
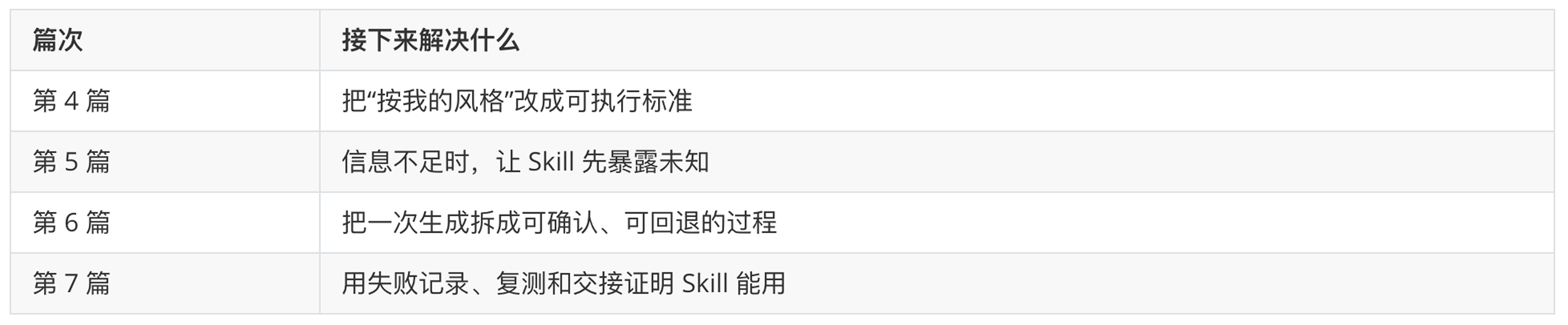
 起点课堂会员权益
起点课堂会员权益下载了一堆 Skill,为什么还是不好用
这是「AI 协作」系列二第 3 篇。上一篇讲了怎样从 0 搭出第一版;这一篇回到我的真实起点:在自己动手之前,我也先下载过一堆别人做好的 Skill。
文中使用一份“会员积分过期提醒优化”的原始生成初稿作为样本。重点不是评价这份 PRD 写得好不好,而是看清:一份结构完整的通用 Skill 输出,为什么仍然不能直接进入自己的项目。

读完这篇,你不需要马上学会重写 Skill。先能从一份完整输出中分清三类内容:已经确认的事实、可以讨论的建议,以及缺少依据却被写成结论的未知。
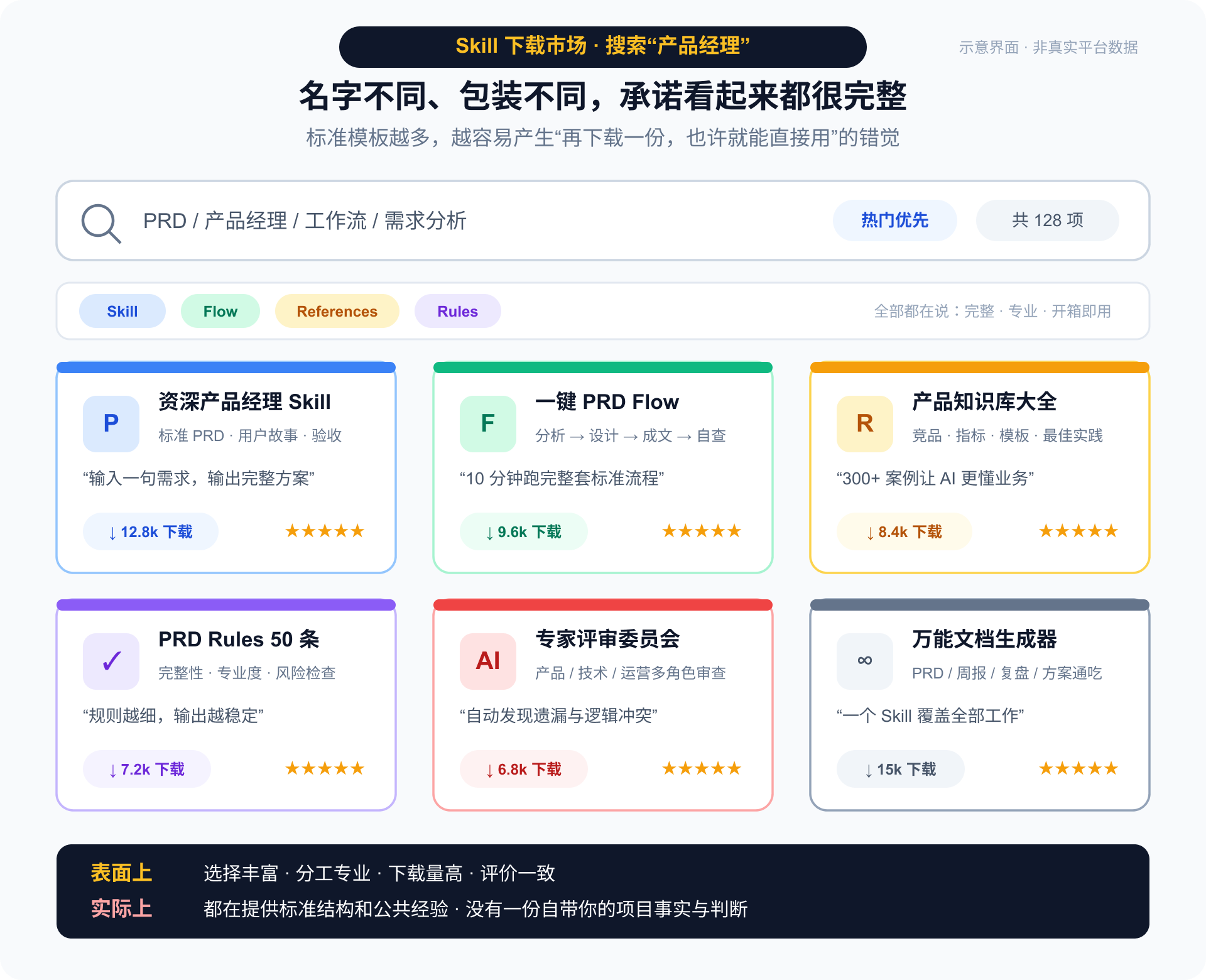
刚开始搭 AI 工作流时,很多人的第一个动作不是自己写,而是下载。
市面上有各种打包好的 skill、flow、references、rules:这个号称“资深产品经理”,那个可以“一键生成完整 PRD”,还有人整理了几十条规则和参考资料。
于是很容易进入一种“大力出奇迹”的状态:
- Skill 看起来专业,先下载;
- Flow 步骤更全,也加进去;
- References 越多,AI 应该越懂业务;
- Rules 写得越细,结果应该越稳定。
文件夹越来越满,我们也很容易把“资料齐全”误认为“系统已经成熟”。
为了看它到底能不能用,我给其中一份市场通用版 Skill 输入了一个需求:
新锐美妆品牌希望优化会员积分过期提醒,减少积分清零后的集中客诉。
它很快生成了一份完整 PRD。
问题陈述、目标与 KPI、用户与范围、四项功能、验收标准、技术约束、状态机、待解决问题和竞品附录,一项不少。
它不是只给了几段建议,而是真的交出了一份“像 PRD 的 PRD”。
第一眼看过去,我甚至不知道该从哪里挑错。直到我换了一个问题:
如果这份文档明天就要进入评审,里面哪些内容可以直接使用?
答案开始变得不一样。

基线还没采集,目标值已经很精确
先看目标与成功指标:
| 指标 | 当前基线 | 目标 |
|—|—|—|
| 积分过期相关客诉工单数 | 待采集 | 降低 60%+ |
| 收到提醒后兑换转化率 | 无 | ≥ 15% |
| 过期前积分消耗率 | 待采集 | ≥ 50% |
| 提醒触达率 | — | ≥ 85% |
这段比“优化体验、提升满意度”专业得多。
它不但给出了结果指标,还补上兑换、消耗和触达指标。数字明确,衡量方向完整,看起来已经可以直接用于验收。
但再看一遍,会发现一个非常直接的矛盾:
当前基线还是“待采集”,改善目标却已经精确到了 60%、50% 和 85%。
这时真正需要回答的是:
- 60% 的改善目标从哪里来?
- “兑换转化率”统计哪些用户、多长时间?
- 提醒触达率是否能把短信和订阅消息合并计算?
- 这些数字是业务目标、行业参考,还是 AI 给出的建议?
换成数据看板,会更容易看出问题:数值虽然都填上了,但指标卡片真正需要的验证信息仍然是空的。

这里需要明确:这些指标不是根据业务基线推导出的结果,而是通用版 Skill 直接定义的目标草案,尚未经过业务、数据和责任人的验证。
表格解决了“指标长什么样”,没有解决“指标凭什么成立”。

数字越具体,不代表可信度越高。
没有来源的精确数字,只会让不确定性更难被发现。
这些数字和方案从哪里来?继续往下看,会发现通用版大量使用了行业经验。
参考资料直接变成了项目方案
文档先列出了一组“行业最佳实践”:
| 最佳实践 | 来源 |
|—|—|
| 30 / 14 / 7 / 3 / 1 天分阶段提醒 | 行业通用 |
| 多渠道覆盖 | 腾讯云积分系统方案 |
| 兑换率提升 217% | 某电商案例 |
| 客诉从 500+ 降至 50 以下 | 某电商实战数据 |
有竞品、有行业方案,还有结果数据。单看这一段,会觉得 AI 至少没有闭门造车。
紧接着,这些参考就进入了本期范围:
本期范围:
– 30 / 14 / 7 / 3 / 1 天分阶段提醒
– 短信 + 小程序订阅消息
– 积分页面常驻提醒
– 展示积分数、过期时间和兑换入口
行业里常见的五个提醒节点,直接成了当前项目的五个节点;多渠道覆盖,也直接变成了短信和小程序订阅消息。
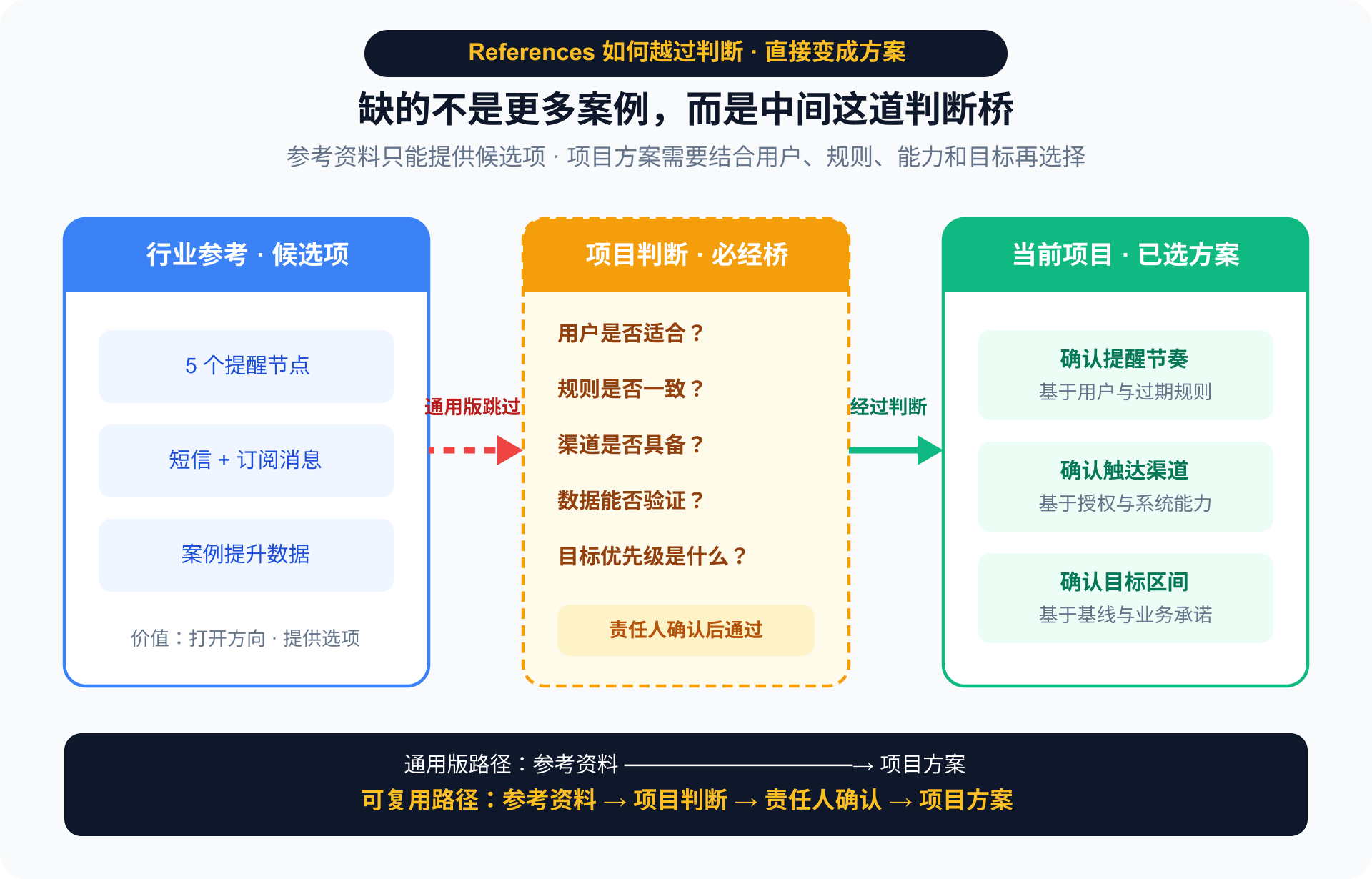
中间缺少了一步:为什么它适合这个项目?
- 五次提醒会不会过于频繁?
- 当前用户是否具有相同的消费和兑换习惯?
- 案例数据的样本、周期和业务规则是否可比?
- 短信与订阅消息是否已经具备?
- 这些做法是候选方向,还是业务已经确认的本期规则?
References 本来应该帮助我们扩大选项、提出问题和支持论证。在这份输出里,它却替业务完成了选择。
这并不代表行业参考没有价值。相反,它很适合帮助我们快速打开思路。
但从“行业里有人这样做”到“我们这期就这样做”,中间仍然需要产品判断。
References 能扩大答案范围,却不会自动完成“这条经验是否适合我”的判断。
当参考方案被写成确定范围,AI 接下来就会继续补齐系统和技术细节。
越像内部事实,风险越高
技术约束部分看起来尤其专业。通用 Skill 不只写出结论,还会继续补成一段接近研发配置的代码:
# 通用 Skill 生成的技术约束草案
notification:
sms:
enabled: true
quota: unlimited
mini_program_subscription:
enabled: true
template_status: approved
points:
source_table: user_point_detail
expire_field: expire_at
valid_status: VALID
scheduler:
cron: “0 9 * * *”
scan_nodes: [30, 14, 7, 3, 1]
retry_times: 3
delivery:
deadline: none
budget_limit: none
通道状态、表名、字段、枚举、定时任务、成本和排期都有了。代码格式又进一步强化了可信感:它不像建议,更像从现有系统里抄出来的配置。
实际输入并没有提供这些信息。
如果继续沿着这段配置往下推,AI 甚至可以补出一份已经“能交给研发”的库表设计:

这份配置和库表草案并不是来自研发方案,而是 AI 为了让技术章节完整,沿着一个未经确认的表名继续推演出来的。
user_point_detail 是不是真实表名?expire_at 是否存在?有效状态是不是 VALID?积分是否按用户聚合?任务由哪个系统执行?短信通道是否已经接入?小程序订阅消息模板是否审核通过?
这些都需要产品、研发和业务分别确认,不能因为它们被写进“技术约束”代码,就自动变成事实。
技术约束应该记录已经确认的系统限制。尚未确定的表结构、任务机制和实现方式,只能作为技术方案草案或待确认项,不能伪装成项目现状。
不同内容被补错,后果也不同:
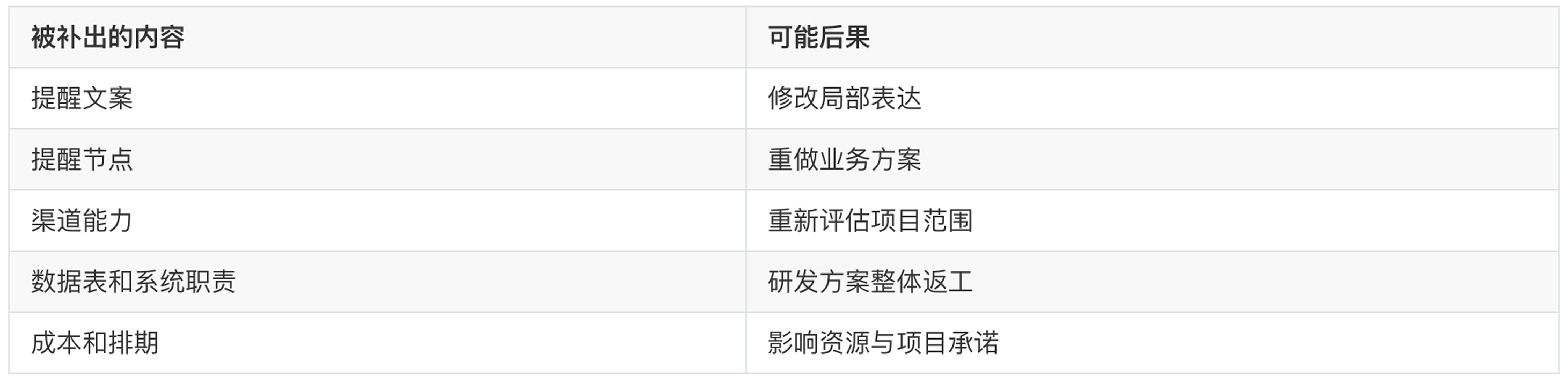
通用 Skill 最危险的地方,往往不是写了一句明显的错话,而是用非常熟练的项目语言,补出了一项看起来已经确认的内部事实。
越像项目内部事实的内容,越不能由通用 Skill 靠行业常识补齐。
奇怪的是,这份文档并非完全不知道自己缺信息。
待确认项有了,但出现得太晚
在第 8 章,它列出了待解决问题:
## 待解决问题
– 历史过期率需要拉取数据基线
– 小程序订阅消息模板是否审核通过
– 是否需要“即将过期积分”专区
– 是否考虑多笔积分分批过期的聚合提醒
这说明 AI 并非完全没有风险意识。它知道基线尚未采集,知道订阅消息能力需要确认,也注意到了多笔积分的复杂情况。
问题在于,这些问题出现之前,完整方案已经写完了。
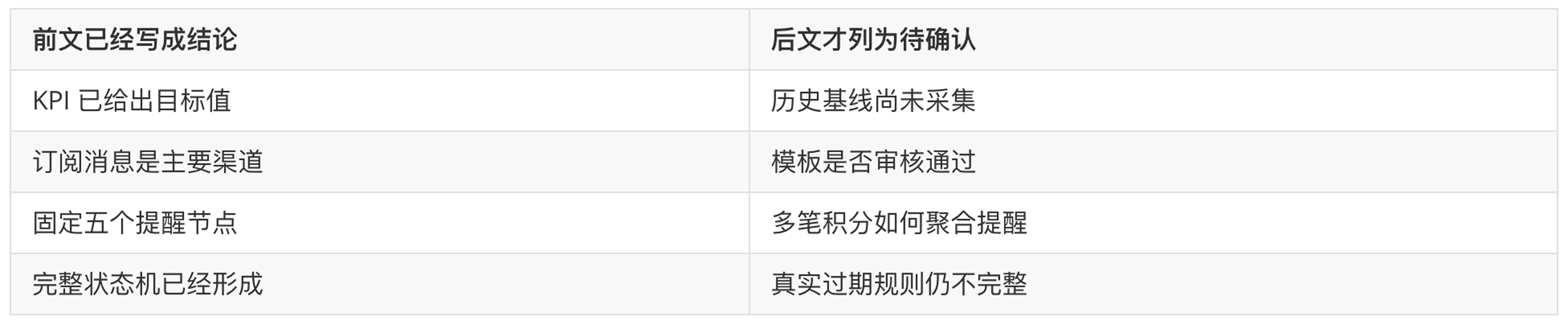
也就是说,它并非不知道信息不足,而是先用通用经验完成方案,再把真正会改变方案的问题放到最后。
这也是整份文档最值得注意的地方:
问题不在于有没有“待确认”章节,而在于待确认项有没有资格阻止前面的方案继续生成。
通用版的默认目标通常是尽快交付一份完整文档。因此它很容易:
- 先用常见做法填满空白;
- 再把不确定内容放到文档末尾;
- 把格式完整放在事实可信之前。
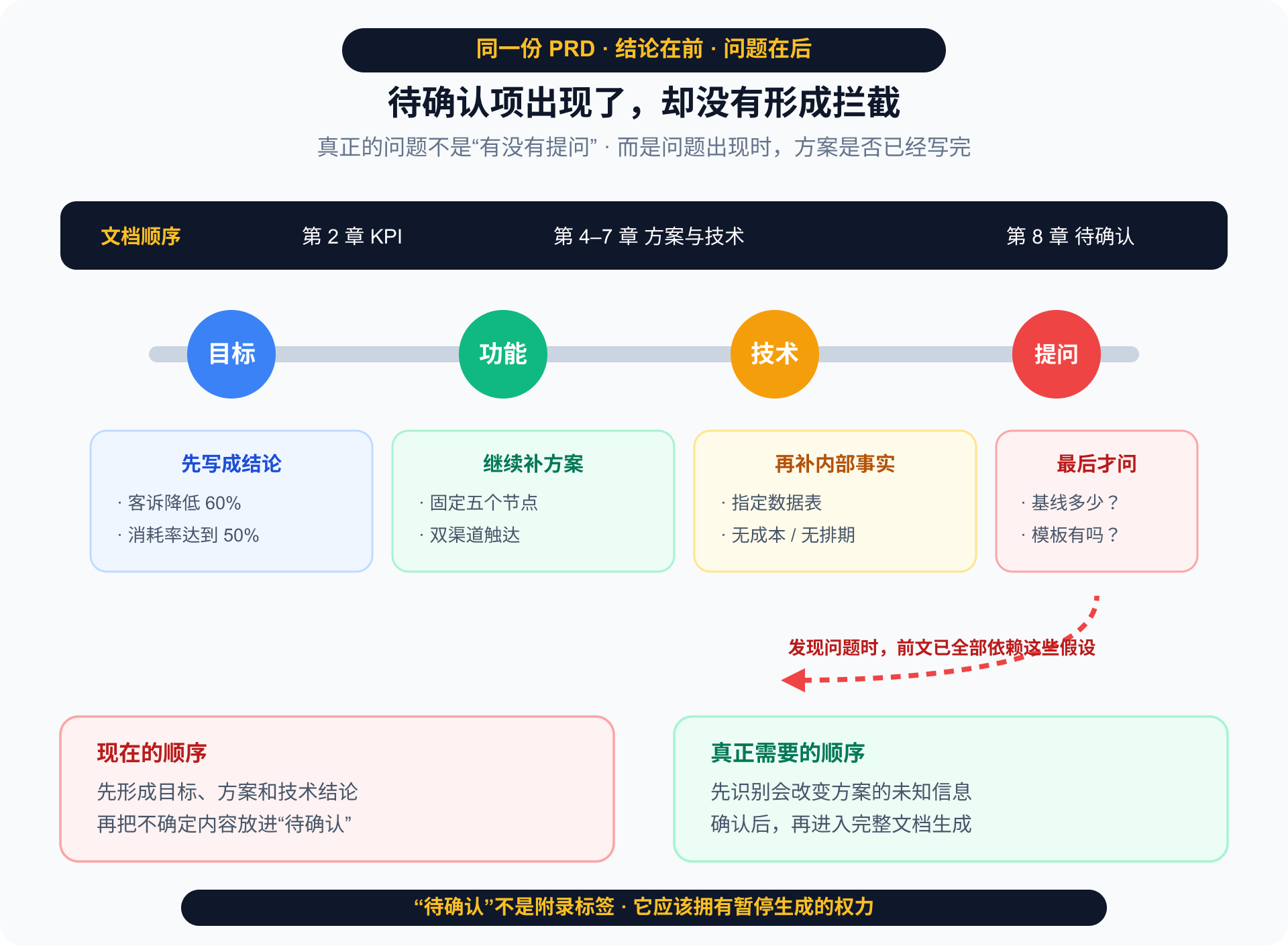
它完成的是公共答案
回头看这份 PRD,每一块都有明显价值:
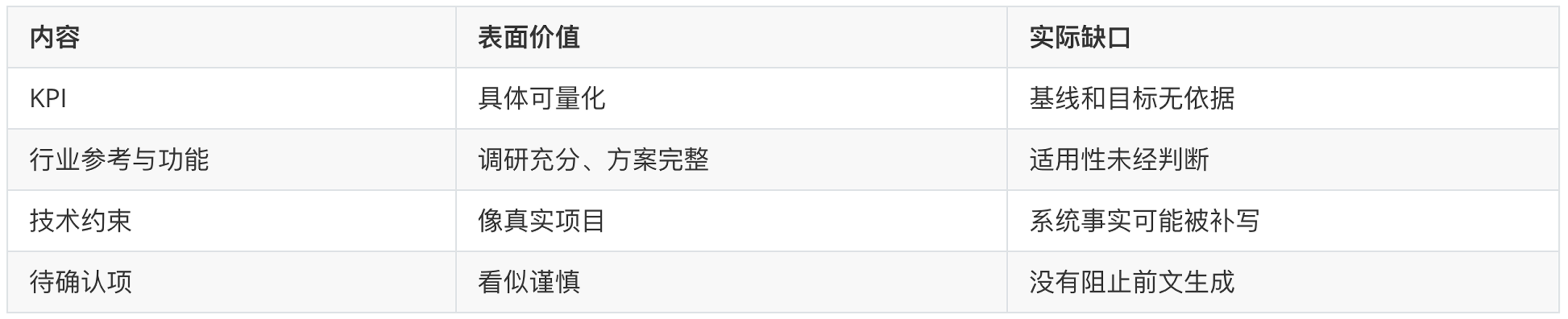
它完成了一份结构完整的标准答案,但真正决定“能不能用于我的项目”的信息,散落在标准结构之外:
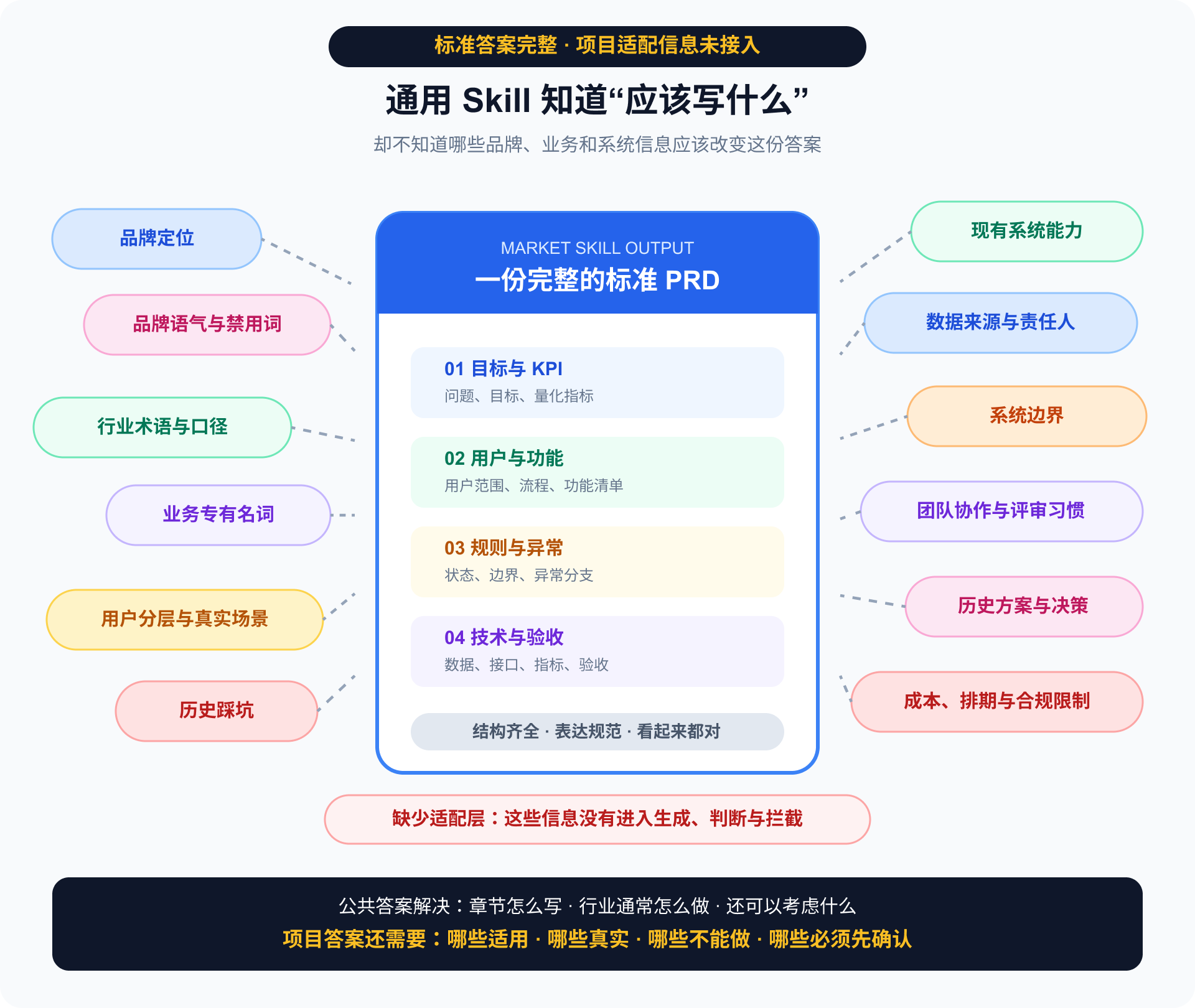
所以,我不认为市场通用版 Skill 没用。
它解决了“从哪里开始”,也告诉我“行业里通常怎么写、怎么做”。它可以帮助我们认识标准结构、获得候选方案、建立第一批问题清单,也能反向暴露当前还缺少哪些项目材料。
但它无法直接回答:
在我的项目里,什么是真的,什么能做,什么必须先停下来确认?
通用版知道公共知识,却不知道我的系统边界、团队习惯、历史包袱和评审标准。
市场 Skill 提供的是公共答案;真正能复用的 Skill,需要装入自己的判断依据。
先用四个问题检查你下载的 Skill
不用急着重写。先找一份你下载或收藏过的 Skill,用它跑一个自己熟悉的任务,然后检查:
- 精确数字是否有基线和来源?
- 行业参考是否未经判断就变成了项目方案?
- 系统、成本和排期是否由真实责任人确认?
- 哪些待确认问题本应阻止方案继续生成?
完成这一步,不需要评价整份输出“好”或“不好”,只要把内容分成三类:
- 输入中已经确认的事实;
- 可以继续讨论的建议;
- 缺少依据、不能直接进入方案的未知。
能把这三类内容分开,就已经看见这份通用 Skill 的适配缺口。
下一步:开始书写自己的第一版
看清这些问题后,我没有继续寻找另一份更强的模板。
我开始把历史 PRD、团队评审习惯和真实返工放在一起,尝试书写自己的第一版 Skill。
但最初写进去的,仍然只是:
- 写专业一点;
- 按我的风格;
- 章节更完整;
- 异常场景更详细。
这些要求方向都对,却无法稳定执行。
下一篇继续拆解:怎样从一份真正通过评审的旧 PRD 中,提取章节、颗粒度、术语和验收标准,把“像我写的”变成 AI 能执行的规则。
总结:完整只是起点,可信才能进入项目
这次使用市场通用版,我得到的不是“下载的 Skill 都没用”,而是四个更具体的判断:
- 指标写得精确,不代表数字有依据;
- 参考资料很多,不代表已经完成项目判断;
- 技术描述很真实,不代表它来自真实系统;
- 列出待确认项,不代表它真的阻止了错误生成。
通用版可以帮助我们快速看到标准结构、候选方案和缺失材料,但不能替我们确认项目事实、系统边界和决策依据。
这一篇先完成“看见适配缺口”。后面的系列会继续解决:
一份 Skill 的成熟,不看它写了多少规则,而看它能否分清事实、建议和未知。
下期预告
公众号继续双线并进:
系列一 · 电商产品能力拆解: 继续拆真实业务系统与产品方案。
系列二 · AI 协作 · 第 4 篇:Skill 怎么才算“像我写的”?
市场通用版解决不了项目适配,我开始自己写第一版。但“专业一点”“详细一点”“按我的风格”这些要求,方向都对,AI 仍然只能猜。
下一篇会具体拆解:
- 怎样选择真正通过评审的历史产物;
- 怎样提取稳定的章节与表格结构;
- 怎样确定业务规则需要写到什么颗粒度;
- 怎样把术语、禁用表达和验收标准写成可检查规则。
第三篇先看清“公共答案为什么不能直接使用”;第四篇开始把自己的工作标准写进去。
作者:Zoe产品手记 公众号:Zoe产品手记
本文由 @Zoe产品手记 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Unsplash,基于CC0协议









建议下载Skill后先跑一个最熟悉的项目,然后对照文中的四类问题检查:基线、行业参考、系统约束、待确认项。把输出里所有没有来源的数字标红,会很有帮助。
如果通用Skill把待确认问题放在最后,那理想的设计应该是先要求用户输入基线数据再生成方案,还是让Skill自动标注出所有假设?哪种方式更实用?
说得很清楚,但我觉得对通用Skill的批判有点过于严格了。它本来就是个起点,能快速给出结构和大方向已经很值了,不能指望它直接交付可用的东西。不过那个把行业参考直接当方案用的确是个坑。
但话说回来,如果要求Skill完整理解项目边界才能生成,那它跟人类专家也没什么区别了。通用Skill的价值就在于快速给出模板,至于适配,本来就应该由人来完成,不能全怪工具。