
 起点课堂会员权益
起点课堂会员权益硬核代码实测:阿康带你揭秘“提示词缓存”的省钱秘籍
本文通过Langchain框架的实战验证,不仅发现缓存命中可降低90%成本,更揭露了OpenAI、Google Gemini和DeepSeek三家大厂在缓存策略上的潜规则与安全风险。最后奉上「静态在前,动态在后」的黄金法则,以及开发者必须警惕的时序攻击隐患。

一、硬核结论:Prompt Caching ≠Output Caching
最近上网冲浪,刚好刷到了IBM团队关于LLM Prompt Caching(大模型提示词缓存)的硬核科普视频。不得不说IBM 的视频一针见血:别把“Prompt Caching(提示词缓存)”和传统的“Output Caching(输出缓存)”搞混了。

很多人一开始都会以为,大模型的缓存就是存“输出答案output”,但实际上的Prompt Caching存的是上下文的输入Input Context,他的特点是:
- 不存结果,只存中间状态:存储的是模型对超长提示词(System Prompt ,PDF文档)的计算中间状态(KV Cache);
- 优化输入,不影响输出:他解决的是Transformer模型最耗时的预填充prefill阶段;
关键机制:当一次新请求的前缀(prefix)完全一致时,模型直接调用记忆,不需要每次都在大脑里重新算一遍attention,而是直接开始生成。
这个就意味着:输入内容越长,通过缓存机制就省的更多。
原理是听懂了,但在大模型实际应用中,这个机制到底有啥实际表现呢?接下来我们通过Vibe Coding的高效方式,使用Langchain框架写一段代码,来对这个机制进行一个彻底理解。结果呢,不仅验证了惊人的成本节省,还意外发现了视频里没写的潜规则,以及一个让我背后发凉的安全风险。
二、实验设计:如何科学的“利用”大模型缓存
为了验证模型缓存机制的真实效果,我设计了一个极其简单的对比实验,设计两组演示共用同一套超长sysetm提示词,仅改变提示词最开始的前缀内容实现强制命中 /回避 提示词缓存,并使用三个题目来做结果对比。为此,我把发给模型的 System Prompt 拆解成了两部分:
System Prompt =[特殊前缀]+ 静态核心内容 (2000+ tokens)
其中,“静态核心内容”就是那 2000+token 固定的角色、任务等内容的设定,而这[特殊前缀],就是我用来控制缓存是否命中开关的“阀门”。
三、试验步骤:
1. 准备标准的静态提示词模板:
我先设计了一个超长的系统提示词(System Prompt),模拟了一个资深的AI技术专家和教育工作者,对用户的提问内容进行解答。这里面塞满了详尽的AI角色设定教学理念和技术栈的介绍,长度达到了2000多的Tokens。(截图未显示完整内容,已上传github,可在文末找到地址)

2. 设置变量:
1)命中组(hit cache):
使用固定前缀[静态时间戳(2025-01-01)],锁死当前代码执行时候的前缀,确保这个组内的所有问题都有相同的前缀信息,并直接强制命中缓存。(注意,第一个提问不会命中)
2)绕过组(miss cache):
使用动态前缀是[动态时间戳(Current Time)],这个组内每次的提问都会产生不同的前缀,强制使缓存失效。
3. 运行代码测试:执行代码即可。

4. 观察运算结果:
直接扒 API 返回里的prompt_cache_hit_tokens字段(根据deepseek官方文档获取即可),并输出一个横向对比表格,Token 消耗和耗时一眼便知。

四、数据结论
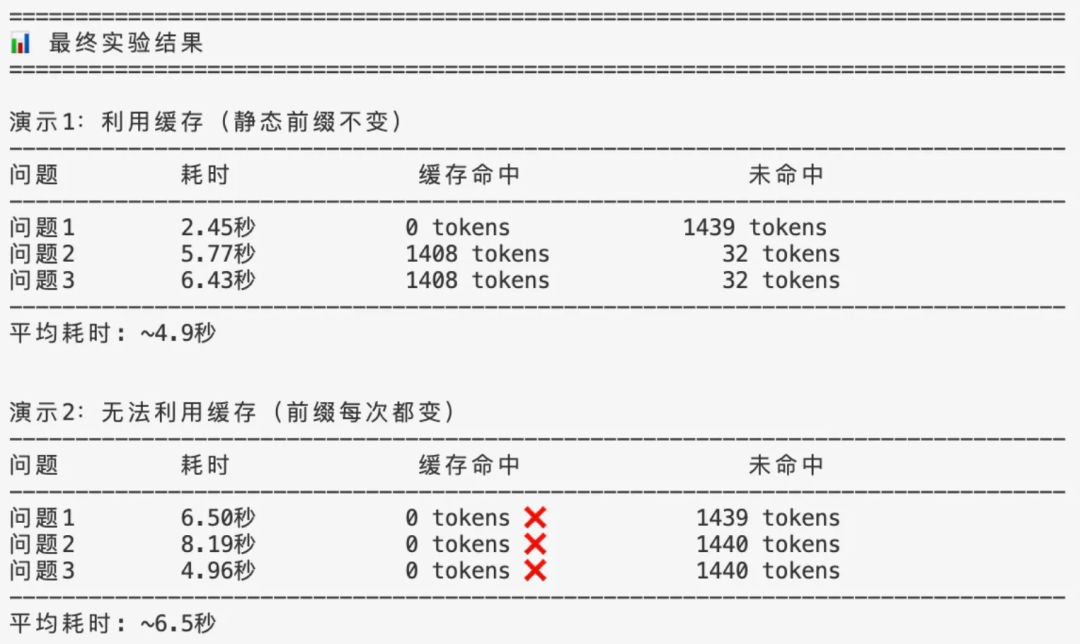
跑完代码,看到日志的那一刻,极度舒适。(注:使用python输出的日志信息来模拟表格对比)
演示1利用缓存的那组,第一次提问0命中,但第二次和第三次提问,prompt_cache_hit_tokens显示都是命中1408 tokens的缓存了。另外,平均耗时也较快点(但注意这个倒不是必然的,影响耗时的因素是很多方面的)。
演示2绕开缓存的那组,很明显三次提问都是0缓存命中了。
多说一点,以deepseek为例,没命中的 tokens,1块钱/百万;命中的,直接打一折,1毛钱/百万。
所以此处如果复用缓存,成本直接砍掉90%了,这对于那些高频跑 RAG、分析长文档的兄弟们来说,这个提示就非常明显了!

五、几家AI大厂的“潜规则”
可能大家认为,deepseek缓存这么香,其他几家AI大厂是不是也一样?
我翻了 OpenAI、Google Gemini 和 DeepSeek 的文档,发现里面的水还挺深。
OpenAI:有起步门槛,还得凑整
OpenAI 的 Prompt Caching 有个1024tokens的起步门槛,你的提示词要是太短,它根本懒得给你。而且呢,它是按128tokens一块一块存的,写提示词的时候最好凑个整,别浪费。

Google Gemini:得加钱
Google 就有意思了,它把缓存分了两类:
- 隐式缓存 (Implicit):全自动,不用你管。
- 显式缓存 (Explicit):这是个付费功能。
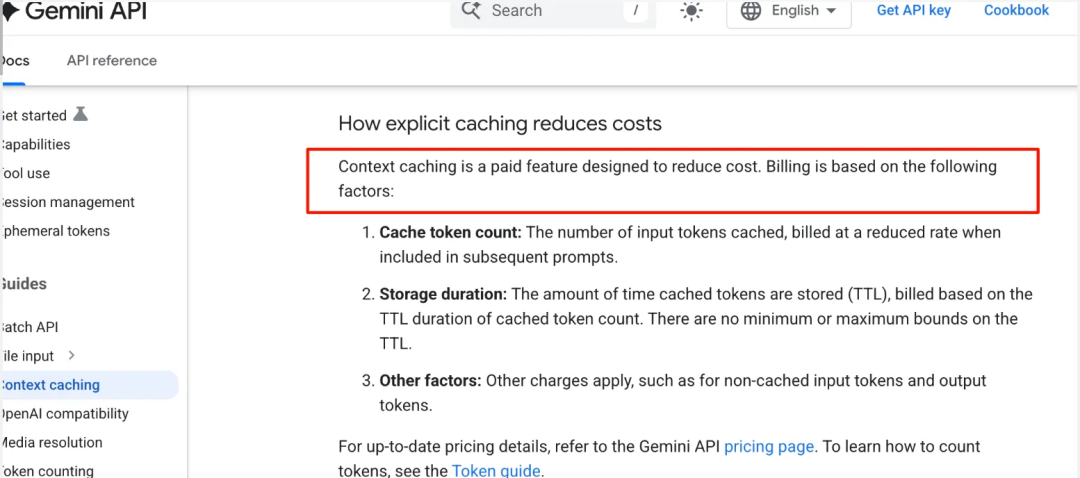
仔细看了谷歌文档,显式缓存是要按缓存token数、存储时长(TTL)、以及其他因素综合收费的。特别是得为数据在显存里“占座”的时间付费,这逻辑就很合理——显存那么贵,不能白给。
DeepSeek:MLA的技术红利
DeepSeek 价格便宜,靠的都是MLA (Multi-head Latent Attention)这种技术,之前网上也有很多大佬专门解读过。简单说就是它用低秩压缩把 KV 矩阵压得非常小,才能支持64 tokens这种极小的缓存粒度。
六、最佳实践:”静态在前,动态在后”–发挥缓存最大价值
缓存这么好的机制,要怎么用起来呢?核心原则就一句:静态在前,动态在后。
在 RAG 应用中,很多朋友习惯把用户问题放在最前面:
“用户问:这个产品的价格是多少?参考资料如下…”
但在缓存机制下,这个其实就是浪费了。用户问题一变,后面的几千字参考资料缓存全废。
正确的做法是反过来:
“参考资料如下…(几千字文档)…基于以上资料,回答用户问题:这个产品的价格是多少?”
只要把最占篇幅且最不常变动的文档,或系统指令放在 Prompt 的最前面,而把变化的用户输入放在最后,这样前缀基本锁定了,缓存也就很好的生效了。
七、安全警示:缓存是一把双刃剑
技术本身是中性的,使用场景决定了他是利剑还是毒药。这次查资料过程中,我也无意发现以下风险问题:
- 侧信道时序攻击 (Timing Attack):攻击者可以构造特定的提问内容,专门去“测”你的 API 响应时间(特别是首字延迟 TTFT)。如果发现响应速度显著变快,这就极有可能意味着命中了缓存,并间接意识到:原来你们内部有人问过这些内容,也证明这些内容确实是存在了。
- 跨租户侧信道攻击 (Cross-Tenant Side-Channel Attack):这是更严重的“窃听”,如果 SaaS 厂商为了省成本搞全局共享缓存池,A 公司的机密文档被缓存后,B 公司要是猜到了相同的前缀,搞不好能利用响应时间差异,把信息给“测”出来。
八、写在最后
缓存这东西,是把手术刀。 用好了,降本增效;用不好,就是埋在系统里的定时炸弹。
动手之前,先问自己三个问题:
1.我的提示词,静态部分够不够长?
2.我的这些缓存数据敏不敏感?
3.我的提示词更新频率高不高?
总之,大模型缓存技术没有银弹,全是权衡。
附:获取完整代码
本文所有演示代码(含deepseek_cache.py 及配置模板)都已经开源到 GitHub 了。 想实测的兄弟复制链接自取:https://github.com/PMKang/AI_LLM_DEMO
作者:产品阿康,公众号:产品阿康成长日记
本文由 @产品阿康 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


