
 起点课堂会员权益
起点课堂会员权益从提示词到上下文:构建下一代企业级AI应用的核心范式转变
企业级 AI 正在告别“拼提示词”的草莽时代,转向“拼上下文”的系统战争。过去 12 个月,我们把 200+ 条业务提示词喂给同一大模型,发现决定准确率的不是 prompt 花哨程度,而是上下文的“三把锁”——知识边界、权限边界、会话记忆。谁能把 ERP、CRM、IAM 里的碎片化数据实时蒸馏成 4K token 的“业务快照”,谁就能把幻觉率从 30% 压到 3%,把交付周期从月缩到周。

在构建企业级AI应用时,一个残酷的现实是绝大多数项目的失败,并非基座大模型能力的失败,而是上下文的失败。即便最强大的大模型,如果提供给它的信息是不完整、有歧义的或者结构混乱的,其表现也会大打折扣。这反映了一个核心事实–决定AI系统性能上限的,正是其在做出推理前所能获取的信息质量。
随着AI从简单的问答工具向能够执行复杂任务的智能体进化,行业内的关注点正迅速从提示词工程(Prompt Engineering)转向一门更系统、更具架构性的学科——上下文工程(Context Engineering)。本文将直接剖析这两者的区别,帮助您理解为何后者才是构建可靠、可扩展的生产级AI应用的基础。
提示词工程,本质上是精心设计和构建输入指令的过程,目的是为了让大模型在推理中,获得更优的单次输出。它的核心焦点在于“如何提问”,即优化直接发送给大模型的、具体的文本字符串。这门技术在处理独立的、单轮次的任务时非常有效,例如生成一封邮件、总结一段文字、生成一张图片等。
上下文工程,则是一门系统性的学科,其定义为在大模型进行推理时,对其周遭所有静态信息和动态信息,进行系统性的设计、构建和管理。它关注的问题在于“需要让大模型知道什么”。它要管理的不是单条指令,而是模型做出推理前,所能看到的整个信息生态系统,这包括对话历史、用户数据、外部知识库、可用的工具及其返回结果等。
为了更直观地理解两者的差异,下表从多个维度进行了直接对比:

可以认为,提示词工程是上下文工程的一个子集。比如你需要将精心设计的系统提示词(System Prompt)视为上下文工程中的一个静态组件,用于刻画每个智能体的角色设定。但是,上下文工程需要构建一个动态运转的系统,在每一次调用LLM之前,都根据当前任务实时地组装一个最优的信息集合。
为什么我们必须要关注上下文工程?这里涉及到对上下文窗口的理解。
著名AI研究者Andrej Karpathy提出了一个精准的技术类比:LLM就像一种新型计算机的CPU,而它的上下文窗口(Context Window)就是这台计算机的RAM(内存)——即AI处理当前任务的工作记忆。
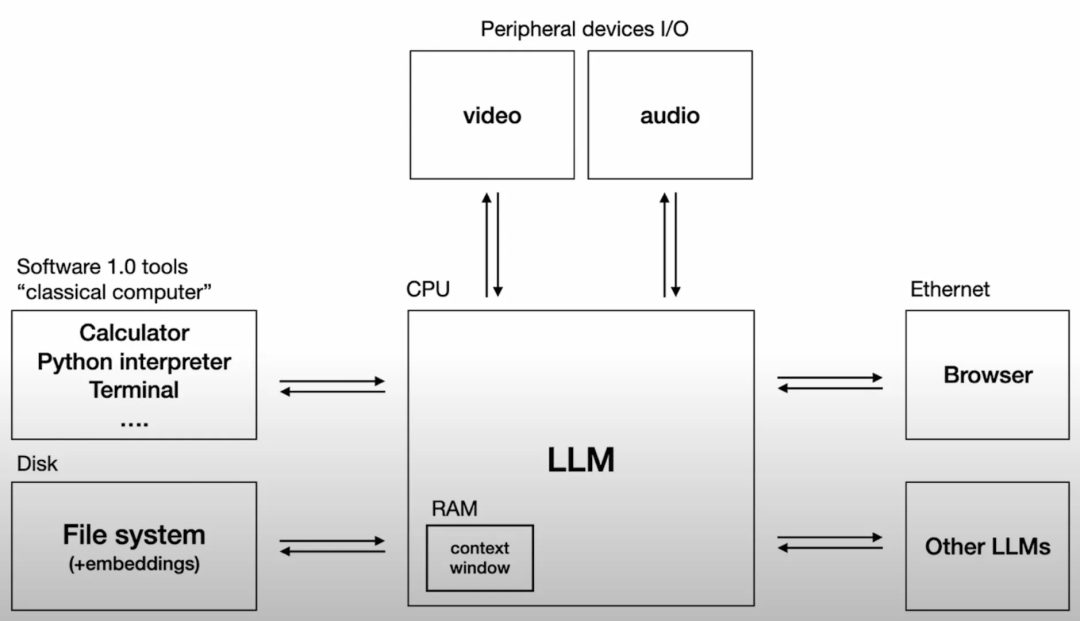
(图源:Andrej Karpathy: Software Is Changing)
LLM的上下文窗口是一种有限且宝贵的资源,它受技术、成本等限制不可能无限大。天真地将所有可能相关的信息都塞入上下文,不仅会迅速耗尽Token预算、增加大模型推理的成本和延迟,还会引发一系列严重的问题,比如:
- 中间遗忘(LostintheMiddle):模型更倾向于关注上下文的开头和结尾,而忽略中间部分的信息。
- 上下文腐烂(ContextRot):随着上下文长度增加,模型准确处理信息的能力会下降。
- 上下文干扰(ContextDistraction/Confusion):过多的无关信息,例如提供了过多的工具定义,会分散模型的注意力,导致其性能下降,甚至完全忽略核心指令。
- 上下文中毒(ContextPoisoning):一个错误的或被篡改的信息进入上下文后,可能会被模型反复引用,导致后续的推理逻辑全盘崩溃。
因此,上下文工程的核心挑战在于在有限的上下文窗口内,传递最高质量的信息。这要求我们从被动地“填满”上下文,转向主动地、策略性地“管理”上下文。
让我们通过一个具体的企业级客户服务场景,来感受这两种方法的巨大差异。
场景是一位已登录的客户发起聊天,“我想查一下我的订单在哪?”
对于一个提示词工程的聊天机器人而言,能做到的系统逻辑非常简单。它接收到用户的文本,然后应用一个预设的提示模板,生成一个标准回复:“好的,请提供您的订单号。”这种方式将搜寻信息的责任完全推回给了用户,体验被动且效率低下。它无法利用用户已经登录这一重要信息,也无法访问任何实时数据。这是一种典型的无状态交互。
对于一个基于上下文工程构建的智能体,能通过一个动态的、多步骤的工作流系统更好地满足用户需求。
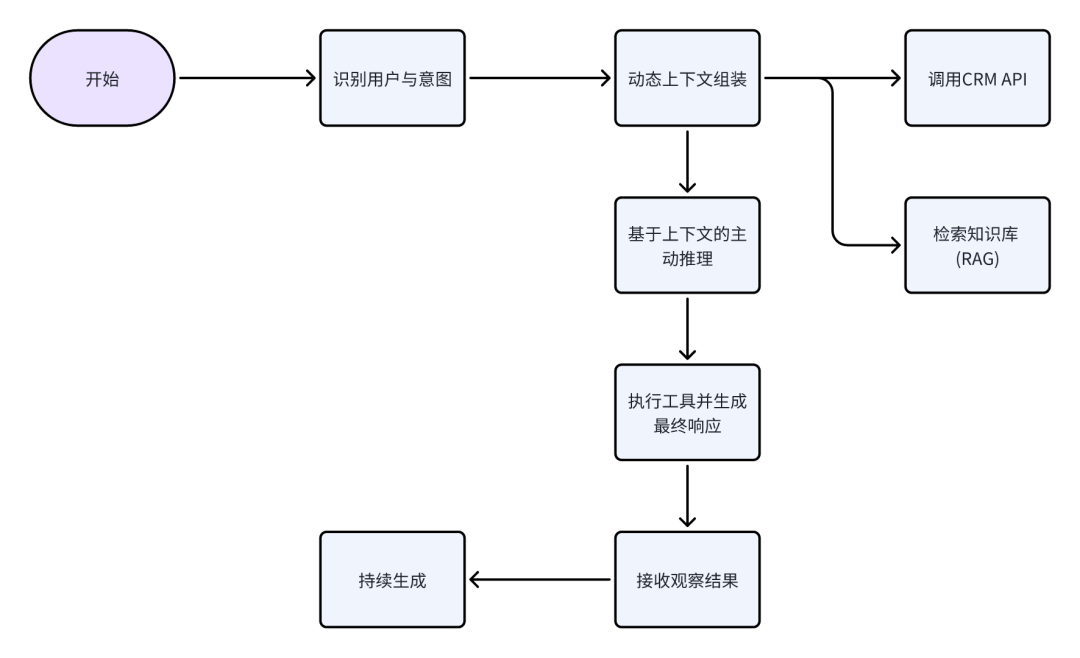
1、识别用户与意图:系统通过用户的登录信息识别出其customer_id,并理解用户的意图是“查询订单状态”。
2、动态上下文组装:系统不会立即响应,而是开始从多个数据源收集信息,动态构建上下文。
2.1、调用CRM API:使用customer_id查询CRM系统,发现该用户最近有三个订单:#123 (T恤), #124 (牛仔裤), #125 (鞋子)。
2.2、检索知识库 (RAG):系统并行地在企业内部的知识向量库中检索公司的“标准配送政策”文档,以备后用。
3、基于上下文的主动推理:此时,智能体的“工作记忆”中包含了“用户有多个近期订单”这一关键信息。它识别出请求的模糊性,并利用这个上下文生成一个更智能的问题,而不是盲目猜测:“我看到您最近有几笔订单:#123 (T恤), #124 (牛仔裤) 和 #125 (鞋子)。请问您想查询哪一单呢?”。
4、执行工具并生成最终响应:用户回复“#124”后,智能体调用内部工具,这里是一个业务系统后端APIcheck_order_status(order_id=124)。
5、接收观察结果:工具返回一个包含物流状态的JSON对象,这个结果被作为新的信息添加回上下文中。
6、持续生成:LLM收到的后续的上下文中,包含了完整的对话历史、从CRM获取的订单信息、工具返回的物流状态以及知识库中的配送政策。基于这个完整的、高质量的上下文,它可以生成一个全面而贴心的回复–“您的牛仔裤订单(#124)已通过菜鸟发货,预计明天下午5点送达。另外提醒您,我们的政策支持30天内退货。”。
这个例子清晰地表明,上下文工程通过系统化地编排信息流,将一个被动的问答机器人,升级为了一个主动、个性化且能解决实际问题的智能助理。
从“提示词”到“上下文”,这不仅仅是一个术语的演进,更是AI应用开发思想的深刻变革。它标志着行业从关注临时的指令技巧,走向了构建可持续、可扩展的信息系统。
在基础模型能力日益商品化的今天,一个公司独特且精心设计的上下文工程,将成为其核心的竞争壁垒之一。能够掌握上下文工程能力的团队,才能够打造出真正可靠、智能且体验卓越的AI产品。
本文由人人都是产品经理作者【明思AI】,微信公众号:【明思AI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


