
 起点课堂会员权益
起点课堂会员权益何时该用LLM?AI产品经理的LLM设计指南
LLM技术热潮下,盲目跟风可能导致资源浪费与产品失控。本文深入剖析LLM与传统逻辑的核心差异,提供清晰的决策框架与成本测算,揭示混合架构的最佳实践,助你在技术选型中做出理性判断,避免陷入'为AI而AI'的陷阱。

LLM无疑是当下最受追捧的技术。很多产品团队在做功能创新时,第一反应就是“能不能用LLM实现?”仿佛不用LLM就称不上智能产品。
但在应用前,必须搞清楚:
什么情况下才真正适合使用LLM?什么情况下传统逻辑依然是更优解?
本文对比两种技术路线的核心特点,给出决策框架,并介绍混合架构的最佳实践,帮助你在热潮中保持理性。
一、LLM vs. 传统逻辑:核心特点对比
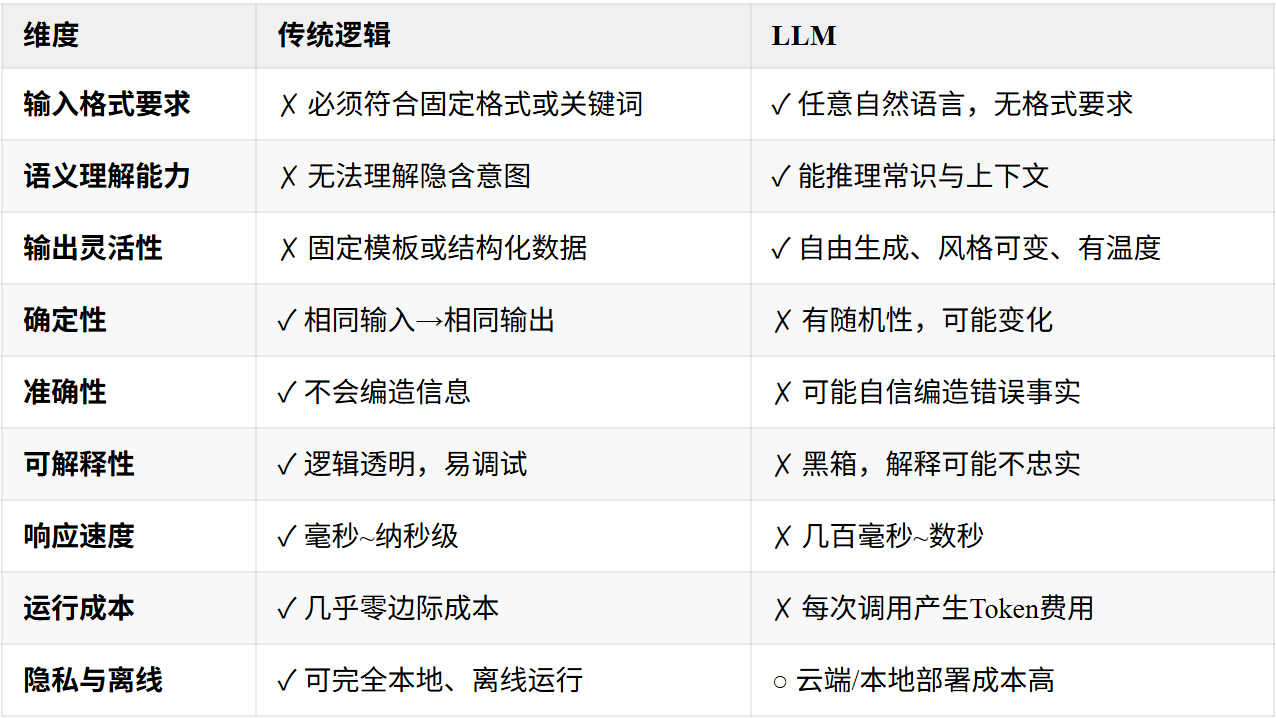
图例:✓ 优势;✗ 劣势;○ 视情况而定(可解决但有代价)。
一句话总结:
传统逻辑擅长“确定、封闭、可穷举”的任务;LLM擅长“开放、模糊、需要理解与创造”的任务。
二、什么时候应该用LLM?
- 输入无法穷举(或者穷举后维护成本远高于LLM调用成本):用户可能用千奇百怪的说法表达同一需求,或者维护大量正则/规则集的成本已经超过LLM调用的代价。例如,客服系统需要识别50种不同问法的“退款意图”,用LLM可以零维护直接理解。
- 核心需求是“理解”或“生成”:需要从模糊表达中抽取意图,或生成不固定的自然语言回复。
- 能接受LLM的代价:延迟几百毫秒以上、单次调用有成本、输出非确定性、可容忍偶尔的小幻觉。
典型适用场景:智能客服复杂意图识别、邮件/文案润色、文档摘要、情感分析、自然语言查询转结构化指令。
三、什么时候谨慎用LLM?
以下场景会带来显著风险或成本。
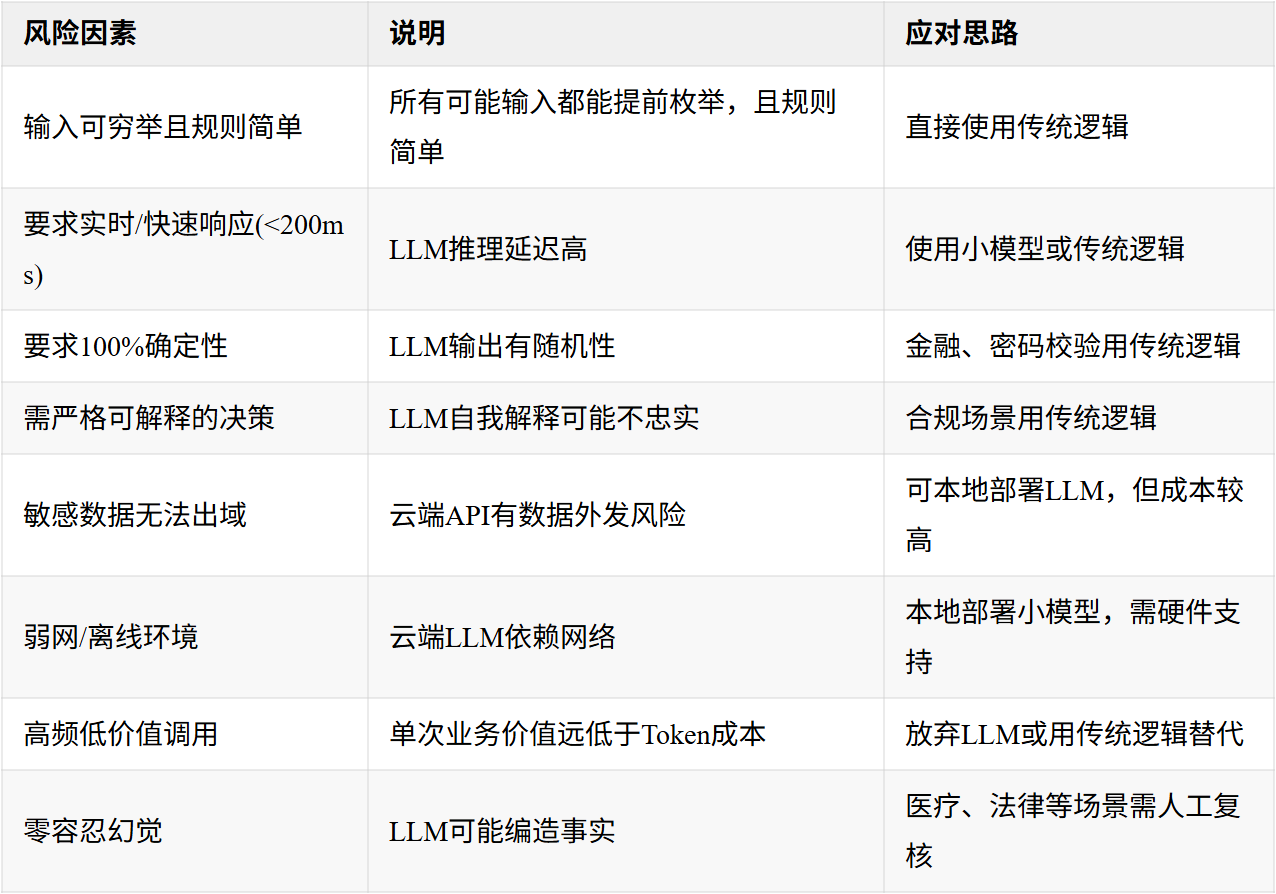
成本量级参考
- DeepSeek-V3:标准定价为输入2元 / 1M tokens,输出3元 / 1M tokens。一次普通用户查询(~1K输入 + 1K输出)成本约为0.005元(0.5分钱)。
- 缓存命中优惠:若开启上下文缓存且命中(依赖重复前缀,非常规价格),输入可降至 0.2元 / 1M tokens。
- 其他厂商轻量模型(如 GPT-4o mini、Claude Haiku):约 $0.15~0.30 / 1M tokens,折合人民币约 1~2元 / 1M tokens。
- 本地部署小模型(如 Llama 3 8B):硬件成本+电费,中等并发下单次查询约0.0001~0.001元量级,但有运维和首次部署开销。
快速判断:每次调用成本约 0.005元(DeepSeek-V3)。通常建议业务价值至少是成本的2倍(即 >0.01元/次)才值得用LLM,以覆盖风险。如果业务价值更高(如节省一次人工客服成本约1-5元),则LLM非常划算。
四、替代方案:中小型模型 / 垂直模型
其实除了LLM,还有BERT(经典中小型模型)、Llama 3 8B(Meta,适合轻量生成)、Gemma 2 2B(Google,极致轻量)、Qwen 2.5 7B(阿里,中文友好)等可以选择。
它们在多个维度上介于传统逻辑和大模型之间:
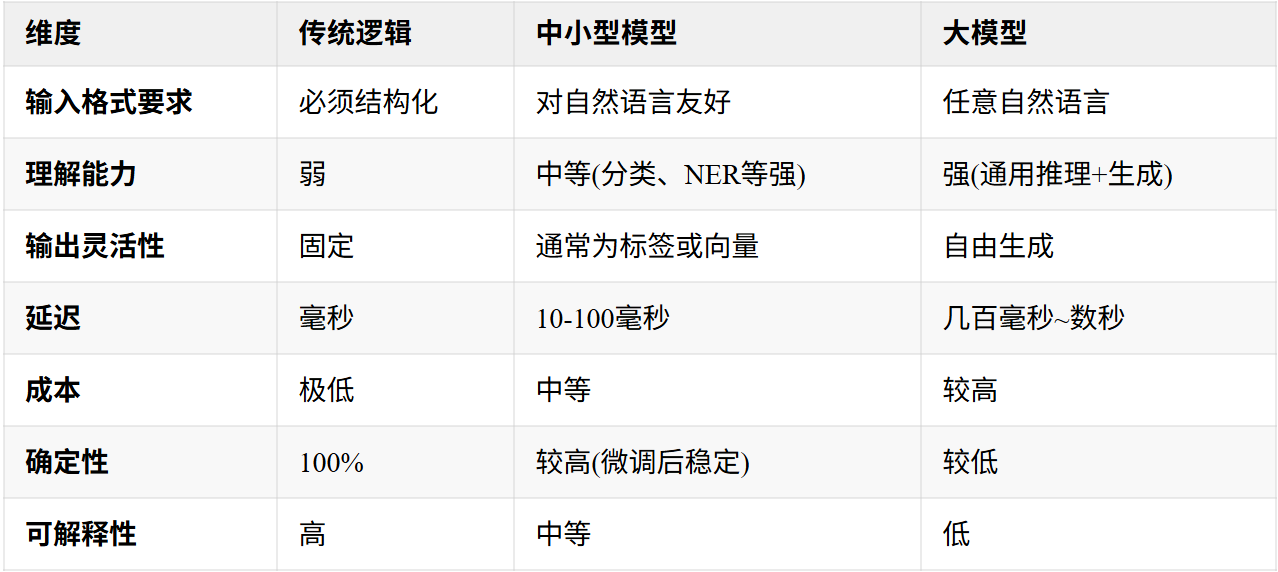
何时优先考虑中小型模型?
- 任务明确且单一(如只做情感分类、意图识别)
- 延迟要求50-200ms,不能接受LLM的秒级响应
- 数据隐私要求高,但可接受本地部署(无需联网)
- LLM成本太高或随机性不可接受,但传统逻辑又不够智能
如果LLM的代价让你犹豫,可以先尝试微调一个中小型模型,往往能以更低成本达到80-90%的效果。
五、最佳实践:混合架构 + 传统逻辑兜底
传统逻辑做骨架,LLM做大脑。用传统逻辑约束、校验、兜底LLM的输出。
如何混合使用?
- 传统逻辑:负责确定、高频、低成本的部分(分流、关键词匹配、数据库查询、模板输出)
- LLM:负责模糊、需要理解与生成的部分(复杂意图识别、情感判断、自由文本生成)
- 用传统逻辑解决LLM短板:校验格式、检测幻觉、强制确定性
混合流程示例(智能客服)
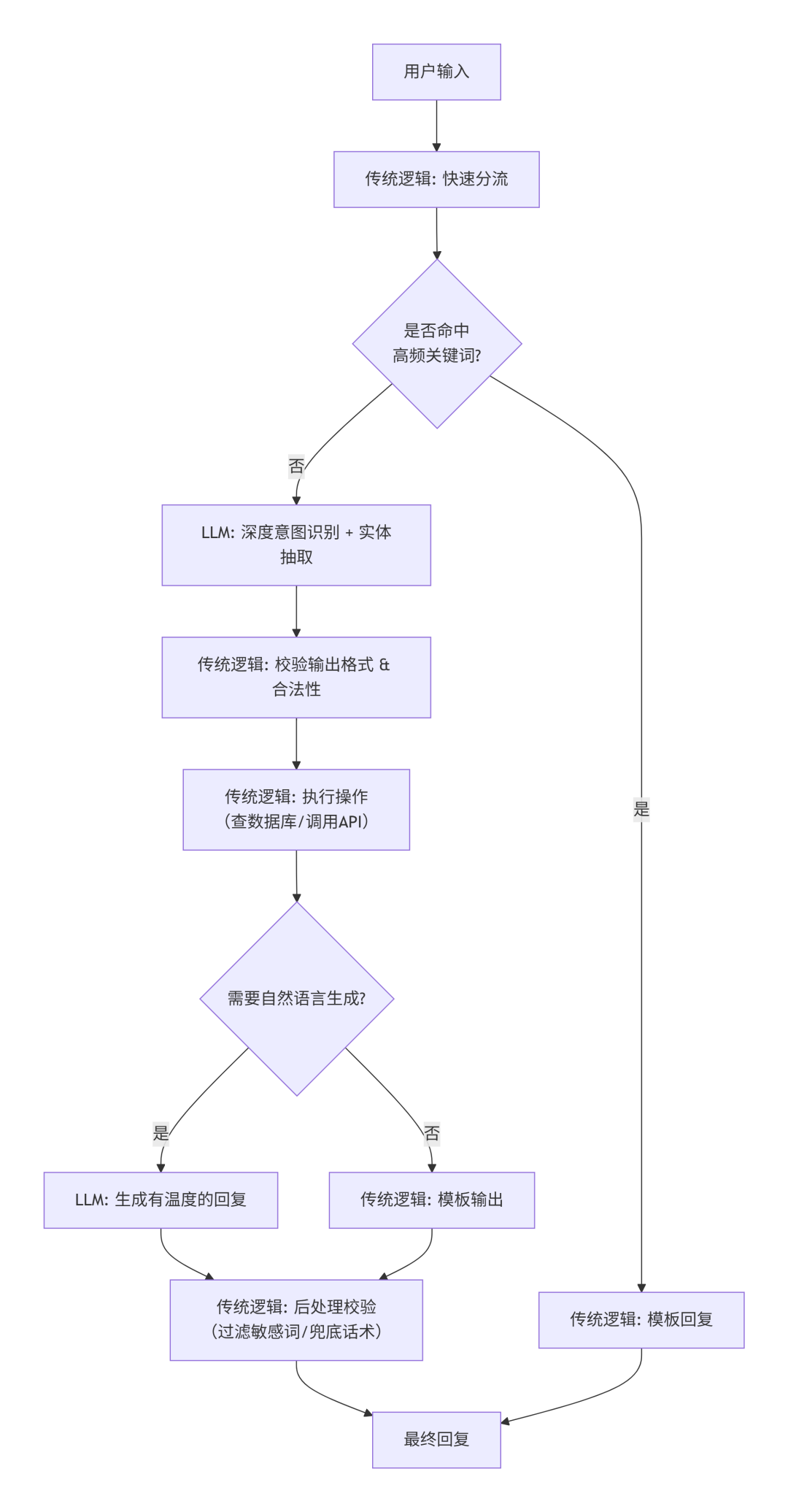
传统逻辑如何解决LLM典型问题?
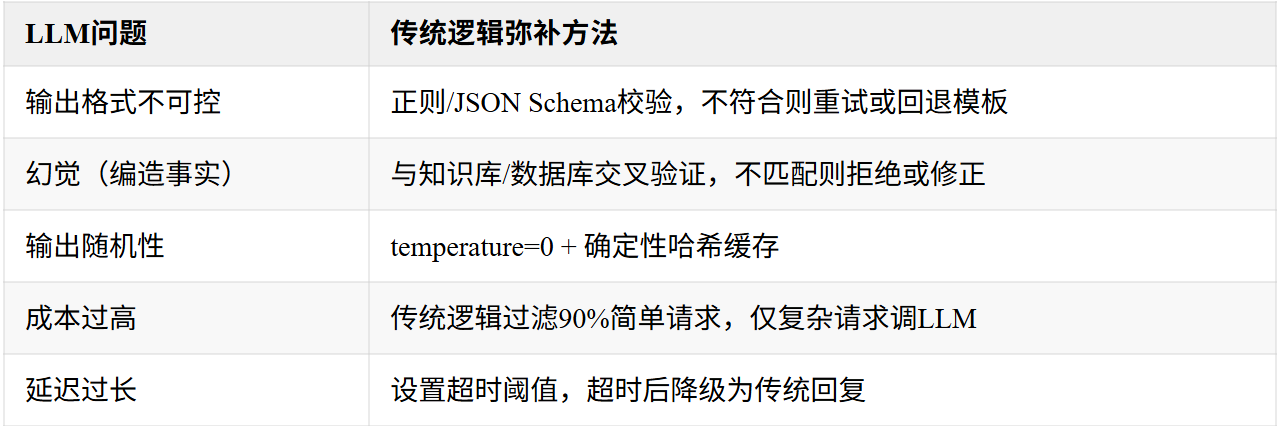
核心原则:不要把LLM当作黑箱端点直接对外输出。在LLM前后都加上传统逻辑的护栏。
最后的话
滥用LLM不仅浪费资源,还会让产品变得不可预测、成本高昂、响应缓慢。
真正的智能设计,是知道什么时候用它,什么时候用中小型模型,什么时候用传统逻辑,以及如何用传统逻辑为LLM兜底。这才是务实的做法。
本文由 @硬核PM 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


