
 起点课堂会员权益
起点课堂会员权益LLM背后的模型训练原理是什么?
“百万级 Token 喂养、参数反复微调,强大 LLM 的训练藏着哪些核心逻辑?从论文到落地,AI 产品经理带你拆解大模型的 “成长密码”~解锁训练全流程,看懂模型从 “词语组合器” 到 “对话高手” 的蜕变!”

中文示意

通往LLM的路径

### 奖励模型介绍(RM)
-训练RM:“奖励模型” (RM) 身也是一个单独的模型(通常是一个较小的LLM)。而我们用来训练它的“教材”,正是那些“人类偏好排序数据”。
-RM的目标: 它的目标不是“生成答案”,而是“给答案打分”。它要学会**“模仿”人类标注员的“品味”。
阶段一:通识教育(预训练 Pre-training)
这是“学生”的大学本科阶段。
学生(大模型): 一个拥有超强“记忆”和“模式识别”能力,但(目前)空无一物的“大脑”(例如一个70B参数的Llama 3)。
教材(训练数据): 人类历史上几乎所有的“公开书籍、网页、代码”等(数万亿的Tokens)。
唯一的课程(训练任务): “超级填空题”。我们强迫“学生”阅读海量的教材,然后不断地“遮住”下一个词,让他去“预测下一个词”。
毕业成果(Base Model):“学生”毕业了。他“博学”到了极致——他读完了整个图书馆,掌握了语法、逻辑、事实知识和编码能力。
个人信息删除 (PIT) — 出于隐私考虑,收集的文本中发现的任何个人数据都会被过滤掉。(以fineweb数据集为例)
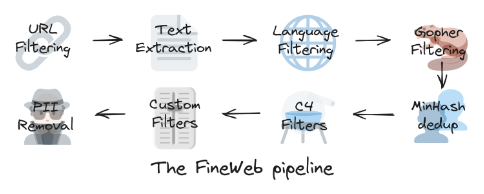
这张图展示的是 「FineWeb 数据清洗管线(FineWeb pipeline)」——它描述了大语言模型(LLM)在构建训练数据集前,对网页数据进行多层过滤与清洗的流程。

2025年的今天互联网的数据量粗算已经来到了175ZB(泽字节1ZB≈1024³GB),但LLM需要的是筛选后的高质量文本。
完成以上步骤后,数据集就准备就绪了。您可以点击此处查看示例数据集:FineWeb 数据集。如需了解更多处理信息,请访问FineWeb Processing v1。

简单说明一下commoncrawl的爬取模式:
CommonCrawl 是一个非营利项目,它会 定期用网络爬虫抓取整个互联网的网页内容,并把结果公开存储在 AWS(Amazon S3)上,供研究者和企业免费下载、训练大模型。
⚙️ 工作模式简述
1)广度优先爬取(breadth-first crawl)
-
- 从一组起始网址(seed URLs)开始,比如新闻、博客、百科等。
- 从这些网页提取出新的链接,不断扩展爬取范围。
- 目标是覆盖尽可能多的公开网页,而不是聚焦某个主题。
2)定期更新(monthly crawl)
-
- 每月执行一次大规模爬取(称为一个 crawl batch)。
- 每次更新大约采集 30~50 亿个网页,体量在 数十 TB 级。
- 新旧网页会合并存档,形成长期可追溯的数据集。
3)数据结构化与存储
-
- 抓取内容以 WARC 格式(Web ARChive) 保存,包含网页 HTML、响应头等信息。
- 后续可用工具提取出纯文本(用于训练数据集如 C4、FineWeb)。
4)开放共享
-
- 数据全部免费开放,可直接在 AWS 或 Hugging Face 等平台获取。
- 很多大模型(如 GPT、Claude、LLaMA、Mistral)都在预训练阶段使用过它。
URL过滤规则网站示例https://dsi.ut-capitole.fr/blacklists/
最后得到例如“fine web”的数据集,这些纯粹的人类语言的文本数据。(如觉得不直观可去看看最后fine web的数据集中的真实文本数据https://huggingface.co/datasets/HuggingFaceFW/fineweb)
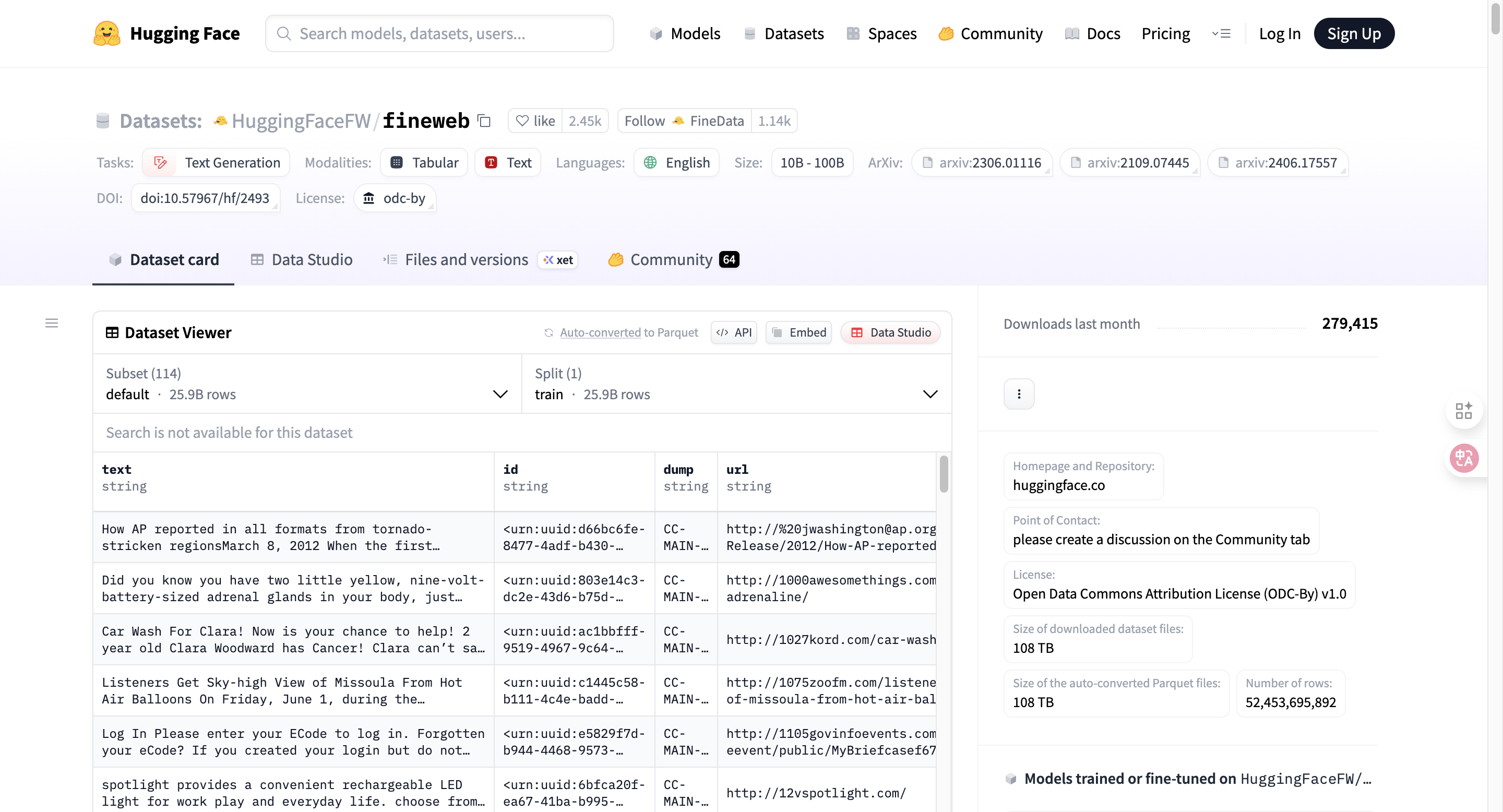
【fine web中的爬取后并筛选出来的高质量文本数据】
开始制作模型数据集
“数据集构建 → 语料拼接阶段”,这一步相当于为模型准备“食物”,让它能通过大量文本去模仿语言规律。
直观理解
假设你前面已经收集了许多文本样本,比如:

我把所有前文获得的文本排列在一起组成模型数据集(一维文本),就像这样:

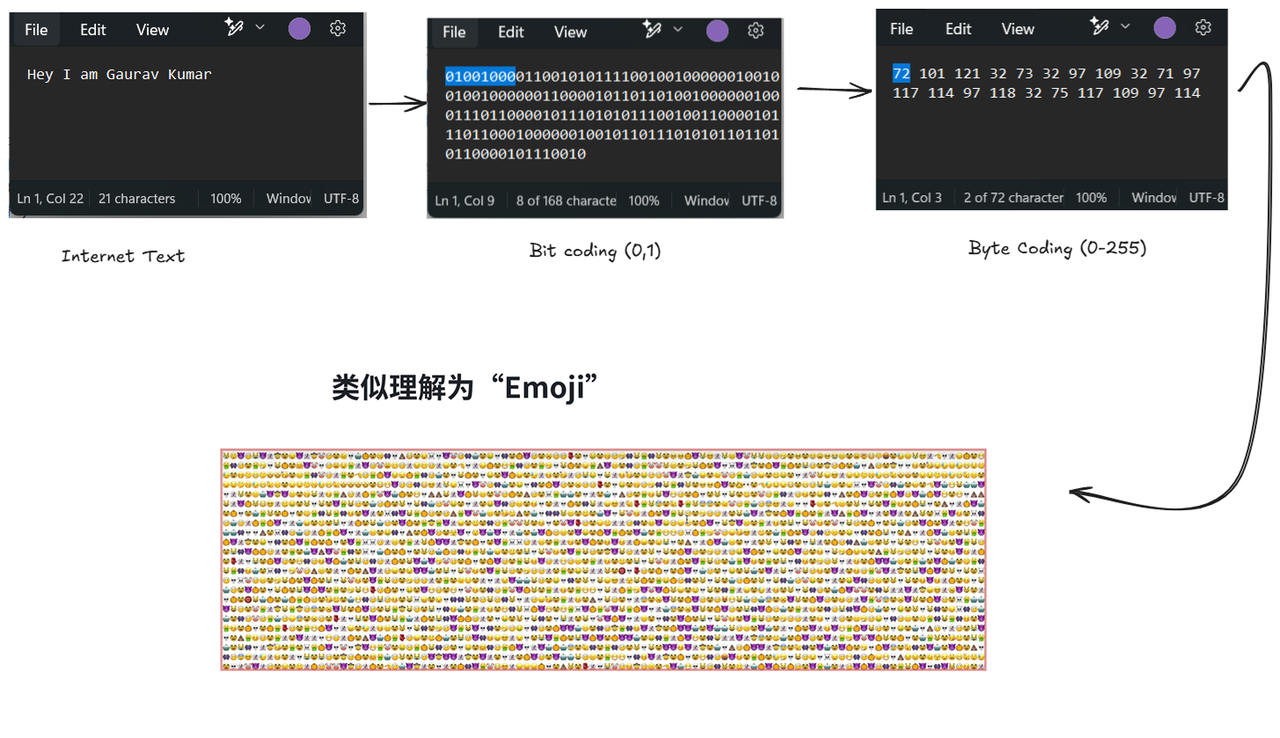
这些文本在底层编码后,得到的计算机中对应这段文本的原始比特数据,而展示的一种特定的表示方式:

像这样,我们就把获得的文字数据集变成了计算机能够读懂的,由0 & 1两个符号组成的,专属于计算机的“文本序列”。
符号压缩
- 为了提高神经网络的训练与调用效率,我们将高频符号或字节压缩成新的符号,减少序列长度。
- 这些符号并非数字,而是便于网络理解的“单位”,类似“”。
- 符号集越丰富,数据压缩率越高,整体效率越好。
Tokenization 就是在创造自己的“Emoji语言”:
- 高频词 → 单一符号(例如“人工智能”→)
- 高频短语 → 单一符号(例如“改变世界”→)
- 低频词 → 保持拆分(例如“纳米机器人”→“纳米”“机器人”)
- 这样模型“看”到的序列就更短、更高效。
- 总体流程:文本 → 字节 → 高频模式提取 → 新符号表 → Token序列
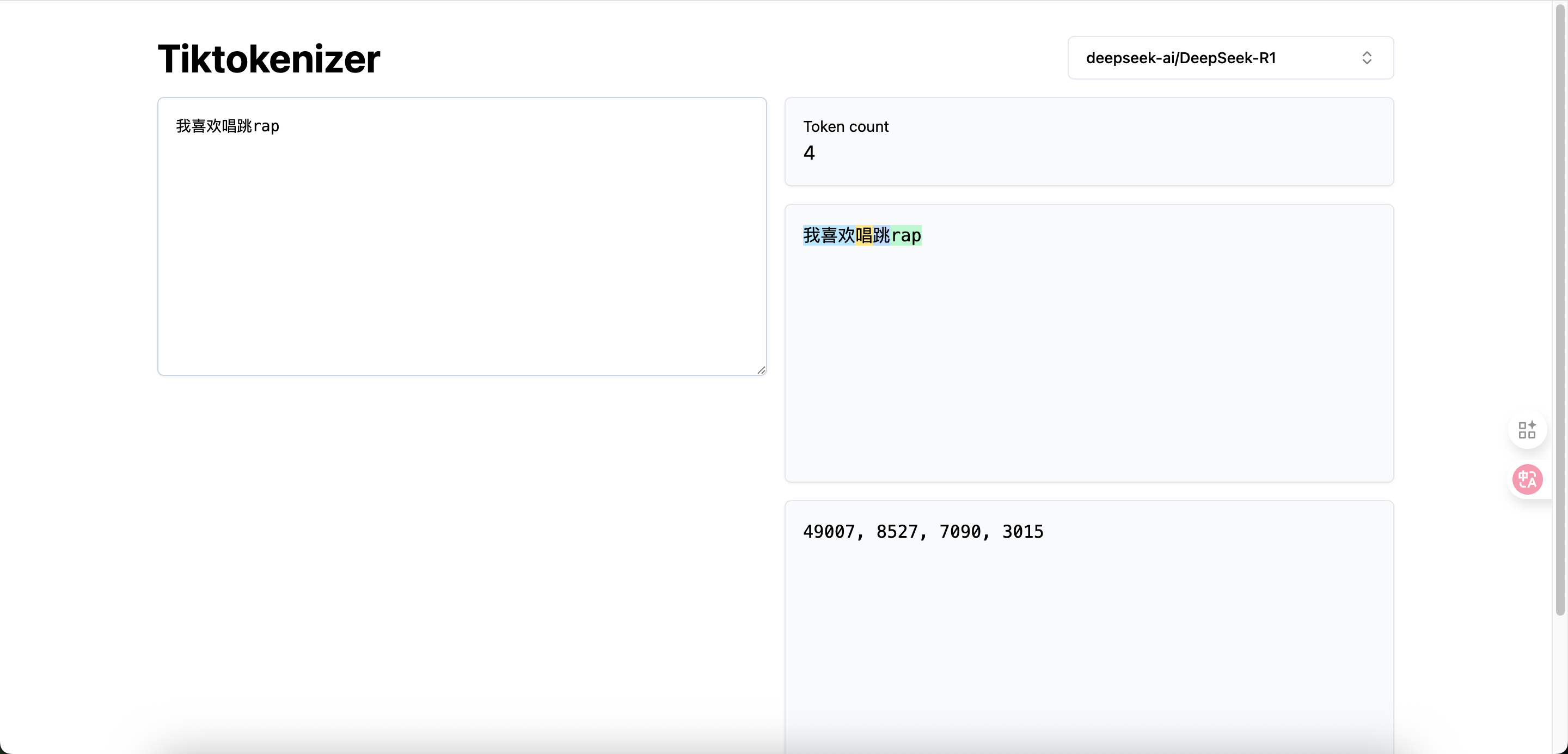
想看看 Deepseek R1是如何对文本进行分词的吗?试试这个工具:Tiktokenizer
如何训练基础大模型
训练神经网络(neural network training)的过程的这个阶段,是计算量最大、最耗费资源的部分。
输入是什么?——上下文序列(Context Tokens)
这些数字就是已经 Tokenized 的符号,也就是模型看得懂的“字母表”。
每个数字代表一个词或词组,例如:

这就是模型的“输入序列”,它会用这段上下文去预测下一个最可能出现的 Token。
输出是什么?——下一个 Token 的概率分布
“预测下一个可能的内容 {【tokens】}”
模型并不会只给一个答案,而是给出一个概率分布,例如:
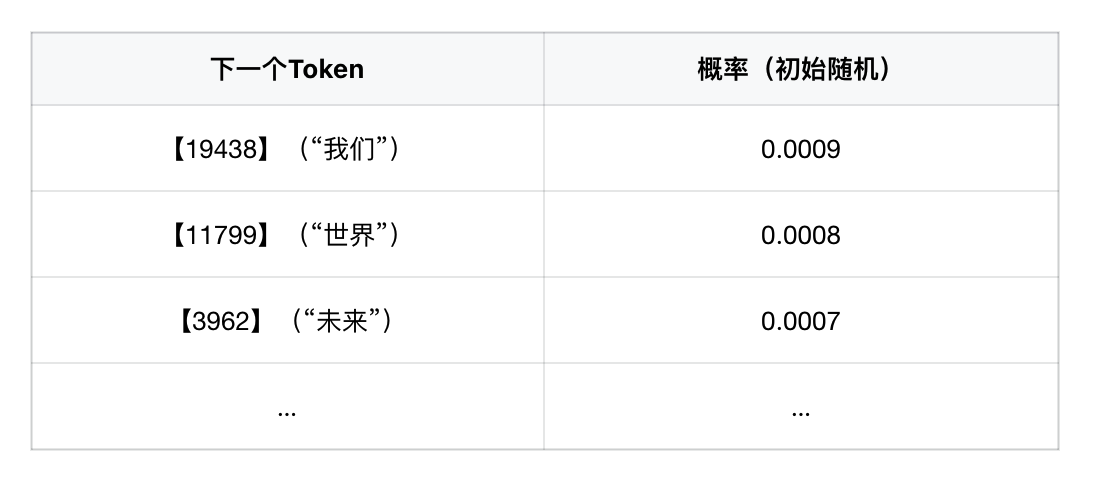
因为词汇表有 100,277 个 Token(以 GPT-4 为例),模型一开始根本不知道哪个是对的,所以输出几乎是随机的。
模型如何“学会”哪个才对?——梯度下降(Gradient Descent)
“我们使用一个数学公式(比如核心的梯度下降)去更新神经网络。”
这一步是训练的灵魂。
简单来说就是:
比较预测结果和真实答案(称为“损失函数 loss”)
➤ 看看模型猜得有多离谱
计算误差的梯度
➤ 哪些权重参数导致错误最大
更新权重(反向传播 Backpropagation)
➤ 调整神经元的“连接强度”,让正确词的概率上升、错误词下降
就像老师批改作文、学生不断改错,神经网络会经过上亿次这样的“纠错”。
再输入一次,模型就变“聪明”了
“更新神经网络后再输入相同的 tokens,模型就会有所调整,得出新的结果。”
这时:
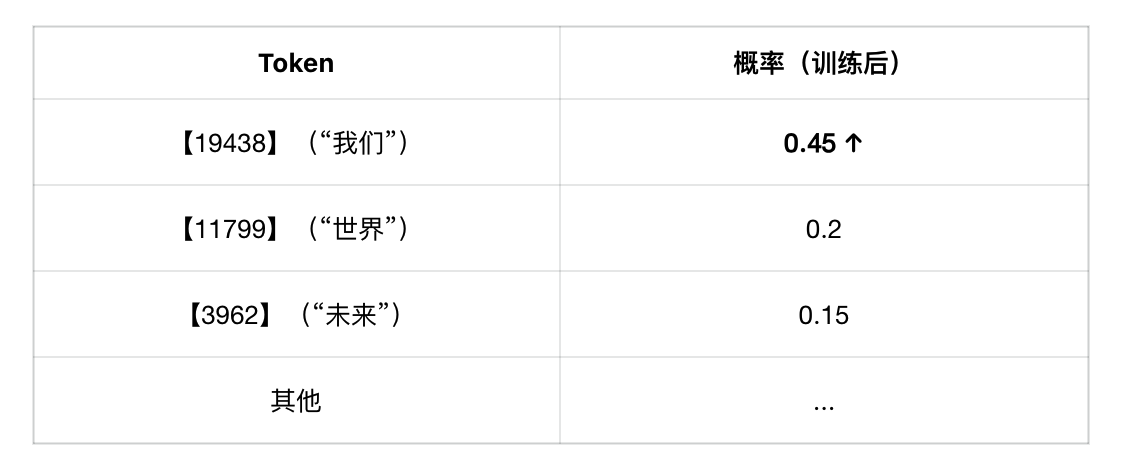
模型“记住了”这个上下文下,“我们”最可能是正确答案。
这就是从随机 → 有序 → 拟合语言规律的过程。
总结一句话
训练神经网络的本质:
在海量文本中不断预测“下一个词”,通过梯度下降调整权重,让正确词的概率越来越高。
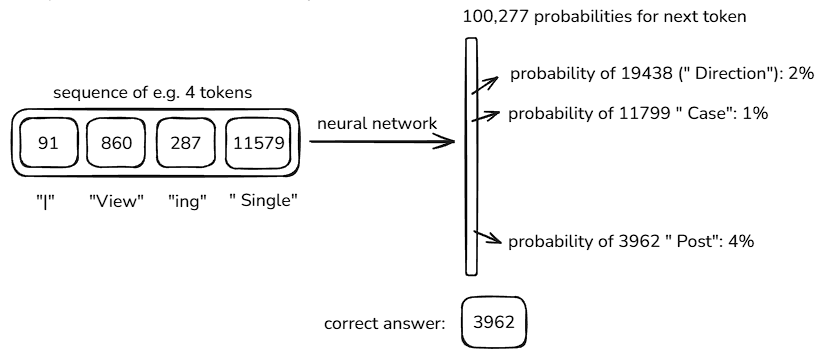
神经网络预测下一个词元的图像
这就是神经网络的训练过程,它的本质就是找到一组合适的参数设置,让预测结果与训练集的实际统计数据的特征相符。使词元之间的关联概率一致,这些tokens相互跟随的统计规律与数据集中的一致
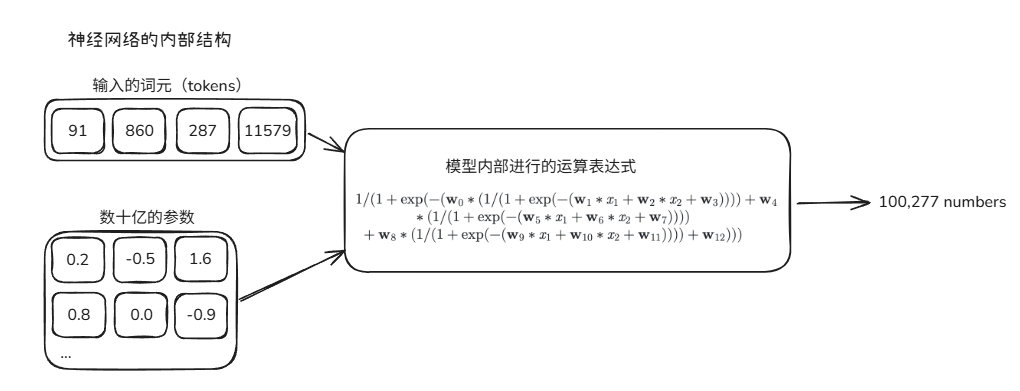
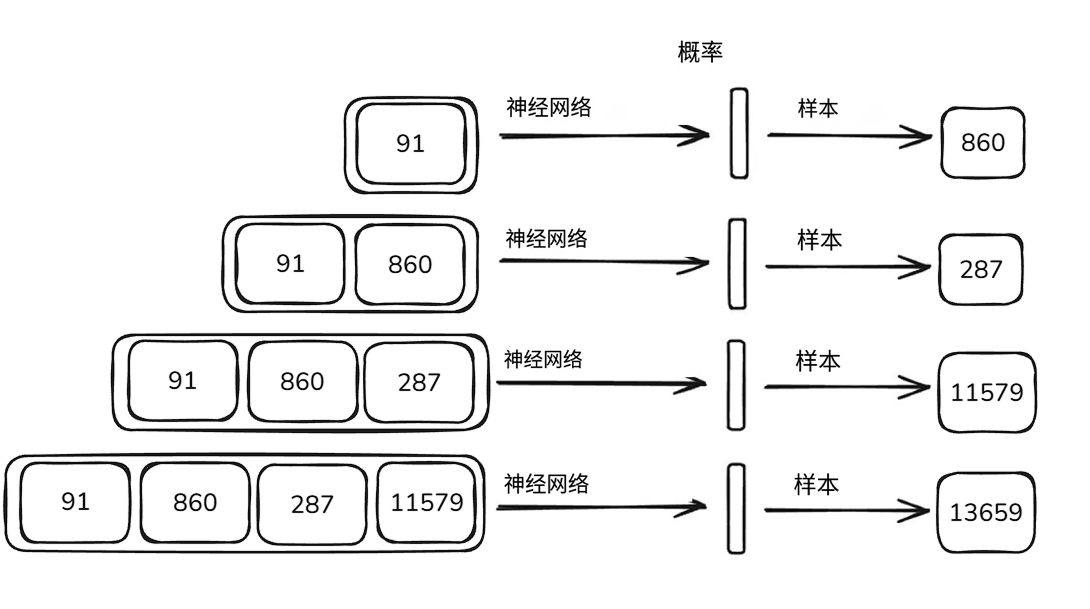
图片逐步演示推理过程
Transformer 架构:现代 AI 模型的核心运转逻辑
先快速拆解模型的核心骨架 ——Transformer 架构:2017 年,论文《Attention is All You Need》的横空出世,让 Transformer 架构正式登场。它不仅是 GPT 系列模型的技术基石,更撑起了整个现代 AI 领域的发展框架。下面用通俗的方式拆解其运转逻辑,帮你快速 get 模型的核心工作原理。
Transformer 的本质,是一套搭载 “自注意力机制” 的数学函数体系。它能让模型在预测下一个词元时,自动聚焦上下文里的关键信息 —— 比如 “周末计划去郊外” 之后,模型会判定 “露营” 比 “编程” 的关联度更高,优先参考前者。这种精准捕捉词语关联的能力,正是 GPT 等模型能理解语境、完成逻辑推理的核心原因。
模型生成答案的具象化流程
- 第一步,我们向模型输入需要处理的词元(tokens),这是模型生成答案的原始素材。
- 模型会调用向量空间(相当于存储 “知识” 的专属数据库)中的权重参数 —— 通过判断词元间的重要性和关联紧密程度,激活对应的 “知识神经元”,启动初步预测。
- 最后,模型同时兼顾所有输入词元和已生成的输出词元,逐词逐步完成答案的 “猜测” 与生成。
【Transformer3D 可视化网站:https://bbycroft.net/llm】
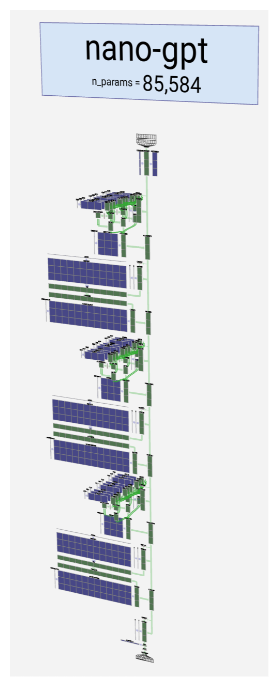
经过上述流程训练出的是基础模型(Base Model)。它虽具备海量知识储备,却算不上合格的实用助手。比如你问它 “如何写一篇旅行攻略”,它可能只回复 “首先确定目的地和出行时间”—— 因为对基础模型来说,这是统计层面最合理的句子补全,而非满足用户需求的完整攻略框架(比如包含交通、住宿、行程安排等核心模块)。而且模型每次生成都带有一定随机性,就像 “掷硬币” 一样,很难输出完全一致的答案。
本质上,基础大语言模型(Base Model)就是一个 “基于统计的词语组合工具”。它的核心目标只有一个:观察给定的文本序列,预测出统计概率上最可能出现的下一个词或字符(即 “词元”)。
接下来,我们通过具体案例和推理过程,让你直观感受其训练与运转效果(以 GPT2 训练为例):
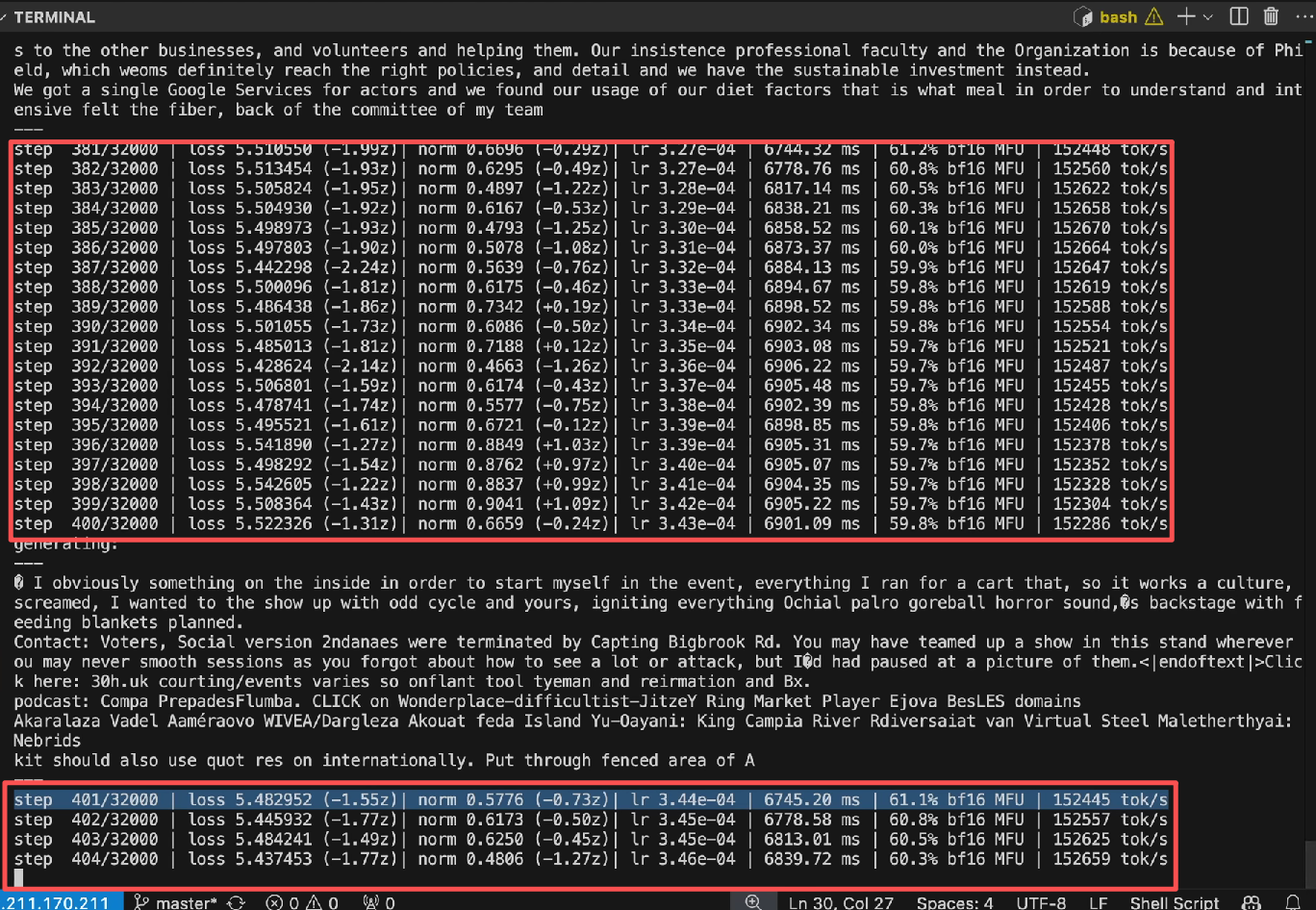
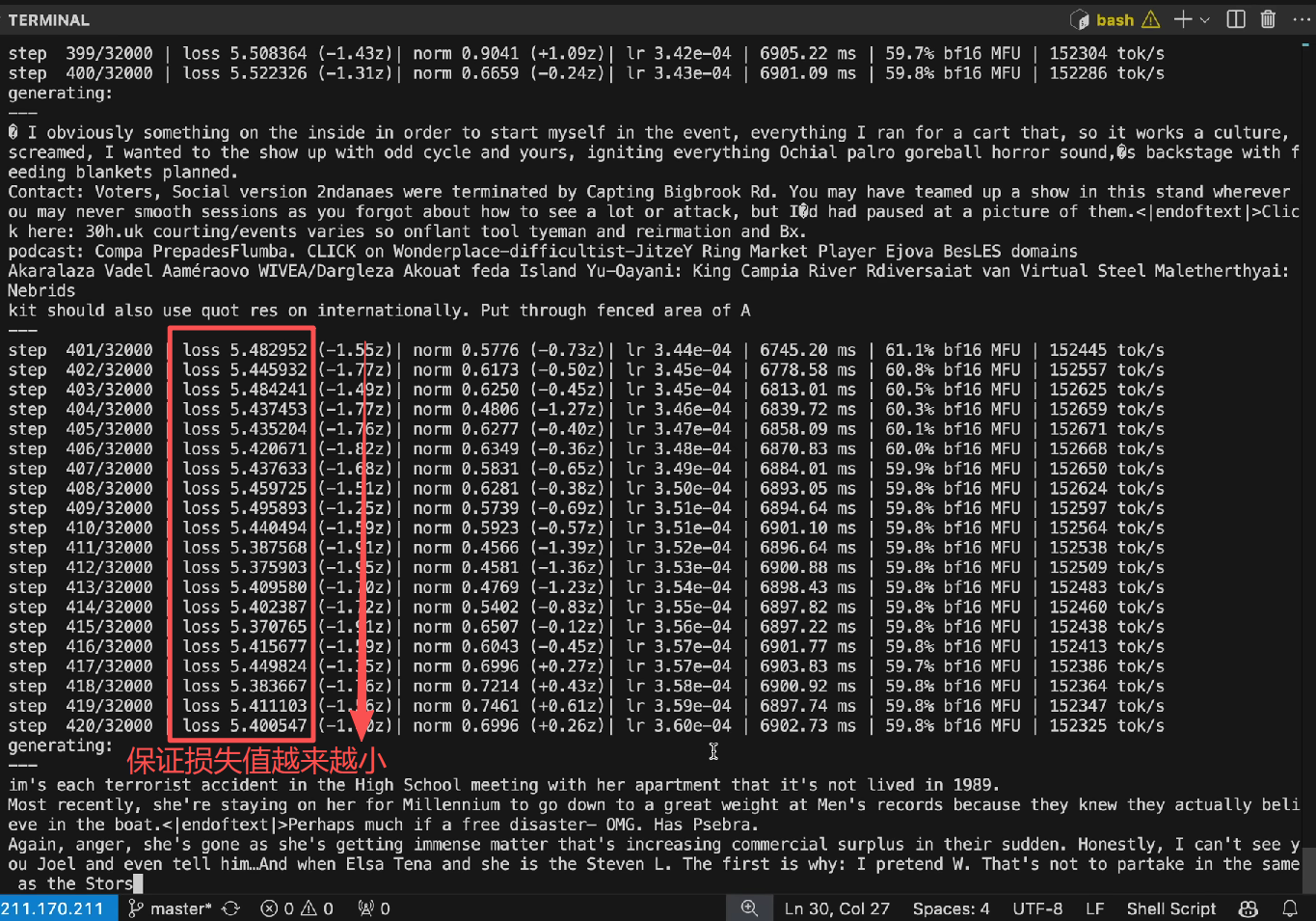
【红框勾选的每一行都是一次模型的更新,每一行都是优化训练集中百万tokens的预测能力。】
在提升模型预测能力的同时,我们也会同步更新每个词元的权重参数,也就是调整神经网络的核心配置。通过不断微调这些参数,模型预测下一个词元的准确率会逐步提升。整个更新过程中,你只需泡一杯咖啡,静静观察电脑上的损失值即可 —— 这个数值直接反映神经网络的当前性能,数值越低,代表模型表现越好。
本文以四吉文档作为参考,感谢!!!
原文:安德烈·卡帕西(Andrej Karpathy)
本文由 @Ai_Chang 翻译发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


