
 起点课堂会员权益
起点课堂会员权益视频分镜提示词Skill,详细制作过程分享!
作者以一篇轻松实用的“复健”之作,开源了其精心打造的「短剧剧本转视频提示词」Coze Skill:该工具不仅能将复杂剧本文档一键拆解为精准的AI视频分镜提示词,更难得的是,作者毫无保留地复盘了从定义标准化文件结构、驱动AI自动编写功能脚本,到构建专属知识库与模板体系的完整开发路径,让读者在直接获取高效提效工具的同时,也能掌握一套系统化定制AI Agent的底层方法论。
好久不见了,放假给我放爽了,回来猛猛干活了。今天这篇比较轻松,我先复健一下,写个简单一点的关于视频提示词 Skill 制作的。
上次写Coze Skill的时候,我曾经分享过一个剧本生成分镜的Skill,大家可以直接在 Coze 使用,链接在:
https://www.coze.cn/?skill_share_pid=7596234767713173538
也可以直接下载 Skill 文件,文件附件链接我放文章最后的飞书云文档链接了。原 Skill 做得比较通用,大家可以在我的基础上修改。

关于它怎么使用,我在 Coze Skill 也写过,就不再赘述,在上面这个 Coze 技能这里也可以看到使用案例:

或者下载最后的 Skill 文件,上传到支持 Skill 使用的工具使用也可以:
今天分享这样的 Skill 怎么做。
简单来说思路就是,首先想明白要做什么,然后将任务一步步拆细,先有整体结构,然后填充枝叶。
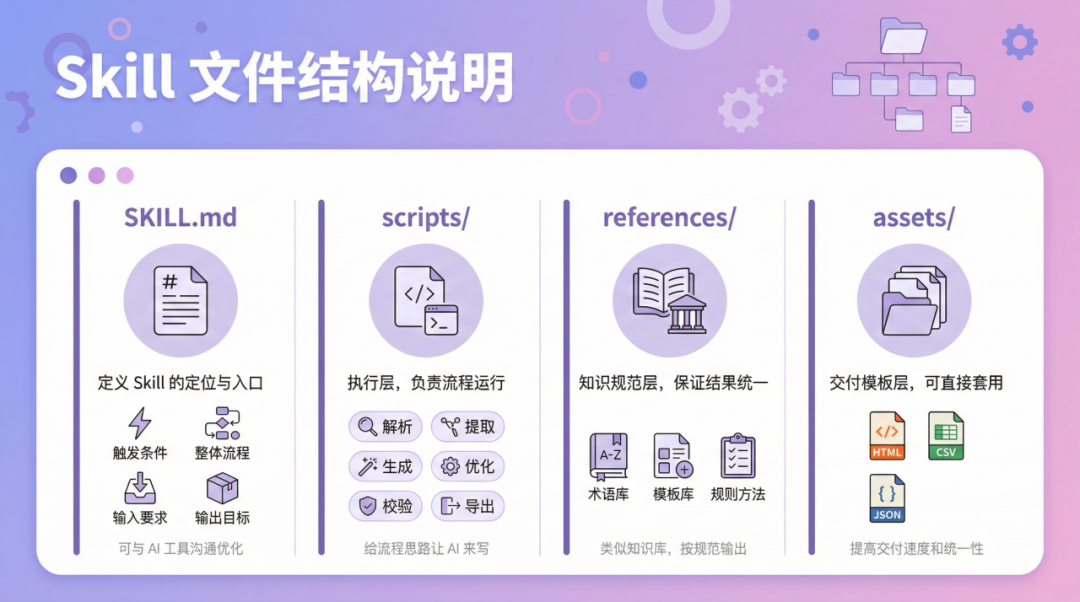
完整的 Skill 结构是这样的:

上面几个结构的说明👇
- SKILL.md:定义这个 Skill 的定位与入口,说明怎么触发、整体流程、输入要求、输出目标。 这个可以自己写一个雏形,然后和 AI 工具沟通并优化。
- scripts/:执行层,这里放的 Python 自动化脚本,它负责把流程真正跑起来(解析、提取、生成、优化、导出等)。这个可以给到流程思路让AI来写。
- references/:知识规范层,提供术语、模板、规则和方法,保证结果统一、可解释、可复用。类似知识库,可以把往常使用的格式规范放进来,并且在需要生成具体某个部分的内容的时候,要求它按照这个规范输出。
- assets/:交付模板层,提供可直接套用的资源文件(如 HTML/CSV/JSON 模板与速查表)。它可以提高交付速度和统一性,避免每次从零做格式与排版。
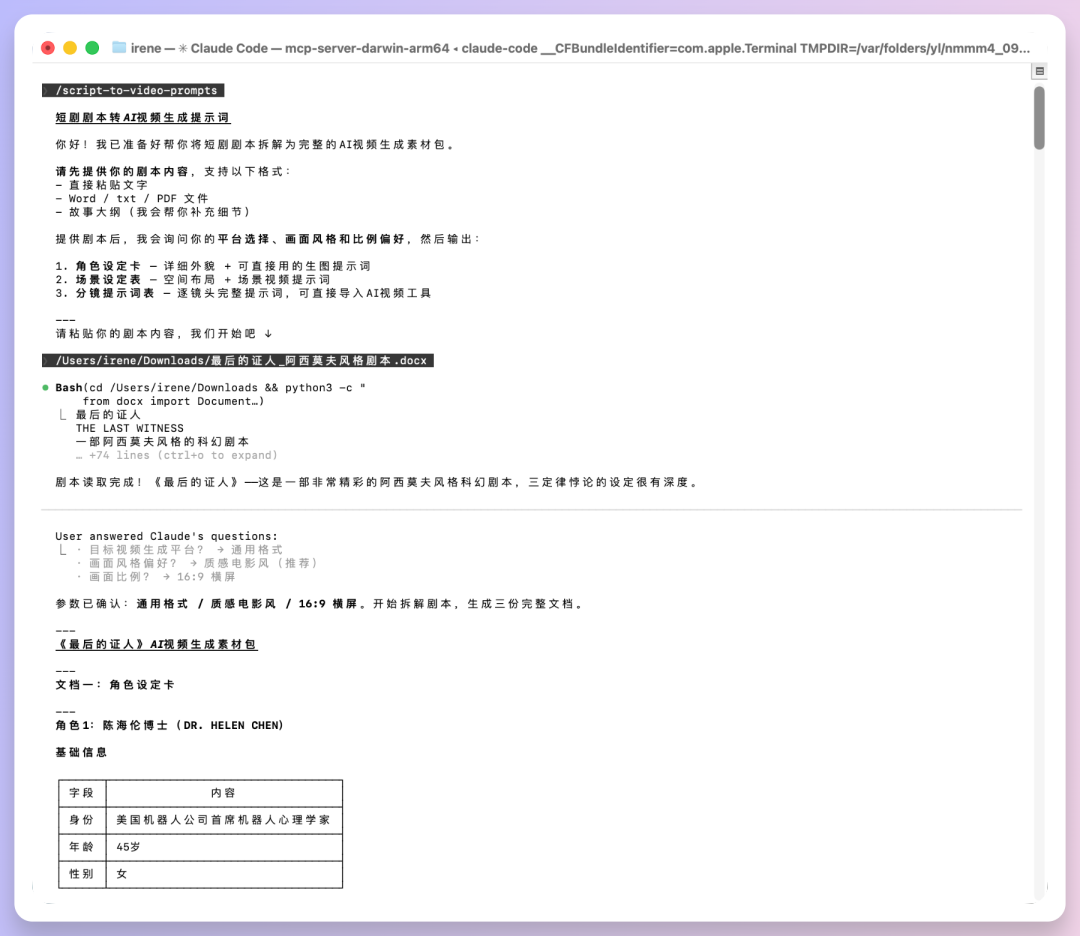
下面是SKILL.md文件,完整 Skill 内容大家可以在文章最后的分享链接去下载查看:
—
name: script-to-video-prompts
description: 短剧剧本转视频提示词生成器。将用户上传的短剧剧本文档智能拆解为可直接用于AI视频生成的完整中文提示词体系。输出包括:角色设定提示词、场景设定提示词、逐镜头分镜提示词。支持批量处理、多格式导出、一致性校验。当用户说”剧本转视频提示词”、”拆解剧本生成分镜”、”短剧转视频”、”批量生成分镜提示词”、”剧本可视化”时触发。
—
# 短剧剧本转视频提示词生成器
将短剧剧本文档智能拆解为可直接用于AI视频生成的完整中文提示词体系,支持自动化批量处理。
## 用户输入
– 短剧剧本文档(Word/PDF/TXT/Markdown/Final Draft .fdx)
– 可选:风格参考图片、角色参考图片、已有角色设定表
## 工作流程
### 1. 剧本智能解析
使用 `scripts/parse_script.py` 解析剧本:
– 自动识别剧本格式(标准编剧格式/自由格式)
– 提取场次(Scene)、场景描述(Action)、角色对白(Dialogue)、动作指示(Parenthetical)
– NLP分析:情绪曲线、节奏变化、画面密度
– 自动生成场次时长估算
### 2. 角色设定提取
使用 `scripts/character_extractor.py` 提取角色信息:
– 基础外貌(年龄、性别、体型、五官特征)
– 发型发色、肤色
– 服装造型(支持多场次服装变化追踪)
– 角色气质/性格的视觉化表达
– 标志性道具/配饰输出格式参考 [references/character_template.md](references/character_template.md)
### 3. 场景设定分析
使用 `scripts/scene_analyzer.py` 分析场景:
– 场景类型(室内/室外、具体地点)
– 空间结构、关键道具布置
– 光线设计(光源类型、方向、强度、色温)
– 色彩基调、视觉氛围
– 天气/时间/季节输出格式参考 [references/scene_template.md](references/scene_template.md)
### 4. 分镜提示词生成
使用 `scripts/storyboard_generator.py` 生成分镜:
– 镜头编号(场次-镜号)
– 景别(大特写/特写/中近景/中景/中远景/远景/大远景),详见 [references/shot_terminology.md](references/shot_terminology.md)
– 画面构图(三分法位置、视线引导)
– 角色动作、表情、站位
– 运镜方式(固定/推/拉/摇/移/跟等),详见 [references/shot_terminology.md](references/shot_terminology.md)
– 情绪氛围关键词,详见 [references/mood_keywords_library.md](references/mood_keywords_library.md)
– 建议时长(秒)
– 转场方式
### 5. 一致性校验
使用 `scripts/consistency_checker.py` 校验:
– 角色跨镜头一致性控制
– 场景连续性检查
– 光影风格统一性校验
– 详见 [references/consistency_control.md](references/consistency_control.md)
### 6. 导出
使用 `scripts/export_utils.py` 导出:
– 支持格式:Markdown/JSON/CSV/Excel
– 支持按场次/角色/场景分类导出
– 可生成可视化分镜脚本
## 输出结构
“`
一、项目元数据
– 片名、集数、总时长、场次数
二、风格总设定
– 画面风格、色彩体系、光影风格
三、角色设定库
– JSON结构化数据 + 自然语言描述
四、场景设定库
– JSON结构化数据 + 自然语言描述
五、完整分镜提示词
– 按场次顺序排列,提示词全部使用中文
六、一致性参考表
– 角色/场景一致性种子词
“`
## 参考文件
### scripts/(自动化脚本)
– `parse_script.py` – 剧本解析器
– `character_extractor.py` – 角色信息提取
– `scene_analyzer.py` – 场景分析
– `storyboard_generator.py` – 分镜生成
– `consistency_checker.py` – 一致性校验
– `export_utils.py` – 多格式导出
– `prompt_optimizer.py` – 提示词优化
### references/(规范文档)
– `screenplay_format_spec.md` – 剧本格式规范
– `character_template.md` – 角色设定模板
– `scene_template.md` – 场景设定模板
– `shot_terminology.md` – 景别/运镜术语词典
– `mood_keywords_library.md` – 情绪氛围关键词库
– `video_style_guide.md` 视频风格指南
– `consistency_control.md` – 一致性控制指南
– `prompt_patterns.md` – 高效提示词模式库
### assets/(模板资源)
– `storyboard_template.csv` – 分镜脚本CSV模板
– `export_template.html` – 可视化导出HTML模板
下方【文件结构】是 Skill 的文件结构,它的文件结构中必须有 SKILL.md 文件。YAML头部、Markdown正文和关键要素是SKILL.md 格式规范。(可选)的部分是不固定的,可以是文件也可以是文件夹,文件夹的命名也可以按照自己的要求来👇

制作 Skill 的时候,可以前期制定标准,中期优化功能模块,后期测试优化与封装。下面是完整的执行思路,注意下方虽然分了步骤,但是实际生成 Skill 的时候它也可以一次执行所有要求,再根据效果继续优化调整的。
前期:制定标准
1. 明确这个Skill操作的总流程
我希望这个 Skill 的工作流程是这样的:
剧本解析 → 角色提取 → 场景分析 → 分镜生成 → 提示词优化 → 一致性检查 → 导出。

如果没有具体明确的工作流程要求,后面所有实现都会默认按照这个规范。
2. 确定输入内容格式
确定支持哪些输入:比如txt/md/docx/pdf/fdx。 同时定义默认输入是一个剧本文档,也可以是一段话甚至一句话,但是这样的话效果和内容走向可能会不太可控;“推荐输入”可加角色图参考、风格图参考、画幅要求、时长限制。
3. 明确Skill最终产出什么
先写清楚最终要产出哪些文件:角色设定、场景设定、分镜提示词、一致性报告、导出文件格式等,这一步的作用是防止中途越做越偏。
4. 设计统一的结构
确定每一步输入输出长什么样。我希望它输出分镜表是什么样的,希望它输出角色设计提示词格式是什么样的等等。这一步很关键,每个输出项的字段先定好,再让 AI 按要求输出,后面就不会乱。
比如我希望完整的分镜提示词表是按照第 X 幕第 X 场景,每个场景的提示词表包含镜头编号、景别、画面描述、构图、运镜、光线、色调、氛围、时长、镜头角度、提示词等。那么我可以自己做或者让AI来生成这样一个统一的表格模板,如果本身有这样的模板,也可以直接放进去。后面的每个脚本都读写这个模板,并且按照这个格式输出,这样就不会不同幕和场景之间格式互相对不上。
可以制作模板放在 assets 里,让 AI 生成的脚本参考这些模板规范进行生成。
中期:优化功能模块
5. 准备references内容
references 中存放术语与模板。
整个提示词的规则可以输出为单独的文档,比如剧本格式规范、镜头术语、情绪词库、提示词模板、一致性指南等。这样会更方便修改和规范指定方向的文档内容。其他人查看时,也能知道为什么这么做。
6. 准备assets文件夹内容
assets 中存放可复用模板内容。
比如:分镜 CSV 模板、角色提示词模板、HTML 模板、速查表等等。这样每次新项目也能直接复用,不用重做排版和字段。
references 和 assets 中的内容建议单独生成、优化,输出文件后放进去,再给到指定路径给后续脚本调用。
7-12. AI生成脚本
接下来的 7-12 几个模块都是脚本,这些都可以让 AI 来写。比如 7 的提示词参考如下:
帮我生成脚本,用于把原始剧本内容(支持 `txt/md/docx/pdf/fdx`)解析成结构化 JSON,要求自动识别并分类:场景标题(INT/EXT 或“第X场/场景X”)、角色名、对白、动作、转场,并输出中文字段:`标题`、`场景列表`、`全角色`、`全地点`、`总时长秒数`、`元数据`(含`场景数`、`角色数`、`地点数`),其中每个场景至少包含`场景编号`、`场景标题`、`地点`、`时间段`、`内外景`、`角色`;规则是“上一行是角色名则下一行优先判定为对白,否则判定为动作”,没有场景标题时自动创建默认场景,空行跳过;重点先保证稳健性和通用性,不追求复杂算法,优先做到“任何剧本或任意文本内容都能读入并形成场景列表”;支持通过命令行传入文件路径并输出格式化 JSON,代码尽量清晰、注释简单、依赖缺失时提示安装。
更简单点(自己直接写),这样写不满意的话可以在这个基础上让 AI 优化提示词:
生成一个通用剧本解析脚本,能读取常见文本格式并智能分析内容,自动识别场景、角色、对白、动作和转场,输出清晰的结构化 JSON;要求优先保证稳定可用,即使输入不规范也能自动补默认场景并正常返回结果。
现在的 AI 工具都很机灵了,我们只要要求它生成 Skill 的时候生成单独的脚本,它就会自己生成。大多数时候都不需要单独输入提示词。
7. 实现【剧本解析】模块
把原始剧本变成结构化数据。识别生成场景标题、角色名、对白、动作、转场。
8. 实现【角色提取】模块
从【7】的解析结果里提角色档案:性别、年龄段、体型、发型、关键词。要求输出时给每个角色一段提示词描述,后面分镜直接可用,调用也方便。
9. 实现【场景分析】模块
从【7】的每个场景里提地点、室内外、时间段、光线、氛围,给每个场景生成一条基础视觉提示词。这一层是全片视觉基础,后面镜头都在它上面叠加。
10. 实现【分镜生成】模块
按【7】的场景自动拆成镜头,至少包含:建立镜头、角色出场、对话镜头。每个镜头都要有编号、景别、运镜、动作、时长、转场、提示词。先保证“有镜头可用”,再逐步优化镜头艺术性。
11. 实现【提示词优化】模块
把镜头提示词做统一处理:术语标准化、去重复提示词、补质量词(提升画面质量和稳定性的万能词,比如高质量、电影感、清晰对焦这类)。这样能让输出更适配视频模型,不会每条风格都散。有时间的话还可以针对不同风格单独制作不同风格、不同视频模型的提示词规范表。
12. 实现【一致性检查】模块
检查角色跨镜头提示词、场景是否跳变、光线是否变化突兀等,输出“问题 + 修复建议 + 复用规范提示词”。
后期:测试优化与封装
13. 导出格式确认
确认默认导出格式,这里我希望至少支持 JSON + CSV + Markdown。目标是让不同职能都能直接看和用。
14. 上传剧本进行测试
用 2-3 份不同的剧本跑全流程。这个剧本可以 AI 生成也可以自己提供。
重点检查:字段是否缺失、镜头是否正确、提示词是不是符合自己的要求。
重要的部分可以单独拎出来补充单独文档和脚本,比如我对视频提示词有指定的要求,那么可以单独一个提示词参考文档(放在 references )或提示词格式参考模板(放在 assets )并要求脚本在指定场景调用。
发现问题就让 AI 针对对应模块修改。
15. 完成 Skill 封装
最后整理为清晰目录,最简单的可以就一个SKILL.md,复杂一些就可以加上脚本、参考、模板等文件夹了,我这里的格式是:
SKILL.md + scripts/ + references/ + assets/。
这个直接让 AI 封装Skill然后自己确认就可以。到这一步,我们就拥有一个比较完整的 Skill 了。
梳理完全部步骤后,就可以输出一个完整的提示词,让 AI 生成 Skill 了。需要详细输出的地方,可以单独生成提示词或模板后放进去,要求脚本调用。
下面我放了最初我的提示词要求,后期对这组提示词进行了分布的详细优化,但是我的 Claude 账号被封了所以优化提示词的过程没有了😅,但大致的逻辑思路是上面这样的,供大家参考。
另外,references/ 和 assets/ 中的内容也建议通过对话多轮优化到自己满意的效果。
你是一个 Skill 开发助手,帮我从零构建一个「剧本转视频分镜提示词」Skill。请按以下规格和顺序执行,不可跳步,不可合并步骤。
—
【第一步:工作流程定义】
这个 Skill 的工作流程是:
先解析剧本结构,识别出幕、场景、对白和动作描述;
然后提取所有角色,为每个角色生成设定;
接着分析所有场景,为每个场景生成设定;
再把每个场景拆解成具体镜头,生成分镜提示词表;
之后对每条提示词做优化,确保它足够具体、包含必要的视觉参数、并且与角色和场景设定一致;
然后做一致性检查,交叉比对角色、场景与分镜之间的偏差;
最后按用户要求的格式导出。不可以跳步,不可以合并步骤。
如果用户没有特别要求改变流程,永远执行完整的七步。
【第二步:输入规格定义】
支持接收 txt、md、docx、pdf 和 fdx 格式的剧本文件。最低可运行的输入是一个剧本文档,哪怕只是一段话甚至一句核心概念也能启动流程,但必须在开始前告诉用户:当前输入信息有限,后续生成内容的风格一致性和走向可能不完全可控,建议补充更多信息。推荐的输入是剧本加上角色参考图、风格参考图、目标画幅比例、目标时长、以及希望的视觉风格关键词。用户提供的参考图永远优先于自己的推断。
【第三步:最终产出定义】
最终产出:一份角色设定文档,包含每个角色的外貌、服装、气质关键词和可用于 AI 生图的完整提示词;一份场景设定文档,包含每个场景的空间描述、光线类型与方向、主色调和氛围词;一份完整的分镜提示词表,按照幕、场景、镜头三级结构组织;一份一致性检查报告,标注角色和场景在不同镜头之间的视觉偏差;最后是以上所有内容的导出文件,支持 CSV、Markdown、Excel 和 HTML 格式。这五样东西是这个 Skill 存在的全部目的,任何中间步骤都是为了最终产出它们。
【第四步:统一结构规范】
分镜提示词表按第 X 幕第 X 场景组织,每个场景的提示词表包含以下字段:镜头编号、景别、画面描述、构图、运镜、光线、色调、氛围、时长、镜头角度、提示词。先生成这个统一的表格模板,后面所有脚本都读写这个模板并按此格式输出。
【第五步:references 内容】
生成以下规范文档:剧本格式规范、镜头术语表、情绪词库、提示词模板、一致性检查指南。每个文档独立成文件,方便后期单独修改。
【第六步:assets 内容】
基于第四步的结构规范,生成以下可复用模板文件:分镜 CSV 模板、角色提示词模板、HTML 导出模板、速查表。
【第七步:剧本解析脚本】写一个脚本,能读剧本文件,分出场景、角色、对白和动作,最后输出为 JSON 格式。代码清晰精炼、注释清楚。
【第八步:角色提取脚本】
从解析结果里提取角色档案,包含性别、年龄段、体型、发型、关键词。为每个角色输出一段可直接用于 AI 生图的提示词描述。
【第九步:场景分析脚本】
从每个场景里提取地点、室内外、时间段、光线、氛围,为每个场景生成一条基础视觉提示词。
【第十步:分镜生成脚本】
按场景自动拆成镜头,至少包含建立镜头、角色出场、对话镜头,每个镜头严格按照第四步定义的字段输出。
【第十一步:提示词优化脚本】
对所有镜头提示词做统一处理:术语标准化、去重复、补质量词、输出质量打分。参考 references/ 中的提示词模板和镜头术语表。
【第十二步:一致性检查脚本】
检查角色跨镜头是否漂移、场景是否跳变、光线是否变化突兀,输出「问题 + 修复建议 + 复用规范提示词」报告。
【第十三步:导出脚本】
将所有产出内容导出为 JSON、CSV、Markdown 三种格式,HTML 格式基于 assets/ 中的 HTML 模板生成。
【第十四步:测试】
用 2-3 份不同类型的剧本跑全流程,重点检查:字段是否缺失、镜头是否正确生成、提示词是否符合 references/ 中的规范。发现问题后定位到对应脚本,只修改该脚本,不动其他文件。告诉我每份剧本的测试结果和发现的问题。
【第十五步:封装 SKILL.md】
基于以上所有内容,生成完整的 SKILL.md 文件,包含:定位说明、触发方式、完整七步流程说明、输入要求、输出目标、文件目录结构。
—
所有文件生成完毕后,输出完整目录结构,以及如何用一份测试剧本跑通全流程的指南。
几个问题
最开始怎么理清制作一个 Skill 的思路?
先抓一条主线:先想清楚“用来做什么、输入什么、交付输出什么”,再把中间步骤进行拆分(比如解析、生成、检查、导出),然后要求统一格式,再让 AI 输出。
轻松慵懒版顺序可以是:提示词直接要求它可以通过输入什么,获得什么输出,中间的流程是怎样的,有哪些模板可以调用,最后让 AI 写脚本。等这个完成了,需要什么再补充。这样做不会一开始就陷入技术细节,也不容易做着做着跑偏。
有任何不清楚的地方都可以问 AI,从大方向到细化都可以问。比如:


AI可能会写得很详细,我们提取关键要素就可以。
再让 AI 按要求生成 Skill 之前把要求尽可能梳理全面,感觉逻辑不够清晰或者还有优化空间,都可以让 AI 去继续优化提示词。
为什么自动化脚本要单独出来?
自动化脚本要单独出来,是因为它和说明文档、模板资源的职责完全不同:在这里,脚本负责执行流程并产出结果,参考文档负责解释规则和标准,模板负责规范格式和交付外观。
为什么要分很多个子脚本?
复杂的 Skill 中,把脚本单独放在 scripts/,可以让我们直接调用、测试、替换和部署,不会被文档内容干扰;同时当规则变化时,我们可以只改 references/,当逻辑变化时只改 scripts/,维护成本和排错成本都会明显降低。
后期如果要修改内容,怎么要去要求 AI 去排查和修改比较节省 token ,并且准确高效率?
最简单的方法是:每次只让 AI 干一件小事,并告诉它“只改哪里、不要乱改、改完怎么验收”。你可以直接说:只检查并修改 scripts/scene_analyzer.py(复制文件路径) 里的光线规则,别动其他文件;先找问题点,再最小改动;最后只告诉我改了哪几行、会影响什么、怎么验证。这样 AI 不会到处读文件、不会大改代码,token 花得少,结果也更稳。
至于要不要改 SKILL.md,取决于改的是规则说明还是代码细节。
小白判断法:如果用户使用方式变了,就改 SKILL.md;如果只是内部实现变了,可以不改。
Skill下载
下载这个 Skill ,可以查看内部所有文件,安装即可直接使用:
https://my.feishu.cn/docx/PsPfdVFD9oZ3nZxcvBFcGxdgnje
本文由人人都是产品经理作者【阿真Irene】,微信公众号:【阿真Irene】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


