
 起点课堂会员权益
起点课堂会员权益AI 应用搭建平台的知识库竞品分析:RAG 功能为什么会这样设计? ——以百度千帆与 Lyzr AI 为例
在RAG产品的竞品分析中,单纯的功能清单对比已远远不够。本文深度解析如何通过DDD子域划分和Kano模型,重新定义RAG产品的分析框架。以百度千帆AppBuilder和Lyzr AI为案例,揭示RAG功能背后的产品逻辑和战略考量,帮助产品经理在资源投入和功能分层上做出更精准的决策。

一、为什么 RAG 产品不能只做“功能清单式”竞品分析?
在分析 RAG 产品时,我们很容易陷入一种惯性:
- 这个平台有没有知识库?
- 有没有文档解析?
- 支不支持混合检索?
- 有没有重排?
- 能不能做效果评测?
这样看似全面,但本质上仍然是在做功能清单对比。
它能回答“谁有这个功能”,却很难回答:
这些功能为什么会出现?
哪些功能是这类产品必备的基础功能?哪个功能该作为重点开发的对象?
为什么有些产品重点做知识解析,有些产品把重心放在检索策略,又有些是强化效果评测?
就导致看了很多竞品,但是到头来还是一头雾水。本文就来拆解该问题。
下面将以:
国内:百度千帆 AppBuilder
国外:Lyzr AI
作为分析对象,这二者都不是单纯的面向技术型人员的的底层 RAG 引擎,而是面向 AI 应用 / Agent 搭建场景的产品平台。它们的知识库能力,分别体现了 RAG 在国内大模型应用平台与海外 Agent 搭建平台中的产品化方式。
RAG 架构通常与Agent智能体产品的中的知识库功能密不可分,现在大多Agent产品中都采用该数据架构来帮助用户将私有数据,快速转化为Agent处理用户问题的知识来源。
产品中RAG的处理流程可以总结为:沿着“知识进入系统—知识被处理—知识被检索—知识被组织为回答上下文—答案被生成—效果被评估与优化”的处理流程逐步产品化的结果。
为了更好地解释这件事,本文尝试引入两种方法:
- DDD 子域划分:从业务价值角度判断,RAG 产品中哪些能力是真正值得投入的核心域。
- Kano 模型:从用户价值角度判断,这些功能分别属于行业门槛、体验增强,还是差异化亮点。
最终形成一套分析框架:
- RAG 处理流程解释“功能从哪里来”;
- DDD 解释“资源该投在哪里”;
- Kano 解释“功能该如何分层设计”。
从了解RAG架构中数据处理环节出发,再使用DDD 子域划分和Kano模型二者结合的方式来分析现有的产品中的具体运用。DDD的子域划分可以帮助我们识别:RAG 产品中哪些能力最值得成为资源投入重点,成为我们产品的差异化。Kano 模型帮助我们判断:这些能力中的具体功能,哪些是行业门槛,哪些是提升满意度的竞争点,哪些是差异化创新机会。
二、分析方法:用 DDD 看业务价值,用 Kano 看用户价值
1. DDD:用业务价值视角看产品能力投入
DDD,即领域驱动设计,最早用于复杂业务系统建模。对于产品分析来说,我们不需要把 DDD 中所有技术概念都展开,比如实体、聚合、仓储、领域服务等。
本文就借用 DDD 的战略设计视角:
- 统一语言:产品、业务、研发要对核心业务概念形成一致理解;
- 限界上下文:在什么业务范围内,一个概念和规则是成立的;
- 子域划分:识别哪些能力是核心域、支撑域、通用域。
微软 Azure 架构文档中也将领域分析、限界上下文等作为 DDD 建模微服务的重要步骤。对于我们进行产品分析而言,最有价值的是这两层:先理解业务领域,再识别业务边界与子域。
在本文中,可以简单理解为:
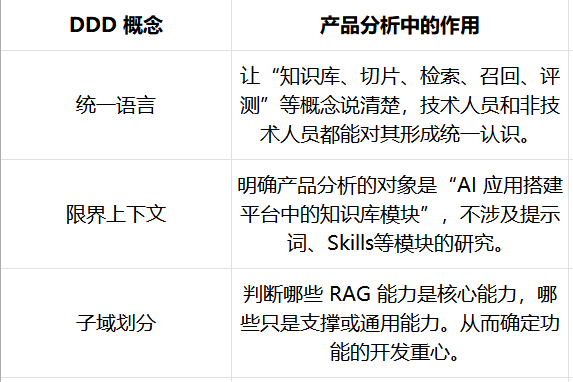
一句话总结,从产品视角看,DDD 主要帮助我们回答:资源应该重点投入在哪里?
其中本文中我们所使用的子域划分,其分为三类:核心域、通用域、支撑域。

微软与 AWS 的架构资料都强调,DDD 的战略价值就在于:让系统设计围绕真正的业务能力,而不是围绕技术模块机械拆分。(Microsoft Learn)
2. Kano:判断功能对用户满意度的影响
Kano 模型它通常将需求分成五类:
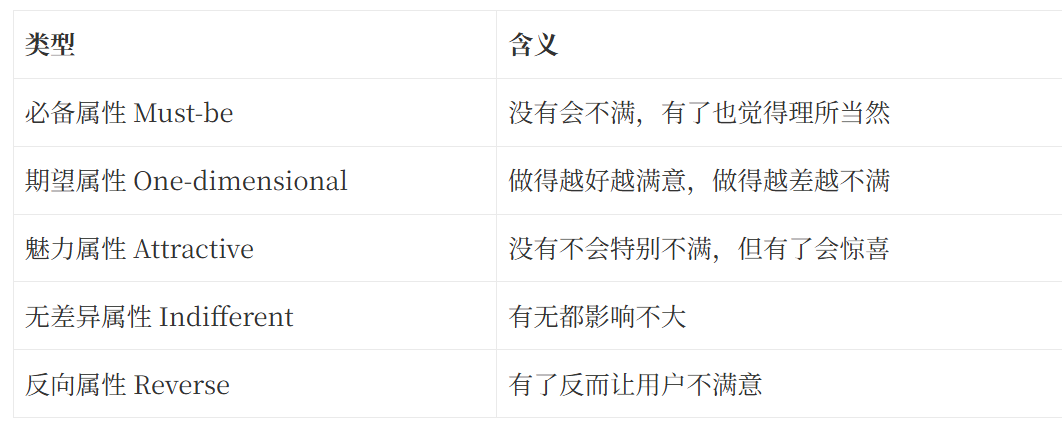
Kano 的价值在于,它不只是告诉我们“用户想要什么”,而是帮助我们判断:
一个功能对用户满意度的影响方式是什么。(asq.org)
ASQ 对 Kano 模型的解释中,也将其用于理解产品或服务功能完成程度与用户满意度之间的关系。
放到知识库产品功能中:
- 文件上传、创建知识库,大概率是必备属性;
- 混合检索、切片配置、重排,更像是期望属性;
- 自动调优、图谱增强、多模态 RAG,可能是魅力属性或高阶期望属性。
具体而言,这些功能属于什么类型的属性,就需要通过Kano的执行方式,从用户的反馈中做出判断,从而进一步得出功能的属性特征。
Kano 主要帮助我们回答:功能应该如何分层设计,帮助我们做出正确的判断。
3. DDD 与 Kano 的关系:一个看资源战略,一个看需求认知
很多产品分析只做 Kano,容易出现一个问题:
用户最兴奋的功能,不一定是企业最应该优先投入的能力。
例如,一个很炫的“AI 自动生成问答助手”可能是魅力功能;
但如果底层知识解析和检索质量不好,这个功能就只是“看起来智能”,但是给用户的体验不好,该功能就无法形成稳定竞争力,反而会影响用户对产品的满意度。
反过来,只做 DDD 的子域划分也不够。
因为你可能能判断检索能力很重要,但如果不了解用户对不同检索功能的感知差异,也无法判断:
- 哪些功能只是行业门槛?
- 哪些功能能提升满意度?
- 哪些功能能形成差异化?
因此:
DDD 是业务价值视角,Kano 是用户价值视角。
二者结合,就是用“业务价值 + 用户价值”来决定功能设计和优先级。
三、RAG 产品功能的真正来源:一切都服从于处理流程
RAG 的核心思想是:
在大模型生成答案之前,先从外部知识源中检索相关信息,再基于这些信息生成回答。
它实际上是一条完整的处理链路:(插入图示)
相应的每一个环节都会自然催生一类产品功能。
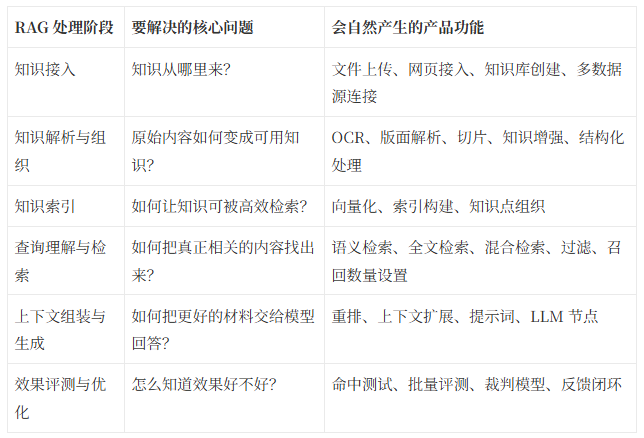
这张功能映射表中我们可以看出,其实RAG 产品功能不是菜单式堆叠,而是 RAG 处理链路在产品层面的逐步显性化,是为了实现流程处理的完整性。
四、基于 RAG 流程重新做 DDD 子域划分
如果把 RAG 产品放入“面向非技术用户的 AI 应用 / 工作流搭建平台”中分析,我认为可以拆出以下能力域。
1. 核心域一:知识构建域
RAG流程中的环节:
知识接入 –> 文档解析 –> 切片 –> 知识增强 –>索引准备
该流程对应的典型功能包括:
- 创建知识库
- 上传文件
- URL 导入
- 文档解析
- 切片策略
- 向量模型
将这部分作为知识库功能的核心,与其在RAG流程密切相关。如果前面的知识处理环节做不好,后面的检索与生成都会被拖累。比如错误切片、解析不完整、知识组织混乱,会直接导致召回失败或回答不准。
2. 核心域二:检索增强域
在 RAG 流程中的:
查询理解 → 检索召回 → 结果排序 → 上下文筛选
这个环节中解决的问题是,用户提问后,能否又快有准的查找到相关内容。这个模块内容映射到具体的产品中的功能是:
- 查询理解
- 召回检索
- 策略选择
- 重排
- 上下文增强
将这部分也作为核心域的原因,与RAG 架构本身的“增强”这概念相关,其本质就在检索。如果找不准,即使大模型再强,最后也是基于错误上下文内容中生成答案,仍然解决不了大模型环节的问题。
在实际的产品中通常对应以下这些功能模块:
- 语义检索
- 全文检索
- 混合检索
- 多知识库检索
- 召回数量
- 匹配分阈值
3. 支撑域:智能体编排域
在Agent智能体搭建的平台中,可以说知识库功能是将 RAG 能力包装成可被业务使用的应用组件或工作流环节。其对应在Agent平台中的典型功能是:
- 工作流画布
- 知识库(知识)节点
- 大模型节点
- 输出节点
这里有一个非常重要的区分:
- 如果研究的是整个 AI 应用搭建平台,工作流编排本身可能是核心域。
- 但如果研究的是RAG 能力如何被产品化,工作流更像是承载 RAG 能力落地的支撑域。
4. 通用域:企业基础能力域
例如:
- 权限管理
- 团队协作
- 安全审计
- 连接管理
- 部署与发布
- 统计分析
这些能力非常重要,会影响用户的使用体验,但它们并不是 RAG 本体能力的来源。所以在本文中,它们就不作为重点展开。
五、为什么选择千帆与 Lyzr AI?
本文选择这两个产品,是因为它们都不是“纯技术型 RAG 引擎”,而是:面向不同技术水平用户的 AI 应用 / 工作流搭建平台。
1、千帆 AppBuilder
百度千帆 AppBuilder 的知识库能力直接面向 RAG 场景。其知识库简介中提到,知识库是 RAG 的数据基础,并提供知识增强、混合检索、全文检索、语义检索与重排序等能力。
千帆更适合观察:
国内大模型应用平台如何把 RAG 做成较完整的知识库工程化能力。
2、Lyzr AI
Lyzr AI 官方的 Classic Knowledge Base 文档明确指出过,它可以创建 no-code RAG pipeline,用于从文件、URL、纯文本等来源构建可搜索的文档理解能力。
Lyzr 更适合我们去观察:
海外 Agent 搭建平台如何把 RAG 封装成非技术用户可配置、可测试、可连接 Agent 的知识库能力。
因此,这两个产品放在一起分析,并不是为了判断谁更强,而是为了观察:
同一条 RAG 流程,在不同 AI 应用 / Agent 搭建平台中,被产品化成怎样的知识库功能。
六、沿着 RAG 流程看竞品:功能是怎么“长出来”的?
1、千帆 AppBuilder:把知识加工过程做得更可配置
在千帆的知识库创建页面中并不只是“上传文档”。
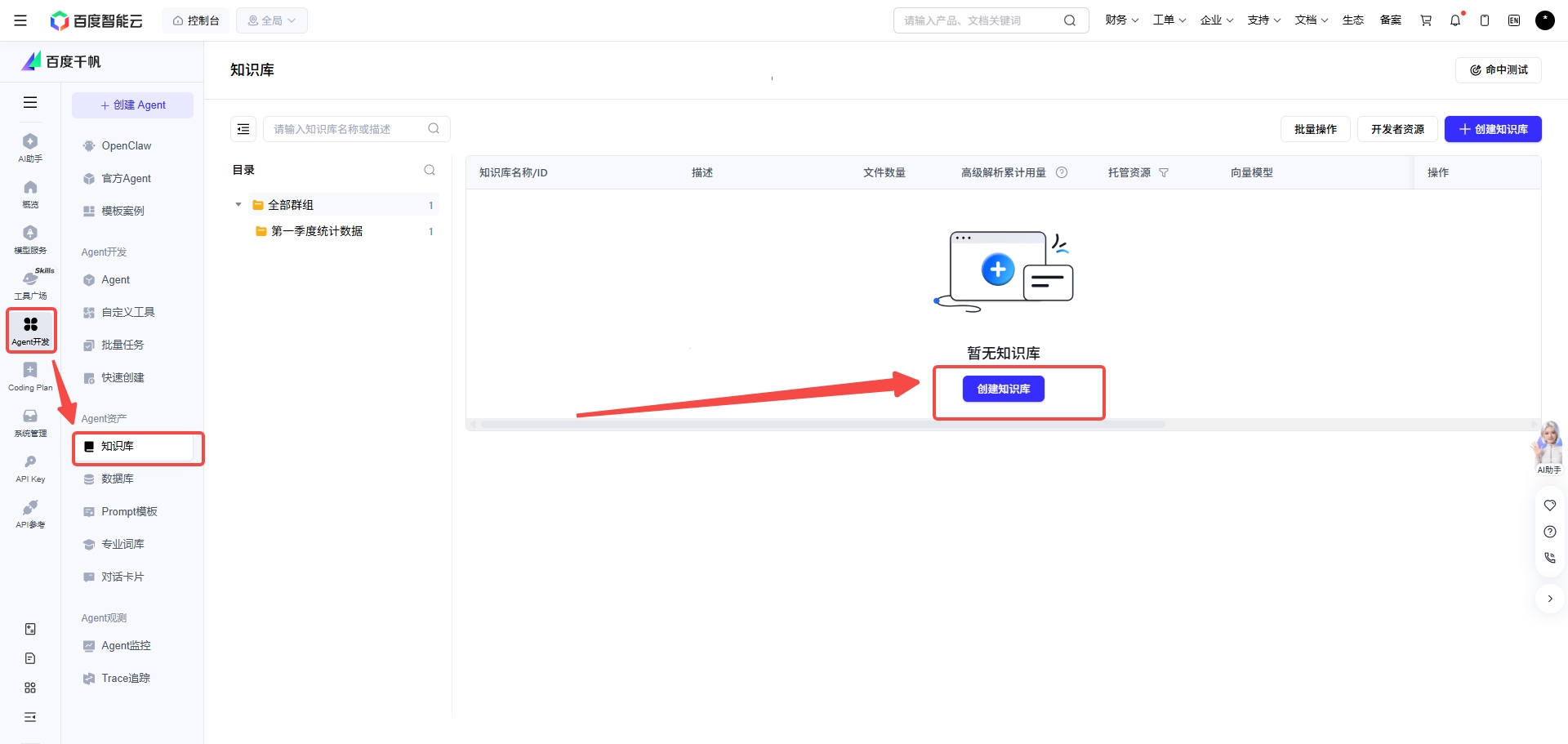
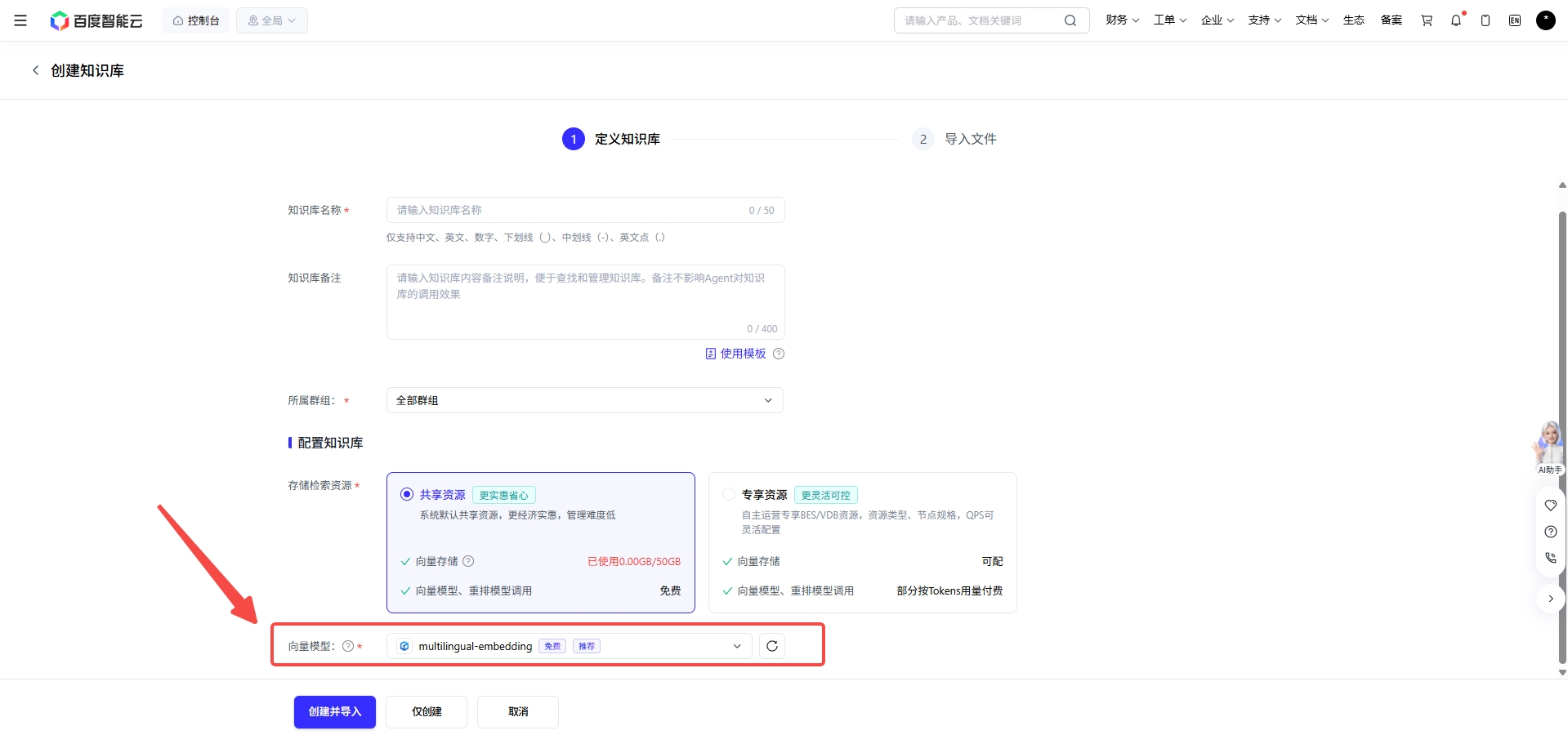
它会进一步提供(上图中可以直观的看到),其实千帆这个创建知识库的功能表单中,字段的命名很讲究,与RAG流程中的处理步骤和细节名称是十分相关,甚至是相同的。以下我总结了其中的操作名称,并且将其与RAG中的模块进行映射对齐。
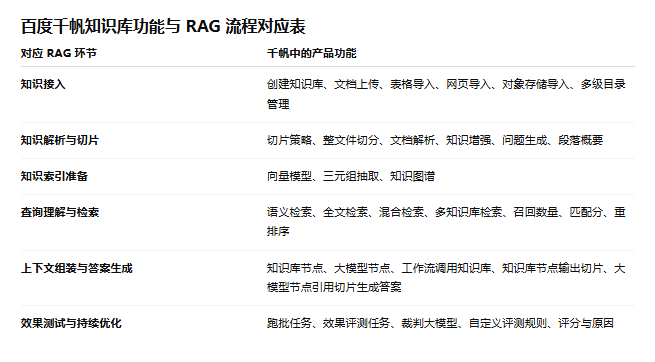
这些能力本质上都在回答同一个问题:
怎样把一份原始资料,转化成更容易被后续检索命中的知识结构?
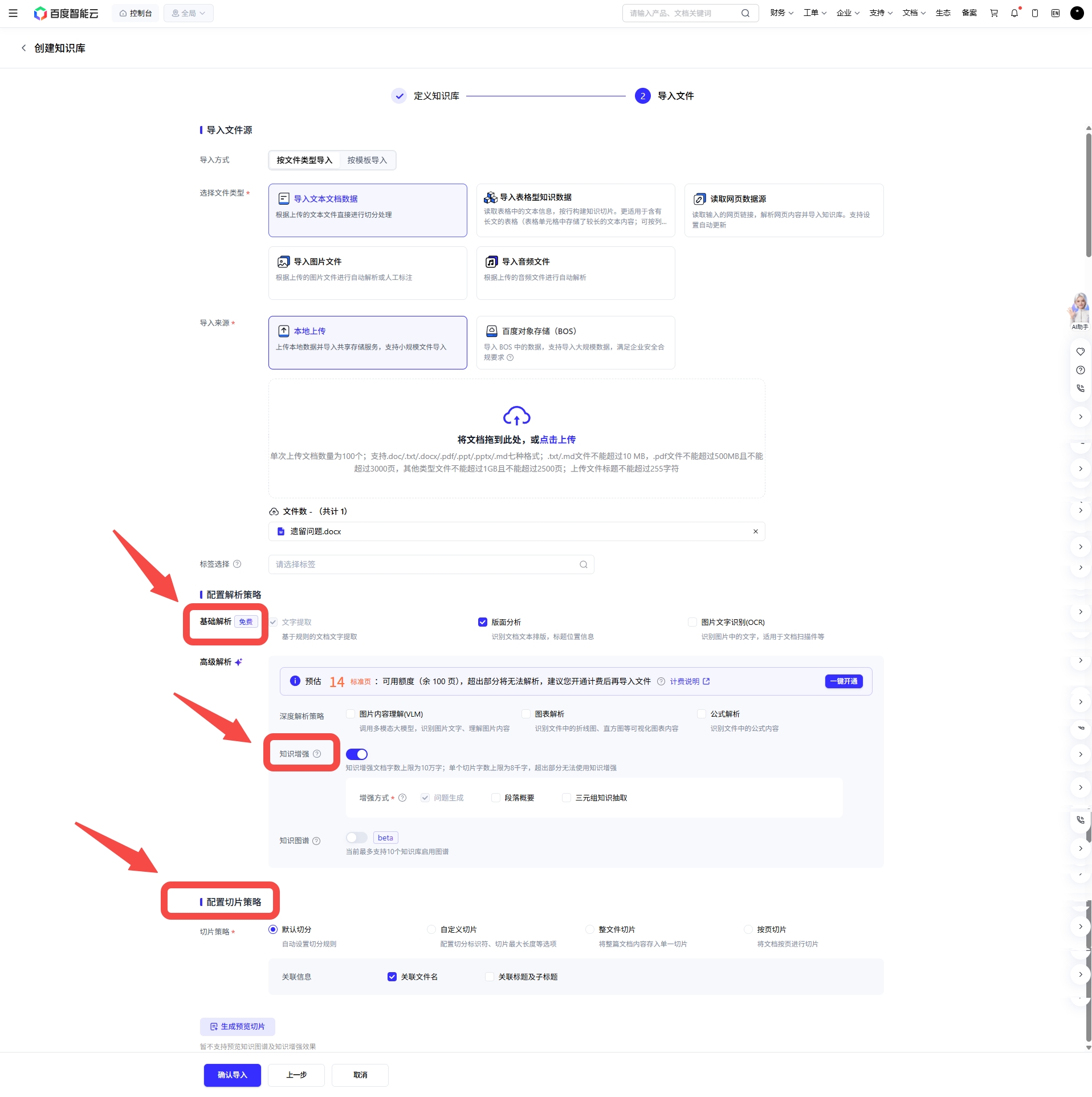
以及在上图的千帆的“知识增强”按钮开启状态下,可选择知识增强的方式(可选增加切门片内容摘要和三元组知识抽取两种知识增强方式),使用该辅助功能会调用大模型生成额外知识点,用于提升切片召回率。这说明它不是把知识库当成静态文件仓库,而是在主动优化知识可召回性。
此外,千帆还在多模态 RAG 与图谱增强 RAG 上做了产品化探索,分别对应图文联合检索、多实体多关系知识组织等复杂场景,但本文中不对该内容展开说明,感兴趣的话可以去千帆平台上试试。
总体来说,百度千帆的知识库能力更像是一套企业级 RAG 知识工程体系。它在知识接入、切片、知识增强、检索策略、工作流调用和效果评测上都有较完整的产品化表达。
2、Lyzr AI:Agent 知识库中的 no-code RAG 产品化路径
Lyzr AI 同样支持知识库,但产品策略不同。在Lyzr AI中 ,创建知识库功能首先就分为了三种类别(知识库、知识图谱、语义数据模型)。其中针对于RAG流程的是知识库搭建这个功能模块,所以接下来我们聚焦于该功能路径,探讨其中功能与RAG的流程间的映射。
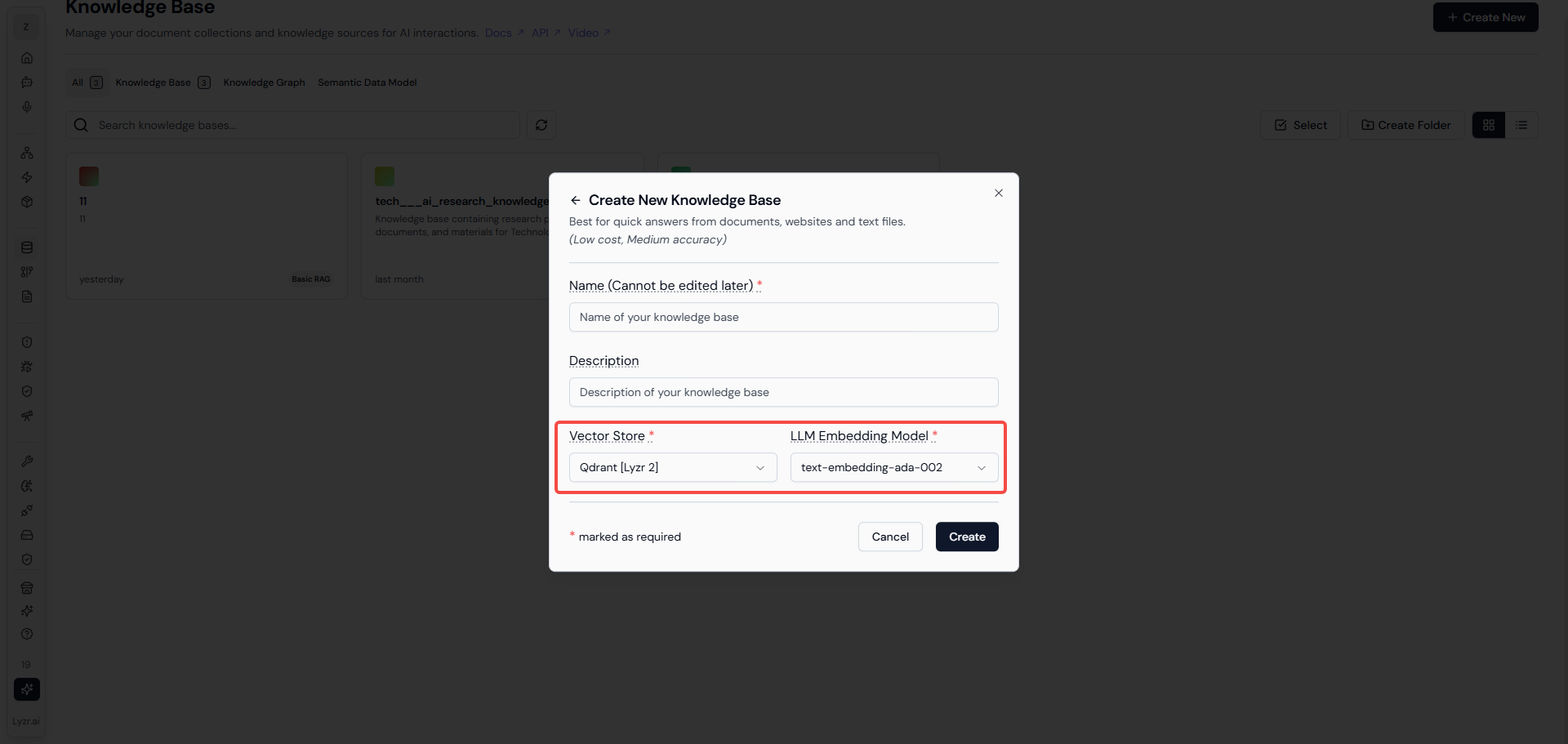
上图是Lyzr AI 进行“知识库”创建的页面,向量化模型和向量库是必填字段,进入下一页后能够自由选择数据导入方式。与本文中阐述的RAG流程相关的是“导入文件”的方式。选择 add file 选择问文件即可(该平台现在仅支持上传PDF、DOCX、TXT文件),就会在页面中左侧列表中显示所上传的文件。
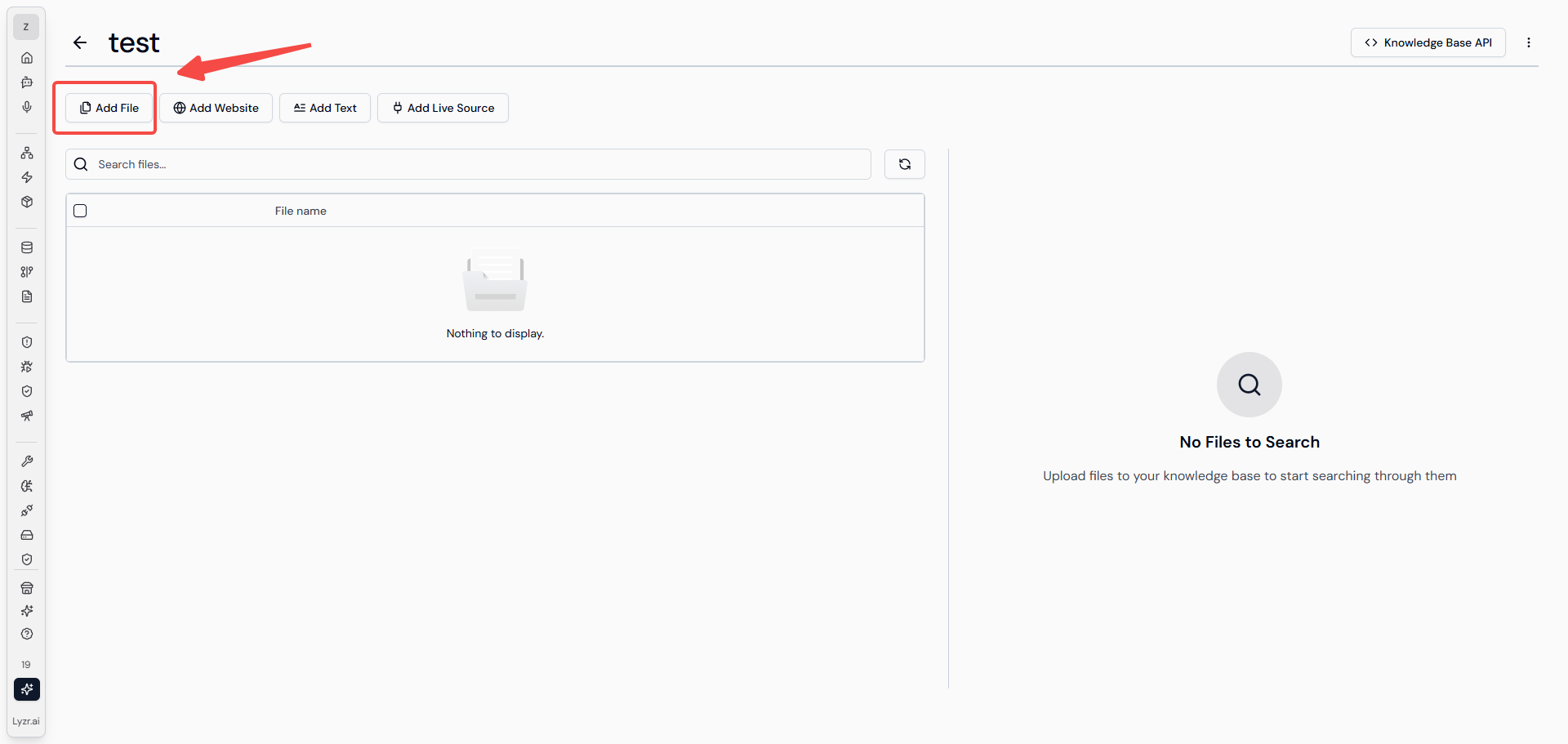
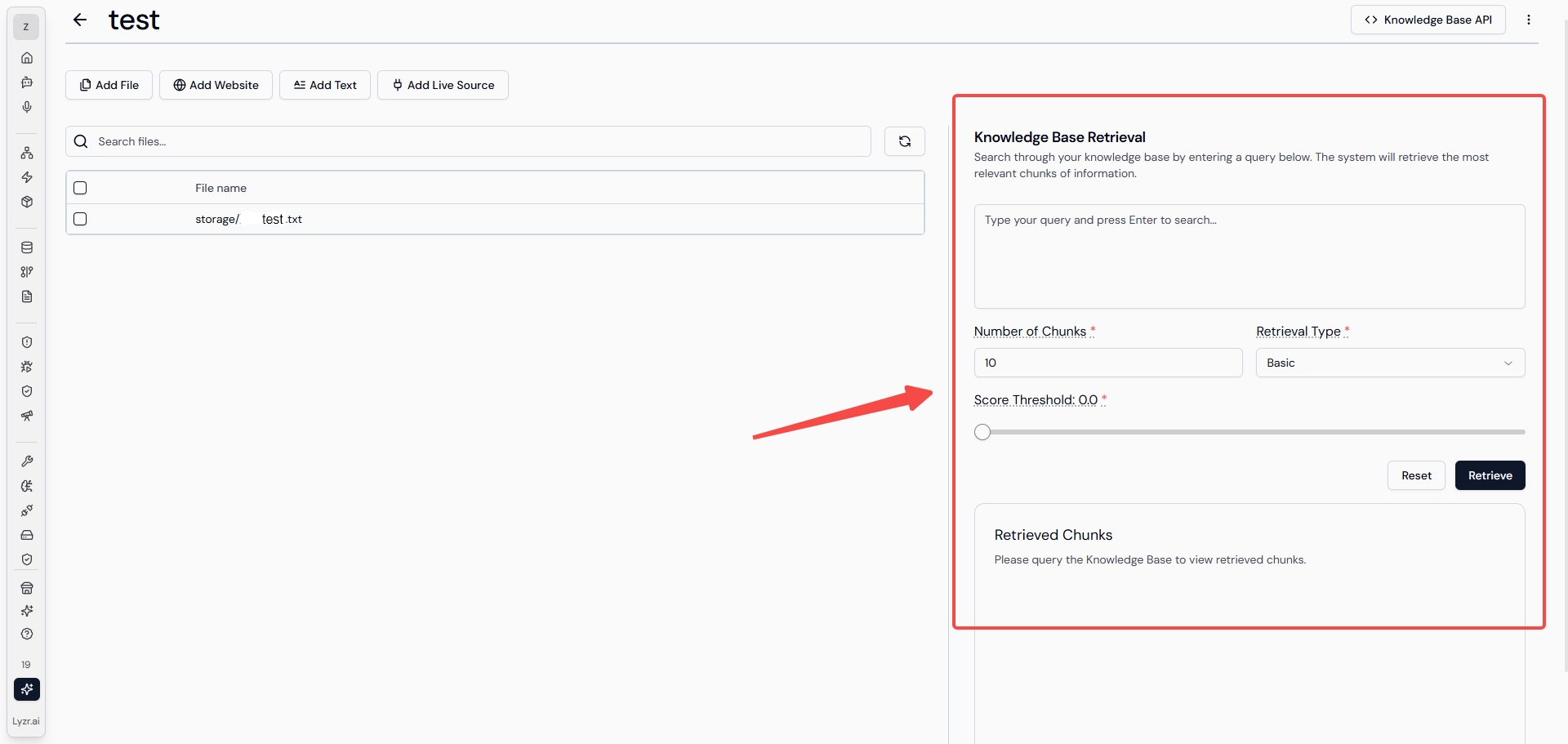
然后才会在界面中呈现出用户可以进行设置的知识库检索选项(上图红框中的内容),Lyzr 在这部分的设计 ,个人认为优于百度千帆的设计,百度千帆中对于知识库的分段配置、检索方式、配置策略等等字段较为复杂,对于新手入门的用户并不友好,而Lyzr AI 这种设计降低了非技术用户的理解成本,只给用户提供最必要的配置字段,既让用户有参与感也不会让用户感觉难操作。
用户不一定需要先理解复杂的知识增强逻辑,只要知道:
我把组织资料放进 Knowledge Base,之后在 Workflow 里接一个 Knowledge Base 节点,就能让 Agent 基于这些资料回答。
Lyzr AI 的知识库更像是面向 Agent 的 no-code RAG pipeline。它把知识接入、切片、向量索引、检索策略、Prompt 组装、引用输出和模拟测试封装到 Knowledge Base 与 Agent 的连接过程中,整体的知识库配置会更加轻量化,更适合新人着手搭建。
小结
在知识构建域:
千帆更强调知识工程化处理
Lyzr AI更强调知识库使用门槛降低
两者处理的仍然是同一个 RAG 问题:知识如何从原始材料变成可检索资产。
七、用 Kano 重新理解 RAG 功能层级
这里需要特别说明:
严格意义上的 Kano 分类,应通过用户问卷调研得到。
下面这张表并不是正式调研结论,而是基于个人对于当前产品成熟度与功能普及程度,做出的产品分析式初判,仅供大家参考。
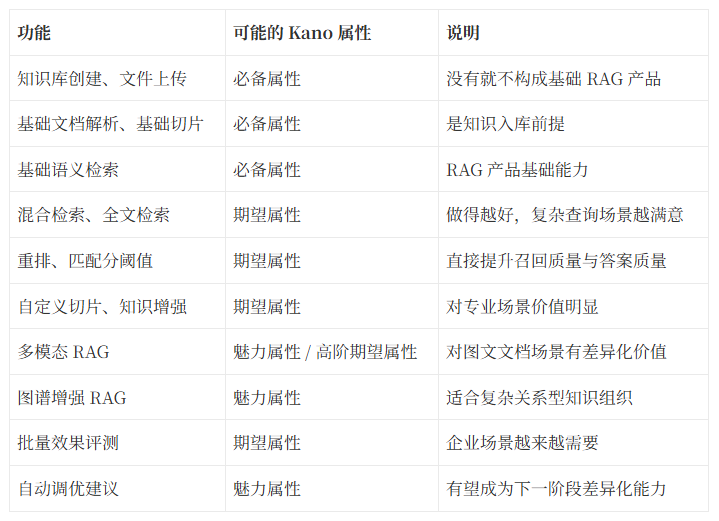
这张表的意义是:
不是所有功能都值得同等投入。而且我们仍然可能对这个kano的判断结果有所怀疑,因此需要进一步确定对功能的属性判断结果是可信的。
下面我们将其和 DDD 子域划分结合,就会得到更清晰的优先级判断。
八、DDD × Kano 结合后,如何指导产品功能设计?
可以形成如下矩阵:
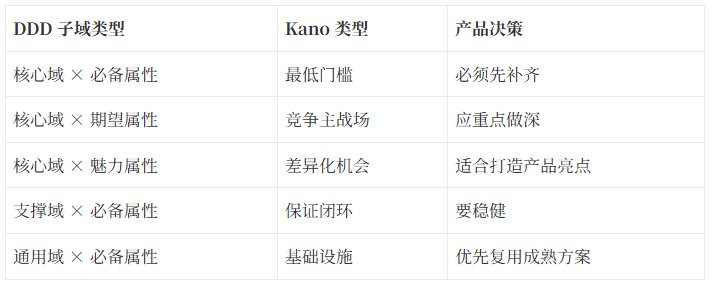
套到 RAG 产品里,可以得到几个很直接的判断。
1. 知识构建域不能只满足“能上传”
如果产品只做到“创建知识库 + 上传文件”,那只能算门槛。
真正值得投入的是:
- 复杂文档解析
- 切片策略
- 知识增强
- 多模态内容组织
因为这些能力决定了后续检索质量。
2. 检索增强域是核心竞争战场
未来 RAG 产品的差异,绝不只是“有没有知识库”,而是:
- 能否更准确召回
- 能否针对不同场景选择更合适策略
- 能否减少无关内容进入上下文
- 能否把检索能力配置化、产品化
这一点,千帆与 Lyzr AI 都已经通过不同方式体现出来。
3. 效果评测将从“高阶能力”逐步变成主流需求
当 RAG 从 Demo 走向正式业务,产品就必须回答:
- 这个问答系统到底好不好?
- 哪个版本更优?
- 优化是否真的生效?
所以,评测与优化不应长期被当作“后台工具”,而应逐渐成为核心能力的一部分。千帆当前对效果评测任务的产品化,就是这一趋势的体现。
4. 非技术用户并不意味着“隐藏所有流程”
这点非常重要。
很多产品一提“面向非技术用户”,就想把所有复杂度都藏掉。
但 RAG 产品不能完全这样做。
真正好的设计不是:什么都不让用户知道。
而是:
把必须理解的关键流程显性化,把不必要的底层复杂度收起来。
从这个角度看:
- 千帆更像是在教用户“如何调好一个 RAG 系统”;
- Lyzr AI 更像是在帮助用户“如何快速把 RAG 能力接进业务工作流”。
这两种路线都有合理性,千帆的用户群体更偏向于技术性人员,而Lyzr AI则对新手用户更为友好。
九、最终结论:RAG 产品功能,本质上是处理流程的产品化表达
本文试图说明一件事:
RAG 产品中的功能,不是孤立的功能点,而是从一条知识处理流程中自然生成的产品模块。
而 DDD 与 Kano 的结合,为我们提供了一个更完整的产品分析方法:
- DDD 帮我们看清业务重点;
- Kano 帮我们看清用户价值层级;
- RAG 流程帮我们看清功能从哪里来。
如果后续要设计一款面向非技术用户的 RAG 产品,先问:
- 这项功能解决的是 RAG 流程中的哪个问题?
- 它属于核心域、支撑域,还是通用域?
- 它对用户来说是必备、期望,还是魅力能力?
DDD的领域划分,帮助更快速敲定产品的核心域业务。
- 千帆强调知识增强、评测任务
- Lyzr 强调简化知识库步骤、必要检索配置
- 某些平台强调自动切片优化、可视化调试
这说明这些能力很可能是当前赛道的 核心竞争区。
所以说RAG 产品中的功能,其实并不是产品人员凭空想出来的,而是正是因为他们懂得RAG的数据处理逻辑、明白其价值所在,并围绕 RAG 处理流程逐步产品化的结果。
本文由 @:) 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


