给大模型,切片、向量化、问答,走通识类的图谱模板,短期看起来也能跑。用户问一个问题,系统找一段相关文档,再生成一个答案。Demo 阶段通常还挺像那么回事。
但当知识库里有十几万篇文档,来源分散在不同系统、不同省份、不同业务线,事情就变了。
这时候你要问的已经不是“这一次能不能答出来”,而是:
这条知识是什么类型?它和哪个产品有关?现在还有效吗?和现有规则有没有冲突?能不能被客服、Agent、RAG 系统稳定复用?
这才是我们做图谱的真正原因。
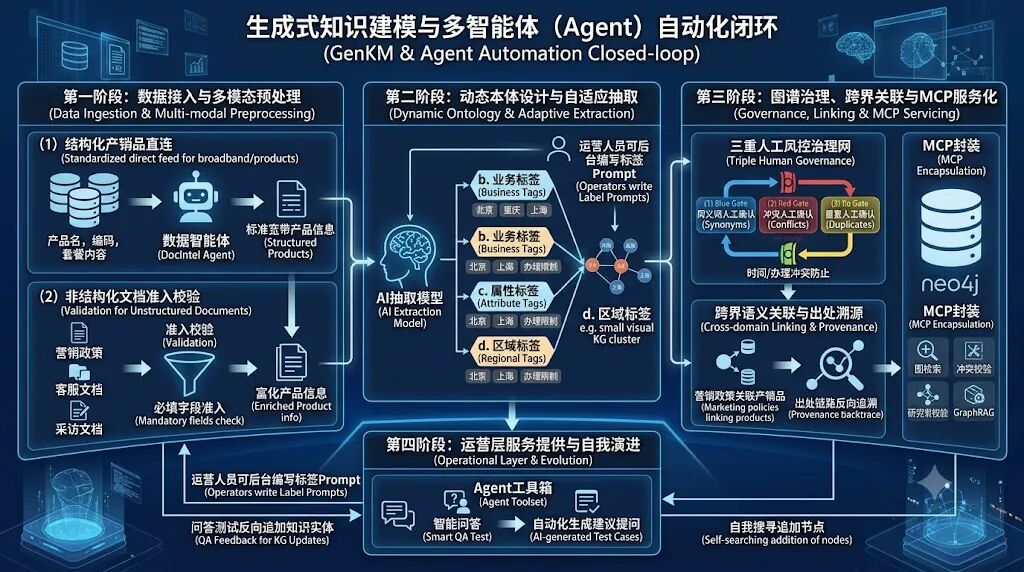
一、第一步不是建图,而是先判断什么能进来
我们现在接触到的知识,大体可以分成两类。
一类是产销品知识,比如宽带、套餐、终端、权益包。这类数据通常来自系统接入,本身就有比较标准的字段:产品名、产品编码、套餐内容、资费说明、办理规则、上下架状态。
这类知识天然比较适合生成图谱。因为它本来就有骨架,图谱更多是在把骨架补齐。
真正麻烦的是另一类:文档类知识。
营销政策、客服文档、采访纪要、活动方案、培训材料……这些东西散落在各个系统里,格式不统一,颗粒度也不统一。有的文档只讲一个产品,有的文档讲一个活动,有的文档里同时塞了多个产品、多个规则、多个时间限制。
这类文档不能直接“进图谱”。它必须先过一道准入。
所谓准入,不是判断这篇文档有没有价值,而是判断它应该按什么方式被治理。
比如一篇营销活动文档,不能只抽一个“活动名称”。它至少要看活动时间、适用地域、适用客群、适用产品、办理渠道、活动规则、权益内容、互斥规则。
少了这些,图谱看起来有节点,但到了真正问答和业务判断时,还是会漏。

二、AI 可以发现线索,但规矩不能交给它自己定
到了抽取阶段,AI 很有用。
它可以从非结构化文档里发现实体、关系、规则和条件。比如它能看出这是一篇活动文档,里面有活动时间、适用地域、奖品权益、互斥条件。
但这里有一个分寸特别重要:AI 可以自由发现,不能永远自由发挥。
我们现在的做法,是把 AI 的发现能力和业务标签体系结合起来。系统里可以维护业务标签、属性标签、区域标签,每个标签后面都有对应的抽取说明和 Prompt。
但标签不是终点,标签只是入口。
系统判断一篇文档是“活动类”,这只是第一步。真正重要的是:活动类文档到底应该抽什么?活动名称、活动时间、适用客户、适用地域、办理渠道、参与规则、互斥规则、奖品、有效期,这些才是后续可治理的字段。
权益包类文档也是一样。它要抽的不是一个泛泛的“权益包”,而是权益内容、资费、有效期、领取方式、生效规则、变更规则、退订规则。
AI 负责发现,业务负责定规矩。
让 AI 看到什么抽什么,最后会得到一堆漂亮但不可控的字段。人工提前把所有类型写死,又会跟不上业务变化。更实际的方式,是先让 AI 帮你发现高频模式,再由业务侧把关键字段沉淀成标准抽取规则。
三、文档图谱最关键的一步,是把规则挂回产品
我们系统里的图谱生成,其实分两条线。
产销品图谱比较直接。产品主数据本身就比较结构化,可以根据产品数据生成。
更难、也更有价值的是文档图谱。因为很多业务规则不在产品主数据里,而藏在各种营销政策、客服口径、活动方案里。
举个例子,某个产品本身只是一个套餐。但一篇营销活动文档里可能写了:哪些用户能参加活动,哪些套餐档位对应哪些合约,活动什么时候开始结束,哪些合约互斥,奖品有效期多久,办理渠道在哪里。
这些信息如果只停留在文档切片里,问答时偶尔也能答出来。
但它很难稳定地关联到具体产销品下面,也很难做冲突检查、重复识别和规则治理。
文档图谱的目标,不是给文档单独画一张图,而是把文档里的规则挂回业务对象。
活动、规则、限制、权益、渠道、时间,最后都要能回到具体产品、具体客户、具体地域、具体有效期上。
这一步里,人工确认不是低效,而是必要的业务闸门。
多个营销文档时间重叠、产品办理限制不一致、活动规则互相覆盖、同一个产品在不同地市口径不同——这些问题,不能靠一句“AI 已抽取”就直接入库。

四、问答测试要看答案,更要看证据链
图谱建完之后,我们会做问答测试。系统会让 AI 生成建议问题,用来快速验证图谱能不能支撑真实问答。
但这里真正要看的,不只是答案对不对。
更重要的是:这个回答关联了哪些节点?用了哪些关系?证据来自哪些文档切片?有没有遗漏关键条件?有没有把不同文档的规则串错?有没有把过期活动当成有效活动?
比如用户问:某个杭州用户能不能参加一个幸运转盘活动?
好的系统不能只回答“可以”或“不可以”。它应该能把判断链路摊开:活动时间是否有效,地域是否匹配,用户是否属于适用客群,套餐档位是否符合,是否存在互斥活动,抽奖机会是否还在有效期内。
图谱问答的价值,不是生成一句答案,而是把答案背后的判断过程交代清楚。
五、图谱质量,不能只数节点和关系
很多图谱项目喜欢报节点数量、关系数量。这个指标当然能看,但它很容易让人产生错觉。
节点多不一定好,关系多也不一定准。
真正要评估的是:实体有没有归一,字段是否完整,关系有没有挂对对象,规则有没有证据,冲突有没有被识别,重复有没有被合并,答案能不能追溯,图谱能不能随着业务变化迭代。
尤其是文档类知识,不可能一次建完就结束。业务会更新,活动会过期,套餐会上下架,政策口径会变化。
图谱如果不能演化,很快就会变成一张漂亮但过时的图。
所以我们也在做图谱的自我演化:当问答过程中发现某个实体节点不够用,系统可以回到知识库里重新搜索、补充候选节点,再进入审核流程。
注意,这不是让 AI 悄悄改图谱。
AI 负责发现缺口,真正入库仍然要走治理流程。
六、图谱最后应该变成一种可调用的能力
做完图谱之后,还有很关键的一步:MCP 封装。
如果把图检索、冲突校验、跨节点推理能力封装成 MCP 服务,客服系统、智能 Agent、RAG 应用、运营工具都可以直接调用它。
到那个时候,图谱就不是“展示用的图”,而是企业知识能力的一部分。
它可以回答问题,可以做资格判断,可以检查规则冲突,可以辅助产品推荐,可以支撑客服口径,也可以让不同 Agent 调用同一套可信知识。
这也是我们为什么不满足于普通 RAG。
普通 RAG 解决的是“从文档里找答案”。知识图谱解决的是“让知识被结构化治理、持续复用、稳定推理”。
前者像临时翻资料,后者更像建立一套业务操作系统。
所以,这套流程真正想做的,不是把十几万篇文档都画成一张复杂的网。
它想解决的是另一件事:
让每一条重要知识都知道自己是谁、从哪里来、和谁有关、什么时候有效、能不能被信任、能被谁调用。
知识图谱的终点,不是图。
是让知识从杂乱材料,变成可以被组织、被验证、被调用的业务资产。
本文由 @是AD 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 unsplash,基于CC0协议









规则挂接这一步确实关键,很多业务的约束条件都散落在文档里,不挂回产品,问答时就容易漏掉互斥或时效条件。能做到冲突检查和规则治理,图谱价值就能真正释放。