
 起点课堂会员权益
起点课堂会员权益向量知识库五步法:从“答非所问”到“精准回复”
用户问“积分怎么用”,我们的机器人回“天气变动请注意更衣”。这不是段子,是我们上线第二周的真实名场面。原因很简单:知识库用的是关键词匹配,用户换个说法就废。后来我用了向量知识库 + 大模型检索,终于让客服不再当智障。

1. 翻车:一个让运营想摔键盘的回复
智能客服上线第二周,一位用户问:
“积分怎么用啊?”
我们的知识库里有标准问答:
- 问题:“积分如何使用”
- 答案:“积分可在结算时抵扣现金,100积分=1元”
但机器人没匹配上,因为用户说的是“怎么用”,而库里写的是“如何使用”。关键词匹配没命中,机器人走了默认回复:
“抱歉,知识库中未包含。”
用户回了一个字:“滚。”
运营小姐姐截图发群里:“这机器人是来砸场子的吧?”
我一看日志,问题很清楚:知识库检索用的是关键词匹配(TF-IDF),用户表达稍有变化就搜不到。更惨的是,我们当时只有200条标准问答,覆盖不到所有问法。
2. 本质:客服的核心不是“能聊”,而是“能找到”
很多人做智能客服,一上来就搞大模型生成回复,结果就是胡说八道。我后来想明白了:
客服的第一要务是“把正确答案找出来”,而不是“自己编一个答案”。
用户问“积分怎么用”,他不需要你陪聊,他需要知道“100积分=1元”。所以问题的关键是:如何从知识库里,快速找到最相关的那一条。
传统关键词匹配的痛点是:
- “怎么用” ≠ “如何使用”
- “退款流程” ≠ “如何申请退款”
- “物流好慢” ≠ “配送时效”
用户说人话,库里写的是“官方语言”,匹配不上。
3. 技术选型:向量检索 + 大模型重排
当时我调研了三种方案:
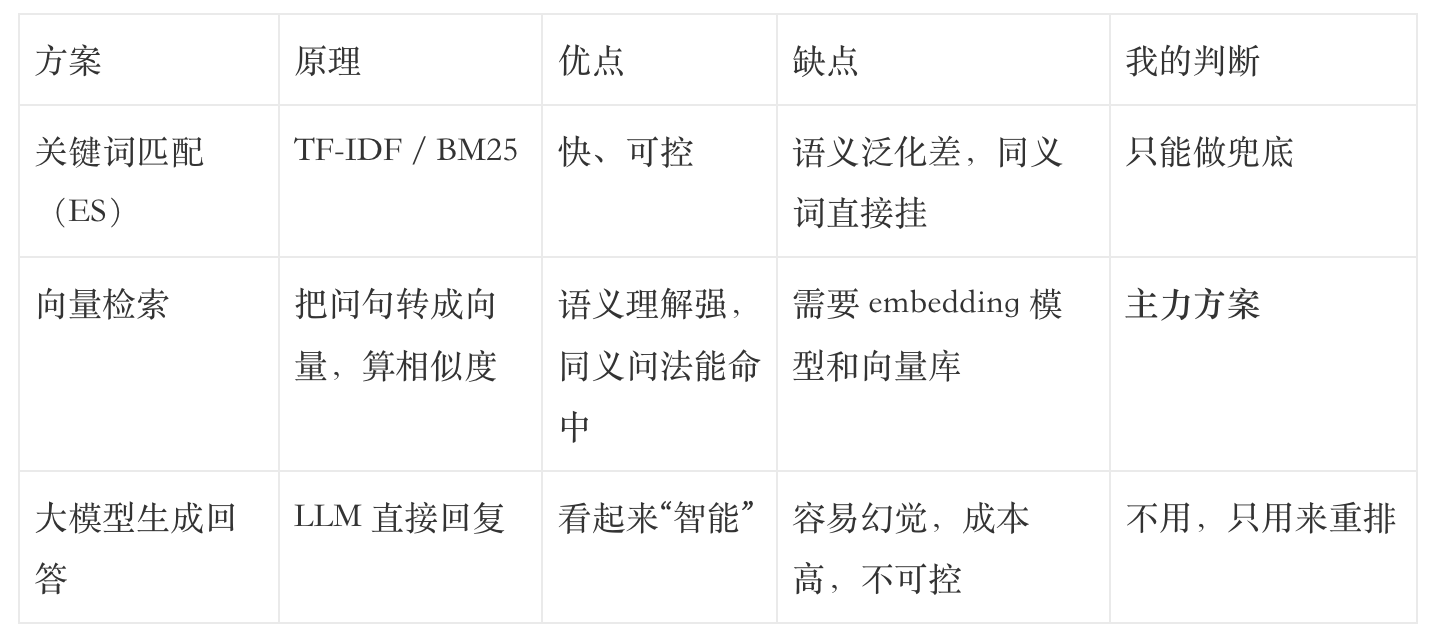
我选了向量检索为主 + 大模型重排为辅的架构:
- 召回阶段:用 embedding 模型把用户问句和知识库里的标准问题都转成向量,用 Milvus 做近似最近邻检索,召回 Top-K(比如 K=10)。
- 重排阶段:把召回的 10 条候选,送给大模型打分,选最相关的 1 条。大模型不看答案内容,只判断“这个问题和用户问句有多像”。
- 输出答案:命中后,返回预先写好的标准答案。绝不生成新内容。
4. 五步法:从零到一搭建向量知识库
第一步:清洗知识库
我们原来有 2000条问答,但很多是“一条问题对应多个答案”或者“答案里带着营销话术”。
我做了三件事:
- 问题标准化:每个标准问题写成最通用的问法,例如“积分如何使用”。
- 答案纯净:只保留答案,去掉“天冷请注意加衣”这类废话。
- 同义问法扩展:每个标准问题,由标注员写 3-5 个同义问法,用于增强检索(也叫“数据增强”)。
比如标准问题“积分如何使用”,同义问法:
- “积分怎么用”
- “积分怎么花”
- “积分抵扣规则”
- “积分能干嘛”
这一步最花时间,但最值得。200 条问答,扩展后变成 600 条,召回率直接涨了一半。
第二步:选择 Embedding 模型(不纠结具体型号)
我们对比了几个开源的中文 Embedding 模型,最终选了一个在公开基准上表现不错的轻量级模型(参数量 ,维度 )。选型标准:
- 中文语义理解能力
- 推理速度(每句 )
- 可本地部署,不依赖外部 API
最终模型部署在 CPU 上,足够支撑 400~500 QPS。
第三步:向量化 + 存入 Milvus
把所有标准问题 + 同义问法,全部转成向量,存入 Milvus。
Milvus 是我们选的向量数据库,优势是:
- 开源,社区活跃
- 支持多种索引类型(IVF_FLAT、HNSW 等)
- 可以分布式扩展
第四步:召回 + 重排
用户问“积分怎么用啊”:
- 转成向量,去 Milvus 里搜 Top-10,召回相似度最高的候选。
- 把用户问句和 10 条候选标准问题,拼成 prompt 送给大模型:用户问:积分怎么用啊 候选1:积分如何使用 候选2:优惠券怎么领 … 请选出最匹配的一个,只输出序号。
- 大模型返回序号,取出对应的标准答案。
第五步:兜底 + 人工闭环
如果大模型重排后最高分仍低于阈值(比如 0.7),说明知识库里没有相关内容,走兜底:
- 回复:“抱歉,这个问题我暂时回答不了,已转接人工客服。”
- 同时,把这条用户问句存入“未命中知识库”,每周人工审核一次,如果是高频新问题,就补充进知识库。
这样就形成了一个数据闭环:线上没命中的问题 → 人工补充 → 向量化更新 Milvus → 下次就能命中。
5. 落地遇到的三个坑
坑一:同义问法写太多,导致检索漂移
有一次,标准问题“退换货流程”,我们写了同义问法“不想要了怎么办”。结果用户问“衣服小了怎么办”,模型误匹配到“退换货流程”,实际上用户可能只是想换尺码。
解法:同义问法要克制,每个标准问题不超过 5 条,且必须与标准问题语义高度一致。
坑二:长文本问题检索不准
用户问“我上周买的薯片,今天收到发现碎了,怎么退款”,太长了,embedding 会稀释关键信息。
解法:先用大模型做关键信息抽取,抽成“商品=薯片,问题=碎了,动作=退款”,再用短句去检索。这一步我们后来加上了。
坑三:知识库更新不及时
运营改了答案,但 Milvus 里的向量没更新,用户还是拿到旧答案。
解法:每次知识库变更,触发增量更新(只重新向量化改动的条目),Milvus 支持按 ID 删除和插入。
6. 坦诚局:向量知识库依然搞不定的场景
- 需要多步推理:用户问“我有2000积分,买一包10元的薯片能抵扣多少?” 需要先查积分规则(100积分=1元),再计算(2000积分=20元,但薯片只卖10元,所以抵扣10元)。这种我们还在用规则引擎 + 代码算。
- 答案需要实时数据:用户问“我的订单到哪了”,向量知识库没有实时物流接口。解法:意图识别命中 query_logistics 后,直接调用 API,不走知识库。
- 超低频长尾问题:比如“你们公司什么时候上市”。向量检索也能找到相关问答,但没必要。我们直接走兜底转人工。
7. 结语:客服的本质是“找答案”,不是“编答案”
做了这么多,我最大的体会是:
智能客服不要迷信大模型生成。先把知识库检索做到极致,80%的问题就能解决。
向量知识库(Embedding + Milvus)+ 大模型重排,是我目前找到的最佳平衡点:
- 召回靠 embedding(快、语义泛化好)
- 存储和检索靠 Milvus(开源、可扩展)
- 重排靠大模型(准、能理解细微差别)
- 答案靠人工写(可控、不胡说)
本文由 @嘻嘻李 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


