
 起点课堂会员权益
起点课堂会员权益“评测即PRD”:AI产品经理的必备技能,从写文档到写评测
硅谷AI产品团队正掀起一场思维革命:Evals正取代PRD成为产品经理的核心工具。从Anthropic到Yelp,领先团队不再用静态文档定义产品,而是通过评测体系动态校准AI模型的行为边界。本文将深入解析如何构建'活的PRD',揭示黄金对话、LLM法官等创新方法如何重塑产品开发逻辑。

在硅谷,一种新的共识正在形成,来自OpenAI、Anthropic、Yelp等AI公司的产品负责人们都在强调:AI时代的PM,最核心的技能不再是写PRD,而是写Evals。
我们也非常认同这个观点,评测是AI产品经理在当前时代最重要的思维转变之一,“评测即PRD(Evals as the New PRD)”

一、PRD的转折: 从“定义产品”到“定义评测”
1. 传统PRD的局限
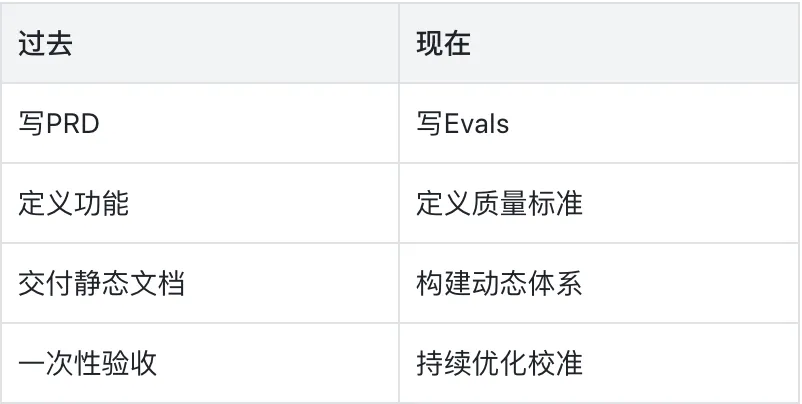
过去,产品经理通过PRD明确功能和边界。但AI产品的特点是:模型具有随机性、输出动态、场景开放,任何静态文档都无法覆盖所有情况。
因此,AI产品团队逐渐转向另一种方式:不再靠文字定义产品,而是靠评测体系定义产品。
Evals 包括自动化测试、黄金对话(Golden Conversation)、LLM法官(LLM-as-a-Judge)共同构成了一个“活的PRD”:可运行、可验证、可演化。
2. “评测即PRD”的思维转变
传统PM的路径是:先写需求,再做开发。AI PM的路径则是:先实验,再评测,从评测中提炼需求。
以前我们写文档指导模型;现在我们写评测校准模型。
评测不是附属环节,而是核心定义。它既是产品规范(Spec),也是验证机制(Judge),为团队提供真实、可操作的质量信号。
二、如何构建“活的PRD”
1. 从“黄金对话”出发
优秀的AI产品设计从体验出发,而不是从功能清单开始。团队会先编写理想的“黄金对话”:
用户:“帮我写一份简历。”
模型:“好的,请提供你的经历,我会帮你优化成更有吸引力的版本。”
这段对话本身就是最早的PRD,展示了语气、引导和边界。PM再据此反推:
- 系统提示词(System Prompt)如何设计;
- Agent流程如何编排;
- 评测标准如何设定。
Yelp、Anthropic等团队正以这种方式工作:从理想体验出发,用评测体系保障一致性。
2. 错误分析:让需求“长”出来
AI产品的需求不是写出来的,而是在错误中被发现的。PM需要系统化地分析失败:
- 抽样100个真实用户交互日志(Traces);
- 手动标注每条结果为Pass或Fail;
- 撰写失败原因的批评笔记;
- 归纳出结构化的失败模式。
这份“失败模式表”,比文字描述更真实,也更能转化为可执行指标。它可以直接用来训练LLM评测器,让模型自动完成质量检查。
3. LLM法官:自动化的质量定义
当系统复杂到人工难以评测时,引入LLM法官(LLM-as-a-Judge),针对特定问题做二元判断(Pass/Fail)。
例如:
- “回答是否忠实于检索内容?”
- “是否应转接人工客服?”
这种二元评测能迫使团队清晰界定质量标准。自动化运行的评测体系,则让PRD成为一个持续迭代的系统,每次模型更新都能获得即时反馈:
“我们离理想状态更近了,还是更远了?”
三、评测驱动的架构与PM角色的升级
1. 复杂系统中,评测决定架构
在RAG(检索增强生成)或Agent系统中,Evals不仅衡量结果,还帮助团队拆解架构:
- 对RAG:分为检索器(Retriever)和生成器(Generator)两部分,分别评测召回率(Recall@K)与忠实度/相关性(Faithfulness & Relevance);
- 对Agent:建立“失败矩阵”,标记在哪一步出现问题。评测粒度越细,系统反馈越清晰。
可以说,评测结构就是产品结构。
2. 新一代PM:评测架构师
AI时代的产品经理正在转变:
四、Evals,是AI产品的语言
传统PRD告诉团队“我们要造什么”;Evals式PRD告诉模型“什么才是好”。
评测不只是验证标准,而是产品需求的动态表达。
Evals,是AI产品的语言;评测体系,是产品不断进化的核心。
专栏作家
hanniman,微信公众号:hanniman,人人都是产品经理专栏作家,前图灵机器人-人才战略官/AI产品经理,前腾讯产品经理,10年AI经验,13年互联网背景。
本文原创发布于人人都是产品经理,未经许可,不得转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


