
 起点课堂会员权益
起点课堂会员权益RAG不是比微调”更准”,而是分工不同
RAG与微调模型之争并非简单的二选一。本文深度剖析两大技术路径的底层逻辑:RAG在知识可追溯性上的优势与微调在领域能力内化上的不可替代性,揭示真实场景中两者互补的必然性。从冰雪装备电商案例到成本决策框架,带你跳出技术站队思维,掌握AI落地的组合方法论。

上周在学RAG的时候,有人问我:为什么要用RAG而不是直接微调模型?
我当时脱口而出:”因为RAG更准啊。”
说完我就后悔了。因为仔细然后那个四条路线的那个图片对应的也是文章内的一个部分。一想,这个回答是错的。
我一开始的理解
我的逻辑链是这样的:
微调模型是个黑箱,你把知识塞进去训练,但你没法保证它输出的时候不瞎编。而RAG是从知识库里检索真实文档,答案有据可查。所以RAG更准。
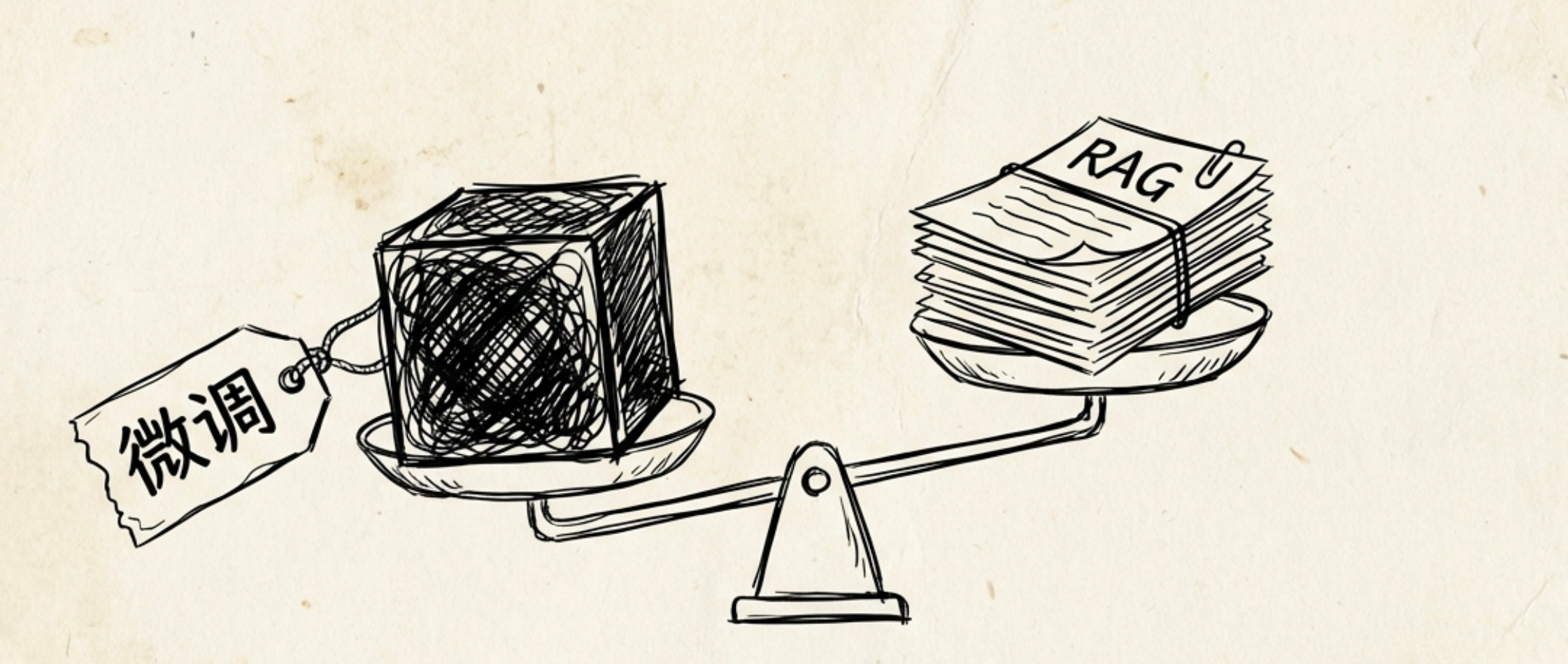
听起来很合理对吧?
但这里面有两个问题,我当时没意识到。
图注:先建立“分工而非二选一”的总框架,再进入下文两个常见误区。
第一个错:RAG也会幻觉
我之前以为RAG因为有检索,所以不会幻觉。
错了。
RAG的幻觉方式不一样,但它确实会幻觉:
- 检索到了不相关的文档,模型基于错误信息生成答案
- 检索到了正确文档,但模型自己推理的时候跑偏了
- 多个检索片段之间有矛盾,模型自己”脑补”了一个折中答案
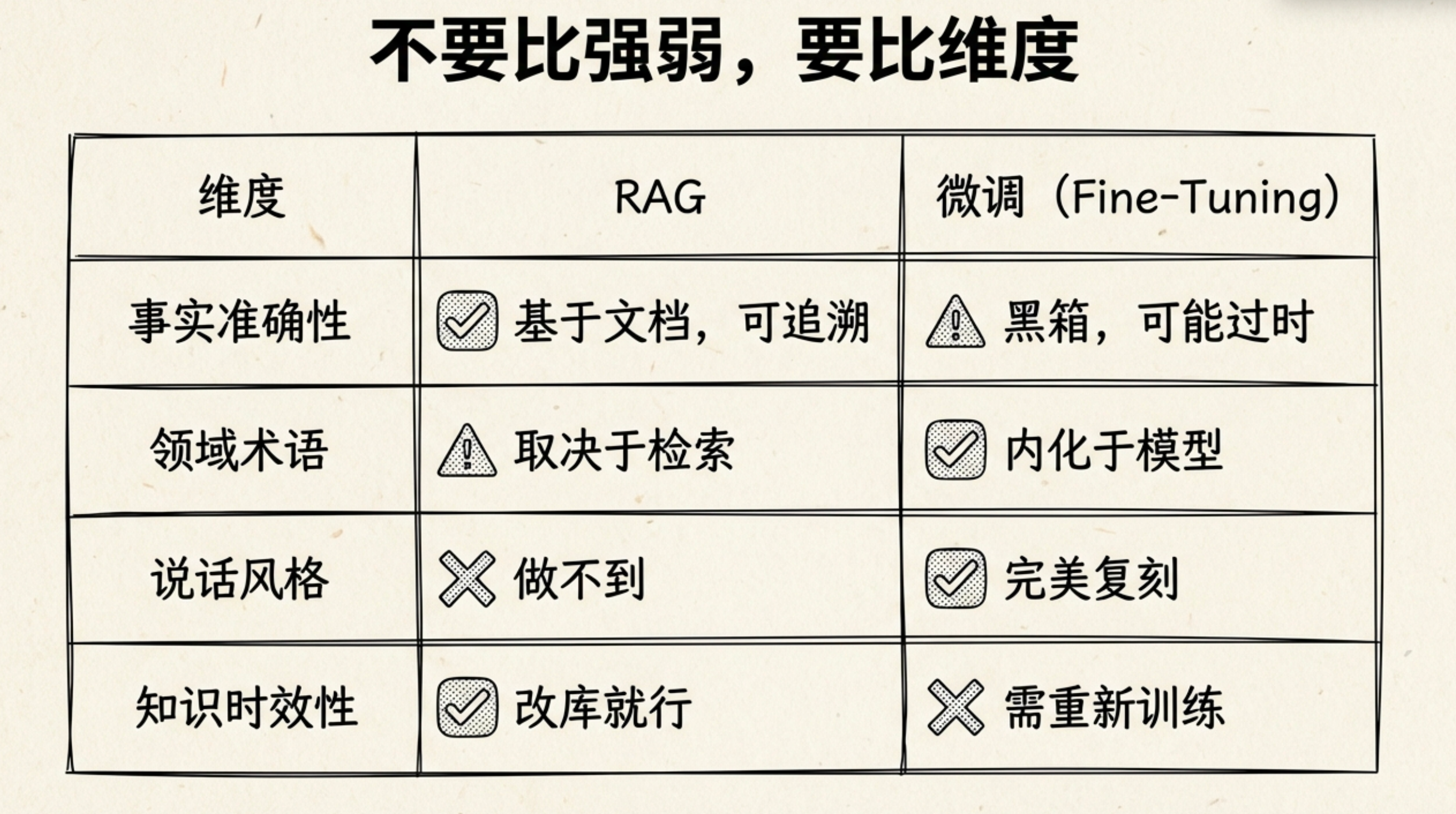
RAG的优势不是”不幻觉”,而是可追溯。出了问题你能查到它参考了哪些文档,能定位是检索的问题还是生成的问题。微调模型幻觉了,你根本不知道它从哪学来的这个错误知识。
所以正确的说法是:RAG不是更准,而是更可控、更可追溯。
第二个错:”更准”这个说法太绝对
微调在特定领域其实可以非常准。
比如你做冰雪装备电商的导购客服,微调过的模型对”全地域板””公园板””固定器硬度”这些术语的理解,比通用模型强得多。它知道”binding”和”固定器”是一个东西,知道新手问”买什么板”的时候不能直接推竞技款,知道怎么用聊天的语气推荐而不是念参数表。
这些东西RAG做不到。RAG只能给模型喂产品文档,但模型怎么”说话”、用什么导购风格、什么场景下推什么档次,这是微调的活。
所以不是谁更准的问题,而是准在不同的地方:
图注:与下表对应,强调“事实可追溯 vs 能力内化”的能力边界。
等一下,提示词不能解决风格问题吗?
有人会说:说话风格不一定要微调啊,写个好的系统提示词不就行了?
说得对,但只对了一半。
提示词确实能控制风格。你在 system prompt 里写”你是一个专业的冰雪装备导购,语气亲切但不油腻,推荐时先问用户水平再给建议”,模型确实能照着做。很多小公司实际落地就是这么干的——调 ChatGPT 或者其他大模型的 API,靠提示词搞定风格。
但提示词有三个硬伤:
- 上下文窗口是有限的。你把产品知识、话术规范、FAQ、退换货政策全塞进提示词,token 很快就爆了。上下文越长,模型注意力越分散,回复质量反而下降。
- 专业知识塞不完。冰雪装备光滑雪板就有几百个 SKU,每个板的参数、适合人群、搭配建议……提示词装不下这些。
- 稳定性不够。提示词控制的风格,换个问法可能就”破功”了。微调是把风格内化到模型权重里,提示词是每次都在”提醒”模型,两者的稳定性不在一个量级。
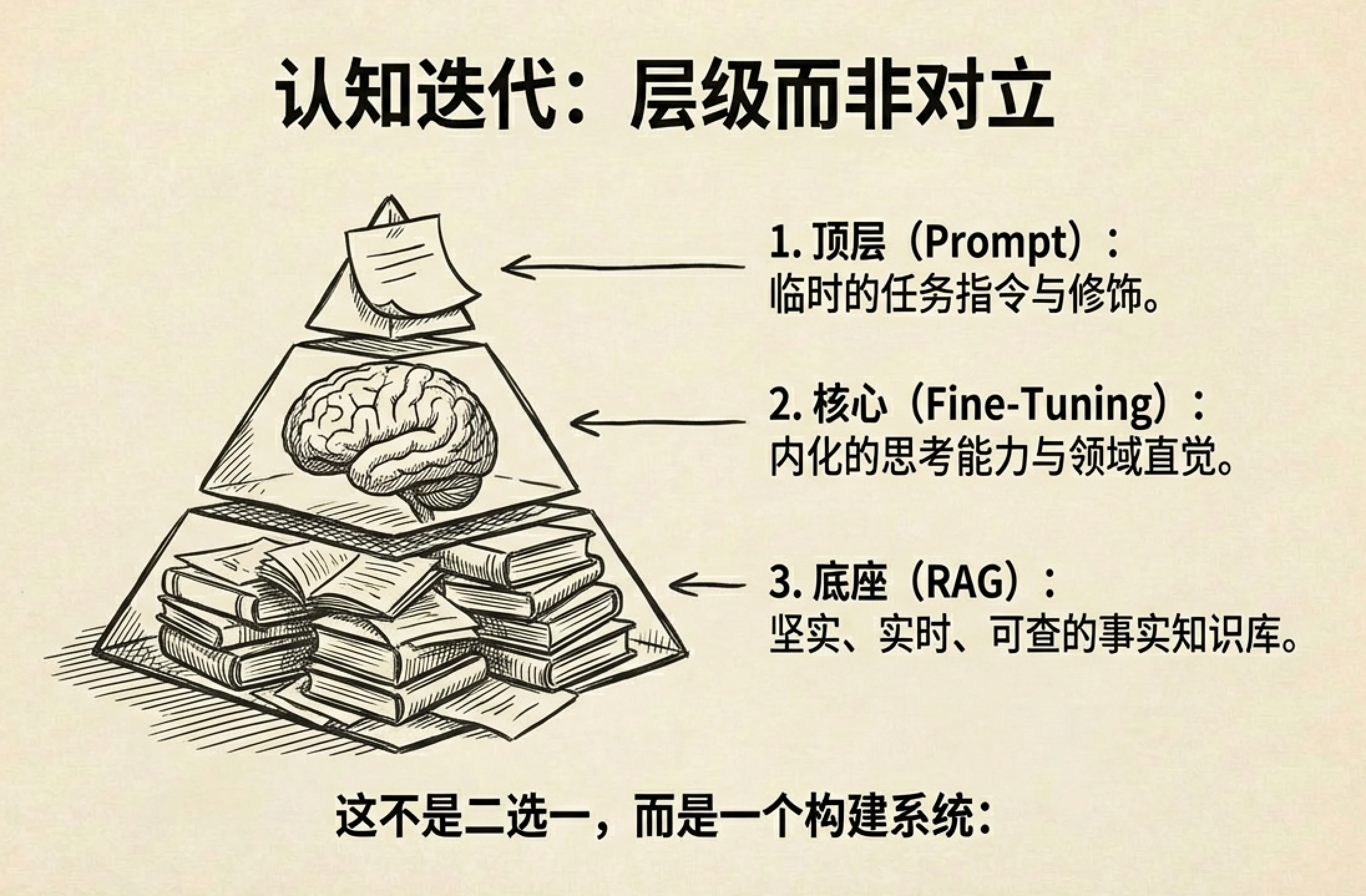
所以实际落地的做法往往是:提示词管基础风格,微调管深度内化,RAG管实时知识。三者不是替代关系,是层级关系。
实际上有些公司两个都上:先微调让模型”懂行”,再用提示词在运行时做精细控制——比如针对不同场景切换话术、控制回复长度、强调某些注意事项。微调打底 + 提示词精调,效果最好,但成本也最高。这又回到了”分工”这个关键词:不是选哪个,而是每一层各管各的事。
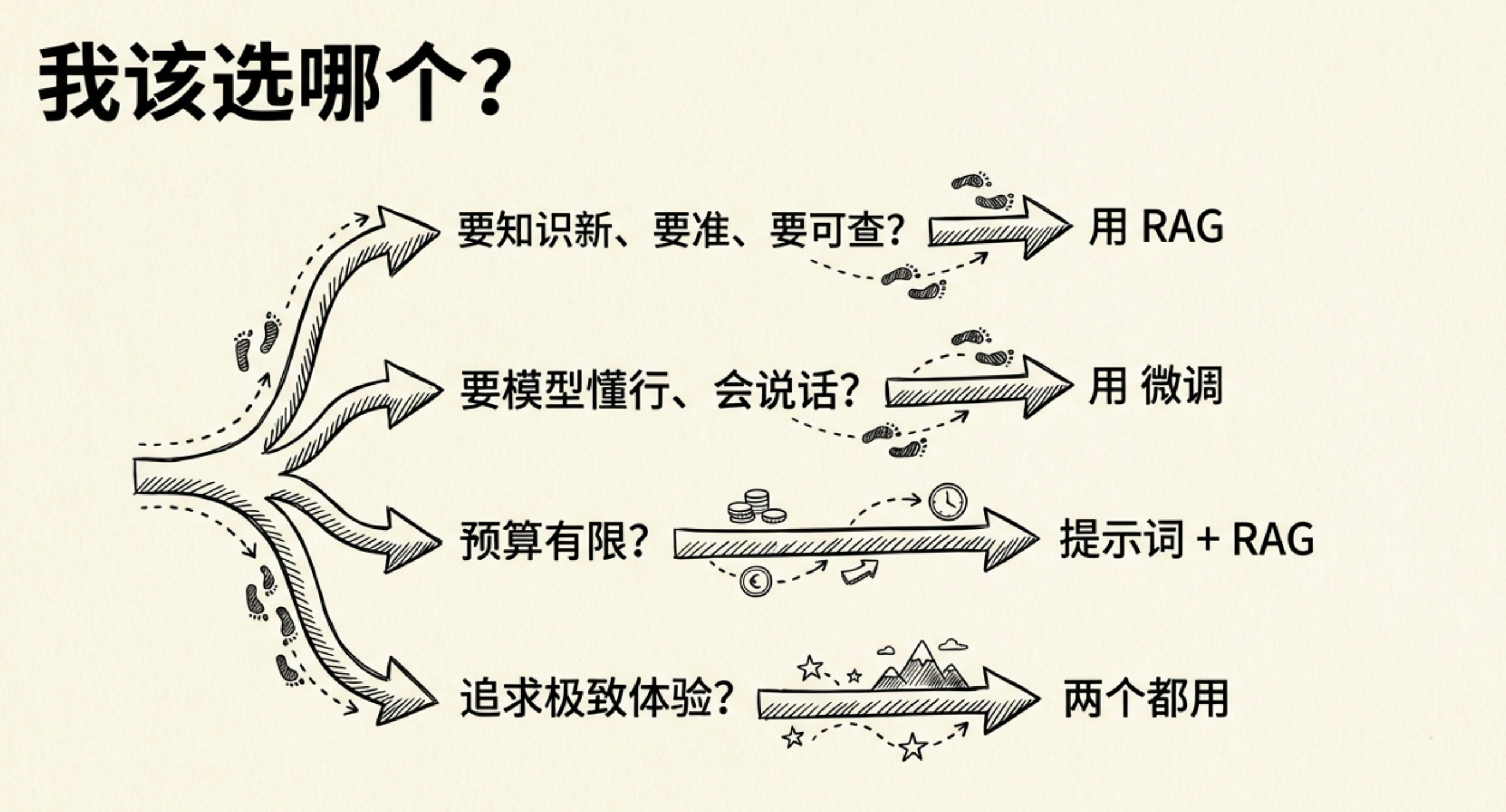
那到底该用哪个?
答案是:看你要解决什么问题。
如果你的核心需求是”知识要新、要准、要可查”: → 用RAG。改商品库比重新训练模型便宜一百倍。
如果你的核心需求是”模型要懂行、会说话”: → 用微调。让模型学会你的领域术语和沟通风格。
如果你预算有限,先不微调: → 用提示词控制风格 + RAG管知识,轻量起步,够用再说。
如果你两个都要: → 两个都用。这不是二选一的问题。
真正落地的方案:两者结合
拿冰雪季电商导购客服举例。
用户问:”新手想买块滑雪板,全地域的,预算3000左右,有推荐吗?”
如果只用RAG:
- ✅ 能从商品库检索到价格、参数、用户评价
- ❌ 回复可能很生硬,像在念商品详情页
如果只用微调:
- ✅ 回复语气像老玩家带新手,知道新手该买软一点的板
- ❌ 价格可能是训练时的旧数据,断货的还在推荐
两者结合:
- 微调负责:导购风格、装备术语、根据水平推荐档次
- RAG负责:实时库存、当前价格、促销活动、用户评价
- 结果:既专业又准确,还能追溯信息来源
用户问题
↓
微调模型(懂装备、会导购)
+
RAG检索(实时商品信息、库存、促销)
↓
“新手全地域板的话,3000这个预算挺合适的~
目前在售的有Burton Process和Ride Warpig,
Process偏软一点更适合新手,现在冰雪季活动价2899,
Warpig稍硬但转弯更灵活,3199。
你平时滑的多是雪道还是想玩玩公园?我帮你细选一下~”
这才是一个真正能落地的回答。不是RAG或微调单独能做到的。
图注:对应“用户问题→能力层(微调)+知识层(RAG)→最终回答”的组合流程。
成本才是真正的决策因素
聊完技术,说点现实的。
图注:用于承接“技术选择最终回到预算与团队能力”的现实约束。
很多时候选RAG还是微调,不是技术问题,是钱的问题。
微调的成本:
- GPU训练:几百到几万美元(看模型大小和数据量)
- 数据标注:人工标注训练数据,耗时耗力
- 迭代验证:训练完不一定好用,可能要反复调
- 知识更新:产品信息变了?重新训练一轮
RAG的成本:
- 知识库搭建:商品文档切片、向量化、入库(一次性)
- 运行成本:每次查询的检索+生成费用(持续)
- 知识更新:改商品信息、重新向量化就行(轻量)
对于大部分中小公司来说,微调的前期投入太重了。RAG是更现实的选择。
但如果你是大厂,有专门的算法团队,有标注好的数据,有GPU集群——那微调+RAG的组合方案才是终极形态。
我的认知迭代
回到开头那个问题:”为什么用RAG而不是微调?”
我现在的回答:
不是”而不是”,是”和”。
RAG和微调不是对立的,是分工不同的。RAG管事实,微调管能力。一个是给模型喂最新的知识,一个是让模型变得更聪明。
就像一个冰雪装备导购:
- 微调让它变成”懂装备的老玩家”(能力)
- RAG让它随时查到最新的库存、价格和促销(知识)
两者缺一不可。
如果非要二选一?大部分场景选RAG,因为便宜、灵活、可控。实在没条件微调的话,提示词+RAG也能撑起来,只是要接受它的局限——模型的”气质”和领域深度,终究没有微调来得彻底。但如果你追求极致的用户体验,两个都上。
工具是为了解决问题,不是为了站队。
本文由 @ChenXiaowu 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


