
 起点课堂会员权益
起点课堂会员权益通过codex解析 Agent工作流程
大模型的诞生与落地是一场精密的技术革命。从预训练到微调,从效果评估到资源隔离,这篇文章深度剖析了AI模型从实验室走向企业应用的全流程。特别是Agent与Skill的协同机制,正在重新定义人机协作的边界——当AI能自主规划、组合技能、处理未知情况时,产品经理的思维框架需要怎样的升级?本文用实战案例揭示了大模型落地的成本、安全与效能平衡之道。

一、造大脑与考试
大模型出生前要过两关训练。第一关预训练,算法团队搭骨架,标注团队洗数据,让模型自学海量文本规律,这时它已经是一个具备基础语言能力的大模型。第二关微调,标注团队转身成了高级导师,手写标准问答、给答案好坏排序;算法团队把这些反馈练进模型参数里,教它变得安全、听话、会遵循指令。
训练完,该上考场了。考卷就是模型效果评估:拿标准答案跟它生成的回复对标,看准确率达不达标,召回率够不够全,顺便测测它会不会一本正经瞎编——也就是幻觉率。几把尺子量过,合格了,才敢放出去上岗。
- 准确率:在你判断为“是”的结果里,有多少真的是。比如查10个垃圾邮件,6个真垃圾,准确率60%。
- 召回率:在所有真正“是”的里面,你找回了多少。比如总共有20封垃圾邮件,你找出了6封,召回率30%。
二、搭舞台跑任务:项目/会话/MCP/知识库/skill/Agent
2.1项目(工作台)
模型训好考过了,要用起来,就得给它搭工作台。工作台分为两种:全局工作台和项目工作台,一个平台可以开多个项目,项目之间的资源默认隔离。假设目前的工作区有三个:全局,全局下的项目A和项目B,他们下面有各自的资源(Agent ,agents.md ,向量知识库和skill),他们之前的资源调用关系如图

项目 A 默认不能调用项目 B 的资源
- 项目 B 默认不能调用项目 A 的资源
- 项目 A / B 可以调用全局资源
- 全局默认不调用项目 A / B 的资源
但如果你明确授权或指定路径,例如“项目 A 参考项目 B 的知识库”,那就可以跨项目调用。默认隔离,显式指定才跨用。
2.2 单窗口对话(短期记忆)
打开一个窗口A,直接和大模型进行交互。窗口有上下文限制(短期记忆容量),指的是在一个对话窗口中“历史对话已经产生的 Token + 你本次提问的 Token”的总和限制,注:不是单次提问的限制。如果超出了限制,新产生的内容就会覆盖最开始产生的内容,该窗口的早期记忆就会丢失。
2.3 多窗口对话(长期记忆)
又打开一个窗口B,窗口B不会有窗口A的记忆。我在窗口A告诉大模型我叫小白 ,我在窗口B问大模型,我叫什么,他是回答不上来的。那我需要解决的问题是:如何跨对话记忆
在codex设置—MCP服务器页面配置Basic Memory工具,你每次聊天,它自动记笔记,新内容随时加进去,知识越聊越丰富。跨窗口跨项目都能用,不用重复描述上下文。
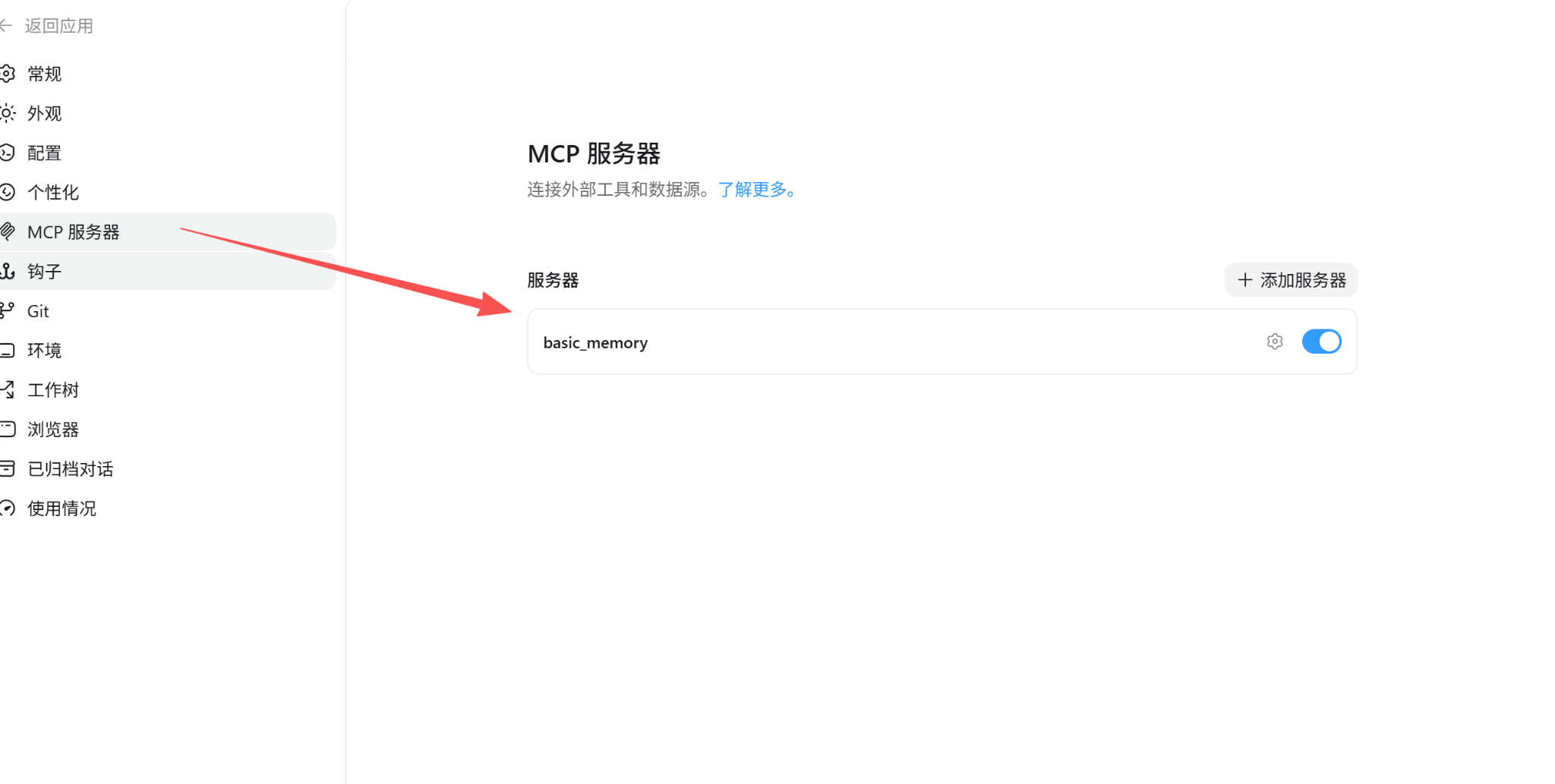

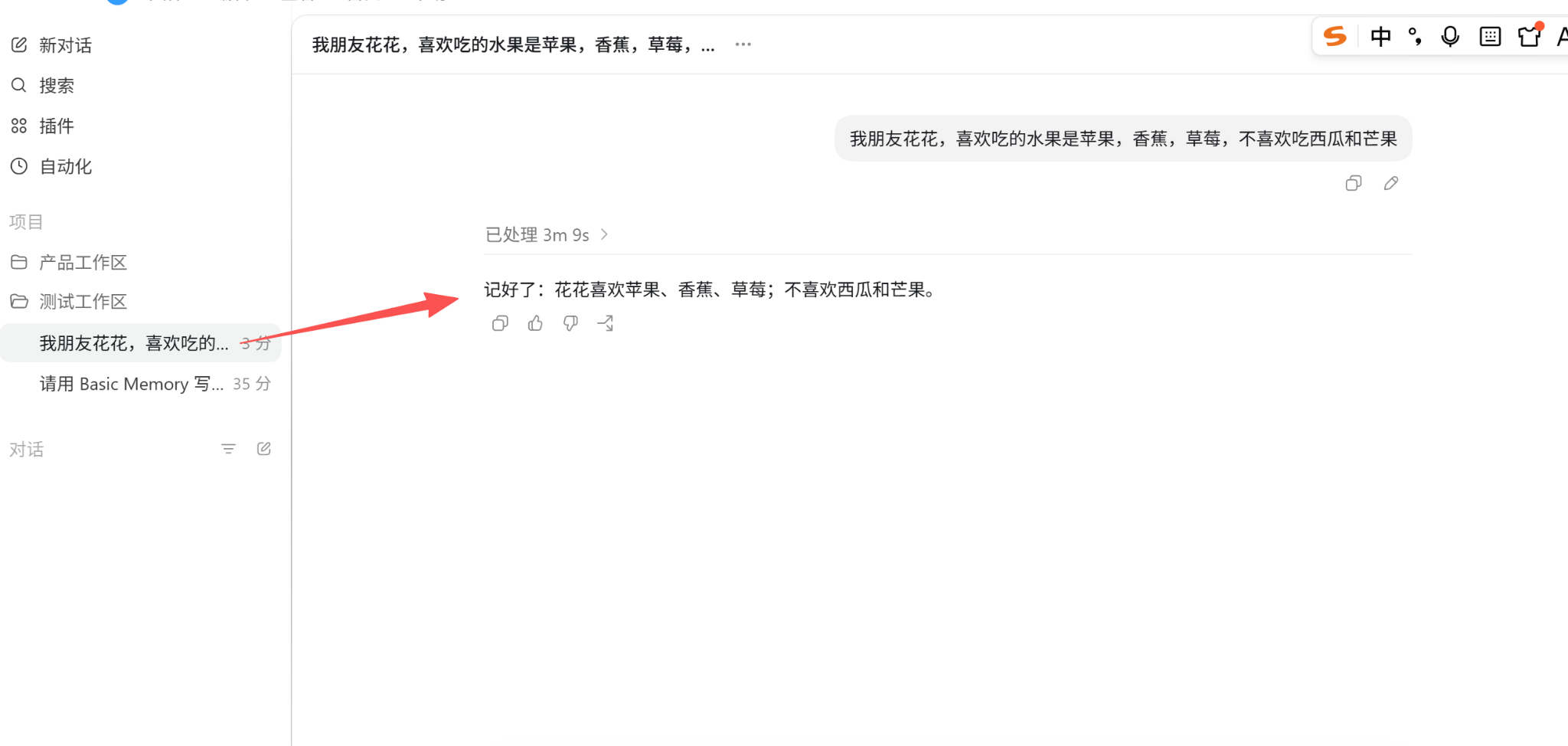
在对话A中提到“我朋友花花,喜欢吃的水果是苹果,香蕉,草莓,不喜欢吃西瓜和芒果”。在对话B中提问“我去朋友花花家做客,想买一个水果,不知道应该买什么,你给我点建议呗(请先查一下记忆,再回答)”,他就会先去查询记忆再回答,建议我带着草莓去
Basic Memory 是动态获取窗口上下文内容从而存储记忆。相对于动态记忆,还需要提到静态规则:在codex中不管是全局还是项目,都有一个AGENTS.md文件,它是AI的项目说明书。像墙上的规则纸条,你手写什么AI就看什么,你不改它永远不变。
2.4 MCP(模型上下文协议)
刚才我们提到了AI 通过 MCP调用Basic Memory的记忆能力,那么什么是MCP呐?MCP是连接AI与外部工具、数据和服务的“通用接口协议”,它让AI能安全、标准化地使用外部资源,真正实现能力扩展和自动化执行。工作流程如图所示
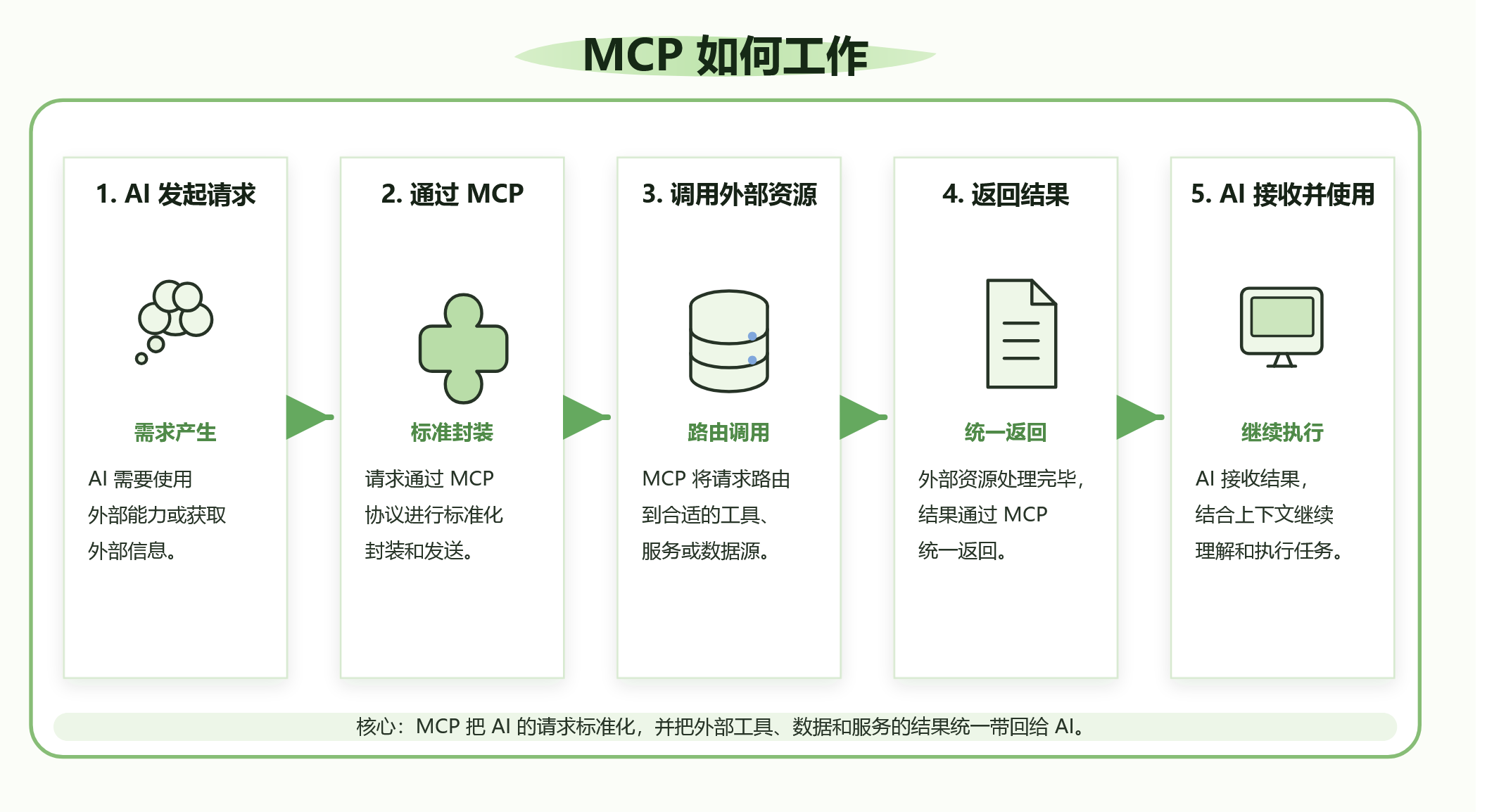
1、AI发起请求:AI需要使用外部能力或获取外部信息。
2、通过MCP:请求通过MCP协议进行标准化封装和发送。
3、调用外部资源:MCP将请求路由到合适的工具服务或数据源。
4、返回结果:外部资源处理完毕,结果通过 MCP统一返回。
5、AI验收并使用:AI接收结果结合上下文继续理解和执行任务。
2.5 Token
Token就是AI处理文字的“最小单位”。不管是你说的话还是它的回答,都会被拆成一个个Token来理解和计算。你提问问题,先被切成Token,再通过Embedding变成数字坐标,加上位置编码,喂给大模型。
Token是计费核心,按输入输出的积木块总数收费。你一次对话的总成本,约等于Token总消耗乘上单价,加上可能有的额外服务费。注意,模型内部推理时反复“默念”的那些看不见的思考,也在消耗Token,所以实际开销往往比肉眼看到的问答字数要大。
2.6 RAG(检索增强生成)
在实际操作中,会存在三个问题:①知识过时:大模型的知识停在训练截止日,仅通过大模型无法获取最新的知识。②记忆容量限制:面对长文档(例如一本几百页的书),直接塞会AI会突破记忆容量限制并且会特别费token。③幻觉:AI有时候会凭空编造,提供给你一个看似很合理但并不对的答案
针对这三个问题,引入了RAG,可以把实时/内部/经常改变的资料做成向量知识库,如果是不需要最新资料的查询,直接把原话丢给模型,模型凭微调时背下的知识直接作答。如果是事实查询,就启动RAG流程:知识库里已经做过文档分片,系统把你问的东西跟那些切片做相似度比对,达标的最相关几个片段被分片召回,巧妙绕过了窗口限制,拼成增强版提示词,让模型根据这些材料作答。AI回答时有了检索到的具体资料作依据,能引经据典,大大降低了凭空编造的可能,答案更可靠。具体执行流程如下图所示:
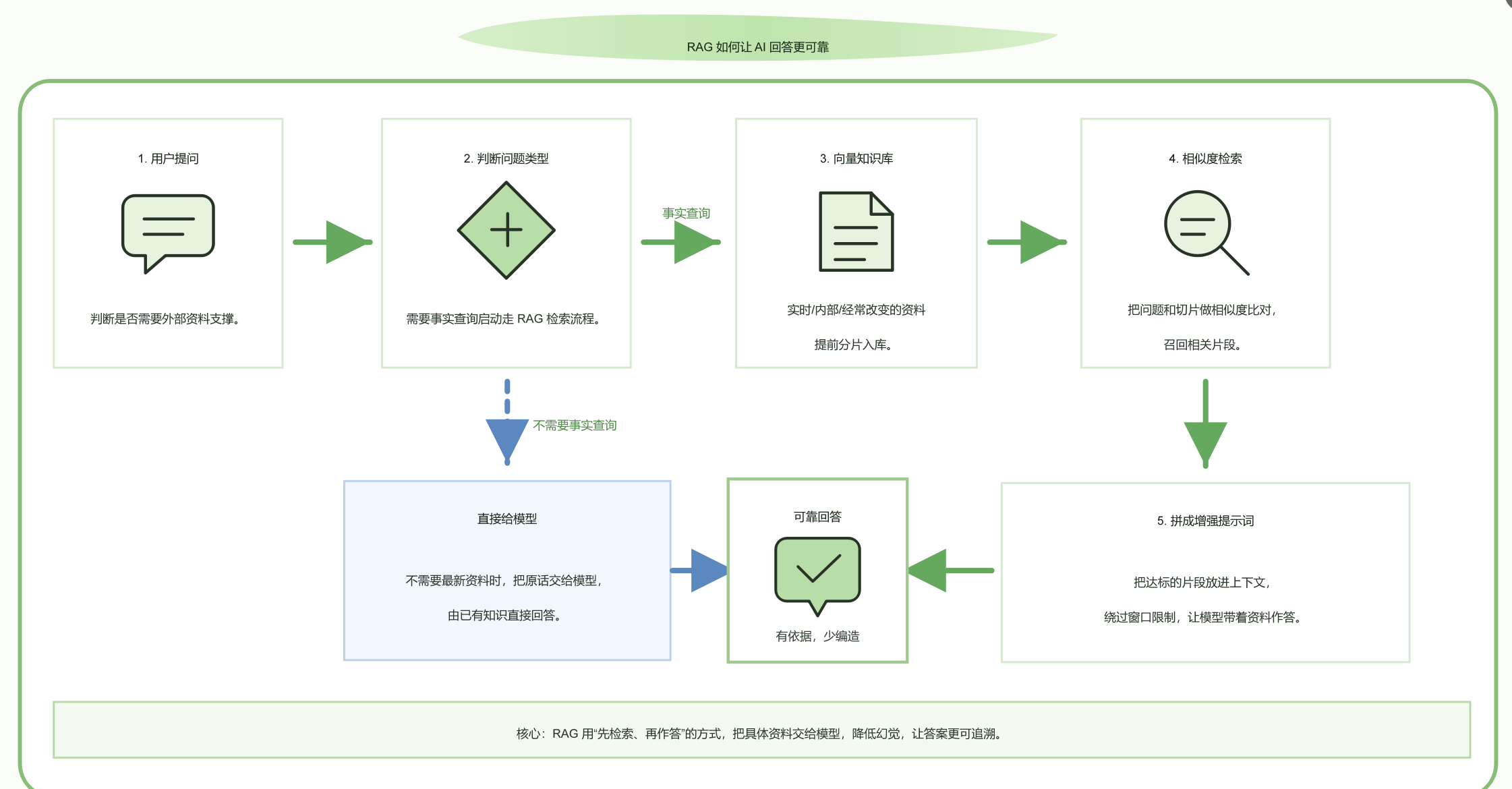
知识库分为两种:普通知识库和向量知识库。刚才说的文档分片,相似度对比指的是向量知识库。普通库看关键词,容易漏;向量库看意思,更聪明。
例如:你的知识库里有一份资料,里面写着:“企业软件的核心不是页面,而是对组织协作和业务流转的建模。你问:“为什么做 B 端系统不能只关注界面?”
普通文件库(书架模式):它只把这份资料存着,不会理解内容。AI 用关键词去搜,比如“界面”“关注”,但资料里没有这些词,只有“页面”“核心”。关键词对不上,所以搜不到,AI 只好回答“没找到相关资料”。
向量库(智能索引员):它提前把这句话转成数字指纹(向量),并记住它的“意思”。你问的“不能只关注界面”和资料里的“核心不是页面”虽然用词不同,但意思相近。向量库通过语义匹配,直接定位到这段话,然后 AI 用它回答你:因为 B 端系统的重点是业务流转和协作,界面只是壳,光做好看没用。
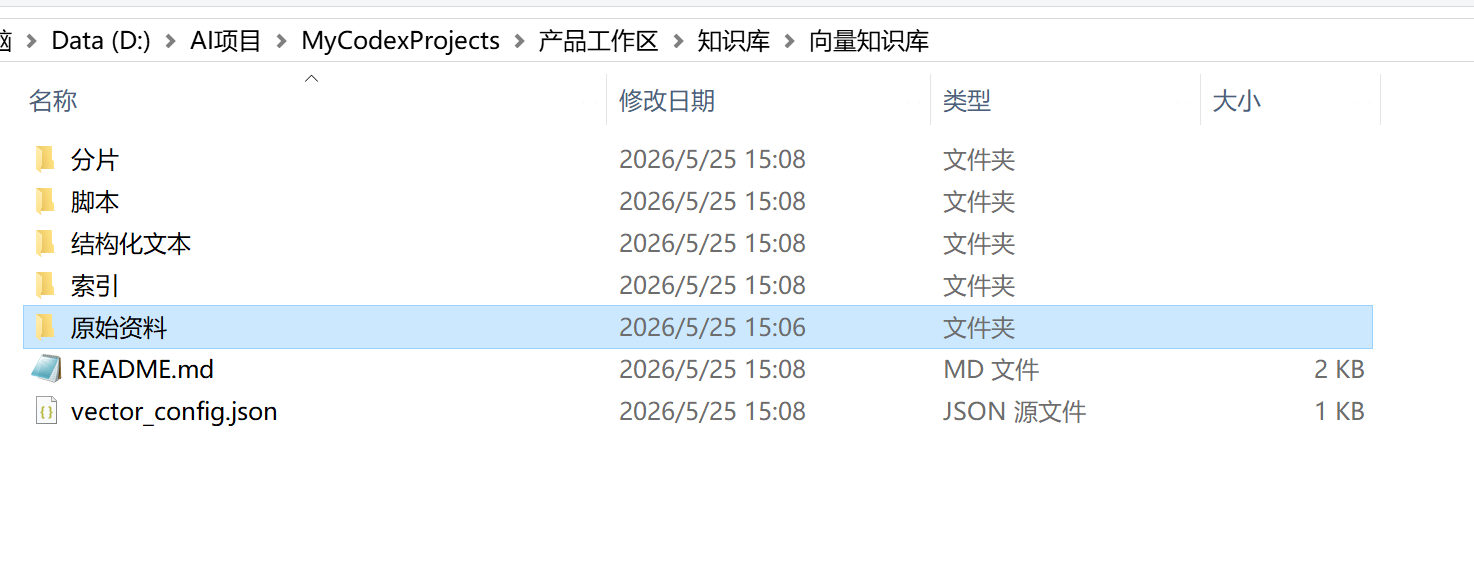
在codex中让AI帮我创建向量知识库并放入长文档

本地向量知识库的结构如图所示
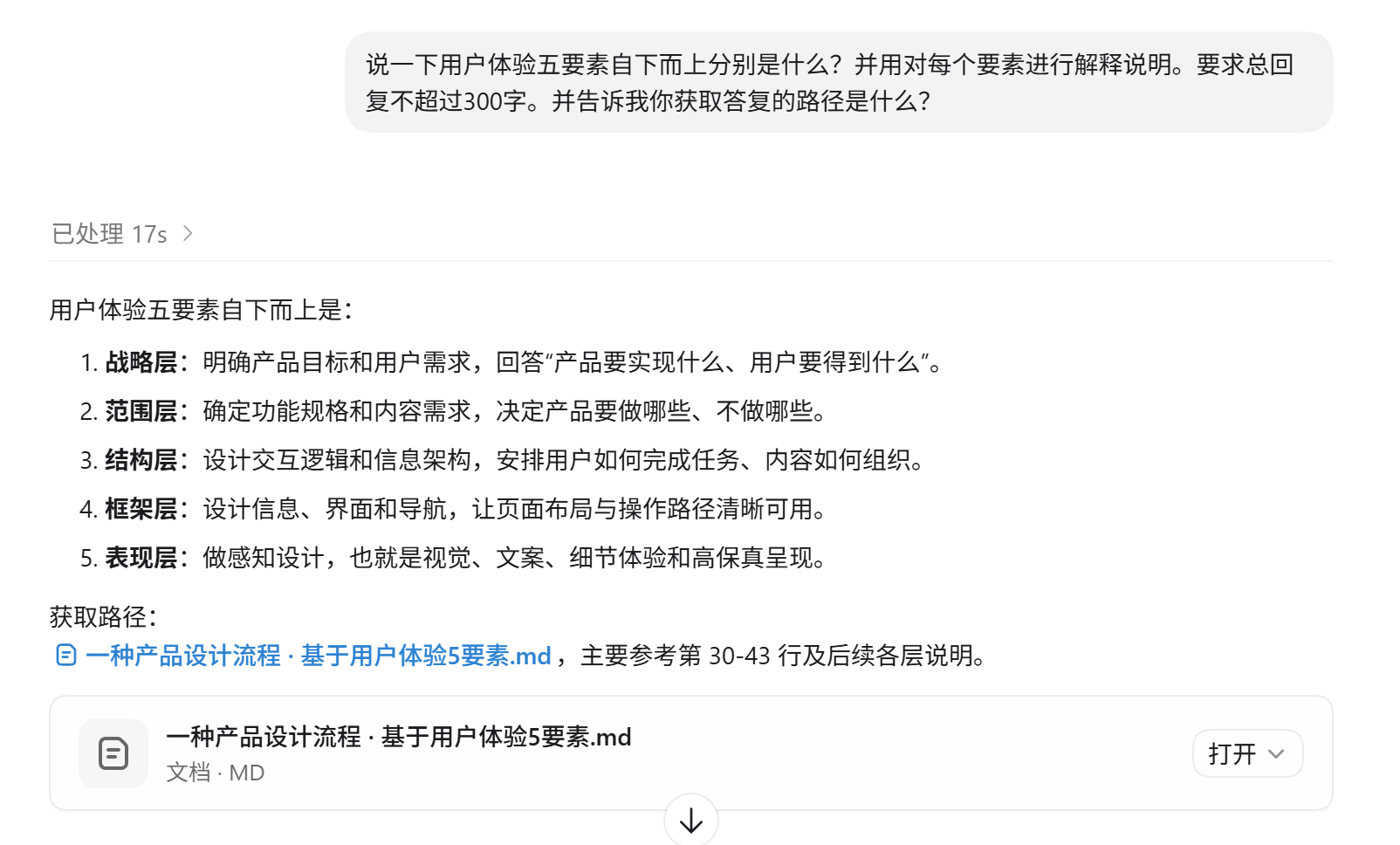
提出问题,会调用知识库中的内容作答。但是注意:事实来源来自知识库文件,最终表述经过 LLM 总结。
2.7 skill(技能)
Skills是AI的“能力工具箱“,技能越多,AI越能帮你解决更复杂、更专业的问题。在codex中安装skill直接输入“帮我安装skill+skill的地址”
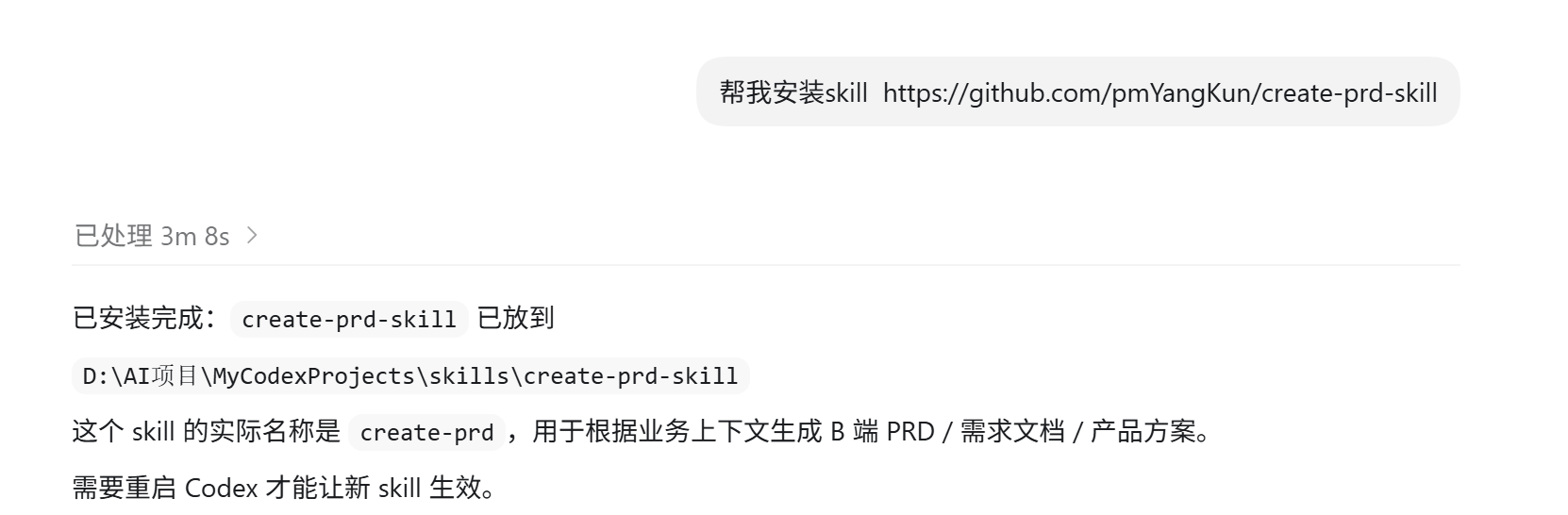
后续发起任务时AI会根据你的任务描述自动判断并匹配合适的 skill——只要描述够清晰,它就能自主调用全局或项目下的 skill,无需你点名
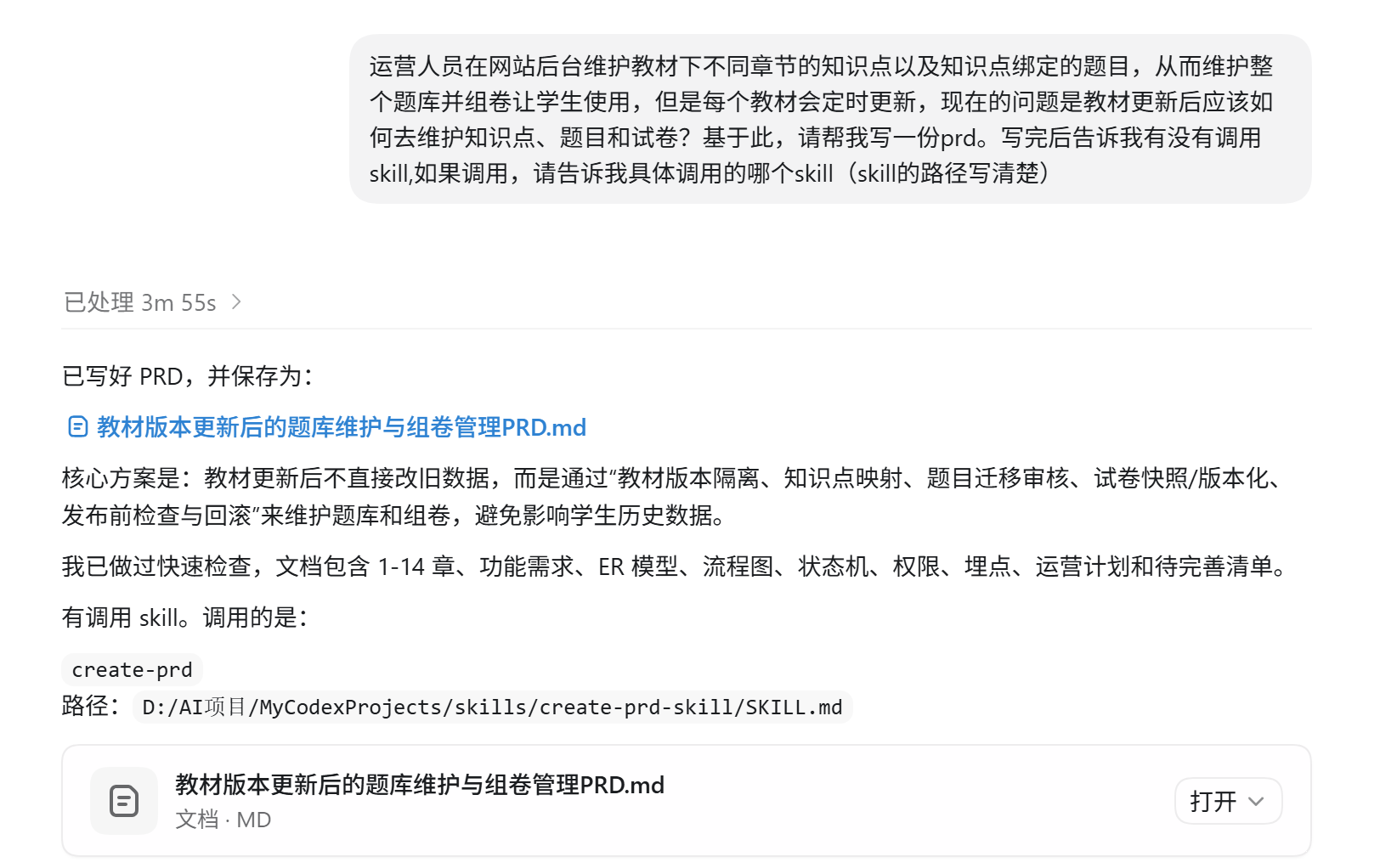
之前需要很长时间才能写完的prd就分分钟实现了从0到80分的写作思考过程,后续再根据自己的真实业务在上面修改完善,从80分慢慢优化为100分

注:每次新会话启动时,都需要重新加载全局和项目相关的 Skill,这会消耗 Token。所以没必要在项目中放置太多不相关的skill
2.8 agent
既然我发出指令,AI可以直接调用相关的知识库,skill,以及外部资源去完成任务,那么**为什么还要需要创建agent呐?**因为真实任务往往不是单一步骤。直接调用 Skill 只能完成你知道且确定的事。例如而 Agent 能处理未知和复杂的情况。它的核心价值是在不确定中自主规划,把多个 Skill 组合成解决方案。所以,Skill 是工具。Agent 是知道何时、以及如何组合使用这些工具的“大脑”。
直接调用 Skill(无 Agent):“用‘翻译Skill’把这段英文翻成中文。”模型直接执行,逻辑是:你下令 -> 模型照做。这是一个固定流程,没有意外。
通过 Agent 调用 Skill:这就像你雇了个管家。你说:“我下午要见个法国客户,帮我准备一下。”Agent(管家)会自主决策:
- 先调用“日程Skill”查客户背景
- 发现客户不懂英文 -> 主动调用“翻译Skill”准备法文材料
- 查完发现客户对茶感兴趣 -> 又调用“知识库”查法国茶文化
- 整个逻辑是:你给目标 -> Agent 自主拆解、决策,调用什么Skill,何时调用,以及如何处理意外。
Agent上岗前,得先定规矩。这就是Prompt那套东西:系统提示词是骨子里的准则,角色设定是它对外的人设,输出格式约束是回话模板,用版本管理记着,改坏了能回滚。对于简单一个人能做的任务,使用单agent去完成;对于需要团队协作且特别复杂的任务,使用多agent去完成。
例如在codex在对话框中输入提示词:“请帮我在这个项目下再创建一个名为‘竞品侦探’的Agent,并在它的系统提示词里写明:‘你是市场分析师。互联网产品市场分析应从市场规模、增长趋势、竞争格局、用户需求、政策与技术可行性五个维度展开;分析材料主要来自行业报告、券商研报、政府公开数据、竞品财报、用户调研、App Store排名;产出文档为《市场分析报告》或《市场洞察报告》。分析竞品时,必须列出3个对比维度和引用出处,没钱拿数据就直说,绝对不准瞎编。”
可以看到本地文件夹下存在刚刚创建成功的agent,yaml文件是Agent的角色设定文件
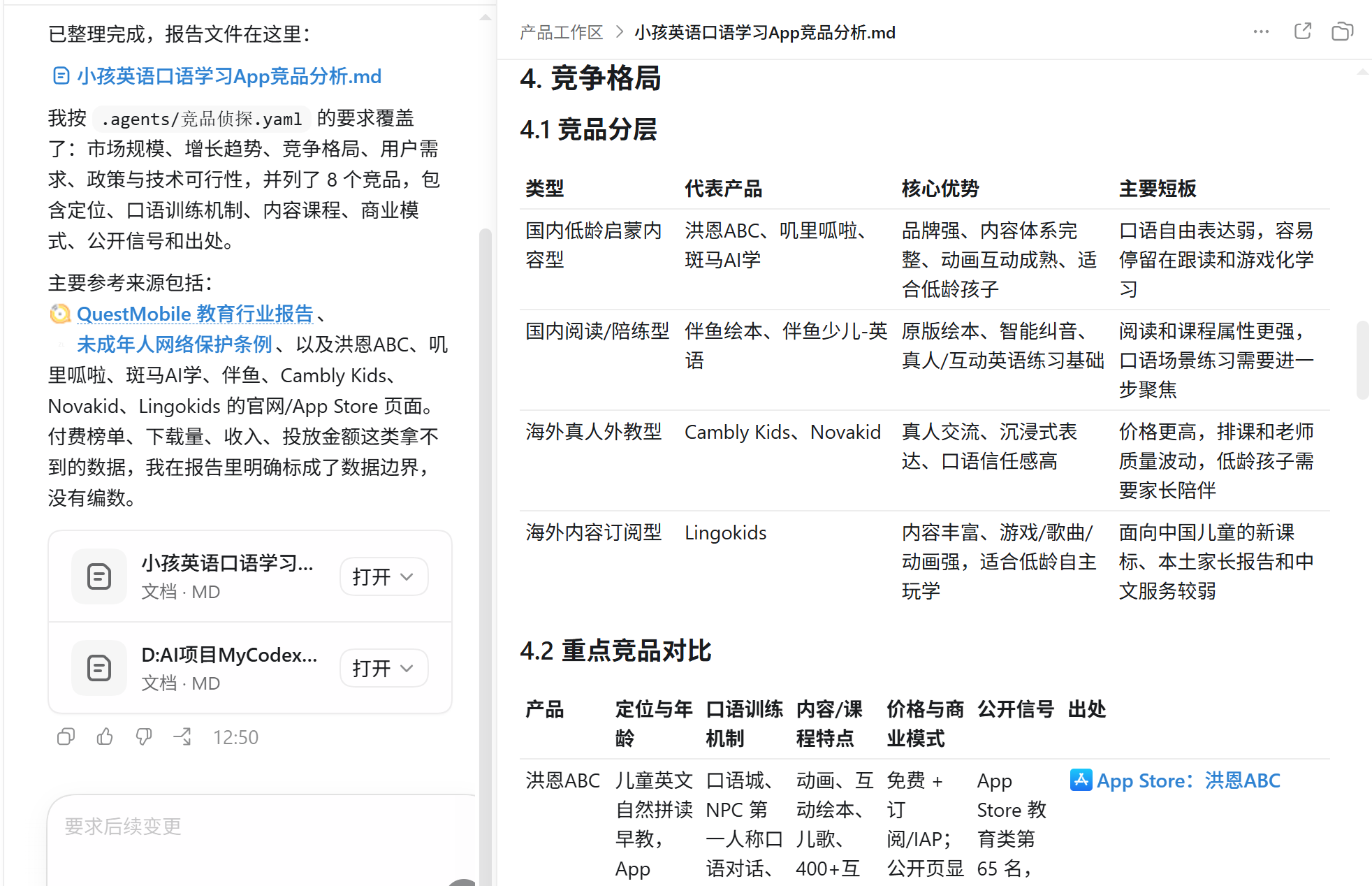
直接在输入框中调用agent去帮你生成竞品分析,agent已经帮我们完成从0到80分的过程,我们自己再精细优化到100分。
三、企业落地agent:成本与安全
对于企业落地agent的实施方案,最现实的问题其实就是钱和数据安全。
当访问量很大时,服务端有并发限制,像餐厅座位,满了就排队。聪明的系统用缓存策略,把高频问题答案暂存,下次直接复用,省去重复推理的Token开销。
数据安全:调用API像天天下馆子,轻量但数据要出门;私有部署是把模型整个下载到自家服务器,数据不出门,贵但放心。
四、小结
整条链子串起来看:预训练生出大脑,微调教其更聪明,评估考过才能上岗;项目搭台分配资源,Agent持规矩上岗;每次提问都在Prompt、记忆、RAG、Skill、MCP有选择性地使用并推理跑完一趟精密流水线;背后还有成本和安全拉着缰绳。这就是现在AI落地应用的完整图景。
本文由 @Grace 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


