
 起点课堂会员权益
起点课堂会员权益OpenAI 的神秘项目 Q* 与通往 AGI 的一小步
最近这些天,OpenAI 的神秘项目 Q* 引发了许多人的关注,因为这个项目可能意味着实现通用人工智能(AGI)的关键突破。这篇文章里,作者就对 Q* 做了猜测与解读,一起来看看本文的分享。

故事要从 11 月 23 日的感恩节前夕说起,路透社发文报道称 OpenAI 的几名研究员给董事会写了一封信提示一个强大的人工智能发现可能会威胁人类,这可能是奥特曼被解雇的重要原因。
随后 OpenAI 在发给员工的内部消息中承认有一个名为 Q* 的项目,在拥有大量计算资源的情况下,它能够解决某些数学问题。只有一个名字,没有论文,没有产品,Jim Fan 说在他做 AI 的十年里还没有见过一个算法能让这么多人好奇。
虽然 Q* 的数学能力据悉只有小学生的水平,但它标志着 LLM 推理能力的增强和幻觉问题的处理,是实现通用人工智能(AGI)的关键突破。目前没有官方解释 Q* 究竟是什么,但 Nathan Lambert 和 Jim Fan 等技术大 V 给出了最靠谱的假设,也是对于如何进一步提升模型推理能力的方法猜想,解读如下。
Let’s learn step by step.
Sense 思考
我们尝试基于文章内容,提出更多发散性的推演和深思,欢迎交流。
Q* 与传统大语言模型的区别:现有模型很难在所训练的数据之外进行泛化,展现出的逻辑推理能力更像是“直觉”,而 Q* 似乎把 Q 学习与 A 搜索模型结合,将基于经验的知识和事实推理结合,实现真正的推理能力、解决幻觉问题。
Q* 的技术路线猜测:自我对弈+思维树推理+过程奖励+合成数据增强。使用过程奖励模型(PRM)对思维树推理过程结果进行评分,然后使用离线强化学习进行优化。
过程奖励模型依赖庞大的数据,即对每个中间步骤打分。仅靠模仿人类数据,人工智能无法成为“超人”。AI 合成数据是增强数据集的方式之一,但对于其生成数据质量和可扩展程度还有待验证。
一、重温 AlphaGo
要理解搜索与学习算法之间的强强联手,我们需要回到 2016 年,重温人工智能历史上的辉煌时刻 AlphaGo。
它有 4 个关键要素:
- 策略 NN(学习):负责选择好的棋步。它能估算出每一步棋获胜的概率。
- 价值 NN(学习):评估棋盘并预测围棋中任何给定可行局面的胜负。
- MCTS(搜索):蒙特卡罗树搜索。它使用策略 NN 模拟从当前位置出发的许多可能的走棋顺序,然后汇总这些模拟的结果,决定最有希望的走棋。这是 “慢思考 “部分,与 LLM 的快速标记采样形成鲜明对比。
- 驱动整个系统的地面实况信号(Groundtruth signal)。在围棋中,它就像二进制标签 “谁赢了 “一样简单,由一套既定的游戏规则决定。可以把它看作是维持学习进度的能量源。
那么上面四个部分如何协同?
AlphaGo 进行自我对弈,即与自己的旧检查点对弈。随着自我对弈的继续,”策略网络”(Policy NN)和 “价值网络”(Value NN)都会得到迭代改进:随着策略在选择棋步方面变得越来越好,”价值网络”(Value NN)也会获得更好的数据来进行学习,进而为策略提供更好的反馈。更强的策略也有助于 MCTS 探索更好的策略。
这就完成了一个巧妙的“永动机”。通过这种方式,AlphaGo 能够引导自己的能力,并在 2016 年以 4 比 1 的比分击败人类世界冠军李世石。
仅靠模仿人类数据,人工智能无法成为“超人”。
二、Q* 的合理猜测
仅凭一个项目的名称,就能引发如此广泛的猜测,这还是第一次。不过,这个简单的名字可能并不仅仅是《沙丘》宇宙中的另一个代号。
核心结论:Jim Fan 认为 Q* 包括下面四个组成部分。与 AlphaGo 一样,”策略 LLM “和 “价值 LLM “可以相互迭代改进,并随时从人类专家的注释中学习。更好的策略 LLM 将帮助思维树搜索探索更好的策略,进而为下一轮收集更好的数据。
- 策略 NN:这是 OpenAI 最强大的内部 GPT,负责实现解决数学问题的思维轨迹。
- 价值 NN:另一个 GPT,用于评估每个中间推理步骤的正确性。
- 搜索:与 AlphaGo 的离散状态和行为不同,LLM 是在 “所有合理的字符串 “这一更为复杂的空间中运行的,因此需要新的搜索程序。
- 地面实况信号(Groundtruth signal):可以理解为是对过程结果的打分数据。OpenAI 可能已从现有的数学考试或竞赛中收集了大量语料,或者使用模型本身合成数据做增强。
Nathan 最初的猜测是将 Q-learning 和 A* 搜索模糊地合并在一起,但随着对这个问题研究的深入,可以越来越相信,他们通过思维树推理搜索语言/推理步骤的能力很强,但这种飞跃比人们想象的要小得多。
夸大其词的原因在于,他们的目标是将大型语言模型的训练和使用与 Deep RL 的核心组成部分联系起来,而正是这些核心组成部分促成了 AlphaGo 的成功:自我博弈(Self-play)和前瞻性规划(Look-ahead planning)。
- 自我对弈(Self-play):是指代理(agent)可以通过与略有不同的自己进行博弈来提高自己的博弈水平,因为它会逐渐遇到更具挑战性的情况。在 LLM 的空间中,几乎可以肯定的是,自我对弈的最大部分将看起来像人工智能反馈,而不是竞争过程。
- 前瞻性规划(Look-ahead planning):是指使用世界模型来推理未来,并产生更好的行动或产出。两种变体分别基于模型预测控制(MPC)和蒙特卡洛树搜索(MCTS),前者通常用于连续状态,后者则用于离散行动和状态。
要了解这两者之间的联系,我们需要了解 OpenAI 和其他公司最近发表的成果,这些成果将回答两个问题:
- 我们如何构建可以搜索的语言表征?
- 我们该如何构建一种价值概念,并将其覆盖到分门别类且有意义的语言片段,而非整个语篇上?
有了这些问题的答案,我们就可以清楚地知道如何使用用于 RLHF 的现有 RL 方法。我们使用 RL 优化器对语言模型进行微调,并通过模块化奖励获得更高质量的生成(而不是像现在这样获得完整序列)。
三、通过 ToT 提示进行 LLMs 模块化推理
提示词里“深呼吸”(take a deep breath)和 “一步步思考 “(think step by step)等技巧的推广,如今已经扩展到了利用并行计算和启发式(搜索的一些基本原理)进行推理的高级方法。
思维树 (ToT)听起来确实如此。这是一种促使语言模型创建推理路径树的方法,推理路径树可能会也可能不会汇聚到正确答案。论文中对使用 LLMs 解决问题的其他方法进行了比较:
基础模型在大规模数据集上训练,可以执行广泛的任务。开发人员使用基础模型作为强大的生成式AI应用的基础,例如ChatGPT。
选择基础模型时的一个关键考虑因素是开源与非开源,下面概述了两种模型各自的优点和缺点:
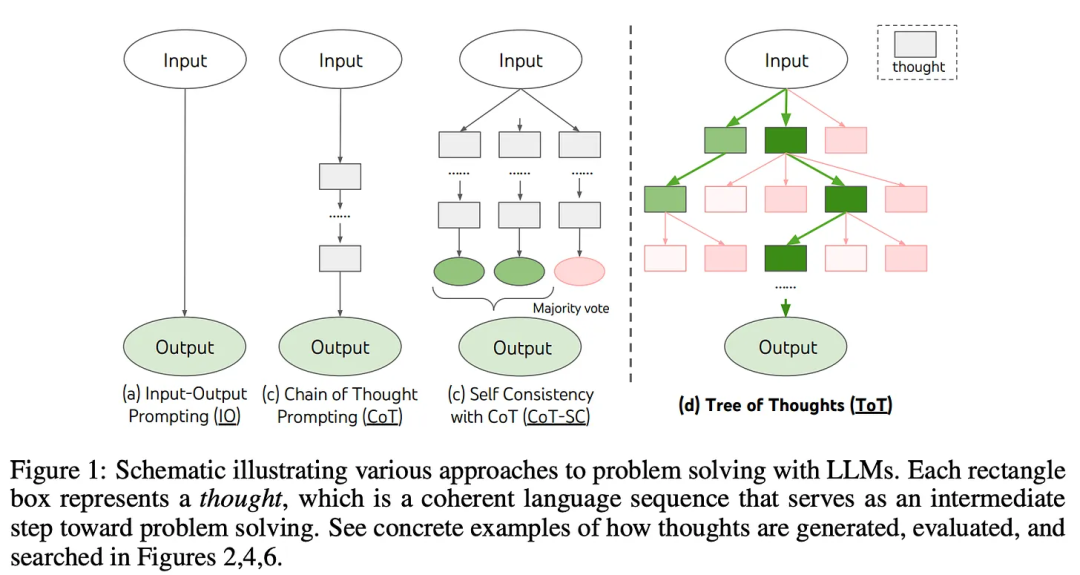
ToT 的创新之处在于将推理步骤分块,并促使模型创建新的推理步骤。这应该是第一种用于提高推理性能的 “递归 “提示技术,与人工智能安全所关注的递归自我改进模型非常接近。
对于推理树,可以采用不同的方法对每个顶点(节点)进行评分,或对最终路径进行采样。它可以基于诸如到最一致答案的最短路径,也可以基于需要外部反馈的复杂路径,这又把我们引向了 RLHF 的方向。
ToT 论文地址:https://arxiv.org/abs/2305.10601
四、细粒度奖励:过程奖励模型 PRM
迄今为止,大多数 RLHF 的方法都是让语言模型的整个响应得到一个相关的分数。对于任何具有 RL 背景的人来说,这都是令人失望的,因为它限制了 RL 方法将文本的每个子部分的价值联系起来的能力。
有人指出,未来由于需要有人类或一些提示源在循环中,这种多步骤优化将在多个对话回合的层面上进行,但这比较牵强。这可以很容易地扩展到自我对弈式的对话中,但很难赋予 LLMs 目标,使其转化为持续改进的自我对弈动态。我们想让 LLMs 做的大多数事情都是重复性任务,而不会像围棋那样对性能设置近乎无限的上限。
另一方面,有一种 LLM 用例可以很自然地抽象为文本块:逐步推理,数学问题就是最好的例子。
过程奖励模型(PRMs)是 Nathan 在过去 6 个月里从 RLHF 朋友那里听到的一个非公开话题。关于这些模型的文献很多,但关于如何在 RL 中使用这些模型的文献却很少。PRM 的核心理念是为每个推理步骤而不是完整的信息分配分数。下面是 OpenAI 论文《让我们一步步验证》( Let’s Verify Step by Step)中的一个例子:
图 2 为同一个问题的两种解决方案,左边答案是正确的,右边的答案错误。绿色背景表示 PRM 得分高,红色背景表示 PRM 得分低。PRM 可以正确识别错误解决方案中的错误。对于错误的解决方案,两种方法都揭示出至少存在一个错误,但过程监督还揭示了该错误的确切位置。

而他们使用的有趣的反馈界面(将被人工智能取代),却很有启发性:

这样就可以通过对最大平均奖励或其他指标进行采样,而不是仅仅依靠一个分数(标准 RM 在该文献中被称为结果 RM),对推理问题的生成进行更精细的调整。
使用 “N最优采样”(Best-of-N sampling),即生成一系列次数,并使用奖励模型得分最高的一次(这是 “拒绝采样”(Rejection Sampling)的推理方式之一,在 Llama 2 中广为流传),PRM 在推理任务中的表现优于标准 RM。
迄今为止,大多数 PRMs 资源只是展示了如何在推理时使用它们。当这种信号针对训练进行优化时,才能发挥真正的威力。要创建最丰富的优化设置,必须能够生成多种推理路径,用于评分和学习。这就是思维树的作用所在。ToT 的提示为人们提供了多样性,可以通过访问 PRM 来学习利用这种多样性。
此外,还有一种流行的公开数学模型被记录为使用 PRMs 进行训练:Wizard-LM-Math。同时,OpenAI 在今年早些时候发布了用于训练 PRM 的《逐步验证》(Verify Step by Step)论文中的细粒度奖励标签。
五、回头来看 Q* 与模型推理
Q* 似乎是在使用 PRM 对思维树推理数据进行评分,然后使用离线 RL 对其进行优化。这看起来与现有的 RLHF 工具并无太大区别,后者使用的是 DPO 或 ILQL 等离线算法,无需在训练期间从 LLM 中生成。RL 算法看到的 “轨迹 “是推理步骤的序列,因此我们最终是在以多步骤方式而非上下文绑定的方式进行 RLHF。
由于有听闻已经表明 OpenAI 正在使用离线 RL 进行 RLHF,这或许并不是一个大的飞跃。这种方法的复杂之处在于:收集正确的提示、建立模型以生成出色的推理步骤,以及最重要的一点:对数以万计的完成情况进行准确评分。
最后一步就是传闻中的 “庞大计算资源 “所在:用人工智能代替人类给每个步骤打分。合成数据才是王道,用树状而非单宽路径(通过思维链)在后面给出越来越多的选项,从而得出正确答案。
据悉有一家或几家大型科技公司(谷歌、Anthropic、Cohere 等)正在通过过程监督或类似 RLAIF 的方法创建一个预训练大小的数据集,这将快速耗费数万个 GPU 小时。
在这一领域,公开可用模型的差距令人担忧。总结来看,虽然核心理念似乎很清晰,但实施起来却很难。所有对 ToT 和 PRM 的评估都是针对数学等推理问题的,而这正是所有新闻报道所说的这种泄露方法的目的所在。即使它不是 Q*,也会是一个有趣的实验。
对于超大规模人工智能反馈的数据与未来:
大模型训练过程中数据不足,合成数据是扩大数据集的方式之一。在短期内,我们是可以利用它创建一些有用的数据。
然而,目前尚不清楚的是它的扩展程度。
它是否能完全取代互联网规模的数据?
Let’sverify step by step.
参考材料:
Nathan 观点:https://www.interconnects.ai/p/q-star?lli=1&utm_source=profile&utm_medium=reader2
Jim 观点:https://x.com/DrJimFan/status/1728100123862004105?s=20
PRM 参考论文:
- https://arxiv.org/abs/2305.20050
- https://arxiv.org/abs/2211.14275
- https://arxiv.org/abs/2308.01825
- https://arxiv.org/abs/2310.10080
编辑:Vela
来源公众号:深思SenseAI;关注全球 AI 前沿,走进科技创业公司,提供产业多维深思。
本文由人人都是产品经理合作媒体 @深思SenseAI 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


