
 起点课堂会员权益
起点课堂会员权益AI产品经理需了解的技术知识:自然语言理解技术NLU

本文章主要介绍了NLU技术的算法包括词法分析、句法分析、语义分析,有助于PM了解技术实现边界,产品快捷高效的落地~
自然语言理解技术(NLU)是人机对话产品中的重要一环,是指机器能够执行人类所期望的某些语言功能,换句话说就是人与机器交流的桥梁。
语言理解主要包括以下方面内容:
- 能够理解句子的正确次序规则和概念,又能理解不含规则的句子;
- 知道词的确切含义、形式、词类及构词法;
- 了解词的语义分类、词的多义性、词的歧义性;
- 指定和不定特性及所有特性;
- 问题领域的结构知识和实践概念;
- 语言的语气信息和韵律表现;
- 有关语言表达形式的文字知识;
- 论域的背景知识。
语言理解通常分为三个层次:词法分析、句法分析、语义分析。
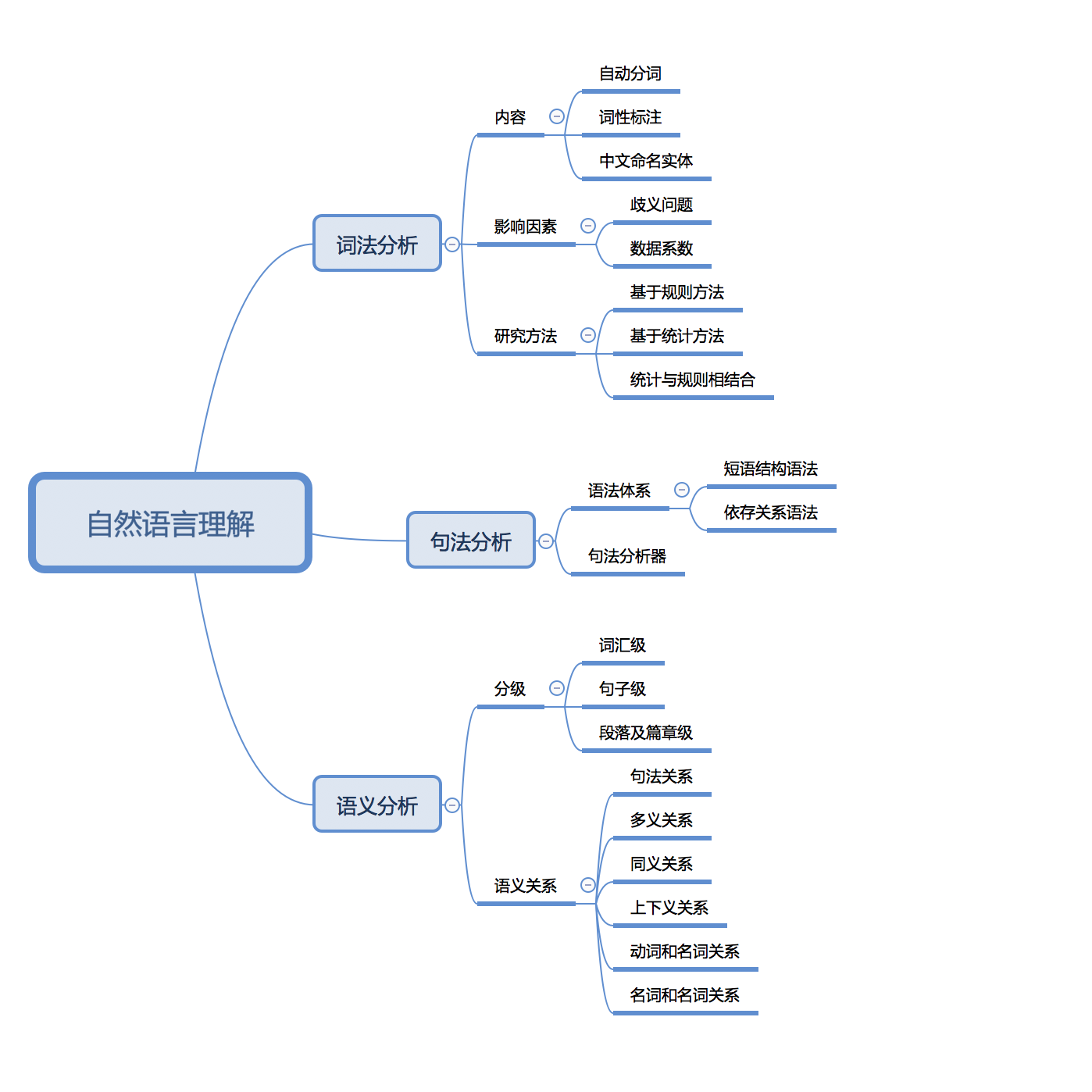
词法分析
词法分析是自然语言处理的技术基础,也是自然语言理解过程的第一层,因此词法分析的性能直接影响到后面句法和语义分析的成果。主要包括自动分词、词性标注、中文命名实体标注三方面内容。
1. 自动分词
现有分词的算法分为三大类:基于词典的分词方法、基于统计的分词方法、基于理解的分词方法。
当前主流的方法还是基于词典进行分词,主要包括正向最大匹配、逆向最大匹配、双向最大匹配。原理是按照既定的规则顺序,将目标字符串依次与词典匹配,匹配成功就取出该词,直到整个字符串全部匹配,如在词典中匹配到,就取出单字。
case:字串“召开大学生运动会”,分别通过三种分词算法进行切分:
(1)正向最大匹配
第一轮取词
第1次:“召开大学生运动会”扫描词典,无匹配
第2次:“召开大学生运动”扫描词典,无匹配
第3次:“召开大学生运”扫描词典,无匹配
第4次:“召开大学生”扫描词典,无匹配
….
第7次:“召开”扫描词典,匹配
第二轮取词
第1次:“大学生运动会”扫描词典,无匹配
第2次:“大学生运动”扫描词典,无匹配
…..
第4次:“大学生”扫描词典,无匹配
第5次:“大学”扫描词典,匹配
分词结果:召开/大学/生/运动/会
(2)逆向最大匹配
第一轮取词:
第1次:“召开大学生运动会”扫描词典,无匹配
第2次:“开大学生运动会”扫描词典,无匹配
….
第8次:“会”
第二轮取词:
第1次:“召开大学生运动”扫描词典,无匹配
第2次:“开大学生运动”扫描词典,无匹配
…
第6次:“运动”扫描词典,匹配
分词结果:召开/大/学生/运动/会
(3)双向最大匹配
将正向最大匹配和逆向最大匹配算法得到的结果进行比较,从而确定正确的分词方法。
选择的依据如下:
- 大颗粒度词越多越好;
- 非词典词越少越好;
- 单字词越少越好。
2. 词性标注
词性标注是对分词结果中的每个单词标注一个正确的词性,例如:每个词是名词、动词还是形容词等。汉语中,词性标注笔记哦啊简单,因为大多词语只有一个词性,或者出现频次最高的词性远远高于第二位的词性。
因此在词性标注时,一般先针对已存在的词库进行统计学处理,建立词性标注模型,进而通过概率判断每个词的词性。
3. 中文命名实体
命名实体就是奖文本中的元素分成预先定义的类,例如:人名、地名、时间、百分比等。它的技术方法主要分为基于规则和词典、基于统计、二者结合的方法。
基于规则和词典的方法,大多是由语言学专家构造规则模板然后进行匹配。这个时候,词典和知识库的创建会直接影响命名实体的准确率。
举个简单规则的例子:人名=【姓氏】+【名字】,那么分别建立“姓氏”、“名字”库,如字串命中,则识别出包含人名实体。
基于统计的方法,主要是通过对训练语料所包含的语言信息进行统计和分析,从许年语料中挖掘出特征。因此这种方法对语料库的依赖比较大,而用来建设和评估命名实体识别系统的大规模通用语料库又比较少。
句法分析
句法分析的目标是自动推导出句子的句法结构,实现这个目标首先要确定语法体系,不同的语法体系会产生不同的句法结构。常见语法体系有短语结构语法、依存关系语法。
依存关系语法
同样分为基于规则和基于统计的两种方法,基本自然语言的技术中,很多都是基于“词典/规则”+“统计”的方法。
(1)基于规则的方法
- 优点在于:可以最大限度的接近自然语言的句法习惯、表达方式灵活多样,可以最大限度的表达研究人员的思想;
- 缺点在于:规则刻画的知识粒度难以确定,无法确保规则的一致性,获取规则同样是一个繁琐的过程。
(2)基于统计的方法
目前是句法分析的主流技术,确定语法体系后,需要按照语法体系人工标注句子的语法结构,将其作为训练的语料。因此语料库的建设是非常关键的。
语义分析
语义分析就是指分析话语中所包含的含义,根本目的是理解自然语言。分为词汇级语义分析、句子级语义分析、段落/篇章级语义分析,即分别理解词语、句子、段落的意义。
这部分在我的工作中相对前两部分应用的较少一些,因此没有过多的进行学习了解。
理解NLU技术的基本原理和算法可以在PM优化产品时起到很大的帮助,使我在产品设计时,可以提前了解技术边界,在和研发沟通时,效率也更高。
本文由 @猪不会飞 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
















大神,可否加个微信。最近在钻研NLP,CV方面的知识;向您学习一下;