
 起点课堂会员权益
起点课堂会员权益手把手教你用kano模型做需求分析
编辑导语:Kano模型是一款对用户需求分类和优先排序的有用工具,利用Kano模型来做产品需求分析,能有效地提高整体的效率以及更好地分析用户需求,本篇文章作者介绍了用kano模型做需求分析的方法内容,一起来学习一下吧。

产品经理日常工作中,经常会遇到来自业务方、运营、BOSS、及自己日常体验总结的各种各样的需求,这些需求交付到自己手中时也会伴随着各种各样“有理有据”的原因。
那我们该如何处理这些需求,且对这些需求进行优先级划分,就需要使用一些需求分析方法来解决。
Kano模型就是一个可以帮助我们有效识别“真伪需求”、划分需求优先级的有效工具。
Kano模型是东京理工大学教授狩野纪昭(Noriaki Kano)发明的对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。
一、意义
KANO模型是一个典型的定性分析模型,一般不直接用来测量用户的满意度,常用于识别用户对新功能的接受度。
有助于产品经理了解不同层次的用户需求,主要是通过标准化问卷进行调研,根据调研结果对各因素属性归类,解决需求属性的定位问题,以提高用户满意度。
二、具体内容
根据不同的需求内容与用户的满意度关系,可以将kano模型的内容具体分为五类,此处根据我们产品上常用的话术概况为【五点】。
1. 基本型需求——痛点
也称必备型、理所当然的需求,是给用户对服务方提供的基本要求。
基本型需求没有达到时用户会表现的很不满意,但是即便做的再好,用户也不会因此有更多的好感。
2. 期望型需求——痒点
期望型需求与用户的满意度成比例关系,即期望型需求满足的越多,用户的满意度越高。
此需求不会像基本型需求那么苛刻,但此需求得不到满足时用户的不满感也不会像基本型需求那样显著增加。
3. 魅力型需求——兴奋点
又称兴奋型需求,不会被用户过分期望的需求。随着不断满足用户的兴奋型需求,用户的满意度也会不断的增加,即便表现的不完善,用户的满意程度也是非常高的。
反之用户的期望不满足时,顾客也不会表现出明显的不满意。
4. 无差异型需求——无关紧要点
不论提供与否,对用户体验无影响的需求。
5. 反向型需求——膈应点
又称逆向型需求,指引起强烈不满的质量特性和导致低水平满意的质量特性,因为并非所有的消费者都有相似的喜好。
许多用户根本都没有此需求,提供后用户满意度反而会下降,而且提供的程度与用户满意程度成反比。
三、使用方法
1. 明确目标
首先需要明确调研的目的是什么?kano模型是否适用,为什么要用kano模型去解决。
这点就需要再次回顾其意义,这里是帮助解决需求属性的定位问题,属于定性分析,定量分析问题无法用kano模型去处理。
2. 设计调查问卷
KANO问卷中每个属性特性都由正向和负向构成,或者说一个问题需要设置正反2个不同的子问题,分别测量用户在面对具备或不具备某项功能所做出的反应。
问卷中的问题一般采用五级选项,按照:喜欢、理应如此、无所谓、勉强接受、我不喜欢,进行评定,因为用户对于一个事情的感知是渐变,不是突变的(描述词语可以根据场景具体定义,但是根据模型内容需要设置五级选项)。
需要注意的是这里的五级并不是跟一一上面模型分级对应,仅仅是针对某一项内容的五种不同的梯度态度,避免在下面数据统计时疑惑。
在问卷设计时,把问卷尽量设计得清晰易懂、语言尽量简单具体,避免语意产生歧义。
同时,可以在在问卷中加入简短且明显的提示或说明,方便用户顺利填答,例如:
- 喜欢:让你感到满意、开心、惊喜;
- 理应如此:你觉得是应该的、必备的功能/服务;
- 无所谓:你不会特别在意,但是可以接受;
- 勉强接受:你不喜欢,但是可以接受;
- 我不喜欢:让你感到不满意。
例如:在微信中消息中,是否需要增加【视频通话】功能?问卷需要设置正反两题:
1)正向:如果我们在微信消息中,提供【视频通过】功能,你的感受是:
- 喜欢;
- 理应如此;
- 无所谓;
- 勉强接受;
- 我不喜欢。
2)反向:如果我们在微信消息中,不提供【视频通过】功能,你的感受是:
- 喜欢;
- 理应如此;
- 无所谓;
- 勉强接受;
- 我不喜欢。
3. 数据清洗
在收集所有问卷之后,注意清洗掉个别明显胡乱回答的个例,如全部问题都选择“我很喜欢”或“很不喜欢”的,这种回答毫无参考价值。
4. 分类整理
将数据清洗过的调查问卷,进行数据汇总,比如某一个用户对于提供【视频通话】功能是喜欢,不提供是无所谓,这个时候这个结果就需要在下面表格中纵向喜欢与横向无所谓中记一票,依次类推进行数据汇总。
5. 量化数据,判断属性
上述表格数据整理完成后,将同类型需求进行求和汇总,得出不同类型需求占比,占比最大的属性,即为该功能的属性归属,也决定了该功能的具体地位。
其中需要注意的一点是,这里表格的格式是固定的,就用下面的表格举例,同色或者同字母表示的就是同一类型需求,这也是kano模型实验定义而成,这里不需要做过多的纠结。
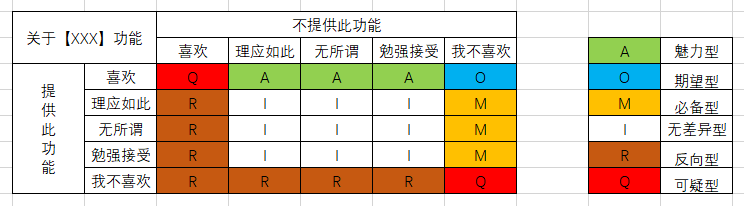
6. 根据数据确立优先级及判断影响
如果说表格法能清楚的针对某一个需求真伪进行判断,那如果面对多个需求,如何识别需求真伪、判断需求优先级,这个时候则需要引入更具体的数据计算:Better-Worse系数, 它更适合面对多需求时如何排定需求优先级。
公式如下:
增加后的满意系数 Better/SI=(A+O)/(A+O+M+I)
消除后的不满意系数 Worse/DSI=-1*(O+M)/(A+O+M+I)
Batter-Worse表示的是增加或者是消除某一功能对满意度的影响程度。
Better的数值通常为正,表示提供某功能后,用户的满意度会提升。其正值越大,代表用户满意度提升的效果会越强,满意度上升的越快。
worse的数值通常为负,表示不提供某功能后,用户的满意度会降低。其负值越大,代表用户满意度降低的效果会越强,满意度下降的越快。
网上查询关于kano模型的说明,基本上并没有讲解这个系数怎么计算与绘图的,这里我们手把手的说一下。
假设我们现在面临有的需求有5个功能点,在没有使用kano模型之前,我们不知道这些需求是否真的需要去做,以及不知道改优先处理哪一个。
这个时候我们就需要先对这5个功能点进行调研问卷测试。
具体可以参照上文说的调研问卷设计方式。这里需要提一点的是,如果我们给用户调研问卷中问题设置的比较多,避免用户做题批量的话,阵列横向单选。
把问题功能点描述作为行,5级评分作为列,这样会高效一点。回归这个用例:
(1)设计调研问卷;
(2)数据清洗,整理数据,输出对应功能的各个数值:
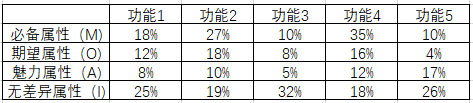
这里因为系数计算方式中不需要反向属性,所以可以不考虑。
根据上述不同系数计算各个功能的batter和worse值:

计算四象法则原点坐标:
这里的原点不是(0,0),是由上述5个功能中,batter值与worse的绝对值的均值作为原点。
Average(better)=(32%+38%+24%+35%+37%)/5=33%
Average(worse)=(-48%+-61%+-32%+-63%+-25%)/5=-46%
所以坐标原点是(46%,33%)横轴是worse值,纵轴是batter值。
绘制四象限图:
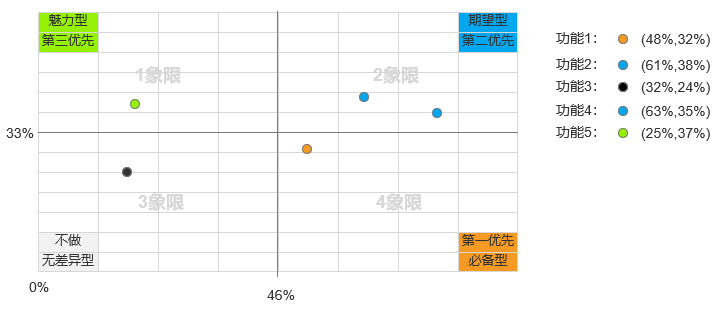
这里散点的放置即为各个功能点的坐标点与坐标原点(46%,33%)想比较,处于什么位置,分布在四象限中即可。
- 第一象限表示:better系数值高,worse系数绝对值也很高的情况。落入这一象限的因素,称之为是期望因素,即表示产品提供此功能,用户满意度会提升,当不提供此功能,用户满意度就会降低;
- 第二象限表示:better系数值高,worse系数绝对值低的情况。落入这一象限的因素,称之为是魅力因素,即表示不提供此功能,用户满意度不会降低,但当提供此功能,用户满意度会有很大提升;
- 第三象限表示:better系数值低,worse系数绝对值也低的情况。落入这一象限的因素,称之为是无差异因素,即无论提供或不提供这些功能,用户满意度都不会有改变,这些功能点是用户并不在意的功能;
- 第四象限表示:better系数值低,worse系数绝对值高的情况。落入这一象限的因素,称之为是必备因素,即表示当产品提供此功能,用户满意度不会提升,当不提供此功能,用户满意度会大幅降低;说明落入此象限的功能是最基本的功能。
Batter-Worse系数,本质上是计算2个坐标值,将相关的结果对应的象限,即可得出该功能属于哪一属性需求(一个功能只计算一个)其实是从数据上解释了kano模型不同类型需求具备程度,对于用户满意度的影响程度。
需求优先级排序,从上述的结果中,我们得出:
- 功能1:属于必备型;
- 功能2、4:输出期望型;
- 功能5:属于魅力型;
- 功能3:属于无差异型。
因此优先级排序上,先处理功能1,其次功能2和4先处理低成本的需求,最后处理功能5,功能3则暂时不需要处理。
综上就是通过batter-worse系数来判断当前需求真伪以及评定优先级的数据方式。
同时我们如果功能的数据量够大,也能通过batter-worse系数绘制成如下的图,来表示各个属性的功能具备与不具备对用户的影响程度。

四、总结
Kano模型其实并不是很复杂,可以简要的用下述流程图概括:
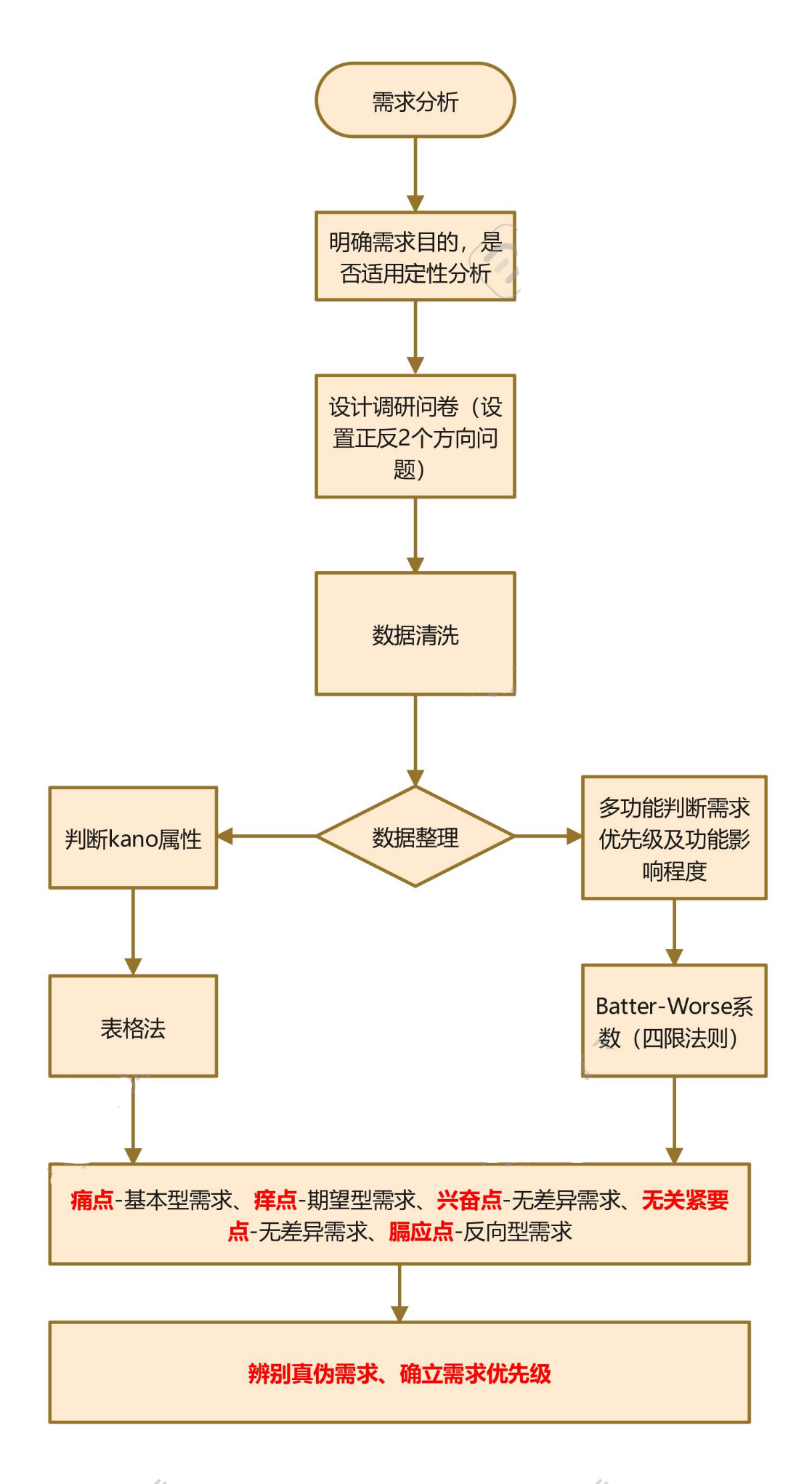
Kano模型可以很好的对需求进行分级,也可以帮助我们将日常面对的零零总总的需求,进行属性归类,定性分析。
明确什么样的需求应该做,什么样的需求应该优先做,什么样的需求不需要花大力气去处理。
最后,关于kano模型中有理解不到位的地方,希望大家批评指正。
本文由 @叽里咕噜 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。









上述表格数据整理完成后,将同类型需求进行求和汇总,得出不同类型需求占比,占比最大的属性,即为该功能的属性归属,也决定了该功能的具体地位。这里的表格在哪里了?
应该就是下面那个表格
第一象限表示:better系数值高,worse系数绝对值也很高的情况。落入这一象限的因素,称之为是期望因素,即表示产品提供此功能,用户满意度会提升,当不提供此功能,用户满意度就会降低;
第三象限表示:better系数值低,worse系数绝对值也低的情况。落入这一象限的因素,称之为是无差异因素,即无论提供或不提供这些功能,用户满意度都不会有改变,这些功能点是用户并不在意的功能;
第一象限和第三象限的worse系数不是一样的吗,为什么一个是高,一个是低?
支持一下
你们俩是情侣吧,这名称和头像
欢迎大家批评指正,更多文章可关注公号:产品碎碎念