
 起点课堂会员权益
起点课堂会员权益用几块钱的麦克风听出百万设备故障——一个工业 AI 产品从 0 到 1 的需求拆解与设计决策复盘
本文从一个工业声纹 AI 产品的实际构建经历出发,拆解工业 AI 产品在跨越 PMF(Product-Market Fit)过程中的需求定义、架构抉择与冷启动策略,希望为同样在 B 端硬核赛道上探索的产品人提供一些可复用的思考框架。

一、一个被忽视了太久的巨大市场
麦肯锡在《工业 4.0:数字化制造再思考》中给出过一个被广泛引用的数字:全球制造业每年因非计划性停机造成的直接经济损失超过 500 亿美元,关键工业资产单次意外停机的中位数损失高达每小时 12.5 万美元。
这个数字很惊人。但更惊人的是,面对如此明确的痛点,绝大多数中小型制造企业仍然在用最原始的方式应对——靠老师傅的耳朵听、靠手背摸温度、靠定期巡检碰运气。不是他们不知道”预测性维护”这个概念,而是现有方案的价格标签直接把他们拦在了门外。
传统压电振动监测系统,单测点 5,000 到 20,000 元,整套系统动辄 50 万元起步,还需要停机打孔安装传感器、聘请专业工程师调试。对一家年营收 5,000 万、利润率 8% 的机加工厂来说,这套系统的投入产出比根本算不过来。
据国家统计局与工信部数据,我国规模以下中小型制造企业超过 380 万家,其中绝大多数仍依赖人工巡检。这是一个规模超过 600 亿元的年度市场,却被供给侧长期忽视。
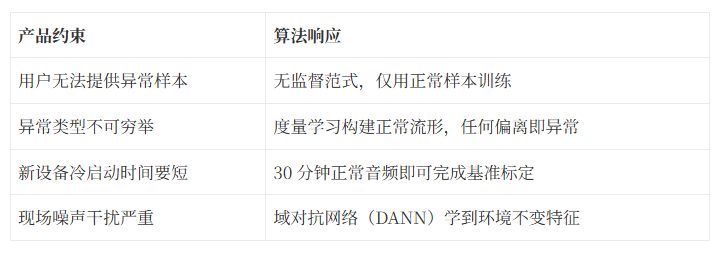
我们团队在做工业声纹 AI 产品”谛听”的过程中,反复直面一个核心问题:工业 AI 产品如何同时做到“用得起、用得了、用得懂”? 这三个字不是口号,而是层层递进的产品约束——解决不了”用得起”,后两个根本没有机会被验证。
接下来,我将从需求拆解、架构抉择、算法选型、冷启动策略四个层面,复盘我们在这个过程中做过的关键产品决策。需要声明的是,以下分析仅代表我们团队在特定约束下的选择,并非唯一正确答案,欢迎同行探讨。
二、需求拆解:从行业痛点到产品定义
2.1 传统 PdM 方案的三个隐性假设
深入分析现有预测性维护方案后,我们发现它们实际上建立在三个对中小企业不成立的隐性假设之上:
假设一:客户付得起单测点万元级的硬件成本。 传统压电传感器(如 SKF 的 CMPT 2310)单个售价数千至万元,一个中型车间 50-100 个测点的硬件投入就超过 50 万。对年利润 400 万的中小企业,这占到了年利润的 12.5%。
假设二:客户能承受停机安装的代价。 压电传感器需要打孔固定在设备外壳上,安装过程必须停机。对于 24 小时连轴转的产线,哪怕 4 小时的停机窗口都很难协调。
假设三:客户能提供足够的异常样本用于模型训练。 这是最容易被忽视的致命问题。工业设备的运行特性决定了它 99.9% 的时间运转正常,异常样本极度稀缺且不可穷举——你不可能把所有可能的故障类型都预先”拍”一遍。传统有监督分类方案在这里先天失效。
三个假设,没有一个对中小企业成立。这不是”功能不够好”的问题,是整个产品范式对目标用户群不匹配。
2.2 用户故事还原:设备科长的一天
与其讨论抽象的市场需求,不如还原一个真实用户场景。
张工,某机加工厂设备科科长,管着厂里 80 多台设备。每天早上 7 点到车间,先花一小时巡检——手摸外壳温度、耳听轴承异响、眼看油位计。他心里清楚,这种巡检漏检率极高,上次 3 号线主轴内壁划痕就是巡检没发现,结果运转了三周后抱轴停产,直接损失 12 万。
他听说过”预测性维护”,也看过展会上 SKF 的方案。但回来一算账:80 个测点 × 8,000 元/点 = 64 万硬件 + 每年 15 万维保,厂长直接把报告打回来了。更让他头疼的是安装要停机,产线排程排不出窗口。
这就是目标用户的真实处境:需求强烈、支付能力有限、容错空间极窄。
2.3 从痛点到产品定义
基于上述分析,我们推导出的产品定义不是”工业声纹监测系统”,而是三个可验证的产品约束:
- 成本约束:单测点硬件成本必须控制在 300 元以内(传统方案的 1/20)
- 部署约束:零停机、非接触、5 分钟内完成单点部署
- 数据约束:模型训练仅需正常运转样本,不依赖异常数据采集
注意这三个约束的关系——成本和部署约束推导出了”用麦克风替代压电传感器”的感知方案选择,数据约束推导出了”无监督学习”的算法范式选择。产品定义不是功能列表,是约束的集合。 约束越清晰,后续的架构和算法选择就越不依赖拍脑袋。
三、架构抉择:端-边-云解耦背后的产品逻辑
我们最终选择了端-边-云三级解耦架构:MEMS 麦克风阵列作为感知终端(端),工控机上的轻量推理引擎作为边缘网关(边),SaaS 多租户中台作为决策中心(云)。
这个架构不是技术自嗨,而是被用户场景的硬约束一步步逼出来的。让我逐层拆解背后的决策逻辑。
3.1 为什么不能全上云?
最常见的质疑是:都 2025 年了,为什么不直接把音频数据传到云端做推理?
答案藏在工厂的网络基础设施里。我们走访的中小型制造企业,车间里的网络环境大致有三类:Wi-Fi 信号时断时续、4G 信号被金属厂房屏蔽严重、部分产线区域根本没有网络覆盖。如果推理依赖云端,一次网络波动就可能导致漏报——而漏报一次的代价可能是一台设备报废。
更重要的是延迟。工业异常从萌芽到恶化可能在毫秒到秒级完成,云端推理的 RTT(往返时延)在 200-500ms 区间,加上排队和模型推理时间,总延迟可能达到秒级。对于需要”第一时间截断”的预警场景,这个延迟是不可接受的。
产品决策:核心异常检测必须在本地完成,网络只是传输结果,不是传输前提。
3.2 为什么边缘推理而非嵌入式推理?
既然要在本地做,为什么不把推理直接塞进传感器节点(比如 ESP32 微控制器)?
我们评估过这条路。ESP32-S3 双核 240MHz,内存 512KB SRAM + 8MB PSRAM,跑一个 INT8 量化后的 ResNet-18 前向传播理论上可行,但实际测试中,内存峰值达到 37MB——ESP32 完全吃不下。更关键的是,一旦模型需要升级或替换,嵌入式 OTA 的稳定性在工业现场很难保证。
所以我们选择了”传感器只负责采集、边缘网关负责推理”的分工。传感器节点(BOM 约 185 元)只做 I2S 音频采样和蓝牙/Wi-Fi 传输,推理放在车间的工控机或普通 PC 上——每台工控机服务 20-30 个传感器节点,ONNX Runtime 单次推理 1.85-4ms,完全满足实时性要求。
产品决策:感知与推理解耦,传感器做极致的”便宜可靠”,推理下沉到车间级网关。这是成本、算力、可维护性的三维最优。
3.3 为什么还要云?
如果边缘已经能完成异常检测,云端存在的意义是什么?
三个场景决定了云不可或缺:
- 跨厂区管理。 一个中大型厂区可能有 3-5 个车间,管理层需要的是全局设备健康看板,不是每个车间独立的一座孤岛。
- LLM 智能诊断。 这是我们认为最关键的差异化环节——传统工业 AI 的终极痛点不是”报不出警”,而是”报了警工人看不懂”。时频波形、频谱图、异常评分……这些对数据科学家有意义,对一线维修工毫无可操作性。我们将大语言模型接入云端,把声学异常数据自动转译为”白话”式故障诊断与维修工单——”3 号线主轴轴承内圈疑似早期剥落,建议 72 小时内停机检查,优先检查内滚道表面”。
- 数据沉淀与模型迭代。 随着装机量增长,跨品类、跨工厂的工业声纹数据库将持续反哺模型优化,形成数据飞轮。
产品决策:边缘做实时守门员,云端做战略参谋。端负责感知、边负责决策、云负责洞察——每一层存在的理由都是一个明确的用户场景。
3.4 架构选择的方法论提炼
回过头看,整个架构决策可以归纳为一个原则:架构不是技术选型,是产品约束的映射。

如果你也正在做 B 端硬核产品的架构设计,不妨先问自己:我的每一个架构层级,对应哪个用户场景?如果答不上来,那这一层大概率是在为技术而技术。
四、算法选型的产品思维:ArcFace 为什么不是”炫技”
4.1 工业异常检测的核心悖论
工业 AI 领域有一个被严重低估的悖论:你永远无法穷举设备所有可能的故障模式。
想象一下:一台离心泵正常运转的声音你录了 1000 小时,但你如何预先录到”轴承内圈剥落初期”的声音?更不用说”叶轮微裂纹””密封环偏磨”这些你甚至想不到的故障形态。传统有监督学习要求每种故障都有标注样本,这在工业现场是根本不现实的。
这不是数据量的问题,而是数据分布本身的特性——工业数据是极端长尾的,尾部你无法预知也无法覆盖。
4.2 有监督 vs 无监督:不是学术选择,是产品选择
很多团队在做工业 AI 产品时,会先走”有监督分类”的路——采集数据、标注、训练、部署。这条路在实验室里跑得通,一旦到现场就会发现:每个新客户、每台新设备、每种新工况都需要重新标注和训练,交付成本指数级上升。
我们从一开始就选择了无监督异常检测(Unsupervised Anomaly Sound Detection, UASD)路线。核心逻辑是:只用正常样本训练,任何偏离“正常流形”的声音都是异常。 这样无论出现什么未知的故障类型,只要它导致了声纹偏移,就能被捕获。
这是产品层面的决策——我们不追求”识别出是哪种故障”(这在 MVP 阶段是过度设计),而是先做到”发现异常、发出预警、争取处置时间”。故障分类是后续迭代的事,但异常检测是当下必须解决的核心需求。
4.3 ArcFace 的跨界逻辑
在确定无监督路线后,算法选型面临另一个问题:如何用正常样本构建一个足够鲁棒的”正常流形”?
我们最终引入了 ArcFace(Additive Angular Margin Loss)——一个来自人脸识别领域的度量学习方法。这个选择背后的逻辑链是:
- 人脸识别的核心问题是“区分不同人的脸”——在嵌入空间中让同一人的特征聚拢、不同人的特征推远
- 工业异常检测的核心问题是“区分正常与异常的声音”——在嵌入空间中让正常样本聚拢、异常样本被排斥
- ArcFace 的角惩罚机制(Additive Angular Margin)恰好可以强制正常工况特征向类中心收缩,对任何频域偏离施以几何级排斥
这个”跨界移植”的效果在国际公开工业声学评测基准 MIMII Dataset 上得到了验证:平均 AUC 92.78%,较传统自编码器基线提升 20 个百分点以上,在公认最难的阀门(Valve)类别上 AUC 达到 97.41%。
4.4 从产品视角看算法选型
我想强调的不是 ArcFace 本身有多新潮,而是算法选型背后的产品思维:
好的算法选型,本质上是让用户无感地绕过数据瓶颈。
我们的目标用户是中小企业设备科长张工,他不可能为你标注异常样本,甚至可能说不清楚”异常”到底有多少种。ArcFace + 无监督范式的产品价值在于:张工只需要让设备正常运转 30 分钟,系统就能自动建立健康基线,之后出现的任何异常都会被捕获——无论他见没见过这种故障。
如果算法选型让用户的使用门槛反而变高了(”请先采集 50 种故障样本”),那这不是 AI 赋能,是 AI 负债。
五、冷启动策略:BOM 200 元的”硬件截流”逻辑
5.1 为什么硬件不赚钱也要铺?
我们最终的单节点 BOM 控制在约 185 元,销售定价 500-800 元。硬件毛利率看起来不低,但如果把研发分摊、库存成本、售后支持算进去,硬件层几乎不赚钱。
为什么要这样做?
核心逻辑是:在“硬件 + SaaS”的复合商业模式中,硬件不是利润中心,是获客漏斗的入口。
SaaS 业务的单位经济学本质上是 LTV vs CAC 的游戏。在工业场景中,传统销售方式的 CAC 极高——你需要拜访客户、做现场演示、拉 POC 周期,一个成单可能需要 3-6 个月。如果硬件本身就能以极低价格进入客户现场(500 元一个节点,试错成本极低),它本质上就是最低成本的获客渠道。
用一组数字来说明:传统工业 AI 方案的单客户 CAC 约 2-5 万元(销售人力 + 展会 + 演示),我们的硬件截流策略将 CAC 压缩到约 4,700 元,而单客户 3 年生命周期价值(LTV)约 30,090 元,LTV/CAC 比值约 6.4 倍,远高于 SaaS 行业 3 倍的健康线。
5.2 “4 步当天上线”如何降低决策门槛
冷启动的另一个关键是降低客户的决策负担。我们设计了”4 步当天上线”的标准化交付流程:
- 现场勘测(1 天内):规划设备点位
- 磁吸安装(单点 5 分钟):无需停机、无需打孔
- 基准标定(30 分钟):采集正常运转声纹,一键建立健康基线
- 功能激活(次日可用):基础监控开箱即用,专业版 30 天免费试用
这个流程的设计原则是:让客户的每一次行动都对应一个即时可感知的结果。 不是”三个月后你能看到效果”,而是”今天装上、今天就能看到声纹波形、明天就收到第一条预警”。
5.3 增长飞轮的设计
冷启动之后,增长飞轮如何转动?
我们的设计是”标杆案例 → 行业白皮书 → 渠道代理”的三级加速:
第一阶段(1-12 月):3-5 家标杆客户,以半价或免费部署,核心目标是沉淀可对外公开的行业白皮书与 ROI 数据
第二阶段(13-24 月):白皮书驱动同业转化 + 与工业设备维保商建立渠道代理(按订阅金额 20-30% 分成)
第三阶段(25-36 月):标准化行业解决方案模板(机加工/化工/水务三套),全国复制
关键洞察是:工业客户的核心决策依据不是你的技术多先进,而是“和我同行业、同规模的企业用了之后效果如何”。 标杆案例不是营销素材,是产品本身的一部分。
六、收尾:工业 AI 产品的三个产品原则
回过头总结,我们在整个产品构建过程中,始终围绕三个递进的产品原则做决策:
- 用得起——成本降两个数量级。单节点 BOM 185 元 vs 传统方案 5,000-20,000 元。不是”便宜一点”,是”便宜到客户可以不需要审批就下单试试”。
- 用得了——零停机部署、无监督泛化。5 分钟磁吸安装、30 分钟基准标定、断网可用。不是”能用”,是”比你现在靠耳朵听还省事”。
- 用得懂——LLM 把报警翻译成工单。不是输出一个 0-1 的异常分数让工程师去猜,而是直接告诉一线维修工”建议 72 小时内停机检查主轴轴承内圈”。AI 的终点不是”检测准确”,是”可执行”。
做工业 AI 产品,最危险的不是技术实现不了,而是做出了一个技术上完美、但目标用户根本用不起、用不了、用不懂的东西。让 AI 回归工具本质——这大概是我们做这个产品学到的最重要的一课。
本文由 @苏淋 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









您好,第一次在这里看到同行业的文章,我现在正在做的也是这个行业的产品,利用温振的数据,希望可以和大佬交流下。VX:c100147258