
 起点课堂会员权益
起点课堂会员权益病历质检优化实践
医疗AI系统的架构迭代正经历从野蛮生长到精细设计的转变。本文以口腔诊疗场景为例,深度拆解如何通过中间件路由、RAG规则解耦和思维链编排三大技术方案,将原本臃肿的百节点系统重构为灵活高效的智能引擎,实现从'病种爆炸'到'零代码维护'的跨越式升级。

一、早期架构回顾
在项目初期,为了快速验证业务逻辑,产品同学采用了基于条件分支的 “硬编码” 模式。
1.1 早期架构图
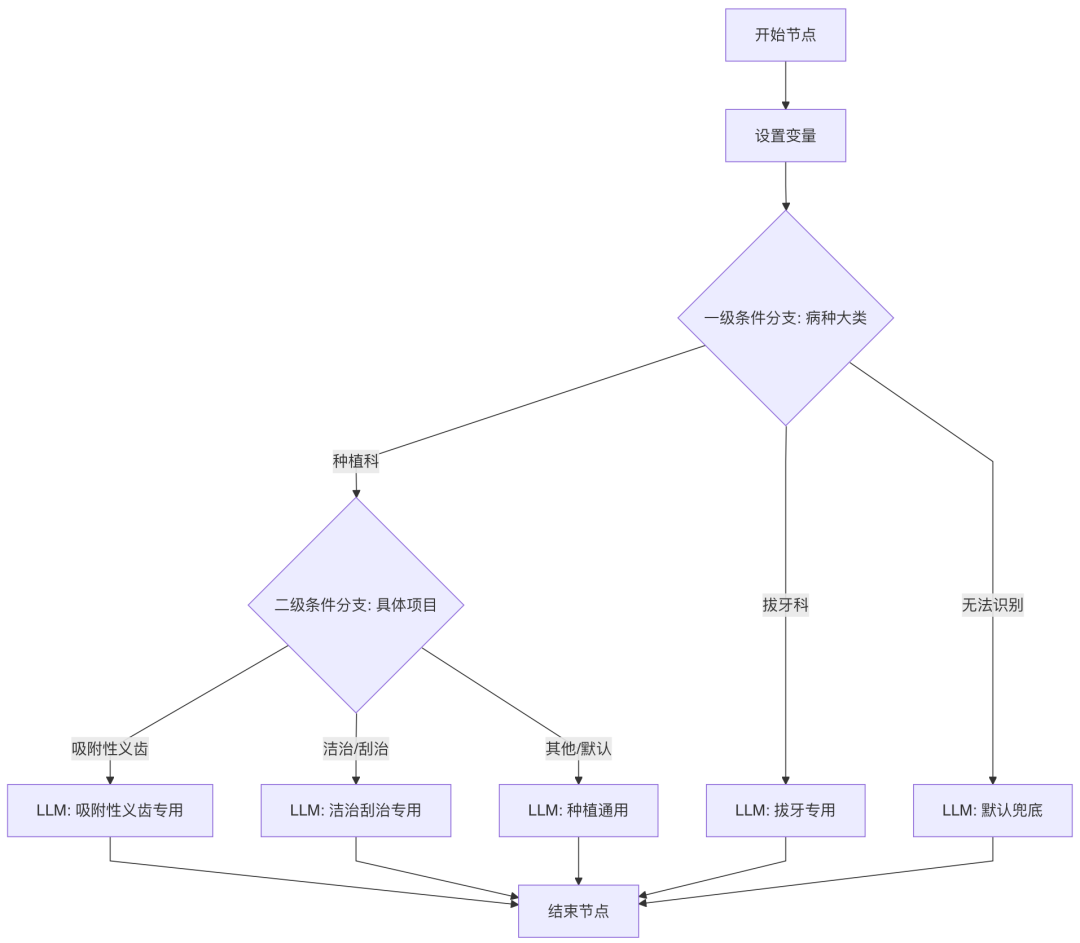
1.2 早期架构的痛点
1.节点爆炸:
- 每新增一个病种(如“根管治疗”),就需要新增一个分支和一个独立的 LLM 节点。
- 如果有 100 个病种,将会有 100 个 LLM 节点,流程图将变得巨大且不可维护。
2. 提示词维护灾难:
- 规则重复:所有 LLM 节点(LLM 2, 3, 4…)都需要包含“主诉必须有时间”、“过敏史必填”等通用规则。
- 修改困难:一旦通用规则发生变更(例如:要求“既往史”增加手术记录),开发人员必须逐个打开几十个 LLM 节点手动修改 Prompt,极易遗漏。
3. 上下文隔离:
由于每个 LLM 节点是独立的,它们无法共享知识。拔牙的 LLM 不知道种植的规则,导致无法进行跨科室的综合判断或逻辑复用。
二、重构优化方案
2.1 新版架构图
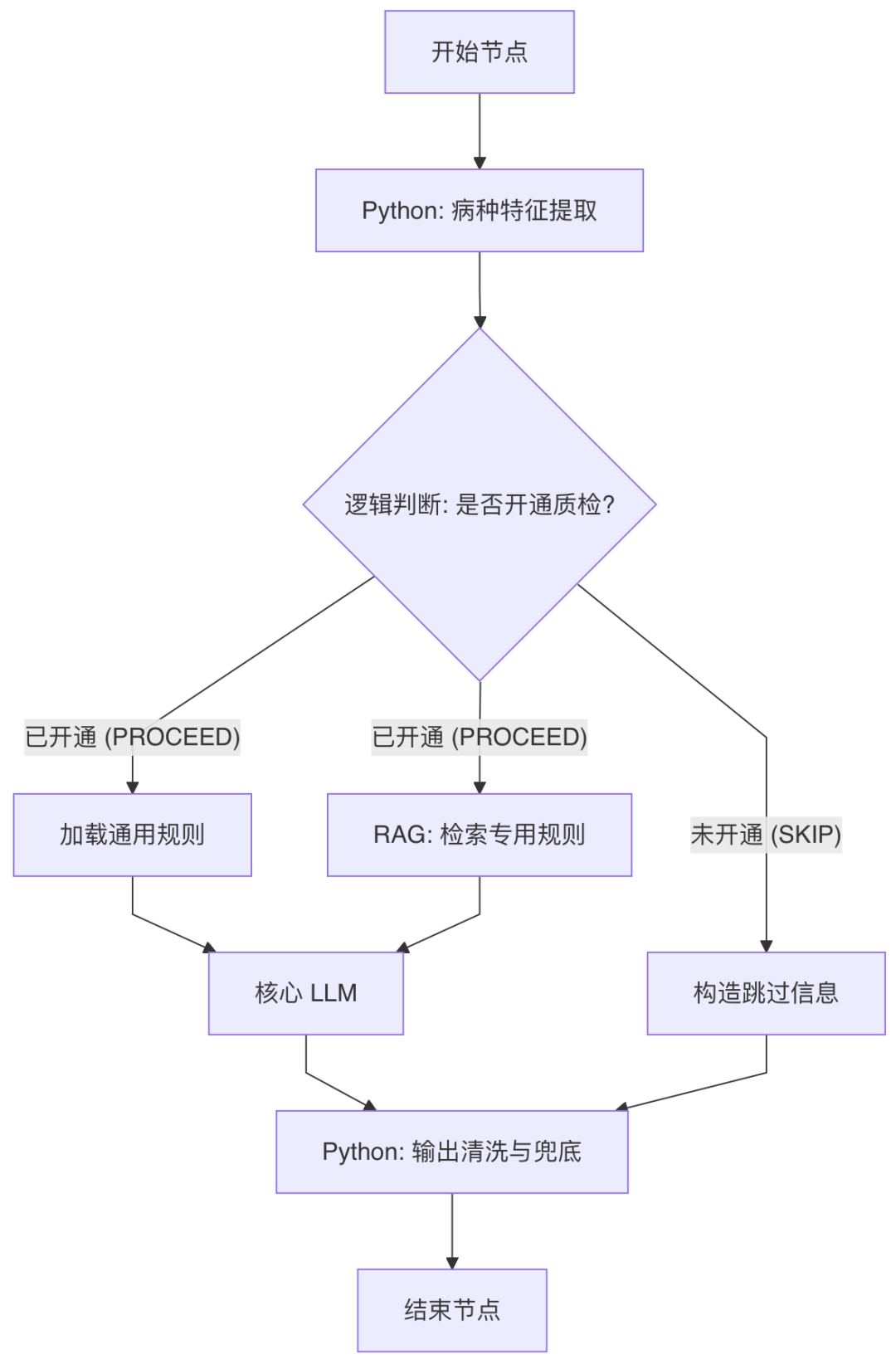
2.2 核心优化点
1.中间件路由:
- 不再依赖 LLM 也就是大模型去“猜”病种,而是用确定性的 Python 代码根据关键词(如“残根”->拔牙,“吸附性”->种植)进行分类。
- 价值:准确率 100%,且运行速度极快,不消耗 Token。
2. RAG 规则解耦:
- 通用规则:作为静态变量注入。
- 专用规则:存放在知识库中,通过标签动态检索。
- 价值:流程图中只保留 1 个 LLM 节点。无论有多少病种,结构不变。
3. 思维链编排 (CoT):
在 Prompt 中强制要求先输出 思维链,分析通用与专用规则的冲突(如 [专用], [合并+扩展], [覆盖] 逻辑)。
价值:解决了“规则打架”的问题,大幅提升了复杂病历判定的准确性。
三、新方案的优势
3.1 业务侧:维护极其简单
以前:业务提需求 -> 开发改代码 -> 重新测试 10 个节点。
现在:业务人员只需在后台上传或修改 Markdown 文档(如更新 种植-吸附性义齿.md),系统自动生效。开发人员零感知。
3.2 技术侧:极其稳定健壮
结构化输出:通过 JSON输出 + Python 后置清洗,彻底解决了大模型输出 Markdown 格式混乱、截断等工程顽疾,接口稳定性达到 API 级别。
3.3 成本侧:极致性价比
- 按需加载:RAG 只召回当前病历需要的 1 份专用规则,输入 Token 数大幅减少。
- 模型降本:由于 Context 清晰,即使使用 qwen3-max,单次调用成本也极低。
本文由 @里奥 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






评论
- 目前还没评论,等你发挥!


