
 起点课堂会员权益
起点课堂会员权益深入研究GUI和VUI

GUI和VUI的差异来自信息维度、信息量大小、交互方式、内容驱动、任务类型等等,今天我们一起探讨一下GUI和VUI的差异,最后重点聊一下如何将GUI转化为VUI。
今天我们深入探讨一下GUI和VUI。
GUI是60年代“人机交互”的奇才道格·恩格尔巴特提出的概念,它使计算机更容易被用户接受,自从80年代苹果推出第一款搭载GUI的电脑后,至今为止GUI一直是人机交互的代表。VUI并不是全新的概念,它的前身是IVR(Interactive Voice Response,交互式语音应答),它诞生于70年代普及于2000年。电话用户只要拨打移动运营商所指定号码,就可根据语音操作提示收听、点播或发送所需的语音信息以及参与聊天、交友等互动式服务。新一代的VUI更多指的是人通过自然语言与计算机进行交互,所以可以认为VUI是人工智能时代下的人机交互代表。
在聊GUI和VUI之前,我们先聊一下视觉和听觉,因为使用感官的不同会直接导致GUI和VUI设计的不同。
维度
如果问GUI和VUI最本质的区别是什么,我认为是传递信息的维度不同。眼睛接收的信息由时间和空间XZY轴四个维度决定;耳朵接收的信息只能由时间维度决定。
虽然耳朵能觉察声音的方向和频率,但不是决定性因素。
时间决定了接收信息的多少,它是单向的、线性的以及不能停止的。耳朵在很短时间内接收的信息是非常有限的,举一个极限的例子:假设人可以停止时间,在静止的时间内声音是无法传播的,这时候是不存在信息的;还有一个说法是在静止的时间内声音总保持在一个当前状态例如“滴~~~”,这时候声音对人类来说就是一种噪音。耳朵接收的信息只能由时间决定。
眼睛却很不一样,即使它在很短时间内也可以从空间获取大量信息。空间的信息由两个因素决定:1.动态还是静态;2.三维空间还是二维平面。在没有其他参照物的对比下,事物的静止不动可以模拟时间上的静止,这时候人是可以在静止的事物上获取信息的。时间和空间的结合决定了信息的大小,好比如花一分钟看周围的动态事物远比一年看同一个静态页面获取的信息多得多。
还有一个重要的区别,眼睛可以来回观察空间获取信息;耳朵只能单向获取信息,在没有其他功能的帮助下如果想重听前几秒的信息是不可能的。
接收信息量的对比
视觉接收的信息量远比听觉高。在知乎上有神经科学和脑科学话题的优秀回答者指出大脑每秒通过眼睛接收的信息上限为100Mbps,通过耳蜗接收的信息上限为1Mbps。简单点说,视觉接收的信息量可以达到听觉接收信息的100倍。
以上数据来自知乎问题“耳朵和眼睛哪个接收信息的速度更快?”
虽然以上结论没有官方证实,但我们可以用简单的方法进行对比。在不考虑超出理解范围外,人阅读文字的速度可以达到500~1000字每分钟,说话时语速可以达到200~300字每分钟,所以视觉阅读的文字信息可以达到听觉的2-5倍。
超出理解范围时会花时间思考,这导致了接受信息量骤降。以上两个数据来自知乎问题“普通人的阅读速度是每小时多少字?”和“为他人撰写中文演讲稿,平均每分钟多少字比较合适?”
如果将图像作为信息载体,视觉阅读的信息远超听觉的5倍。眼睛还有一个特别之处,通过扫视的方式一秒内可以看到三个不同的地方(图)。
以上数据来自《人工智能的未来》一书。
GUI和VUI的差异
维度加上视觉听觉各自的特点导致了GUI和VUI在信息展现、交互等方面的不同。以下我们讨论一下GUI和VUI的差异。
内容与数据驱动
GUI的内容主要为图形和文字;VUI的内容主要为文字,图形和文字都属于非结构化数据。目前的GUI展示的内容是由结构化数据驱动的;VUI展示的内容是由非结构化数据驱动的。
信息交互
如何理解GUI和VUI由不同的数据类型驱动?人主要通过点击和手势的方式与GUI进行交互,至于人在做什么其实计算机是不知道的,它只是将点击和手势转化为坐标和操作两种数据,再给予相应的响应事件,例如打开链接、获取数据库的信息。
人通过对话的方式与VUI进行交互,对话过程中使用的自然语言属于非结构化数据,VUI要给出正确的响应事件必须要先理解人类在说什么,更重要的是在想什么。
情境感知
要知道用户在想什么做什么,必须要有出色的情境感知(Context Awareness)能力,也就是上下文理解能力,它能根据用户是谁、用户情感、当前环境、之前的记忆给出下一步的预测。目前的人工智能技术还没很好地掌握以上几点技术,所以GUI和VUI的情境感知能力相对初级,只能人为设计来弥补。
任务类型
由于眼睛比耳朵可以接收更多信息,所以GUI更适合展示内容。在指令面前,GUI和VUI各有优势,到底谁是最佳只能具体问题具体分析了,取决于各自的步骤长短。但可以肯定的是,目前的VUI不适合复杂的任务,因为它在多轮任务中表现并不是很出色。
信息架构:
GUI的信息架构包含了页面和流程,页面里包含了各种布局和结构;而VUI的信息架构只有流程,所以GUI的信息架构要比VUI复杂。由于页面操作的限制使GUI无法随意切换毫无相关的流程,而通过对话交流的VUI可以做到这一点,在导航的便捷性上,VUI更胜一筹。
GUI to VUI
为什么要将GUI转换为VUI?
- 现有互联网的绝大部分内容和数据都与GUI的信息架构和代码有关,所以我们没有必要为两个界面做两套内容。
- 这有助于人工智能助手的发展。如果我们要将GUI的内容转换为VUI内容,我们必须简化当前信息,使信息压缩为200-300字每分钟或者3-5字每秒。
目前的人工智能还做不到图片理解、情境感知等技术,要将大部分GUI内容自动压缩并转换成自然语言绝非易事,所以需要人为制定一些转换策略。
在转换策略上我们可以借鉴成熟的无障碍规范指南——a11y,部分内容是为失明人士提供帮助的,可以将界面内容转换为声音内容,我们借鉴以下三个准则:
- 可感知性:信息和用户界面组件必须以可感知的方式呈现给用户。
- 适应性:创建可用不同方式呈现的内容(例如简单的布局),而不会丢失信息或结构。
- 可导航性:提供帮助用户导航、查找内容、并确定其位置的方法。
解释:
(1)在可感知性里下面有一条非常重要的准则:为所有非文本内容例如图片、按钮等等提供替代文本,使其可以转化为人们需要的其他形式。现在的通用做法是为图片、按钮等非文本内容增加描述性内容,例如在img标签上增加alt属性,在input button标签上增加name属性。开启无障碍设置后,失明人士通过触摸相关位置,系统会将属性里的文字朗读出来。
举个例子:
以京东的广告为例,应该在alt属性上加上简洁的内容“12月14日360手机N6最高减600”,当VUI阅读该内容时可以将广告重点朗读出来。

在这里我有新的想法,以下图为例:粉红色区域为一个小模块,图片、副标题、时间和作者等信息对于必须简化信息的VUI来说都不是必要信息。是不是可以在div标签上增加一个“标题”属性,当VUI阅读到该div时可以直接阅读该属性的内容,例如标题内容;如果用户对作者感兴趣,可以通过对话的形式获取作者信息。

(2)以淘宝为例,以下内容普通人花几秒就可以看完;如果以VUI的形式进行交互,首先VUI不知道从哪开始读起,其次是用户没有耐心听完全部内容。为什么?因为GUI的结构有横纵向两个维度,VUI结构只有一个维度,用户在GUI上的阅读顺序无法直接迁移到VUI上,所以a11y希望页面设计时可以采用简单的布局,GUI和VUI采用相同的结构,避免丢失信息或结构。
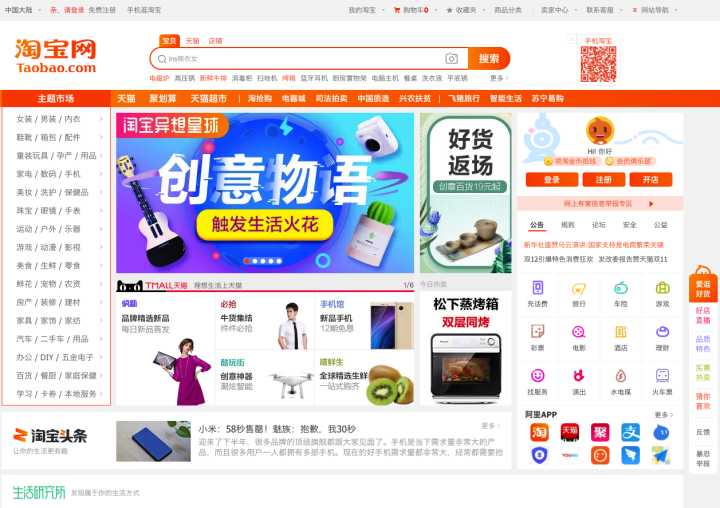
(3)在可导航性上,a11y希望网页提供一种机制可以跳过在多个网页中重复出现的内容模块。在这里我有新的想法:可以直接跳过无需朗读的内容模块,例如淘宝的导航、主题市场、登录模块,因为用户使用淘宝VUI主要需求为搜索物品和获取优惠信息。同理,是不是可以在div标签上增加一个“跳过”属性,当VUI阅读到该div时可以直接跳过div,当用户有需求时,可以通过对话的形式对该div里的内容进行交互。
最后我还有另外一个想法:是不是可以为大段内容如新闻、介绍等增加“文本摘要”属性,当VUI阅读到该标签式,自动使用文本摘要功能。
结合以上三点思考,GUI在转换为VUI时以“概括”、“跳过”的方式可以大大地简化信息,使VUI拥有一个良好的体验。
以上三个属性需要W3C、Google、苹果等组织统一制定标准。
VUI and GUI
VUI和GUI的结合已经不是新鲜事,例如Siri、Google Assistant、Cortana、Bixby,以及最近推出的Alexa屏幕版。在GUI的基础上增加VUI有助于简化整个导航的交互,可以做到无直接关系页面的跳转,例如以命令的形式导航去其他应用的某个页面。在VUI的基础上增加GUI可以使选择、确认等操作得以简化,尤其是用Alexa进行购物时。
结语
人工智能时代下GUI和VUI的发展会越来越快,研究和探索它们是一件非常有趣的事情。我认为在未来几年里,个人智能助手的成熟会使VUI和GUI的结合会越来越紧密,它直接影响到未来几年移动交互的发展。
如果你也有相关想法欢迎和我交流:-)
作者:薛志荣(微信公众号:薛志荣),百度交互设计师,二年级生
本文由 @薛志荣 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!


