
 起点课堂会员权益
起点课堂会员权益AI PM 进阶笔记【5】:RAG总翻车?90%的坑都在“离线准备”和“重排序”
RAG技术在企业AI落地中的痛点与解法,你真的了解吗?从加拿大航空的‘退款门’到纽约市政府的法律失误,这些真实案例揭示了RAG架构的致命陷阱。本文将深入拆解RAG与LLM的协同逻辑,从知识缺陷到行为缺陷的精准诊断,再到混合检索与语义分块的核心技术,带你避开那些让项目夭折的深坑。
一、场景直击:我们都踩过的RAG落地坑
在企业AI落地一线摸爬滚打多年,我们复盘发现一个共性问题:很多团队兴致勃勃接入大模型做RAG,最后却草草收尾。

1.1 定义维度:理解RAG与“开卷考试”的隐喻
检索增强生成(RAG)是一种系统架构模式,而非单一技术。从本质上看,若将预训练大语言模型(LLM)视为知识截止于训练完成时的主体,传统问答任务即相当于“闭卷考试”——模型需完全依赖内部参数权重(记忆)作答,易因知识缺失或过时出现“幻觉”,即牺牲事实准确性以维持语言流畅性。
RAG架构将其转变为“开卷考试”,核心聚焦LLM的推理与综合能力。面对问题时,模型会先检索外部向量数据库中的相关信息,再基于这些事实材料组织答案。这一转变明确了LLM的企业应用定位:其并非存储事实的数据库,而是处理信息的推理引擎。RAG通过结合数据库的存储检索能力与LLM的推理能力,实现“大脑”(LLM)与“外挂硬盘”(检索器)的协同,达成能力跃升。
1.2 价值维度:RAG解决了LLM的哪些“硬伤”?
企业级应用中,原生LLM存在三大核心缺陷,RAG提供了针对性解决方案。
1.2.1 疗愈“幻觉”:事实的锚定
“幻觉”是生成式AI在严谨场景落地的最大阻碍,RAG可强制模型生成过程锚定在检索到的上下文之中。其核心机制为在生成阶段的提示词中加入限定指令,使模型输出基于外部事实而非单纯内部参数预测;深层价值不仅在于降低错误率,更在于实现可解释性——生成答案可附带引用来源,用户可追溯验证,这是原生LLM不具备的优势。
1.2.2 突破“时效性”:动态知识更新
LLM训练周期长、成本高,训练完成后知识即定格在特定时间点(知识截止日期)。RAG的核心优势在于,企业可通过更新外部知识库实现AI知识的实时更新,无需对模型进行重新训练,大幅降低知识更新的成本与周期。
1.2.3 筑牢“隐私墙”:数据安全与权限控制
企业数据存在权限分级,原生LLM若通过微调纳入全量数据,不仅权限控制技术难度大,还易引发数据泄露风险。RAG将数据留存于数据库层面,成熟向量数据库支持基于角色的访问控制(RBAC),检索时仅返回用户有权限查看的内容,LLM仅在单次请求中临时获取数据,请求结束后即“遗忘”,实现数据安全与模型能力的隔离。
核心不是技术不行,而是从一开始就踩了坑。以下是真实发生的行业血泪史:
(Case1)航空/客服团队:加拿大航空(Air Canada)“退款门”
1. 事故
航司的RAG客服机器人误解了丧亲退款政策,向用户承诺了并不存在的“先买票后退款”政策。
2. 后果
2024年,加拿大民事法庭裁定航司败诉,必须按机器人承诺进行赔偿。法庭驳回了航司关于“机器人是独立实体”的辩护。
3. 来源
BBC News / 加拿大民事裁决庭 (CRT) 2024年公开判决书
(Case2)政务/法律团队:纽约市政府“MyCity”聊天机器人
1. 事故
该机器人利用RAG技术回答企业主问题,但错误地建议雇主“可以克扣员工小费”以及“没有任何法律规定商家必须接受现金”,这些完全违反了当地法律。
2. 后果
纽约市政府被迫在页面显著位置添加免责声明,并紧急人工介入修正。
3. 来源
The Verge / 纽约时报 2024年4月报道
(Case3)汽车/销售团队:雪佛兰经销商(Chevrolet of Watsonville)
1. 事故
用户通过诱导性提问(Prompt Injection),让接入了GPT的客服机器人同意“以1美元的价格出售一辆2024款雪佛兰Tahoe”。
2. 后果
聊天截图在社交媒体病毒式传播,导致该经销商不得不暂时关闭聊天服务。
3. 来源
Business Insider 2023年12月报道
(Case4)法律行业:律师引用虚假案例(Mata v. Avianca案)
1. 事故
纽约律师Steven Schwartz使用ChatGPT(虽非RAG架构,但原理一致:过度依赖模型生成)撰写法律简报,引用了6个完全不存在的虚假判例。
2. 后果
律师面临法庭制裁和巨额罚款,职业生涯受损。
3. 来源
纽约南区联邦地区法院2023年法庭记录
小总结
1. 把原生大模型当“全知全能的专家”,而忽视了它本质上是一个“概率预测机”
2. 检索增强生成。给学霸配一本“实时更新的参考书”,并且强行要求他“不仅要查书,还要告诉我这一行在书的第几页”。
二、核心认知:先搞懂这3个问题,再动手搭RAG
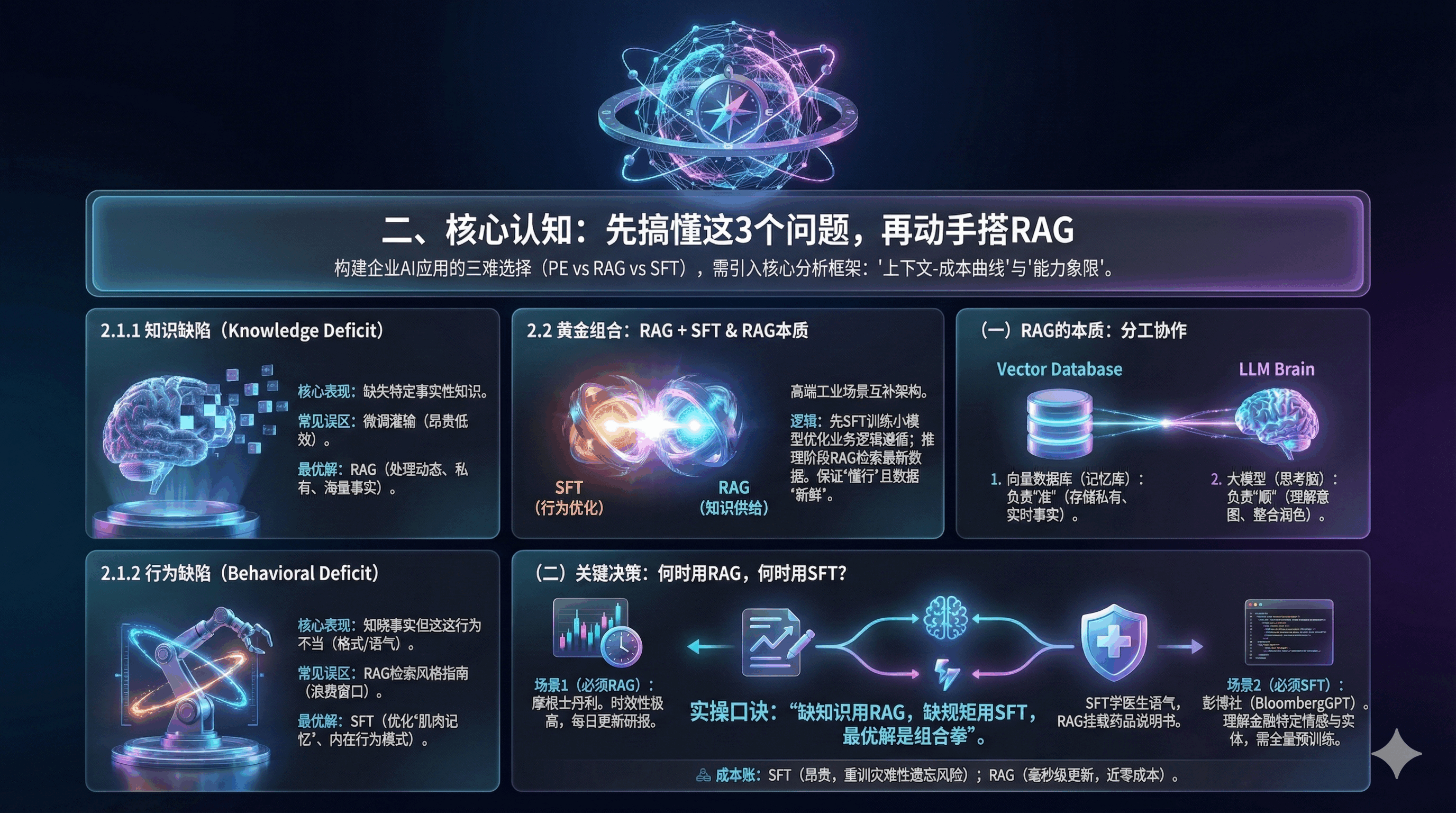
在构建企业AI应用时,架构师往往面临经典三难选择:是编写复杂提示词(Prompt Engineering, PE),还是外挂知识库(RAG),亦或是微调专属模型(Supervised Fine-Tuning, SFT)?科学决策需引入核心分析框架:“上下文-成本曲线”与“能力象限”。
2.1 核心区分:知识缺陷 vs 行为缺陷
决策第一步是诊断模型问题,需将其归类为“知识缺陷”(Knowledge Deficit)或“行为缺陷”(Behavioral Deficit)。
2.1.1 知识缺陷(The Model Doesn’t Know)
核心表现为模型缺失特定事实性知识;常见误区是通过微调灌输此类知识,不仅昂贵且低效,因LLM知识压缩效率远低于数据库且易遗忘;最优解为RAG,其是处理动态、私有、海量事实性知识的合理方案。
2.1.2 行为缺陷(The Model Doesn’t Act Right)
核心表现为模型知晓事实但行为不符合需求,如格式错误、语气不当等;常见误区是通过RAG检索风格指南纠正,易浪费上下文窗口且效果不稳定;最优解为SFT,其擅长调整模型的“肌肉记忆”,优化说话风格、指令遵循能力等内在行为模式。
2.2 三大技术的深度对比矩阵
以下从成本、性能与适用场景维度,对三种技术路线进行深度对比总结。
2.2.1 黄金组合:RAG + SFT
高端工业场景中,三者并非互斥而是互补,“RAG + SFT”是极具优势的架构。核心逻辑为:先通过SFT训练小参数量模型,优化其对企业术语的理解与业务逻辑的遵循(行为层面);推理阶段再通过RAG检索最新业务数据喂给模型(知识层面)。该组合既保证模型“懂行”,又确保数据“准确新鲜”,且小模型推理成本远低于直接调用大模型。
(一)RAG的本质:不是“技术”,是“分工协作”
RAG架构的核心分工如下:
1. 向量数据库(记忆库)
负责“准”。存储私有数据、实时事实。
2. 大模型(思考脑)
负责“顺”。理解意图、整合信息、润色语言。
(二)关键决策:何时用RAG,何时用SFT(微调)?
建议插入决策树图表:根据数据动态性和知识范围选择技术路径
实操口诀: “缺知识用RAG,缺规矩用SFT,最优解是组合拳”。
1. 场景1(必须RAG):摩根士丹利(Morgan Stanley)财富管理助手
需要基于每天更新的十万份研报回答问题,知识时效性要求极高。
来源:OpenAI 官方客户案例库
2. 场景2(必须SFT):彭博社(BloombergGPT)
需要模型理解金融特有的复杂情感分析和命名实体识别,通用模型无法胜任,必须基于金融语料全量预训练/微调。
来源:Bloomberg 2023 技术论文
3. 场景3(RAG+SFT):医疗问诊
先用SFT让模型学会“像医生一样说话”(语气、格式),再用RAG挂载最新的药品说明书(知识)。
4. 成本账(更新版)
SFT: 训练一次数千至数万美元,且每次知识更新都要重训(灾难性遗忘风险)。
RAG: 知识更新只需更新数据库(毫秒级,接近零成本)。
三、避坑前提:别把RAG当成“检索+生成”两步走
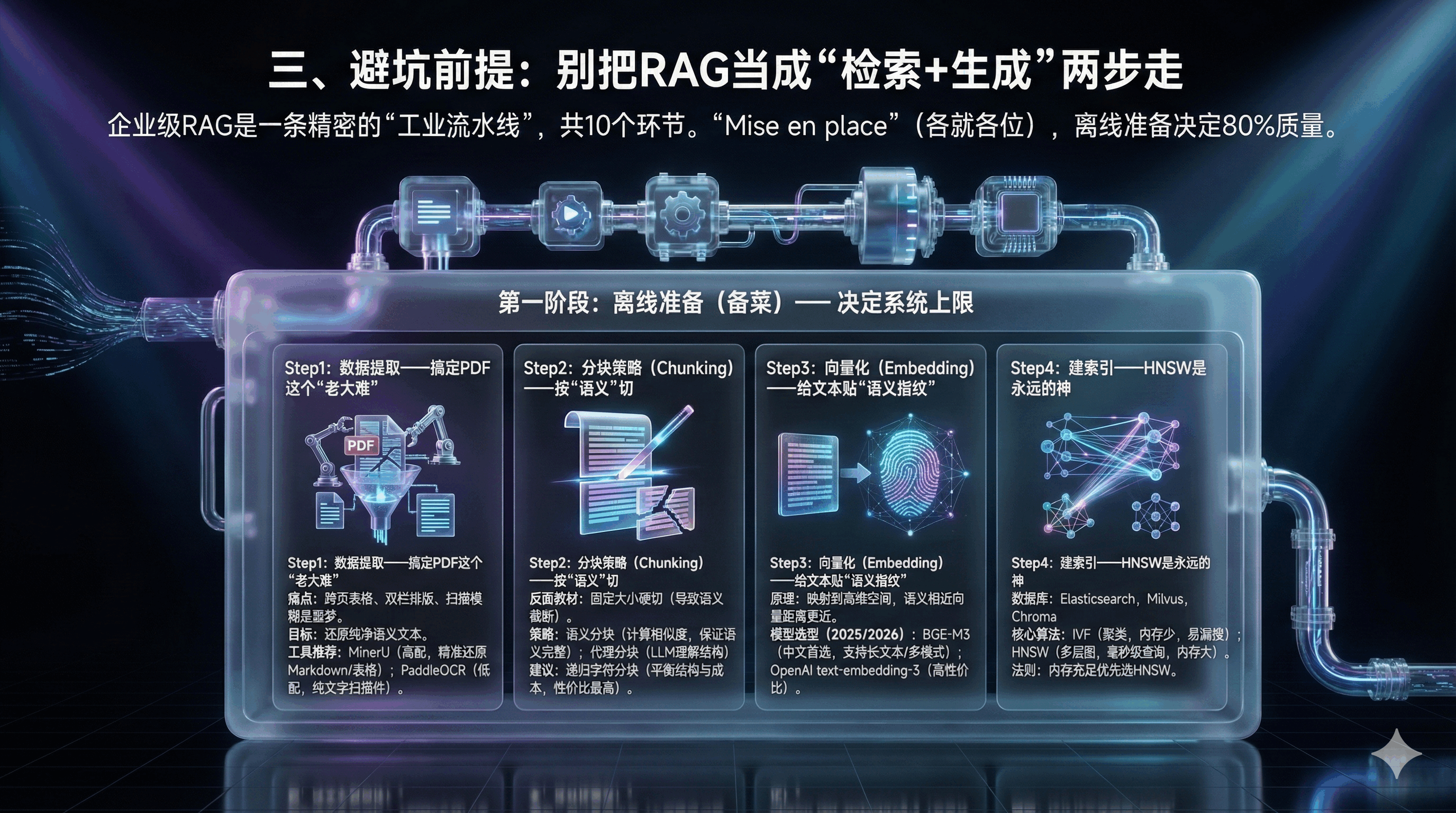
企业级RAG是一条精密的“工业流水线”,共10个环节。
在烹饪界,有一句名言:“Mise en place”(各就各位)。如果厨师在客人点单后才开始洗菜、切肉,那餐厅必将倒闭。同理,RAG 系统的质量,80% 取决于离线阶段的数据处理质量。这直接对应了 AI 领域的铁律:Garbage In, Garbage Out(垃圾进,垃圾出
第一阶段:离线准备(备菜)—— 决定系统上限
Step1:数据提取——搞定PDF这个“老大难”
真实痛点: PDF中的跨页表格、双栏排版是RAG的噩梦。
企业数据并不像互联网文本那样干净。它们隐藏在 PDF 的表格里,PPT 的图表中,以及扫描件的模糊字迹中。数据提取的目标是将这些非结构化数据还原为纯净、带有语义结构的文本。
PDF 是为打印而生的格式,而非为机器阅读而生。
多栏排版:传统的提取器往往会横跨两栏读取文字,导致语义拼接错误;
表格与公式:复杂报表提取后易变成无意义字符流,丢失行列关系;
扫描件:图片格式文档需 OCR,但手写体或模糊文档的传统 OCR 错误率极高。
工具推荐(实测有效)
高配(GPU资源充足):MinerU (Magic-PDF)
特点: 上海人工智能实验室OpenDataLab开源。基于视觉模型,能精准还原Markdown格式,保留表格结构。
适用: 研报、论文。
低配(CPU/轻量级):PaddleOCR / RapidOCR
特点: 百度飞桨生态,OCR识别率高,但对复杂版面还原度弱于MinerU。
适用: 纯文字扫描件。
Step2:分块策略(Chunking)——按“语义”切
反面教材: 直接按500字硬切。导致一句话被切断,检索时丢失上下文。
策略一:固定大小分块 (Fixed-size Chunking) —— “快餐切法”
按固定字符数切分(如每 500 字符一切,保留 50 字符重叠)。
优点:计算成本低、易实现;
缺点:易出现“语义截断”,导致上下文碎片化,破坏逻辑连贯性 。
策略二:语义分块 (Semantic Chunking) —— “米其林切法”
按语义逻辑切分,而非字符数。
机制:计算句子间余弦相似度,将高相似度句子归为同一 Chunk,遇相似度骤降则拆分 (16);
价值:保证每个 Chunk 为完整语义单元,大幅提升检索相关性;
代价:需对句子进行 Embedding 计算,离线处理成本显著增加。
策略三:代理/大模型分块 (Agentic Chunking) —— “主厨定制”
利用 LLM 理解文档结构并切分,如通过提示词要求拆分逻辑独立章节。
评价:效果最佳,但 API 调用与时间成本极高,仅适用于高价值文档处理 。
工业界建议:多数应用场景下,递归字符分块(Recursive Character Chunking)性价比最高,优先按段落换行符切分,无法切分再按句子拆分,平衡结构保留与成本控制。
Step3:向量化(Embedding)——给文本贴“语义指纹”
切分后的文本块需转换为计算机可理解的向量(Vector)。
原理:Embedding 模型(如 BGE, OpenAI text-embedding-3)将文本映射到高维空间,语义相近文本的向量距离更近 ;
双编码器 (Bi-Encoder):离线阶段常用架构,独立编码文档为静态向量,可存储复用,不依赖后续查询
模型选型(2025/2026 推荐)
中文首选: BGE-M3 (BAAI/bge-m3)。
理由: 北京智源出品。支持多语言、支持长文本(8192 token),且同时支持稠密检索(Dense)和稀疏检索(Sparse),泛化能力极强。
OpenAI生态: text-embedding-3-small/large。性价比极高。
Step4:建索引——HNSW是永远的神
数据库选型
海量向量需建立索引以提升查询效率,避免暴力搜索导致的速度问题。
推荐:
Elasticsearch (8.x+) / OpenSearch: 如果你已有ES集群,直接用,支持向量检索。
Milvus / Weaviate: 专业的向量原生数据库,适合海量数据(亿级)。
Chroma / FAISS: 适合本地开发或轻量级应用。
核心算法之争:IVF vs HNSW
IVF (Inverted File Index,倒排文件索引):
- 机制:通过 K-Means 等聚类算法划分向量簇,查询时先定位所属簇再精准搜索 ;
- 类比:超市购物直接前往对应商品区;
优缺:构建速度快、内存占用少,但簇边缘易漏搜,需通过 nprobe 参数调节搜索范围 。
HNSW (Hierarchical Navigable Small World,分层导航小世界):目前向量数据库主流高性能索引算法。
- 机制:构建多层图结构,上层为稀疏“高速公路”用于快速定位,下层为密集节点用于精细匹配,查询时逐层逼近目标 (21);
- 类比:开车导航从高速到省道再到街道;
权衡:查询速度快(毫秒级)、召回率高,但内存消耗大,图结构需常驻内存 。
选型法则:千万级以下数据量且内存充足,优先选 HNSW;
十亿级数据量或对内存敏感,IVF 或结合 PQ(乘积量化)压缩更合适 。
第二阶段:在线服务(做菜)—— 决定用户体验
数据存入向量库后,进入实时性要求极高的同步服务流程,响应用户查询需求。

Step5:混合检索(Hybrid Search)—— 必做项
用户提问后,流程分为三步:
- Query 向量化:实时调用 Embedding 模型将问题转换为向量;
- 相似度搜索:在向量库中计算查询向量与文档向量的余弦相似度;
- Top-K 召回:宽泛检索相似度靠前的 Top 50 或 Top 100 片段 。关键点:此环节核心目标是保障召回率,避免遗漏正确答案,否则后续环节无法补救。
避坑:纯向量检索无法匹配精确关键词(如SKU编号、人名)。
方案
向量检索(Dense): 抓语义(搜“水果”能出“苹果”)。
关键词检索(Sparse/BM25): 抓字面(搜“A123号零件”必须精准匹配)。
结合两者,召回率通常能提升15%以上。
Step6:检索评估(Context Recall)
RAGAS框架: 使用 ragas 库进行自动化评估。不要靠人眼看,要看指标。
检索后需监控质量,核心指标为 Context Recall(上下文召回率)。
定义:检索到的 Top 50 片段中是否包含回答问题所需事实 ;
监控方式:通过离线“金标准数据集”评估,若召回率低,需优化分块策略或更换 Embedding 模型
Step7:重排序(Rerank)—— 效果提升的大杀器
为什么要重排序?
检索阶段使用的双编码器虽快,但语义理解粗糙,易混入噪音片段,直接输入 LLM 会干扰推理,甚至引发“迷失中间”现象。
交叉编码器 (Cross-Encoder) 的魔法
重排序模型(如 BGE-Reranker, Cohere Rerank)采用交叉编码器架构。
- 机制:将 Query 与 Document 拼接后输入模型,深度分析两者逻辑关系;
- 能力:精准识别微小语义差异,区分相关与无关内容 ;
- 流程:对 Top 50 候选片段逐一打分排序,仅保留 Top 3-5 优质片段;
- 代价:计算量大、速度慢,因此仅用于候选片段精排,形成“粗排+精排”漏斗设计 。
检索为了速度(双塔模型),往往精度不够。Rerank模型(交叉编码器)为了精度,逐一打分。
推荐模型: BGE-Reranker-v2-m3。
效果: 在Top-50检索结果中,Rerank能将正确答案从第20位捞到前3位。
Step8:重排评估(Hit Rate / MRR)
确保正确答案在前K个结果中出现。
核心关注 Context Precision(上下文精确度)。
目标:确保真正相关的文档排在前列;核心指标:NDCG@10 或 Mean Reciprocal Rank (MRR),若正确答案排序靠后,需微调或更换重排序模型
Step9:生成——Prompt工程的“紧箍咒
精选片段准备就绪后,由 LLM 生成最终答案。
Prompt 构建:将检索片段填入模板,包含系统指令(仅基于背景信息作答,信息不足则答“不知道”)、背景信息与用户问题;
核心作用:实现“Grounding”(锚定),强制模型在给定事实范围内推理摘要 。
真实有效的Prompt技巧
角色设定:“你是一个专业的合规助手…”
边界限制:“请仅根据以下参考资料回答,如果资料中没有答案,请直接说‘不知道’,严禁编造。”
引用标注:“回答时请在句尾标注来源,如 [文档A, 第2页]。”
Step10:最终评估——RAGAS三维指标
- Faithfulness(忠实度): 答案是否违背了参考资料?(治幻觉)
- Answer Relevance(相关性): 答案是否回答了用户问题?
- Context Precision(上下文精度): 检索到的资料里是否包含噪音?
四、价值升华:RAG落地的3个核心竞争力
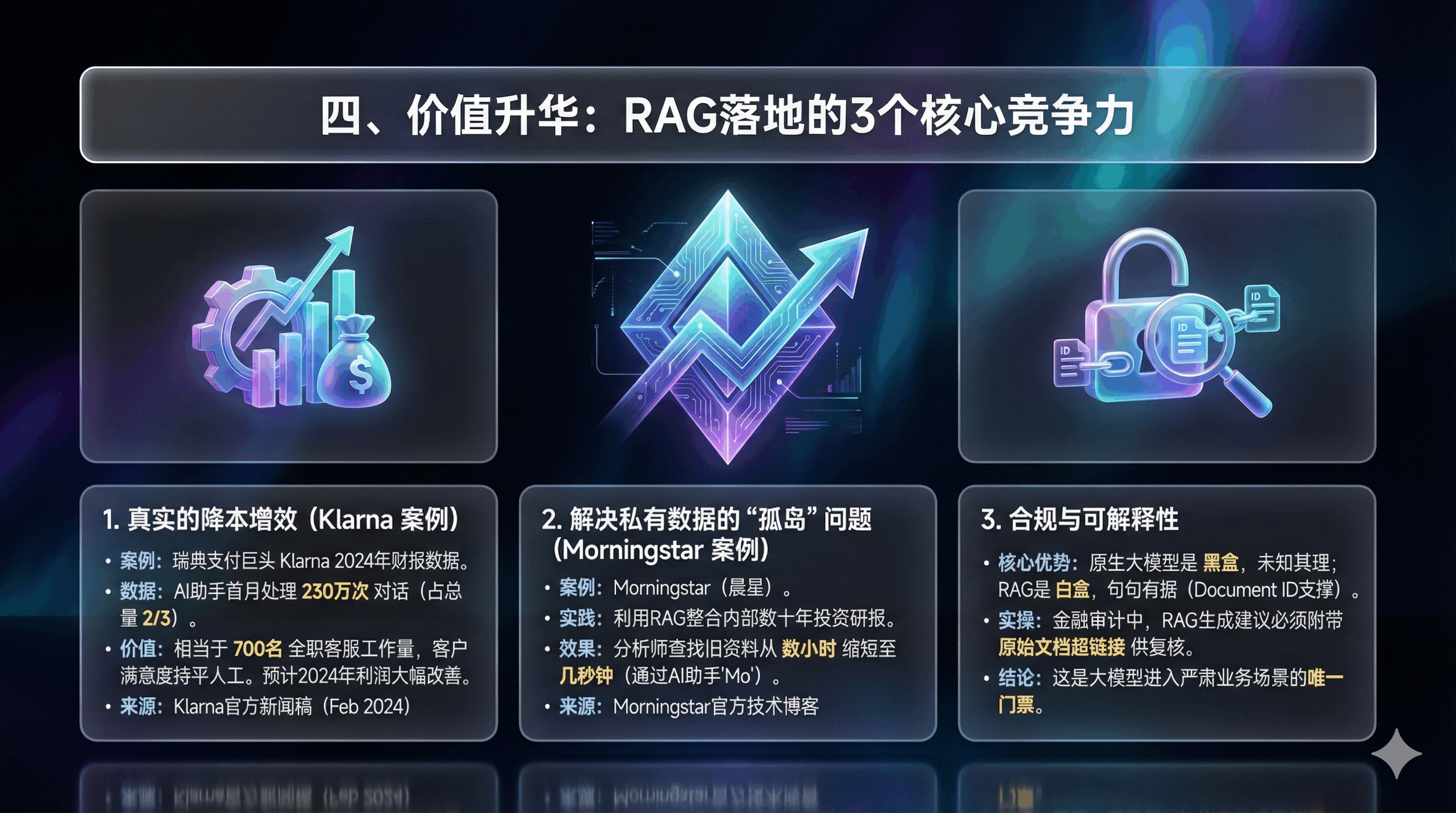
(Case1)真实的降本增效(Klarna 案例)
案例: 瑞典支付巨头 Klarna 2024年发布的真实财报数据。
数据: 其AI客服助手上线一个月后,处理了230万次对话(占总客服量的2/3)。
价值: 相当于700名全职客服的工作量,且客户满意度与人工持平。导致其2024年预计利润大幅改善。
来源:Klarna官方新闻稿 (Feb 2024)
(Case2)解决私有数据的“孤岛”问题
案例: Morningstar(晨星)。
实践: 利用RAG技术整合内部数十年积累的投资研究报告。以前分析师找旧资料要翻几个小时,现在通过Mo(其AI助手)几秒钟定位。
来源:Morningstar官方技术博客
(Case3)合规与可解释性
核心优势: 原生大模型是黑盒,你不知道它为什么这么说。RAG是白盒,每一句话背后都有Document ID支撑。
实操: 在金融审计中,RAG生成的每一条建议都必须附带原始文档的超链接,供人工复核。这是大模型进入严肃业务场景的唯一门票。
本文由 @王俊 Teddy 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









翻车……